YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
0.引言
k折交叉验证(K-Fold
Cross-Validation)是一种在机器学习中常用的模型评估技术,用于估计模型的性能和泛化能力。它的主要作用是在有限的数据集上对模型进行评估,以便更准确地了解模型在新数据上的表现。K折交叉验证的基本思想是将原始数据集分成K个子集(折),然后依次将每个子集作为验证集,其他K-1个子集作为训练集,进行K次训练和验证。每次验证后,计算模型在验证集上的性能指标,如准确率、精确率、召回率等。最后,将K次验证的性能指标平均,作为模型在整个数据集上的性能估计。
K折交叉验证的作用包括:
- 模型性能评估: K折交叉验证可以更准确地评估模型在数据集上的性能,避免因数据分布不均匀而导致评估结果不准确的问题。
- 泛化能力估计: 通过在不同的训练集和验证集上进行多次评估,可以更好地估计模型的泛化能力,即模型在新数据上的表现。
- 减少过拟合: K折交叉验证可以帮助检测模型是否出现过拟合问题。如果模型在训练集上表现很好,但在验证集上表现较差,可能存在过拟合。
- 参数调优: 在每一轮交叉验证中,可以使用不同的参数设置来训练模型,以找到在验证集上表现最好的参数组合。
- 数据利用率: K折交叉验证充分利用了数据集中的所有样本,因为每个样本都会在不同的折中被用作训练和验证。
总之,K折交叉验证是一种有助于评估和改进模型性能的重要技术,尤其在数据有限的情况下,它能更准确地估计模型在新数据上的表现。

