目录
1、概述
2、系统监控的目标
2.1、任务的状态机
2.2、任务服务函数
2.3、任务周期性事件
2.4、时间监控的指标
2.5、时间监控的原理
2.6、CPU负载率监控原理
2.6.1、设计思路
2.6.2、监控方法的评价
3、基于WDGM模块热舞时序监控方法
3.1、活跃监督
3.2、截至时间监督
3.3、逻辑监督
1、概述
任务是操作系统的基本调度单位,也是汽车软件应用程序功能实现的重要载体,任务在操作系统中的运行情况将直接影响汽车软件应用程序功能的实现情况。因此,监控操作系统中任务的运行情况能够有效地帮助汽车软件工程师开发软件系统、校验软件系统功能以及排查系统错误等。此外,任务运行情况还会影响系统中的其他指标,其中之一就是处理器核心负载率。它是衡量系统调度性的关键参数,同时,核心负载率也被用来衡量硬件系统的大致寿命。从之前文章叙述的操作系统的配置中可以看出,Vector 公司的 MICROSAR 解决方案提供了针对操作系统本身的一些简单的接口Hook函数,其中系统启动和关闭Hook可以有效地了解操作系统的整体运行,而错误处理Hook则是密切关注操作系统内部运行是否出现问题。对于任务的相关监控问题,只规定了两个Hook,涵盖了任务上下文切换的一种情况,还有很多其他情形并没有在标准中给出规定。
2、系统监控的目标
2.1、任务的状态机
任务是操作系统中的一个重要对象,OSEK 操作系统标准对任务有详细的规定。标准规定操作系统的任务只有一个固定的优先级(除非在某些特定情况),操作系统以优先级为驱动对任务进行调度,即决定哪个任务可以被处理器执行,哪些任务需要等待。这样一来,任务在操作系统中的状态是在不断变化的。此外,标准定义了基础任务(Basic Task)和扩展任务(Extended Task)两类任务。对于基础任务来说,只有在自身执行完成、被高优先级任务或者中断打断才会释放对处理器核心的占用,而扩展任务还可能是因为等待任务执行所需的条件而释放对处理器核心的占用。
AUTOSAR规范关于任务的定义几乎完全继承了OSEK操作系统标准,因此,基础任务和扩展任务的概念可以沿用。两种任务在操作系统的中状态是会发生变化的,可以用任务的状态机模型进行描述,具体内容本书的前面几个章节已进行了详细叙述,这里不再赘述。扩展任务比基本任务多出了一个等待(Waiting)状态,这是扩展任务在运行时(Running)由于缺少特定的事件(Event)而进入的状态。进入此状态后,扩展任务可以被其他低优先级任务抢占,而在特定事件发生后,扩展任务从等待状态被激活进入就绪状态,经过操作系统调度后,可以再次运行。
每个时刻,操作系统中的任务都处在下图中所示的一种状态或是状态切换之中,一段时间内每个内核各个时刻的所有任务所处的状态以及状态切换就构成了这段时间的多核操作系统的任务时序。而针对任务的监控功能的目的就是将这段时间内多核操作系统的任务时序信息尽量精确地采集出来,为此需要监测操作系统内每个时刻任务的状态信息。下面以两个周期性任务为例,解释操作系统中任务状态切换的具体情形,具体流程如下图所示。
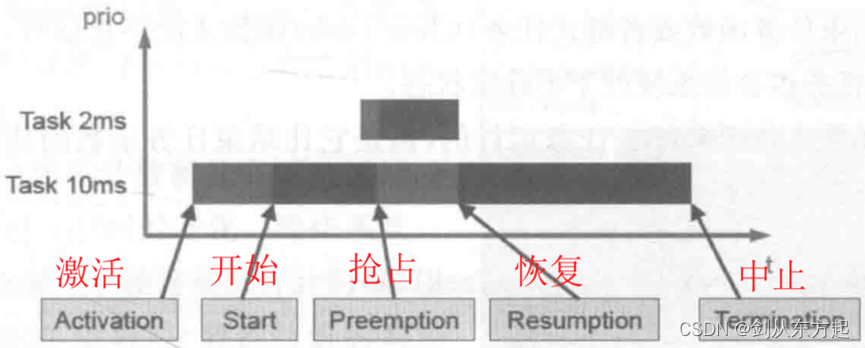
如上图所示,假设操作系统内有两个周期性任务,周期分别为 2 ms 和 10 ms,2 ms任务优先级高于10 ms任务。可以看出,任务要运行首先要经过激活过程,激活过后的任务进入就绪状态。操作系统经过调度发现当前没有优先级更高的任务,于是启动(Start)任务,任务进入运行状态。一段时间后,2 ms 任务被激活进入就绪状态,由于 2 ms 任务优先级高于 10 ms任务,所以,2ms任务被启动,同时,10 ms任务被保存上下文后放回到就绪列表,这个过程称为10 ms任务被2 ms任务抢占(Preemption)。直到2 ms任务结束,进入挂起状态,10 ms任务才会重新进入运行状态,这个过程称为10 ms任务被恢复(Resumption)。一段时间后,10 ms任务执行结束,进入挂起状态。
2.2、任务服务函数
首先是激活任务(ActivateTask)函数,该函数是用来激活处于挂起状态的任务的,其函数定义原型如下:

