一、首先在VM创建一个新的虚拟机将Docker安装好
-
更新系统:首先打开终端,更新系统包列表。
sudo apt-get update sudo apt-get upgrade下图是更新系统包截图
-
安装Docker:使用以下命令在Linux上安装Docker。
sudo apt-get install -y docker.io
-
启动Docker服务:使用以下命令启动Docker服务,我们通过ps命令可以看到docker服务的进程
sudo systemctl start docker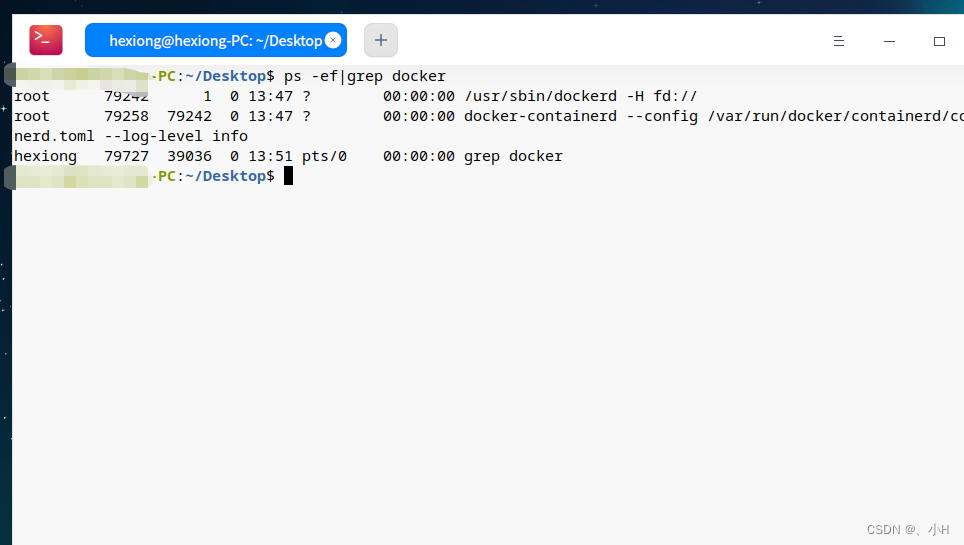
-
使Docker开机自启:使用以下命令将Docker服务添加到系统服务中,使其在系统启动时自动启动。
sudo systemctl enable docker -
验证Docker是否安装成功:使用以下命令检查Docker是否成功安装。
docker version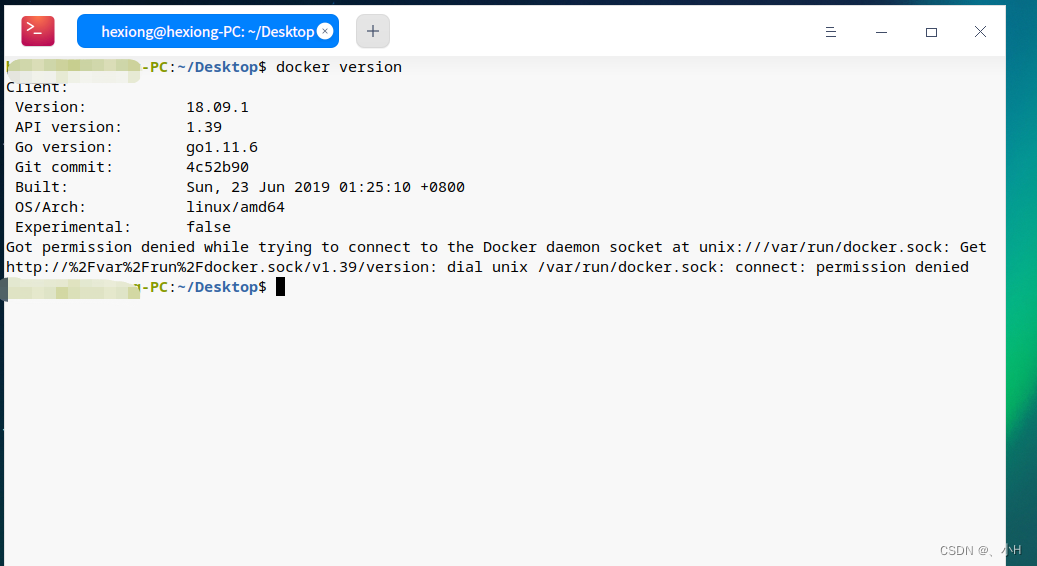
-
添加当前用户到Docker用户组:为了避免在执行Docker命令时使用sudo,可以将当前用户添加到Docker用户组中。
sudo usermod -aG docker <username>其中“<username>”是您的用户名。

-
退出当前会话并重新登录:要使更改生效,退出当前会话并重新登录。
