文章目录
- 1.基本语法
- 2. EXPLAIN各列作用
- 1. table
- 2. id
- 3. select_type
- 4. partitions
- 5. type
1.基本语法
EXPLAIN SELECT select_options
#或者
DESCRIBE SELECT select_options
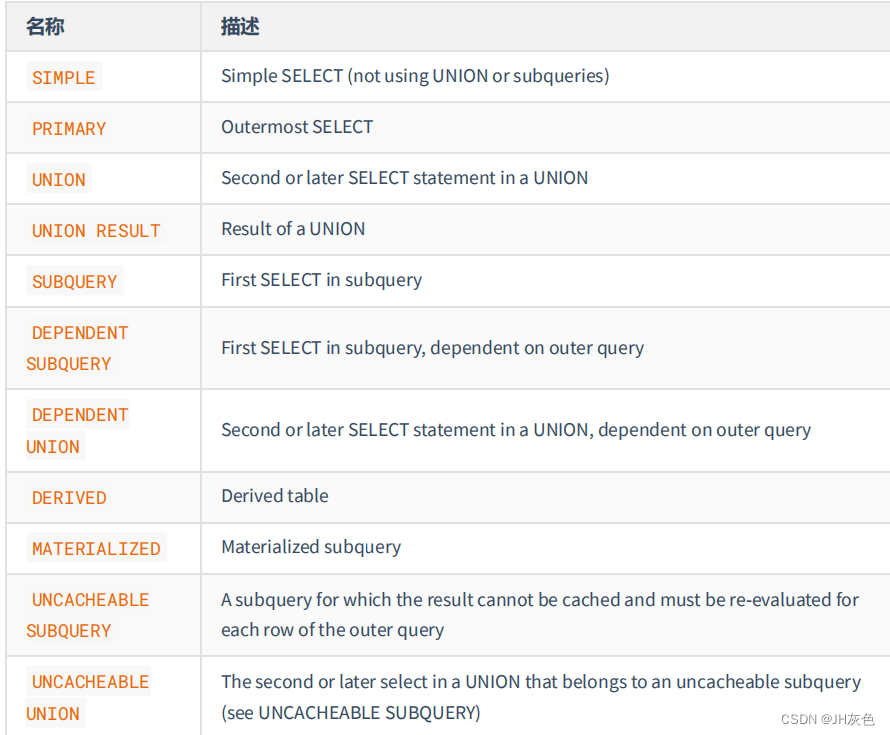
EXPLAIN 语句输出的各个列的作用如下:
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个SELECT关键字都对应一个唯一的id |
| select_type | SELECT关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
2. EXPLAIN各列作用
建表
CREATETABLEs1(idINTAUTO_INCREMENT,key1VARCHAR(100),key2INT,key3VARCHAR(100),key_part1VARCHAR(100),key_part2VARCHAR(100),key_part3VARCHAR(100),common_fieldVARCHAR(100),PRIMARYKEY(id),INDEXidx_key1(key1),UNIQUEINDEXidx_key2(key2), INDEXidx_key3(key3),INDEX idx_key_part(key_part1,key_part2,key_part3)) ENGINE=INNODBCHARSET=utf8;
CREATETABLEs2(idINTAUTO_INCREMENT,key1VARCHAR(100),key2INT,key3VARCHAR(100),key_part1VARCHAR(100),key_part2VARCHAR(100),key_part3VARCHAR(100),common_fieldVARCHAR(100), PRIMARYKEY(id),INDEXidx_key1(key1),UNIQUEINDEXidx_key2(key2),INDEXidx_key3(key3),INDEX idx_key_part(key_part1,key_part2,key_part3)) ENGINE=INNODBCHARSET=utf8;
1. table
不论我们的查询语句有多复杂,包含了多少个表 ,到最后也是需要对每个表进行单表访问的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
2. id
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字,比如下边这个查询语句:
SELECT * FROM s1 WHERE key1 = 'a';
稍微复杂一点的连接查询中也只有一个 SELECT 关键字,比如:
SELECT * FROM s1 INNER JOIN s2
ON s1.key1 = s2.key1
WHERE s1.common_field = 'a';
查询语句中每出现一个SELECT关键字,设计 MySQL的大叔就会为它分配一个唯一的id值,这个 id 值就是EXPLAIN输出的第一列,比如下面查询中只有一个SELECT关键字,所以EXPLAIN结果中也就只有一条id 列为1的记录.
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';


mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2;

对于包含子查询的查询语句来说,就可能涉及多个 SELECT 关键字.所以在包含子查询的查询语句的执行计划中,每个 SELECT 关键字都会对应一个唯一的id值:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a';

查询优化器可能对涉及子查询的查询语句进行重写,从而转换为连接
查询(当然这里指的是半连接),所以这里的id值相同:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field
= 'a');

mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;


mysql> EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;

MYSQL5.6 以及之前的版本中,执行UNION ALL语句可能也会用到临时表。
小结:
- id如果相同,可以认为是一组,从上往下顺序执行
- 在所有组中,id值越大,优先级越高,越先执行
- 关注点:id号每个号码,表示一趟独立的查询,一个sql的查询趟数越少越好
3. select_type
(1) SIMPLE:查询语句中不包含 UNION 或者子查询的查询都算SIMPLE类型。

(2)PRIMARY:对于包含 UNION或UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其中最左边那个查询的 select_type 值就是 PRIMARY。
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;

(3) UNION:对于包含 UNION或UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其余小查询的 select_type 值就 UNION。
(4) UNION RESULT:MySQL 选择使用临时表来完成 UNION 查询的去重工作,针对该临时表的查询的 select_type 就是 UNION RESULT,前文有。
(5) SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询是不相关子查询,而且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT 关键字代表的那个查询的 select_type 就是SUBQUERY。