该服务函数用来将任务从挂起状态改变成就绪状态,调用该函数后的任务编号将会被放入就绪列表中。如果该任务未处于挂起状态,却调用该函数对任务进行激活,则把该激活记录下来,在任务处于挂起状态后进行激活,操作系统确保从第一条语句开始执行任务代码。需要注意的是,当扩展任务从挂起状态转移到就绪状态时,其所有事件都将被清除。
结束任务(TerminateTask)函数用来处理任务执行完毕,返回到挂起状态的过程。其函数原型如下:

此服务函数将任务从运行状态转移到挂起状态,如果该任务具有多个激活请求,那么,在终止该任务时,会自动将同一任务置于就绪状态。该服务函数会自动释放分配给任务的相关内部资源。如果任务还占用其他资源,应该在调用该函数之前就释放完毕。如果资源仍处于被占用状态,则调用该函数可能导致操作系统处于不确定的状态。在任何情况下,任务只有在调用结束任务函数或者链式任务(ChainTask)函数才能终止运行,否则,任务不得终止,强行终止任务也会使系统处于不确定状态。
链式任务函数也是用来终止任务运行的,但是它比结束任务函数的功能要复杂一些。其函数原型如下:

此服务函数会导致调用的任务终止。但该调用任务终止后,将激活任务编号为<TaskID)的后续任务。使用此服务函数,可以确保后续任务在调用任务终止后最早开始进入就绪状态,这样一来,可以利用这个函数进行简单任务激活与运行次序的设置。如果后续的任务与当前任务是同一个任务,则任务不会被转移到挂起状态。即使后续任务与当前任务相同,分配给调用任务的内部资源也会被自动释放。在调用该服务函数之前,也要释放任务占用的其他资源。否则,会导致操作系统处于不确定状态。
调度(Schedule)服务函数是用来进行任务上下文切换的。其函数原型如下:

调用该服务函数时,如果有较高优先级的任务已准备就绪,则释放当前正在运行任务的内部资源,将当前任务置于就绪状态,保存其上下文并执行较高优先级的任务。否则,当前调用的任务将继续运行。调度服务函数和其他服务函数的联系十分紧密,当调用了激活任务函数成功后,会触发调度服务函数的调用,这个过程称为再调度(Rescheduling),这样做的目的是为了将就绪列表中更高优先级的任务及时地执行。不仅仅是激活任务函数,当结束任务函数和链式任务函数调用成功时,也会触发再调度过程。
以上就是和任务状态转移有关的操作系统服务函数,这些服务函数相关协同,使得操作系统内部任务得以高效有序运行。
2.3、任务周期性事件
对于汽车软件系统来说,其中的任务大多是周期性的,而在AUTOSAR操作系统中,任务是由若干可运行实体组成的。也就是说,任务中的可运行实体也是周期性的。在AUTOSAR操作系统的开发流程中,可运行实体是在RTE配置阶段映射到任务中去的,任务中可运行实体的执行是由RTE层的相关事件触发的,这些事件被称为RTE事件(RTEEvent)。AUTOSAR 规范支持的 RTE事件有多种,例如数据接收事件(Data ReceivedEvent)、数据接收错误事件(Data Receive Error Event)、数据发送完成事件(Data SendCompleted Event)以及时间事件(Timing Event)。这些事件通常都是通过AUTOSAR操作系统事件来完成,除了时间事件。
AUTOSAR操作系统中任务的周期性执行是靠时间事件来驱动的。时间事件的产生要依靠操作系统警报(OS Alarm)、计数器(Counter)以及计时器(Timer),三者之间的关系如下图 所示。下图中的用于计数器的资源是指计时器,计数器用于记录时间的变化。操作系统一般会给计数器分配一个硬件或软件计时器,用来驱动计数器累加,这样,计数器数值的累加就代表着相应时间的变化,计数器的数值是以"tick”为单位进行度量的。当计数器的数值到达某一事先预设的值时就会触发警报,警报可以驱动特定任务的执行,也可以执行其他自定义的操作。从下图中可以看出,一个计数器可以驱动多个警报,警报可以设置成单次的,也可以是循环的。当循环警报驱动任务执行的时候,该任务就是周期性执行的任务。