1.数据准备
使用交叉验证前,需要把数据准备为yolo格式,不知道如何数据准备的朋友可以看下这篇文章:YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等
.
├── ./data
│ ├── ./data/Annotations
│ │ ├── ./data/Annotations/fall_0.xml
│ │ ├── ./data/Annotations/fall_1000.xml
│ │ ├── ./data/Annotations/fall_1001.xml
│ │ ├── ./data/Annotations/fall_1002.xml
│ │ ├── ./data/Annotations/fall_1003.xml
│ │ ├── ./data/Annotations/fall_1004.xml
│ │ ├── …
│ ├── ./data/images
│ │ ├── ./data/images/fall_0.jpg
│ │ ├── ./data/images/fall_1000.jpg
│ │ ├── ./data/images/fall_1001.jpg
│ │ ├── ./data/images/fall_1002.jpg
│ │ ├── ./data/images/fall_1003.jpg
│ │ ├── ./data/images/fall_1004.jpg
│ │ ├── …
│ ├── ./data/ImageSets
│ └── ./data/labels
│ │ ├── ./data/images/fall_0.txt
│ │ ├── ./data/images/fall_1000.txt
│ │ ├── ./data/images/fall_1001.txt
│ │ ├── ./data/images/fall_1002.txt
│ │ ├── ./data/images/fall_1003.txt
│ │ ├── ./data/images/fall_1004.txt
│ ├── ./data/classes.yaml
其中,特别要注意的一点是,需要新建个classes.yaml的文件,然后将自己的标签按序填写,如下所示:
names:0: your_label_11: your_label_2
2.代码准备
下面代码可以什么都不用改直接运行,前提是按我的数据格式,这个代码放在data的上层目录中
import datetime
import shutil
from pathlib import Path
from collections import Counter
import osimport yaml
import numpy as np
import pandas as pd
from ultralytics import YOLO
from sklearn.model_selection import KFold# 定义数据集路径
dataset_path = Path('./data') # 替换成你的数据集路径# 获取所有标签文件的列表
labels = sorted(dataset_path.rglob("*labels/*.txt")) # 所有标签文件在'labels'目录中# 获取当前文件的绝对路径
current_file_path = os.path.abspath(__file__)# 获取当前文件所在的文件夹路径(即当前文件的根目录)
root_directory = os.path.dirname(current_file_path)print("当前文件运行根目录:", root_directory)# 从YAML文件加载类名
yaml_file = 'data/classes.yaml'
with open(yaml_file, 'r', encoding="utf8") as y:classes = yaml.safe_load(y)['names']
cls_idx = sorted(classes.keys())# 创建DataFrame来存储每张图像的标签计数
indx = [l.stem for l in labels] # 使用基本文件名作为ID(无扩展名)
labels_df = pd.DataFrame([], columns=cls_idx, index=indx)# 计算每张图像的标签计数
for label in labels:lbl_counter = Counter()with open(label, 'r') as lf:lines = lf.readlines()for l in lines:# YOLO标签使用每行的第一个位置的整数作为类别lbl_counter[int(l.split(' ')[0])] += 1labels_df.loc[label.stem] = lbl_counter# 用0.0替换NaN值
labels_df = labels_df.fillna(0.0)# 使用K-Fold交叉验证拆分数据集
ksplit = 5
kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # 设置random_state以获得可重复的结果
kfolds = list(kf.split(labels_df))
folds = [f'split_{n}' for n in range(1, ksplit + 1)]
folds_df = pd.DataFrame(index=indx, columns=folds)# 为每个折叠分配图像到训练集或验证集
for idx, (train, val) in enumerate(kfolds, start=1):folds_df[f'split_{idx}'].loc[labels_df.iloc[train].index] = 'train'folds_df[f'split_{idx}'].loc[labels_df.iloc[val].index] = 'val'# 计算每个折叠的标签分布比例
fold_lbl_distrb = pd.DataFrame(index=folds, columns=cls_idx)
for n, (train_indices, val_indices) in enumerate(kfolds, start=1):train_totals = labels_df.iloc[train_indices].sum()val_totals = labels_df.iloc[val_indices].sum()# 为避免分母为零,向分母添加一个小值(1E-7)ratio = val_totals / (train_totals + 1E-7)fold_lbl_distrb.loc[f'split_{n}'] = ratio# 创建目录以保存分割后的数据集
save_path = Path(dataset_path / f'{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val')
save_path.mkdir(parents=True, exist_ok=True)# 获取图像文件列表
images = sorted((dataset_path / 'images').rglob("*.jpg")) # 更改文件扩展名以匹配你的数据
ds_yamls = []# 循环遍历每个折叠并复制图像和标签
for split in folds_df.columns:# 为每个折叠创建目录split_dir = save_path / splitsplit_dir.mkdir(parents=True, exist_ok=True)(split_dir / 'train' / 'images').mkdir(parents=True, exist_ok=True)(split_dir / 'train' / 'labels').mkdir(parents=True, exist_ok=True)(split_dir / 'val' / 'images').mkdir(parents=True, exist_ok=True)(split_dir / 'val' / 'labels').mkdir(parents=True, exist_ok=True)# 创建数据集的YAML文件dataset_yaml = split_dir / f'{split}_dataset.yaml'ds_yamls.append(dataset_yaml.as_posix())split_dir = os.path.join(root_directory, split_dir.as_posix())with open(dataset_yaml, 'w') as ds_y:yaml.safe_dump({'path': split_dir,'train': 'train','val': 'val','names': classes}, ds_y)
print(ds_yamls)# 将文件路径保存到一个txt文件中
with open('data/file_paths.txt', 'w') as f:for path in ds_yamls:f.write(path + '\n')# 为每个折叠复制图像和标签到相应的目录
for image, label in zip(images, labels):for split, k_split in folds_df.loc[image.stem].items():# 目标目录img_to_path = save_path / split / k_split / 'images'lbl_to_path = save_path / split / k_split / 'labels'# 将图像和标签文件复制到新目录中# 如果文件已存在,可能会抛出SamefileErrorshutil.copy(image, img_to_path / image.name)shutil.copy(label, lbl_to_path / label.name)
运行代码后,会在data目录下生成一个文件夹,里面有5种不同划分的数据集
3.开始训练
下面的代码放在和上面代码的同级目录中,训练参数可以根据自己情况进行调整
from ultralytics import YOLOweights_path = 'checkpoints/yolov8s.pt'
model = YOLO(weights_path, task='train')
ksplit = 5
# 从文本文件中加载内容并存储到一个列表中
ds_yamls = []
with open('data/file_paths.txt', 'r') as f:for line in f:# 去除每行末尾的换行符line = line.strip()ds_yamls.append(line)# 打印加载的文件路径列表
print(ds_yamls)results = {}
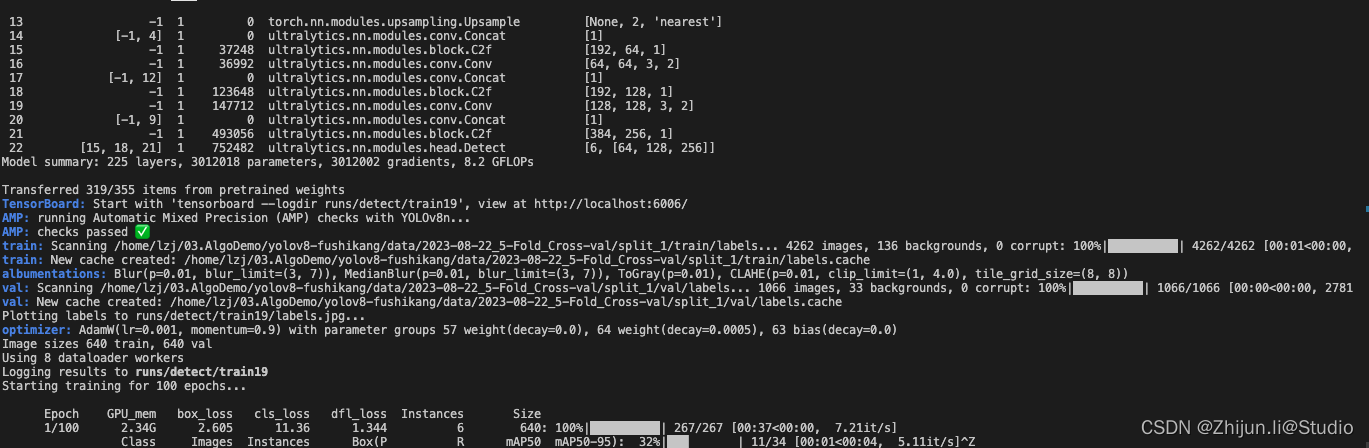
for k in range(ksplit):dataset_yaml = ds_yamls[k]model.train(data=dataset_yaml, batch=6, epochs=2, imgsz=1280, device=0, workers=8, single_cls=False, )
![[机缘参悟-102] :IT人 - 管理的本质?管理人与从事技术的本质区别?人性、冰山模型、需求层次模型](https://img-blog.csdnimg.cn/img_convert/55062531d0dd55093c68b5d2873400ee.jpeg)




![[Open-source tool] 可搭配PHP和SQL的表單開源工具_Form tools(1):簡介和建置](https://img-blog.csdnimg.cn/6c0dc324998d48569a9eb692f8576296.png)

![Vue3 [Day11]](https://img-blog.csdnimg.cn/454dfbf535164b378fb15c4f22c78773.png)