作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
数仓
- **作者前言**
- 什么是数仓
- 数仓分层
- 数仓类型
- 数仓规范
- 数据走向
什么是数仓
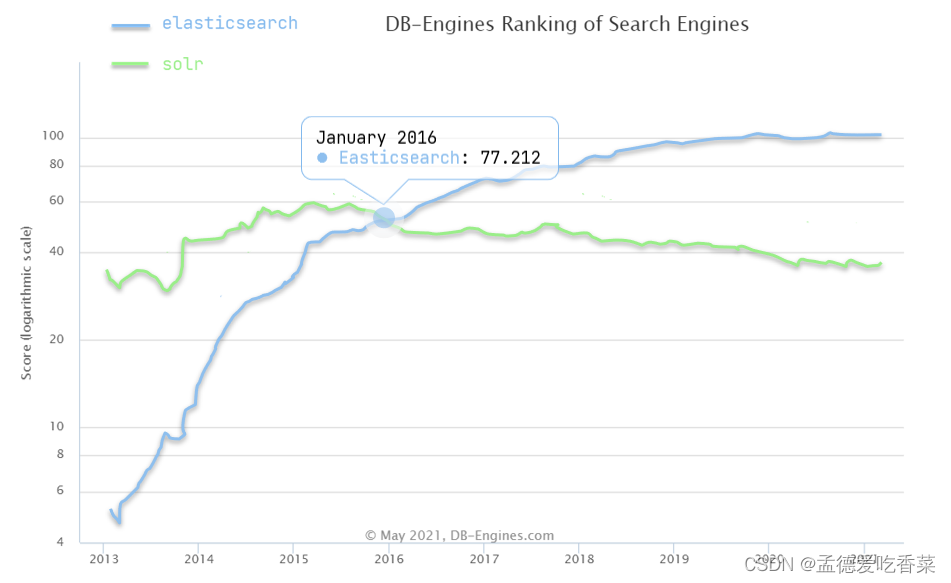
数仓,又称为数据仓库,是一个存放数据的仓库。这些数据需要按照一些结构、规则来组织和存放。作为数据基础,不仅需要满足基础数据的提供,也要允许经过需求计算之后的数据支持。数仓是一套体系,整合了多种技术,为某个项目或团体实现数据支持。
数仓工程师(数仓开发工程师),更加偏向业务与建模思维的结合。对整体的需求框架有清晰的认识,在保证阶段性数据成果的前提下,还能为以后的业务拓展留有空间。不仅需要对当前的数据任务做出判断,也需要紧跟项目发展。随着数据量的增大,同样需要对数仓环境进行升级优化,例如变更计算引擎、迁移数据库、分仓管理运行脚本等等。