2.4、时间监控的指标
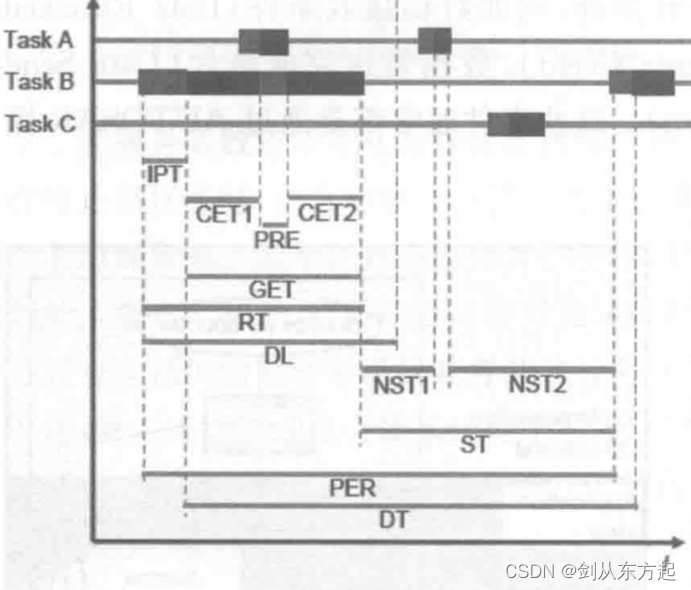
在详细了解了操作系统内部任务执行的相关状态切换过程以及中断对任务运行时序的影响后,需要用一些指标来描述任务的运行情况。相关研究文献曾用最坏执行时间WCET(Worst Case Execution Time)来表述任务的一种时间属性,也用响应时间RT(ResponseTime)来描述任务完成请求所需要的时间。在总结相关文献和对任务运行状况的研究基础上提出了以下描述任务时序的指标,见下表。