# 要退出当前 Docker 会话并重新登录,可以使用以下命令:exit# 然后再使用以下命令重新登录:docker login# 这将提示您输入 Docker Hub 用户名和密码,以便重新登录。
现在您已经成功在Linux上安装了Docker容器。您可以使用docker run命令来启动新容器
二、在Docker中安装Hive(非Docker Compose 方式)
-
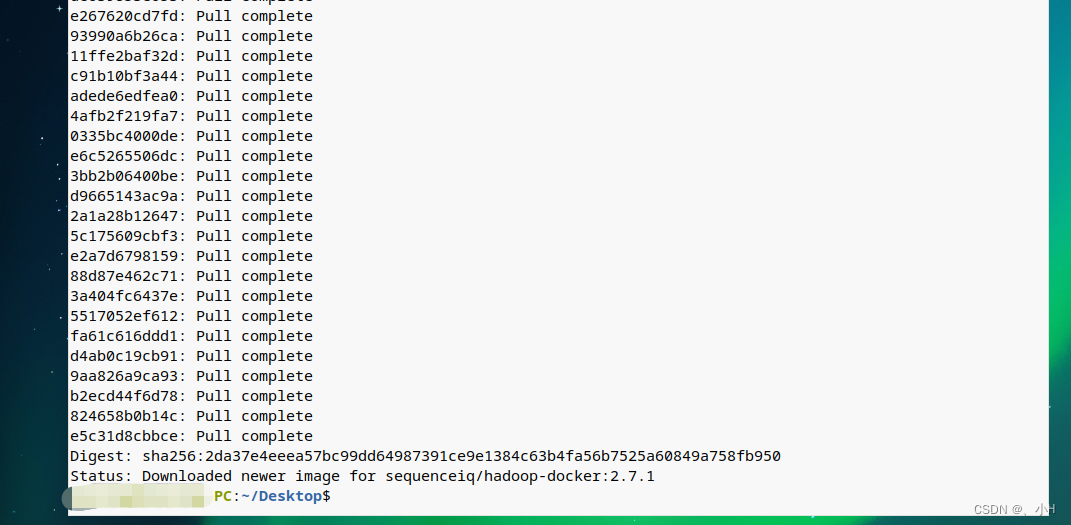
确保已安装和启动Docker后,打开终端并输入以下命令以下载Hive镜像:
docker pull sequenceiq/hadoop-docker:2.7.1
下图是下载 hadoop容器截图
- 等待hadoop镜像下载完成后,输入以下命令以启动Hive容器:
docker run -it sequenceiq/hadoop-docker:2.7.1 /etc/bootstrap.sh -bash## 以下是 释义
docker run -it sequenceiq/hadoop-docker:2.7.1 /etc/bootstrap.sh -bash 命令的意思是,在当前系统上启动一个新的 Docker 容器,使用指定的镜像 sequenceiq/hadoop-docker:2.7.1,然后运行 /etc/bootstrap.sh 脚本来配置 Hadoop,最后打开一个交互式的 Bash shell。让我们详细解释一下这个命令的各个部分:docker run:这是 Docker 命令来启动一个新的容器。