(6) DEPENDENT SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询被查询优化器转换为相关子查询的形式,该子查询的第一个SELECT 关键字代表的那个查询的 select_type就是DEPENDENT SUBQUERY。
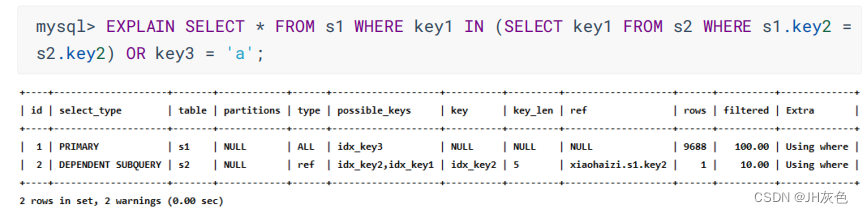
(7) DEPENDENT UNION:在包含 UNION 或者 UNION ALL 的大查询中 ,如果各个小查询都依赖于外层查询,则除了最左边的那个小查询之外 ,其余小查询的 select_type值就是 DEPENDENT UNlON。

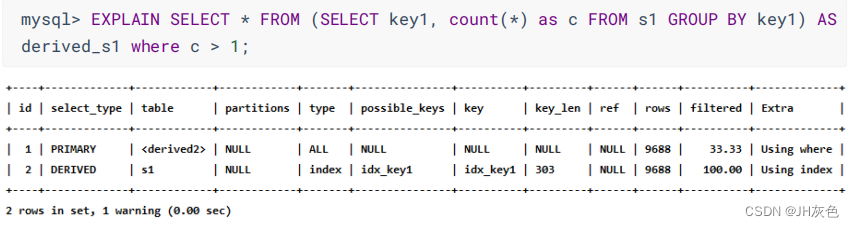
(8) DERIVED:在包含派生表的查询中,如果是以物化派生表的方式执行查询,则派生表对应的子查询的 select_type 就是 DERIVED。
(9) MATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询 ,该子查询对应的select_type 属性就是 MATERlALIZED。

(10) UNCACHEABLE SUBQUERY
(11) UNCACHEABLE UNION
4. partitions
-- 创建分区表,
-- 按照id分区,id<100 p0分区,其他p1分区
CREATE TABLE user_partitions (id INT auto_increment,
NAME VARCHAR(12),PRIMARY KEY(id))
PARTITION BY RANGE(id)(
PARTITION p0 VALUES less than(100),
PARTITION p1 VALUES less than MAXVALUE
);
DESC SELECT * FROM user_partitions WHERE id>200;
查询id大于200(200>100,p1分区)的记录,查看执行计划,partitions是p1,符合我们的分区规则

5. type
完整的访问方法如下: system , const , eq_ref , ref , fulltext , ref_or_null ,index_merge , unique_subquery , index_subquery , range , index , ALL 。
(1) system:当表中只有一条记录并且该表使用的存储引攀 (比如 MyISAM MEMORY)的统计数据是精确的, 那么对该表的访问方法就是 system。

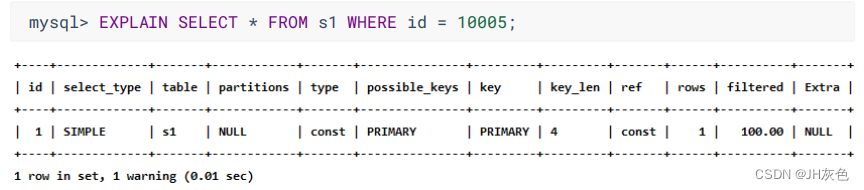
(2) const:我们根据主键或者唯一二级索引列与常数进行等值匹配
时, 对单表的访问方法就是 const。
(3) eq_ref:执行连接查询时,如果被驱动表是通过主键或者不允许存储 NULL 值的唯一二级索引列等值匹配的方式进行访问的(如果该主键或者不允许存储 NULL值的唯一二级索引是联合索引,则所有的索引列都必须进行等值比较) 。则对该被驱动表的访问方法就是eq_ref 。
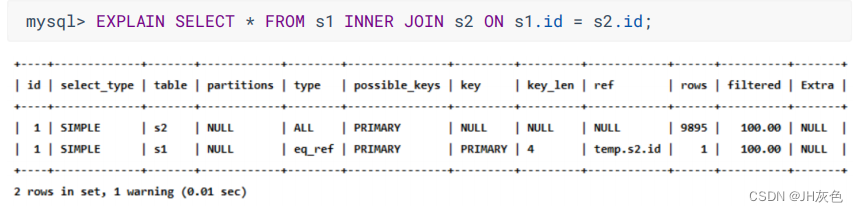
从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
(4) ref:当通过普通的二级索引列与常量进行等值匹配的方式查询某个表时,对该表的访问方法就可能是ref。

(5) fulltext:全文索引
(6):ref_or_null:当对普通的二级索引列进行等值匹配且该索引列的值也可以是NULL值时,对该表的访问方法就可能是ref_or_null。

(7) index_merge:索引合并
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

(8) unique_subquery:类似于两表连接中被驱动表的eq_ref访问方法,unique_subquery针对的是一些包含IN子查询的查询语句。如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询在转换之后可以使用主键或者不允许存储 NULL值的唯一二级索引进行等值匹配, 那么 type 列的值就是 unique_subquery。








![[PyTorch][chapter 51][Auto-Encoder -1]](https://img-blog.csdnimg.cn/ad287288c7c942129815f6fced4716db.png)