利用specJVM98和Java Grande Forum Benchmark suite Benchmark集合对SJVM、IntelORP,Kaffe3种Java虚拟机进行系统测试。在对测试结果进行系统分析的基础上,比较了不同JVM实现对性能的影响和JVM中关键模块对JVM性能的影响,并提出了提高JVM性能的一些展望。
目录
1 Java虚拟机的关键技术
1.1 字节码执行方式
1.2 自动内存管理
2 JVM 性能的分析和比较
2.1 JVM 的选择
2.2 JVM 性能测试
2.3 JVM 性能的分析和比较
3 结语
Java语言的平台无关性、安全性、自动内存管理等特性,使Java语言得到广泛的应用。Java虚拟机JVM)是 Java平台的核心,JVM读入Java 类文件并执行类文件中的字节码。在一个平台只要有1 个Java虚拟机就可执行Java程序,实现Java语言的平台无关性。Java的字节码中无影响系统安全的指令,同时,JVM读入类文件时,需要预验证类文件,这两点保证了Java语言的安全性。自动内存管理减轻了Java程序员的负担,提高了应用程序的可靠性。但这些特性,使Java的性能受到了一定的影响。字节码执行方式(Execute Engine)和自动内存管理是影响 Java 虚拟机性能的关键模块。本文通过比较几种有代表性的 Java 虚拟机的实现,分析了JVM 中的这2 个关键技术。
1 Java虚拟机的关键技术
1.1 字节码执行方式
最早的Java虚拟机采用的是解释(Interpreter)执行的方式,这种方式效率极低,但JVM的可移植性较好。目前主流的 Java 虚拟机基本采用即时 JIT,Just—In-Time) 编译的方法执行字节码,即将 Java的字节码动态编译为本地的机器码,效率较高,好的JIT 编译效果可以接近 C 语言静态编译的效果。但JIT在执行任何一个方法时,都需要先将该方法编译为本地代码,需要额外的内存存放编译后的本地代码。对于程序中执行频度较低的方法,由于增加了编译的时间,其效率不如解释执行的情况。衡量一个JIT好坏的标准包括编译的代码质量、编译的代码大小以及编译的时间这3个方面。自适应优化(Adap-tive Optimization)是字节码执行的第3 种方式,其实质是混合执行(Mixed code execute)。自适应优化在第1次调用一个方法时,先采用解释执行的方式,当这个方法的调用达到一定的频度而成为“热点”(Hot spot 的方法后,将该方法编译为本地代码,以后对该方法的调用,直接执行编译后的本地代码。
1.2 自动内存管理
自动内存管理也称为垃圾收集(GC,Garbage Collection) ,其作用是自动回收无用单元的内存空间,释放内存的工作由Java虚拟机自动管理,减轻了应用程序员的负担,避免了Java应用程序的内存泄漏。垃圾收集算法的主要评价标准为吞吐量(Throughput)和停顿时间(Pause time) 2个方面。吞吐量指在程序运行中,非垃圾收集的时间与整个应用程序运行时间的比值,比值越高,垃圾收集算法的整体效率越高。