-it:这是两个选项。-i 表示交互式会话,-t 表示为终端提供伪终端。这两个选项结合起来意味着提供一个可以交互的终端。
sequenceiq/hadoop-docker:2.7.1:这是要使用的 Docker 镜像的名称和版本号。在这个例子中,我们使用的是名为 sequenceiq/hadoop-docker 的镜像,版本为 2.7.1。
/etc/bootstrap.sh -bash:这是在容器启动时要运行的命令。在这个例子中,我们首先运行 /etc/bootstrap.sh 脚本来配置 Hadoop,然后运行 -bash 进入交互式的 Bash shell。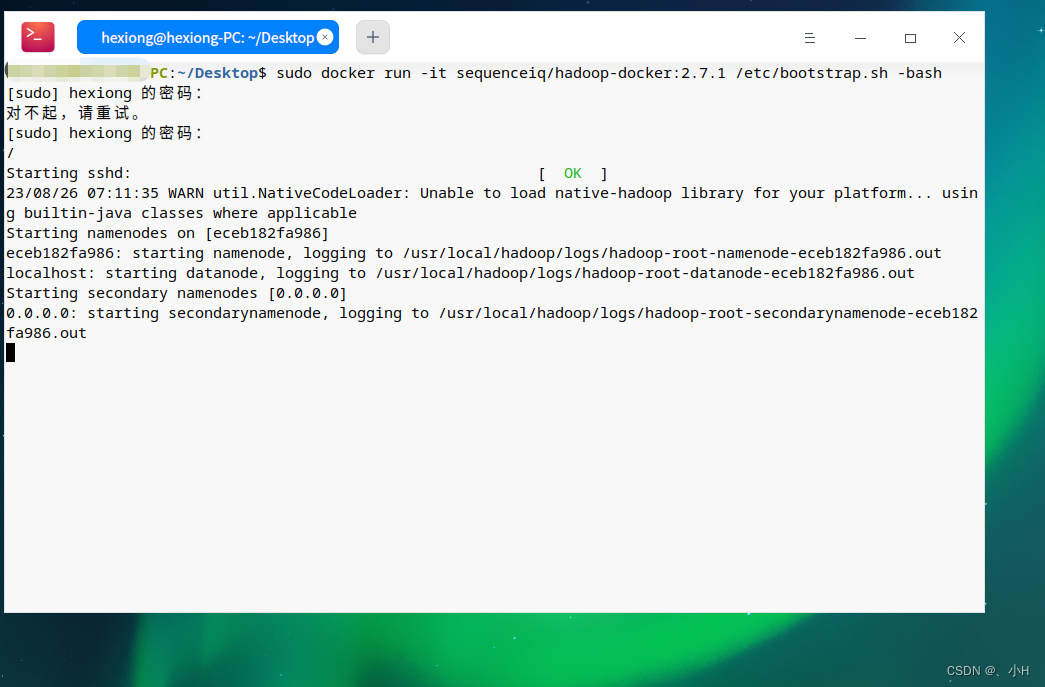
推出hadoop,以下方式启动hadoop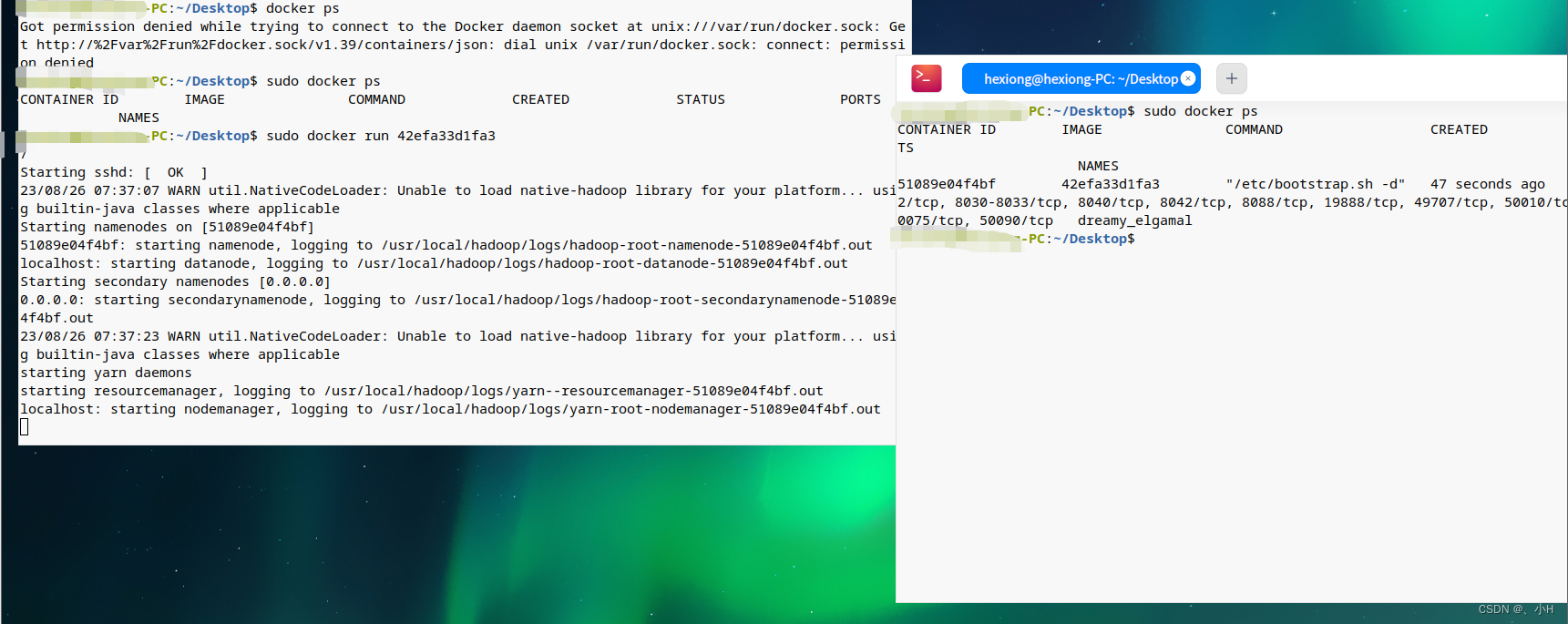
- 进入容器后,输入以下命令以安装Hive:
yum install -y hive
- 安装完成后,您可以使用以下命令启动Hive:
hive
- 接下来,您可以使用Hive进行数据分析和查询。
请注意,在这个过程中,您需要了解Docker的基本使用方法和Hadoop生态系统的基本知识。