我们可以想象一下,一个仓库里面有许多的小地方,存放不同的东西,数仓就相当于一个仓库,不同的数据存放在不同的地方,如果我们要找到某些数据还要知道在哪个地方,这就要求我们要标明类型了
数仓分层
集群:物理层架构
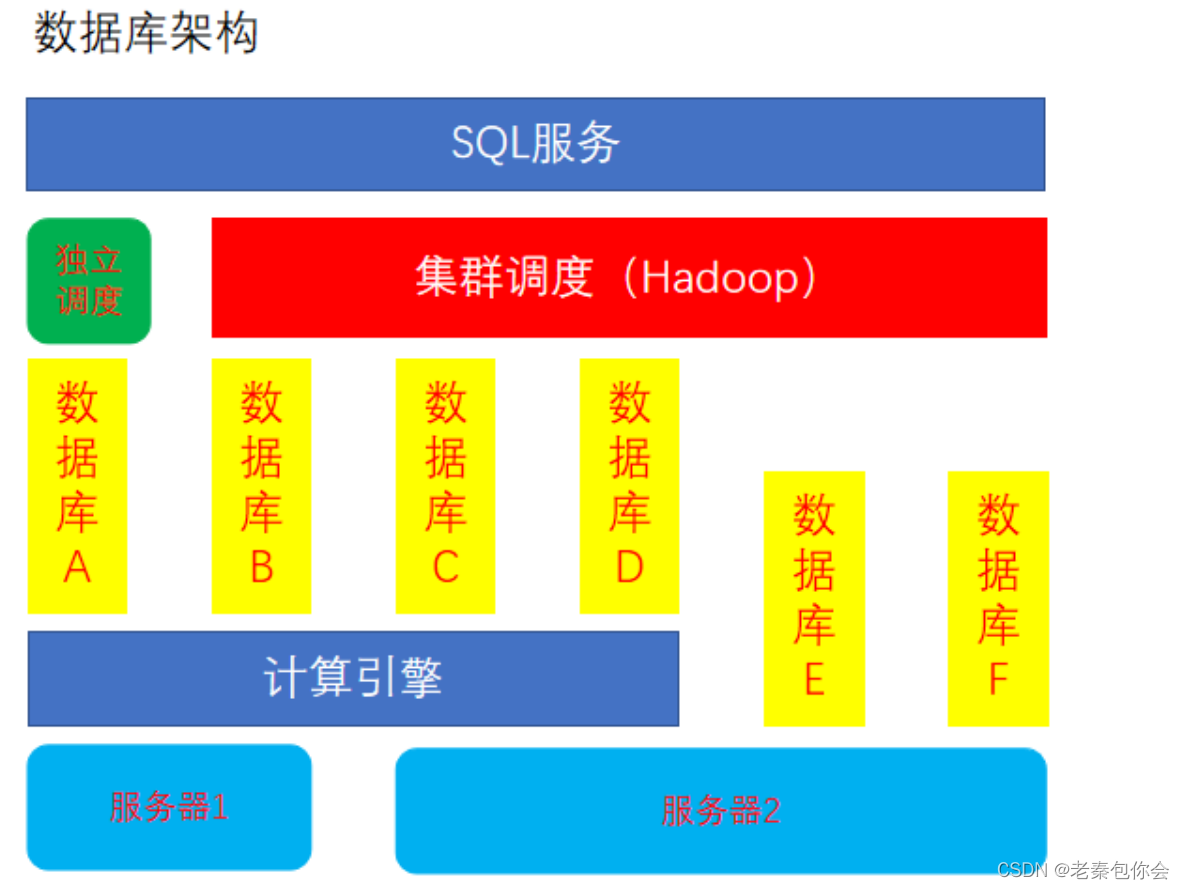
我们虚拟机的就相当于是下面一部分
原理就是我们通过客户端输入sql语句,传递到sql服务,然后具体化调度,让调度在数据库里面找数据,并返回,
计算引擎就是我们的cpu和内存,而我们虚拟机的计算引擎就是我们电脑里面的计算引擎

1、数据库一定是搭建在服务器上,专门的数据库服务器上只会搭建一个数据库
2、计算引擎是搭建在服务器上的,引擎不随调度使用,只用于对应的数据库
3、调度即为调用数据的工具,集群调度是将多个数据库统一管理,但数据库任然是单独运行的
简单的说就是两台服务器的连接要通过集群调度来连接,进行统一的调度
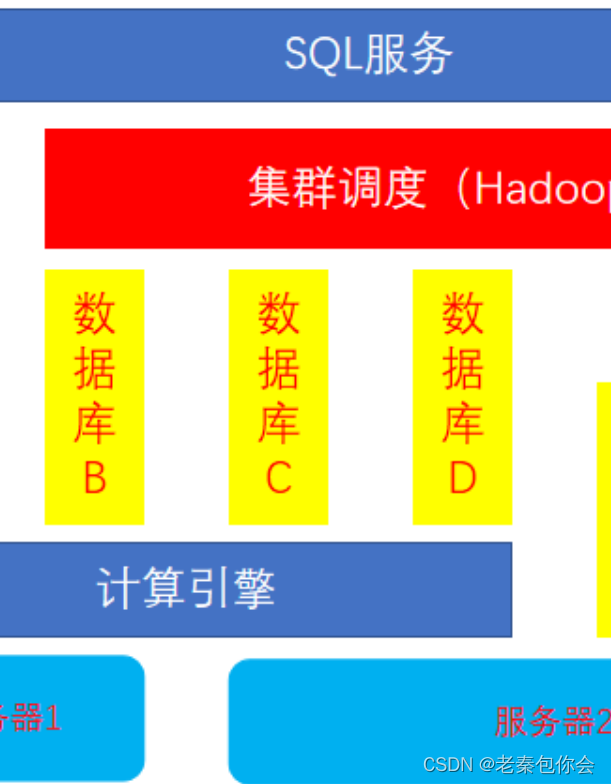