2 JVM 性能的分析和比较
2.1 JVM 的选择
在本测试中,选择了3 个有代表性的虚拟机实现作为研究的对象。
1) Sun Hotspot Client VM 1.4.1 (SJVM) 【1.是Sun公司提供的针对J2SE平台的虚拟机,采用了自适应优化的字节码执行方式、基于代(Generation)的垃圾收集机制、标记-清除(Mark-Sweep)算法和拷贝算法结合的算法。
2) Intel Open Runtime Platform 1.0.10 (Intel ORP 2.是Intel公司提供的Java 虚拟机,提供了针对IA32架构优化的JIT编译器,采用增量式的Train垃圾收集算法。
3)Kaffe 1.0.73.是开放源代码的Java虚拟机实现,它支持的平台较多,垃圾收集机制采用了不分代的保守的标记一清除算法,并提供了 JIT 的编译器。
2.2 JVM 性能测试
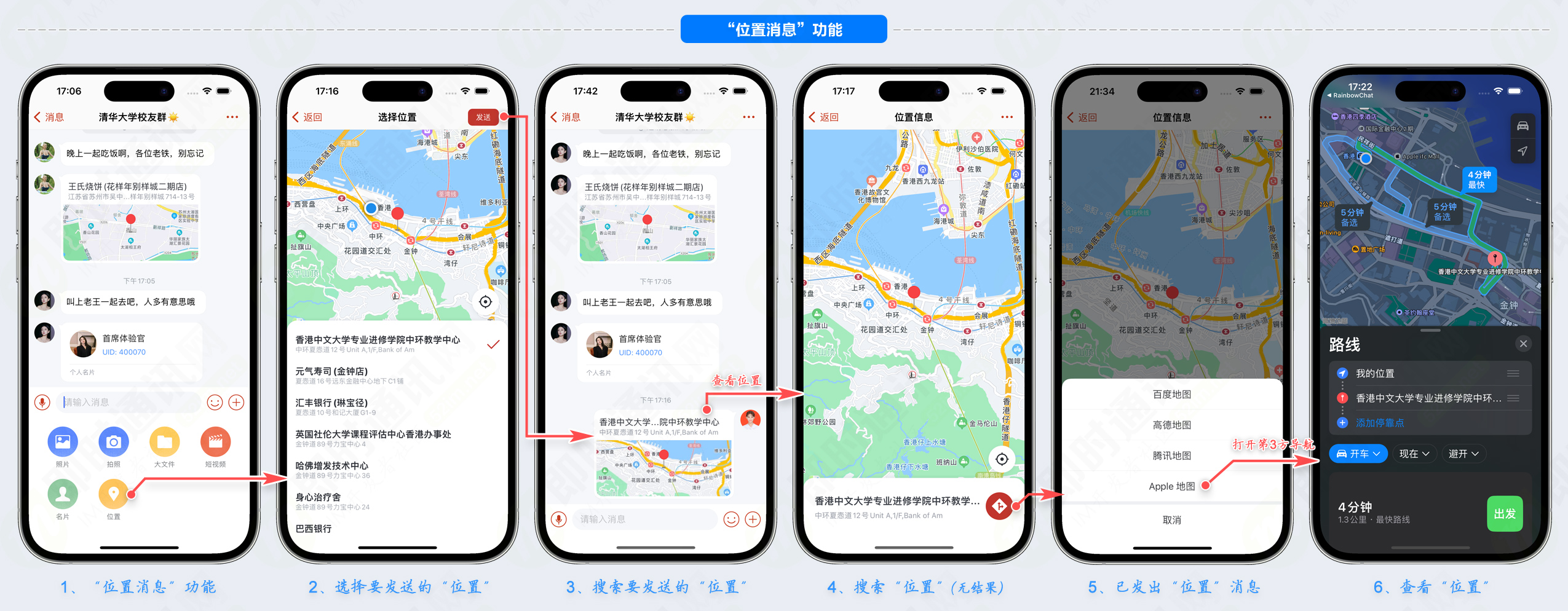
通过Benchmark集合的测试,能够有效的比较和分析不同JVM实现对性能的影响以及JVM中关键模块对JVM性能的影响。在本测试中,测试用的Benchmark集合为specJVM98【4】和Java Grande Forum Benchmark suite5.specJVM98采用的是接近真实的应用程序,主要包括Db、Compress、Jess、Javac、Mep-gaudio、Mtrt、Jack7个应用程序。Java Grande Forum Benchmark (以下简称JGF)包括3个部分的测试,第1部分为基本的底层操作,包括算术、赋值、方法调用、异常处理等;第2部分为核心的操作,包括加密、堆排序、矩阵相乘等算法;第3部分为大规模的应用程序,包括了Alpha-beta剪枝搜索、RayTracer等算法。本测试采用的操作系统为Red Hat Linux 7.3.硬件平台为AMD Athlon 1700+,内存256M。图1为specJVM98的测试结果,图2 至图4为JGF3个部分的测试结果。
2.3 JVM 性能的分析和比较
在Java虚拟机中影响性能的模块主要是即时编译和垃圾收集这两个模块。即时编译模块的性能包括编译时间和编译后代码质量两方面。垃圾收集模块主要从吞吐量和停顿时间2 个方面来衡量。
从图1可以看出,Kaffe虚拟机的性能较差,除了第一项测试compress接近SJVM和Intel ORP的性能外,其它测试中的性能表现低于另2个虚拟机的一半。Intel ORP在Compress, Mepgaudio2项测试中要略高于SJVM,而SJVM的性能在其他测试中表现最好。因此,从specJVM98的测试结果来看,SJVM的虚拟机表现最好,Intel ORP的性能较接近SJVM, Kaffe的性能与这两者间有一定的差距。
