🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。
🏆本文已收录于PHP专栏:MySQL的100个知识点。
🎉欢迎 👍点赞✍评论⭐收藏
文章目录
- 🚀一、前言
- 🚀二、三大范式
- 🔎2.1 第一范式
- 🔎2.2 第二范式
- 🔎2.3 第三范式
- 🚀三、反范式
- 🔎3.1 数据冗余
- 🔎3.2 性能问题
- 🔎3.3 设计复杂度
- 🚀四、总结
🚀一、前言
数据库三大范式是指关系型数据库设计中的三个基本规范,分别为第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
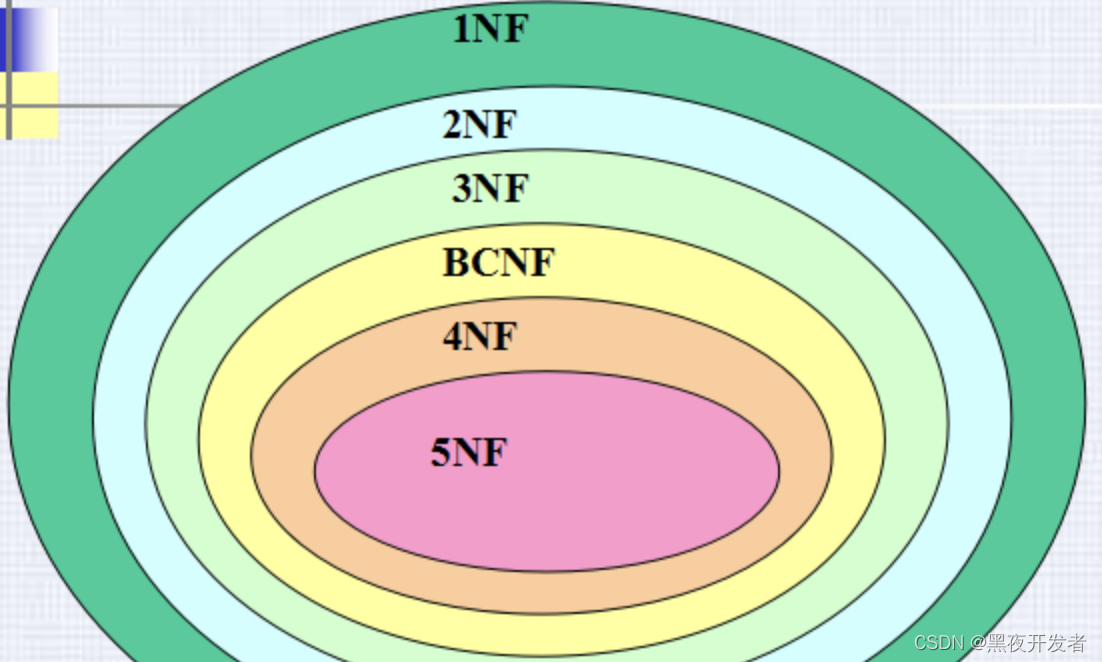
🚀二、三大范式
🔎2.1 第一范式
第一范式(1NF)要求表中的每个字段都不可再分,即每个字段只能保存单一值。同时,每个字段必须有一个唯一的名称,并且在表中的每一行中都必须有一个唯一标识字段(主键)。1NF的核心概念是原子性。
以订单表为例,我们可以设计如下的表结构:
| 订单编号 | 客户编号 | 订单日期 |
|---|---|---|
| 001 | 1001 | 2021-01-01 |
| 002 | 1002 | 2021-02-05 |
| 003 | 1001 | 2021-03-10 |
在这个表中,每一列都是原子的,符合第一范式。
🔎2.2 第二范式
第二范式(2NF)对于满足1NF的表,要求所有非主键字段必须完全依赖于主键。也就是说,如果一个表中存在复合主键,那么每个非主键字段必须依赖于全部的主键,而不能只依赖于部分主键。2NF的核心概念是函数依赖。
我们继续以订单表为例,再设计一个商品表:
| 商品编号 | 商品名称 | 商品价格 |
|---|---|---|
| P001 | 商品A | 10.00 |
| P002 | 商品B | 20.00 |
| P003 | 商品C | 15.50 |
在商品表中,商品编号是主键,商品名称和商品价格完全依赖于商品编号,符合第二范式。
接下来,我们设计一个订单详情表来记录订单中的商品信息:
| 订单编号 | 商品编号 | 数量 |
|---|---|---|
| 001 | P001 | 5 |
| 002 | P002 | 2 |
| 003 | P001 | 3 |
在订单详情表中,订单编号和商品编号作为联合主键,而数量列只依赖于订单编号和商品编号,而不是部分依赖。因此,订单详情表符合第二范式。
🔎2.3 第三范式
第三范式(3NF)在满足2NF的基础上,要求所有非主键字段之间不能存在传递依赖关系。也就是说,如果一个非主键字段依赖于另一个非主键字段,那么这两个字段应该拆分成两个独立的表。3NF的核心概念是消除传递依赖。
| 学生表(students) | ||
|---|---|---|
| 字段 | 数据类型 | 约束 |
| 学生ID | int | 主键 |
| 姓名 | varchar | 非空 |
| 年龄 | int | 非空 |
| 性别 | varchar | 非空 |