计算引擎我们还可以理解为是一台独立的服务器,使用其的cpu和内存,进行计算不会使用到服务器1和服务器2,这样就降低了这两个服务器的要求,这两个服务器只要保证能把数据调出去就可以了,至于怎么处理数据就看计算引擎了
4、可以通过统一的SQL服务操作不同调度的数据库,但是不能进行关联查询使用
5、数据库架构中的各个部分是允许单独替换的,在集群中,某一个数据库停止运行,并不会影响其他数据库的使用
总结:sql服务是可以控制多种调度,而调度可以控制数据库,而计算引擎和数据库是搭建在服务器上的,数据 的返回要通过计算引擎进行数据的计算返回
数仓类型
(逻辑层架构)
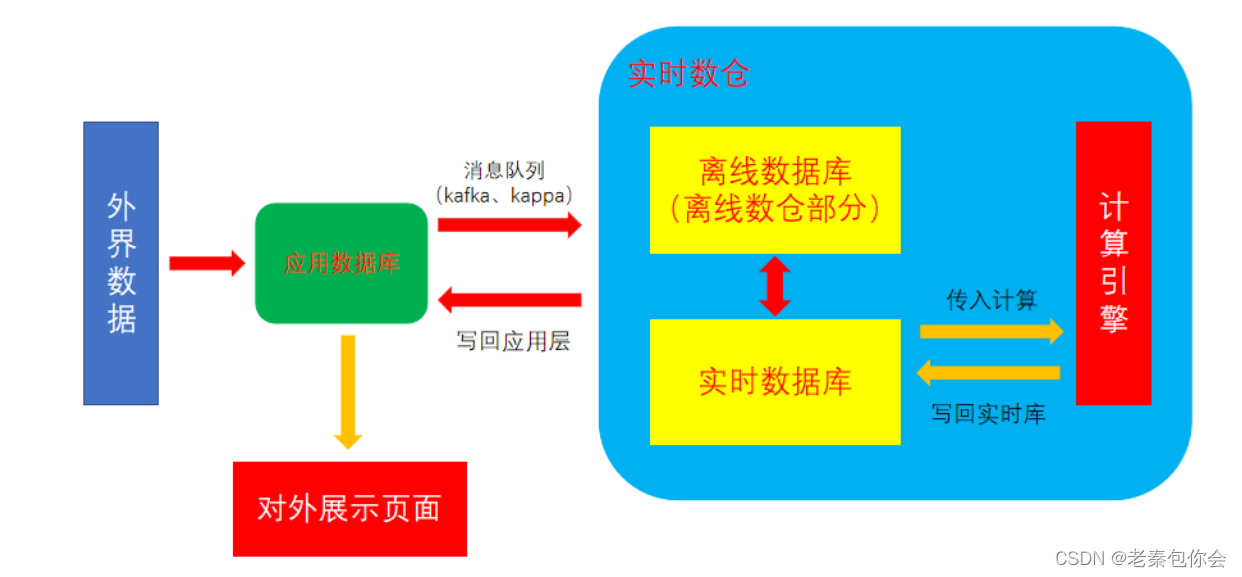
实时数仓: 通过即时返回的数据进行计算,不断更新数据库。好比是 mysql 中的视图,可以即时展现最新数据。
- 即时处理,不断增长的、基本无限的数据流,对应到有限的计算资源。通过引擎的快速计算并返回
- 无边界处理,持续的数据处理,针对每一次(每一个时间段)的新增数据进行合并计算
- 低延迟,因为计算引擎的强力,可以保证高频的数据更新