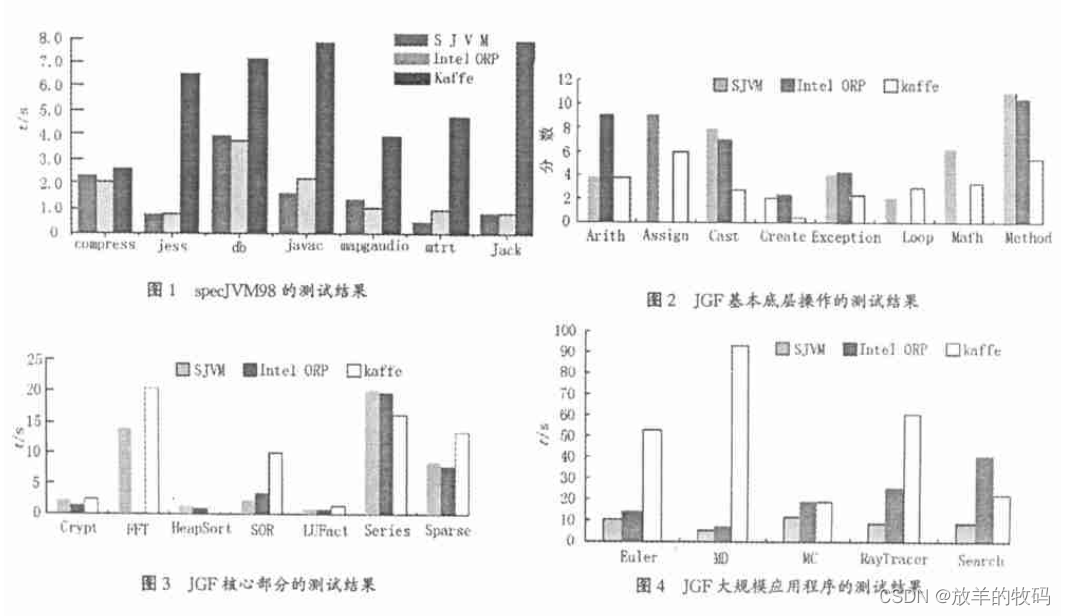
从图2、图3、图4可以看出:对于JGF基本底层和核心部分的测试,Intel ORP和SJVM的性能相差不大,Kaffe 的性能都低于前两者;对于大规模应用程序的测试,SJVM 的性能远好于 Intel ORP 和Kaffe,而Intel ORP的性能好于Kaffe,这个程序的详细运行结果见表1。
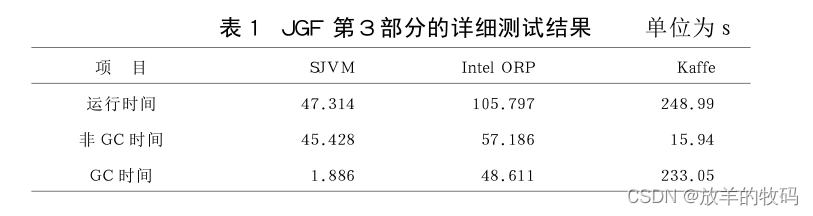
从表1可以看出:Kaffe 的 GC 时间为Intel ORP 的4.79 倍,非GC (大部分为JIT) 时间为Intel ORP的27.87%,非GC时间占整个运行时间的6.40%; Kaffe与Intel ORP相比,大部分的时间花费在JIT编译上; Intel ORP的GC时间为SJVM的25.77倍,非GC时间为SJVM的1.26倍;GC时间占整个运行时间的45.95%。
从以上分析可以看出:
1) SJVM的整体性能是最好的,大部分的性能高于Kaffe和Intel ORP,尤其是在JGF大规模应用程序的测试部分,它的性能远远高于Kaffe和Intel ORP。这是由于字节码执行方式采用了自适应优化的算法,只编译最常用的“热点”方法,同时编译的代码质量较高。
2) SJVM垃圾收集机制较好,也是其性能高于其它两个JVM的关键原因。Intel ORP的即时编译较好,接近SJVM采用的自适应优化的算法,但垃圾收集表现较差,在测试中,一些Benchmark的程序未能正确运行,其语言支持不好。
3) Kaffe的性能表现比较差,主要原因是由于即时编译较差,同时垃圾收集机制的算法也较粗糙。
3 结语
JIT 编译和垃圾收集模块是 JVM 中影响性能的关键模块。JIT 编译的实现与体系结构的关系密切,实现时应充分考虑体系结构的影响,针对目标平台优化。垃圾收集机制的平台相关性较小,实现垃圾收集时,考虑较多的是算法上的提高。当然,不同平台上的内存管理机制还是有差别的,如不同平台上实现虚拟内存的方式、实现cache的方式都有可能不同,这也是提高一个特定平台上垃圾收集机制时需要考虑的因素。
![【Android】 No matching variant of com.android.tools.build:gradle:[版本号] was found](https://img-blog.csdnimg.cn/18061ff5584843479c428b044d21a99c.png#pic)

![[C++ 网络协议] 套接字的多种可选项](https://img-blog.csdnimg.cn/990901890efe4f7a99bc6b110d4864ec.png)




![[MyBatis系列④]核心配置文件](https://img-blog.csdnimg.cn/bc3e9339d22f48d6a744edface62c793.png)