| 课程表(courses) | ||
|---|---|---|
| 字段 | 数据类型 | 约束 |
| 课程ID | int | 主键 |
| 课程名称 | varchar | 非空 |
| 学分 | int | 非空 |
| 成绩表(grades) | ||
|---|---|---|
| 字段 | 数据类型 | 约束 |
| 学生ID | int | 外键(学生表) |
| 课程ID | int | 外键(课程表) |
| 分数 | int | 非空 |
上述表结构设计就是符合第三范式的。
🚀三、反范式
实际使用过程中,需要注意以下几个问题:
🔎3.1 数据冗余
范式化的数据库设计,可以尽可能地减少数据冗余,避免了数据的不一致和更新异常。但范式化的设计也可能导致查询时需要进行多表连接,影响查询性能。
🔎3.2 性能问题
范式化的数据库设计可能导致复杂的查询语句,对于大量数据的查询和处理可能性能较差。在实际应用中,需要根据具体情况进行性能优化,可以考虑使用反范式化来提高查询性能。
🔎3.3 设计复杂度
范式化的数据库设计可能会增加数据表的数量,使数据库结构变得复杂。在设计过程中需要权衡范式化的好处和复杂性,并根据实际需求做出适当的选择。
为了解决上述问题,有时候需要采用反范式化的设计方法。反范式化是指有意地将数据冗余存储在数据库中,以提高查询性能或简化数据模型。以下是一个反范式化设计的例子:
假设有一个订单管理系统,包括订单表(Order)和产品表(Product)。原始的范式化设计如下:
Order表:
| 订单ID(主键) | 订单日期 | 产品ID(外键) | 数量 |
|---|---|---|---|
| 1 | 2020-01-01 | 1 | 10 |
| 2 | 2020-01-02 | 2 | 5 |
Product表:
| 产品ID(主键) | 产品名称 |
|---|---|
| 1 | 电视 |
| 2 | 冰箱 |
在这种设计中,每个订单记录只存储了产品ID,需要通过外键关联到产品表来获取产品名称。当进行查询时,可能需要进行多表连接,影响查询性能。
为了提高查询性能,在反范式化设计中可以将产品名称冗余存储在订单表中:
Order表:
| 订单ID(主键) | 订单日期 | 产品ID(外键) | 产品名称 | 数量 |
|---|---|---|---|---|
| 1 | 2020-01-01 | 1 | 电视 | 10 |
| 2 | 2020-01-02 | 2 | 冰箱 | 5 |
这样,在查询订单时不再需要进行多表连接,可以直接从订单表中获取产品名称,提高查询性能。但同时也增加了数据冗余,需要在更新订单时保持冗余数据的一致性。
🚀四、总结
总结起来,数据库的三大范式是关系型数据库设计中的基本规范,用于避免数据冗余、更新异常和数据不一致。在实际应用中,需要根据具体情况进行范式化或反范式化的设计,权衡范式化的好处和复杂性,以及考虑查询性能和数据一致性的需求。

推荐您阅读本专栏其他内容,MySQL的100个知识点,相信不会让您失望。如果你对上面的功能有疑问,随时欢迎与我交流。