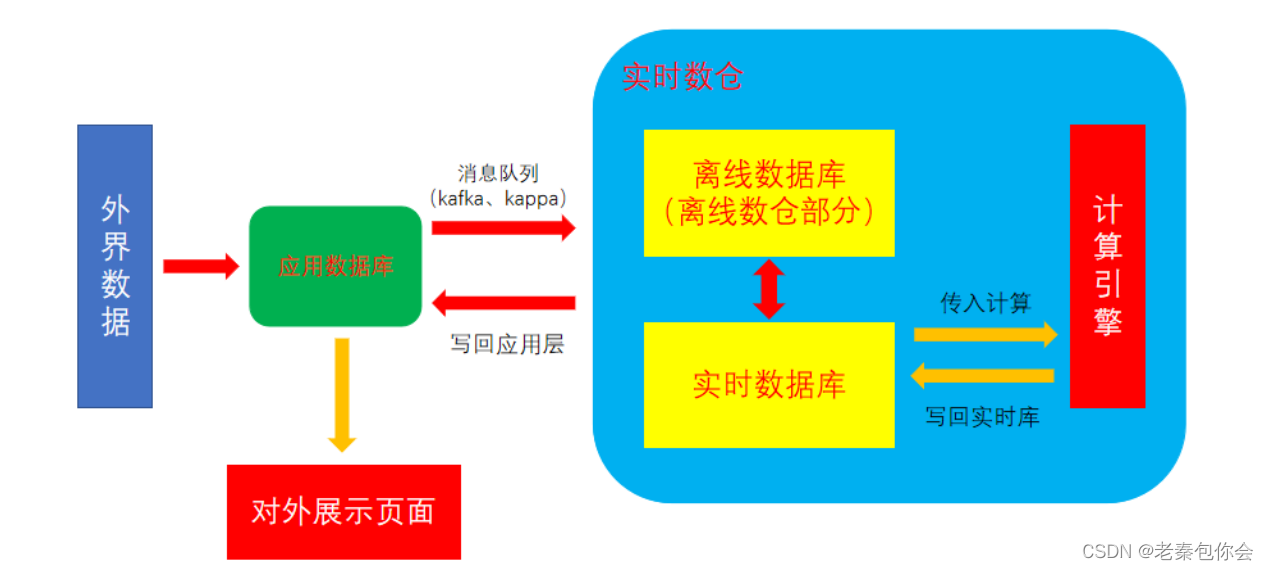
看到这里就会有一些小可爱不理解了,为啥离线数据库会存在,因为有一些数据不需要实时更新,如姓名和性别这些,这样就很节约性能,还有可以把计算好的数据进行和未计算的数据保存到离线数据库
计算引擎
现在主流的实时计算引擎有Blink、Flink、Kylin,能够一定程度支持快速计算的数据流引擎有Presto、Spark。
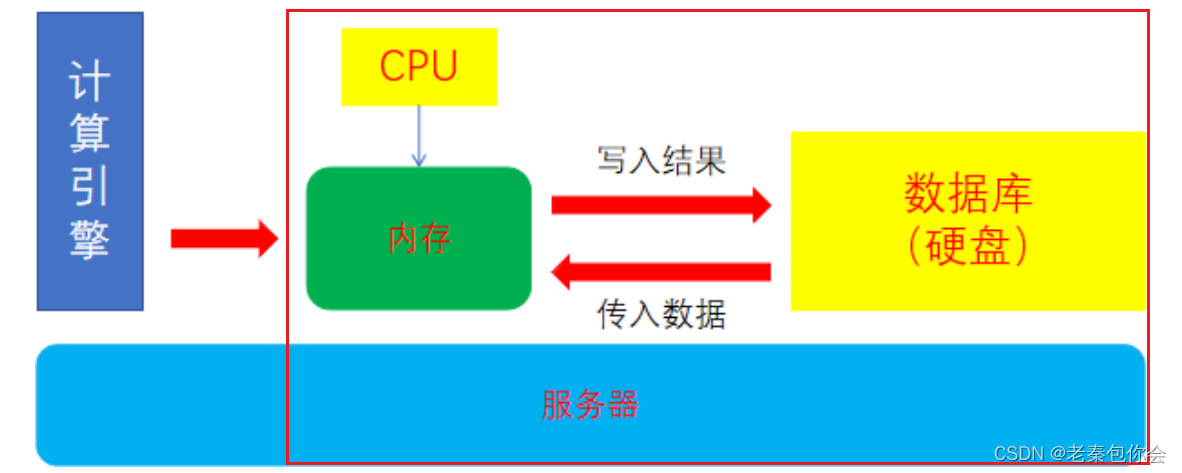
这里就是计算引擎的大致结构,计算引擎是搭建在服务器上的
数据流引擎
细心的小可爱就会发现数据流引擎是啥,我们先来讲讲我们通过写sql语句把数据拿出来给计算引擎,然后把计算好的数据写入到数据库,如果我们拿出来的数据用不到,计算完才会写入数据库,内存的使用量就增加了,而数据流引擎就是为此产生的,计算是发生在内存中的,数据流引擎会把需要用到的数据再过滤,不需要的数据就写回数据库,然后需要的数据传输到内存,这样内存的空间就会剩余很大
实时计算引擎
简单的说就是物理上缩短了硬盘和内存上的传递距离,还会在内存不够用的时,把硬盘转换成内存,内存空间就会变大,处理速度就会变快,比数据流引擎快
离线数仓:不需要实时计算的数仓环境,通常使用的数仓环境。即为通过将历史数据(一般为T+1的数据)计算好后,同意保存在数据库,在对外展示。
- 数据可靠,因为都是历史数据,只要SQL语句准确,不会出现计算的偏差。
- 环境友好,就如同是一般的数据库,搭建十分简单。不需要其他优化。
- 可控性强,即使SQL或者数据计算出错,同样有修改的时间
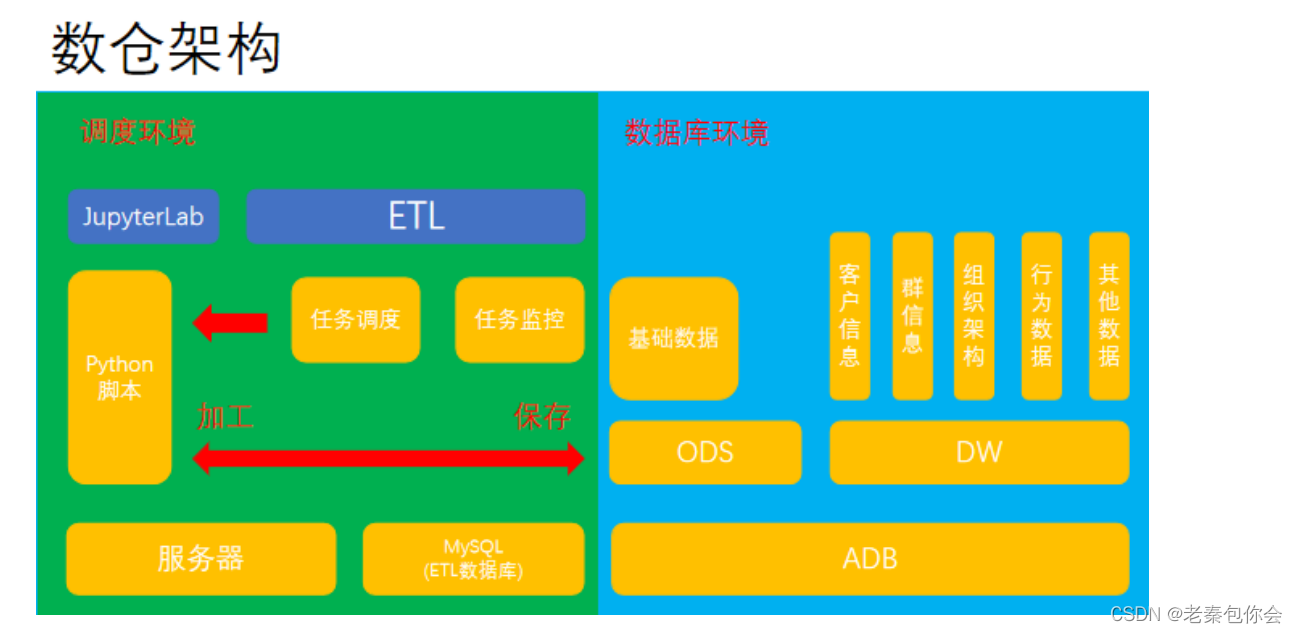
数据库环境
- 数据库:数仓的基本环境,包括数据库类型、计算引擎、单独的内存与CPU。这里的ADB是构建在阿里云上的数据库,是专门为阿里云使用者提供的大数据计算的数据库。小型企业或私人,通常会使用hive作为自己的数据库。一般作为数仓使用的数据库,服务器性能最低要求是8核CPU,16G内存和1T硬盘容量。
- ODS: 操作性数据。作为数据库到数据仓库的一种过渡,数据结构一般与数据来源保持一致,便于减少ETL的工作复杂性,且数据周期较短。
- DW:数据仓库。是结果数据,保存ODS过来的数据,允许报错数据,而且这些数据不会被修改。为分析性报告和决策支持而创建,对多样的业务数据进行筛选与整合。指导业务、改进流程,控制时间、成本、质量。
- 同等效果的还会有DM数据集市、DL数据湖,其本质都是对数据的进一步处理与分类。
简单的说就是ODS里面是基础数据,这里会原模原样的输入输出,不会更改,数据在调度环境里通过python代码进行操作并写入回来,保存到ODS,数据仓库拿到数据再进行一系列的操作等
调度环境
6. 服务器:这里的服务器更像是一个容器,承载了脚本和ETL的运行环境。如果牵扯到即时数据和大数据的计算与清洗,需要对服务器的内存和CPU性能有一定要求。一般作为调度环境的服务器,性能基本要求是8核CPU,16G内存和1T硬盘容量。
7. ETL数据库:一般为MySQL,因为通用性强。可以搭建在调度环境上,但不要和数仓在同一环境。
8. 编辑器:以Jupyter为例,本身没有特别限制。主要是针对运行脚本的语言,如果是shell或者其他,也可以使用VScode等其他编辑器进行调试。通常是将代码在编辑器中调试好后再考虑进行部署。
9. ETL:任务调度服务。只是一个服务,理论上可以使用Linux中的crontab进行替代(需要自己写关联)。主要作用是监视任务的运行情况和进程。通过调度已经正常运行的脚本,完成任务。
简单的说就是另起一台服务器用来搭建ETL和python脚本,ETL有一个mysql数据库,是属于他的,我们在jupyterLab里面写脚本,在ETL调度,从数据库环境里的基础数据读数据python代码进行一系列的操作,然后再写入数据库环境
数仓规范
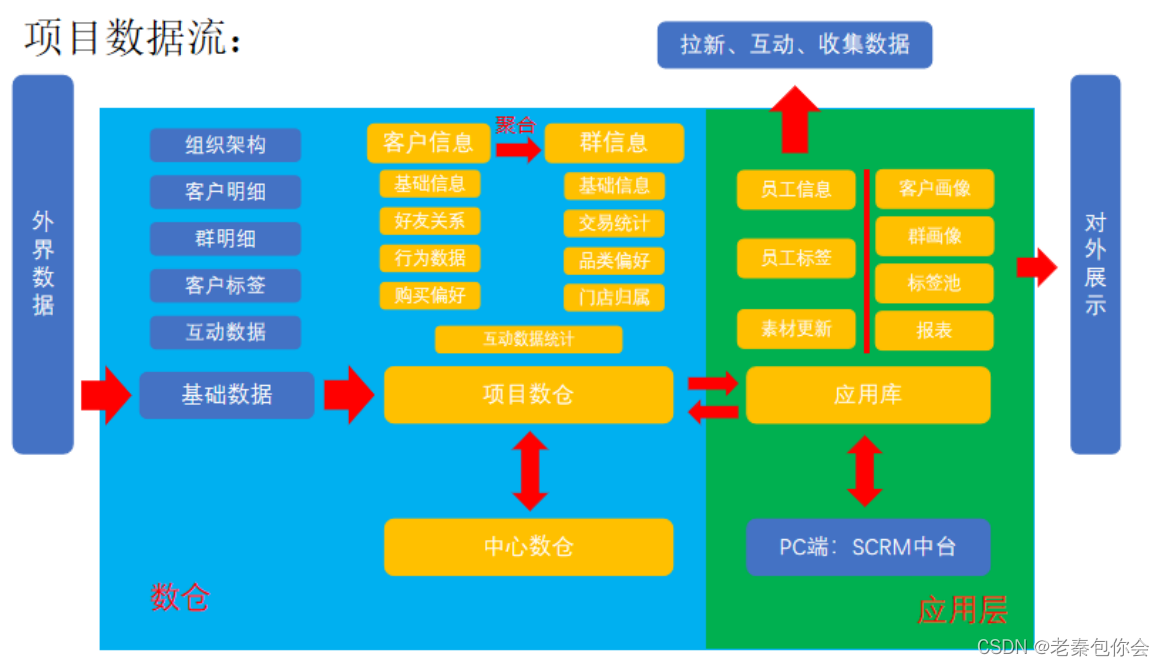
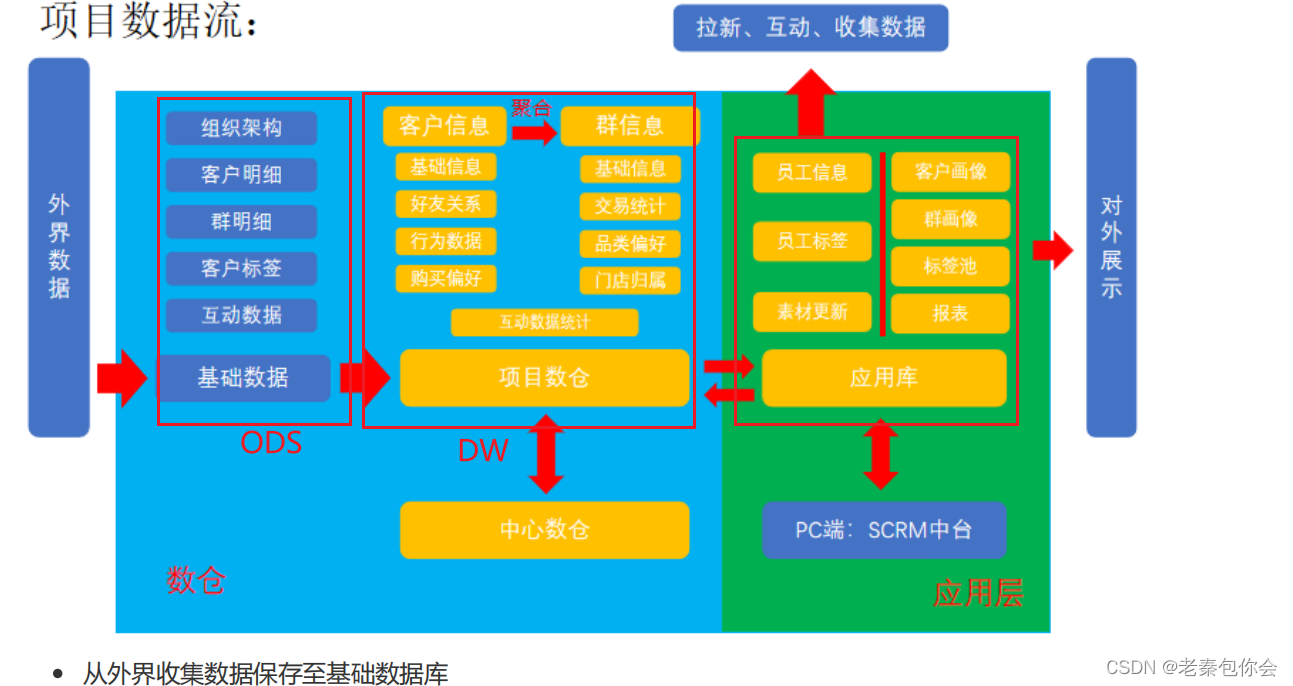
这样就可以很明了的理解清楚了
- 从外界收集数据保存至基础数据库
- 保存的外界数据在基础数据库不做任何更改,可以通过简单的计算和聚合分成不同维度、不同标签的数据,另行保存到基础数据库
- 根据项目需求,从基础数据库取数并进行计算,得到满足业务需要的数据,保存在项目的数仓中
- 通过与中心数仓的交互,可以关联到更多维度的数据
- 将已经做好的业务数据写入应用层的应用数据库,供后端使用
SCRM中台,集中展示业务数据的后台,一般只对内部开发。用于将具体的数据图像或表格化展示的平台,方便业务人员读取,根据展示数据进行下一步业务动作 - 对外展示,不仅是网页,也可以是移动端
数据走向
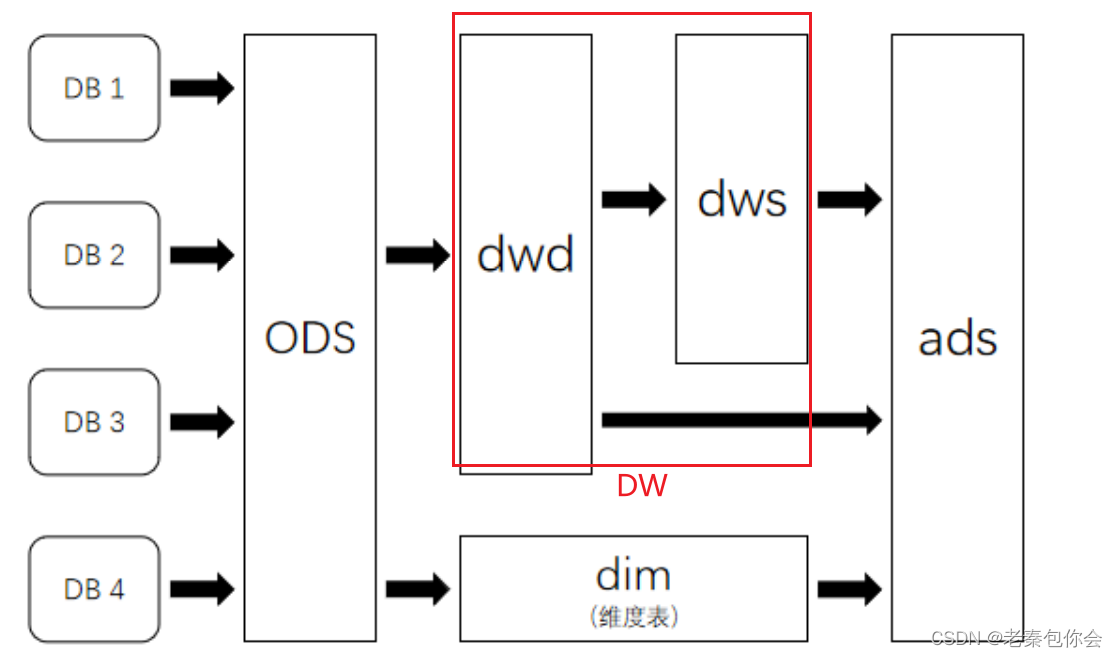
从DB到ODS会有简单的预处理,可以是增量数据,也可以是全量数据
ODS:操作数据,存储所有基础数据,简单清洗
dwd:明细数据,将所有维度数据细化,减少事实表与维度表的关联,提高明细表的易用性,相当于未处理的中间数据
dws:汇总数据,通过聚合,形成宽表,构建指标数据
dim:维度数据,不根据日期做区分,作为最基础的展示表
ads:应用数据,存放产品化的数据,主要为前端展现