这些指标的具体物理意义要结合任务的运行时序进行阐述,指标在任务运行过程的物理意义如下图所示。从下图中可以看出各个指标的物理意义。其中,IPT 是指任务被激活后到开始执行所需要的时间;CET 表示任务的执行时间,即任务实际处于运行状态的时间,也是内核执行该任务功能代码的时间。对于被抢占的任务来说,会有多个CET,多个CET累加才是该任务的总执行时间。任务的周期(PER)是指相邻两次任务激活时刻的间隔,这一般是由软件工程师根据功能进行设置的。PRE指任务被抢占的时间,即任务由于被更高优先级任务抢占而重新进入就绪状态持续的时间。任务的响应时间(RT)是指任务从激活到结束所需的时间,响应时间一般被用来衡量操作系统的实时性。它不得大于截止时间(DL),否则,操作系统会被认为不符合实时性要求。
2.5、时间监控的原理
通过上文的描述可以发现,操作系统任务时序监控的关键点落在任务状态切换过程上。只要能精确测量每个任务运行流程中任务状态切换的激活点、开始点、抢占点、恢复点和结束点的时间,就能精确反映操作系统任务运行时序。上述监控流程如下图所示。
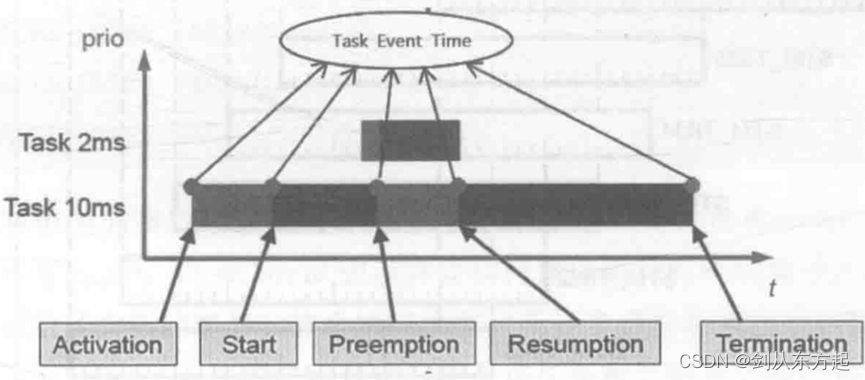
从上图中看出,监控过程归纳总结为提取三类信息。首先是任务的识别信息,由于每个内核中分配的任务可能不止一个,所以要判断当前获取的是哪一个任务的信息,通常用任务标识符 TaskID来识别该任务。其次是具体的事件信息,这是指当前的时刻发生的是任务激活到任务结束这五种事件中的哪一种事件。最后是时间信息,也就是当前发生的事件点的时间值,该信息的获取一般取决于硬件类型。将这三类信息的数据组合在一起,形成一个监控数据,存储在一个特定的位置。当然,在针对多核操作系统的监控方案中也要识别当前任务所在的内核,因此还要将内核识别信息CoreID也提取出来,将上述的监控数据依据内核的不同存储在不同数组或结构体中。
所有任务的大致运行情况如下:
- 所有任务的激活时刻(包括扩展任务的设置事件时刻)。
- 所有任务的开始时刻。
- 高优先级任务抢占了低优先级任务的抢占时刻(包含中断打断任务运行的时刻)。
- 高优先级任务完成后低优先级任务的恢复时刻(包含中断服务后恢复任务运行的时刻)。
- 所有任务的结束时刻(包括扩展任务等待事件时刻)。
任务的监控流程的关键在于要能够“知道”任务运行的各个关键事件发生点,并在事件发生的时间点进行关键信息的提取。例如,当任务被激活的瞬间,监控功能能够立即执行,获取关键的信息。因此,对任务运行关键点的捕捉与具体操作系统的软件机制有很大关系。在OSEK操作系统的国际标准中规定了一组任务运行流程中状态切换的接口PreTaskHook 和 PostTaskHook,通过这些接口,用户可以捕捉到一些任务运行的关键时间点。但是,标准规定的这两个接口并不能完成全部的监控功能。首先,它不能涵盖任务被激活的时间点捕捉;其次,它们没有包含任务被抢占的情况下抢占时间点和任务恢复时间点的捕捉,它们只包含了任务执行结束后与新的任务开始执行之前的切换时间点。
首先来看任务时序监控的第一种情况,即监控所有任务的激活时刻。OSEK 操作系统的国际标准规定,所有任务的激活都需要通过调用操作系统服务函数ActivateTask来完成。操作系统服务函数ActivateTask (TaskType (TaskID))将标识符为TaskID的任务的状态从挂起状态改变为就绪状态,此时,任务被写入就绪列表中。因此,只要操作系统调用了该服务函数,就说明有任务被激活,在该服务函数调用时获取任务编号、事件类型、当前时间值和内核编号,这样就能组成一个任务激活的监控数据。一般,上述过程的代码是用户在操作系统提供的接口中自定义实现的,但是ISO 17356-3标准没有规定针对任务激活服务函数的接口,通过研究MICROSAR操作系统发现,该操作系统在自己的软件代码中提供了用于任务激活过程中的接口--OS_VTH_ACTIVATION。该接口以宏定义的形式命名,其原型如下:

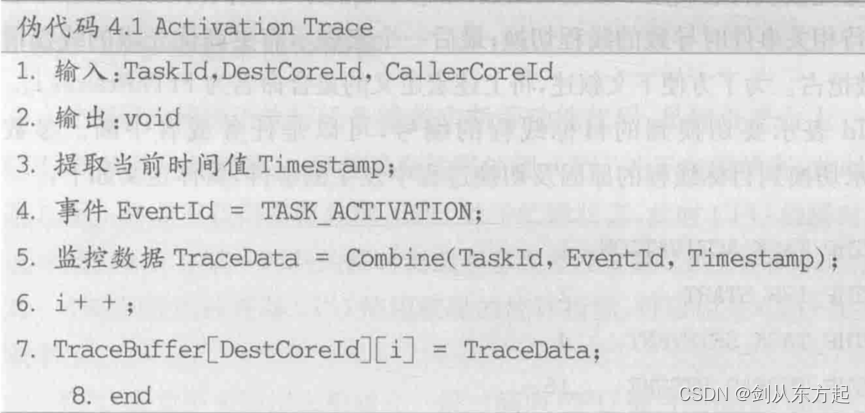
该接口函数传递的参数中包含了 TaskId, DestCoreld 和 CallerCoreld。其中,TaskId表示被激活的任务的编号;DestCoreld 表示将要执行该任务的内核的编号;CallerCoreld 表示调用该接口函数的内核的编号。这个接口函数只是一个没有功能的空函数,具体的功能需要用户自己定义。因此,在该接口函数中实现上述任务激活时刻监控的功能即可。该过程实现的伪代码如下:
剩下的四种情况其实可以归为一大类,它们都与任务的运行(Running)状态有关。而一个CPU内核同一时间只能执行一个任务或中断,因此涉及任务运行状态的变化就一定会有上下文的切换。当然,第一个任务的开始运行也包含在内。OSEK操作系统的国际标准关于任务或中断上下文的切换规定了一个服务函数Schedule,该服务函数主要是为了调度任务的运行,当有较高优先级的任务已处于就绪状态,则释放当前任务的内部资源,将当前任务置于就绪状态,并保存其上下文,之后执行较高优先级的任务。而MICROSAR操作系统针对该服务函数提供了一个功能强大的接口——OS_VTH_SCHEDULE。因此,在操作系统中,该接口会在任务之间或任务与中断之间在切换的时候被调用,这为开发监控功能提供了很大的方便。MICROSAR操作系统中以宏定义的形式来定义该接口,其原型如下:

该函数传递的参数如上所示,其中参数FromThreadId指的是内核的上一个运行的线程的标识符,即直到切换发生之前一直在运行的线程,该标识符可以是任务的编号,也可以是中断的编号。参数 FromThreadReason 表示上一个运行的线程被切换的原因,也就是上文所说的任务运行过程中的事件。系统以宏定义的形式列举出了这些事件,具体定义如下:

第一个宏表示任务完成执行后调用了该接口函数;第二个宏表示中断执行结束;第三个宏则表示扩展任务在等待相关事件时导致的线程切换;最后一个宏表示有更高优先级的线程请求执行,前一个线程被抢占。为了方便下文叙述,将上述宏定义的集合命名为FrThReason[i]。参数ToThreadId表示要切换到的目标线程的编号,可以是任务或者中断。参数ToThreadReason表示切换到目标线程的原因及切换过程中发生的事件,具体定义如下:

第一个宏表示高优先级的任务被激活导致的切换;第二个宏表示有中断请求需要处理导致的切换;第三个宏指的是扩展任务在等待的事件被设置导致的切换;最后一个宏表示被抢占的线程恢复运行状态。将上述宏的集合命名为 ToThReason[i]。形参 CallerCoreld 则表示切换动作发生的内核的编号。了解了这个接口函数的功能之后,只要在系统调用该接口的时候判断切换的原因,获取当前时间值并与事件标识符和内核编号组成一个监控数据即可。上述过程实现的伪代码如下:

这样,就能完成任务、中断的切换过程的监控。至此,关于任务时序监控功能的大致实现方案叙述完毕。
2.6、CPU负载率监控原理
处理器内核用于执行任务或者中断等功能代码,是硬件平台上一个十分重要的资源。CPU 的状态只有两种:一种是没有代码处理,CPU处于空闲状态,此时CPU 的瞬时负载率是 0;另一种是有代码需要处理,CPU处于忙碌状态,此时 CPU 的瞬时负载率是100%。因此,讨论CPU在某一时刻的瞬时负载率多大是没有意义的,讨论的CPU负载率指的是对一个时间段内处理器CPU使用状况的统计指标,可以说是CPU在一段时间内的平均负载率。
CPU 负载率主要用来衡量在一段时间内CPU 被占用情况,如果CPU 的负载率一直处于过高的状态,则说明操作系统的空闲时间很少。一旦某些任务的执行时间稍微延长或中断请求频繁,便很可能造成接下来的任务或中断不能正常执行的情况,这样就不能满足系统实时性的要求。同时,CPU长时间超负荷运作也会损害控制器的硬件。因此,必须将CPU的负载率控制在一定的范围内,以保证系统能够稳定运行,满足实时性的要求。
CPU 的负载率可以用CPU的一段工作时间与该时间段内被占用时间的比值来计算。CPU被占用的时间记为tlond, CPU的运行总时间记为ttotal。则CPU的负载率可以如下计算:

在该方法中,计算 CPU 被占用的时间和 CPU 的运行总时间是监控 CPU 负载率的关键。具体如何测量这两个时间的值,要先了解AUTOSAR操作系统中的任务组成结构。在AUTOSAR规范中,除了软件工程师配置的实现汽车电子软件具体功能的任务,还规定了一种没有任何具体功能的特殊任务,名为空闲任务(Idle Task)。规范中规定操作系统中空闲任务的优先级最低,没有固定周期,可以不执行任何功能程序,当系统中没有其他任务要运行或中断请求时,操作系统会自动跳转到空闲任务,并且一直在执行空闲任务。空闲任务在操作系统中的运行情况如下图所示。
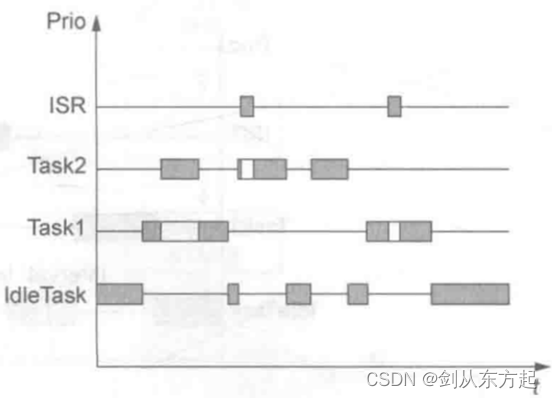
从上图中可以看出,当CPU不被占用时,会一直执行空闲任务。因此,空闲任务的运行时间即可作为 CPU 的空闲时间,将该时间记为tidle,则可得如下公式:
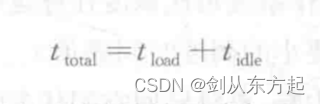
那么,CPU的负载率的计算式可以扩展成如下:

这样,就将一段时间内CPU的总运行时间分成空闲时间和忙碌时间,而忙碌时间中包含了占用CPU的任务的运行时间,也包含了CPU处理中断请求的时间。CPU负载率计算的重点就是利用AUTOSAR操作系统的空闲任务机制获得一段时间内CPU的空闲时间或者是 CPU 的忙碌时间。
2.6.1、设计思路
计算空闲任务执行时间的思路是:在空闲任务中添加一个循环,循环开始时读取当前 STM 模块寄存器的值(Current STM Value),并和上一次循环读取到的STM值(Last STM Value)相减,即为两次循环的时间间隔(Interval)。由于空闲任务一直在执行,所以,两次循环的时间间隔就是空闲任务的执行时间。把所有的时间间隔相加,即为空闲任务总的运行时间。然而,空闲任务的优先级最低,会被其他任务或中断打断。当空闲任务被打断后,当前循环的STM值与上次循环的STM值之差就不再是空闲任务的执行时间了,而是其他任务或中断的执行时间,即CPU的忙碌时间。两种情况的区别如下图所示。

上图中循环表示两次STM时间值的差值Interval。可以看到,当空闲任务连续运行计算得到的时间间隔和空闲任务被打断后计算得到的时间间隔代表的含义是不同的。因此,需要一种方法来判断空闲任务在当前循环执行中是否被其他任务或中断请求所打断。在 AUTOSAR 操作系统中,当较低优先级的任务在执行时,如果激活了高优先级的任务,同时低优先级任务是可抢占类型的任务的话,操作系统会停止执行低优先级的任务,转而执行高优先级的任务。这一过程需要操作系统进行调度,执行调度代码会占用 CPU 一段时间。根据调度情况的不同,操作系统每次调度任务运行所需的时间也不同,假设一个比操作系统最小的调度时间还要小的调度时间阈值ts。也就是说,当操作系统从空闲任务跳转到其他高优先级任务或者中断,再跳转回空闲任务时,即使高优先级的任务或者中断服务函数不执行任何的代码,时间间隔也会大于ts。
因此,时间间隔值的大小可以作为判断上一次空闲任务的执行是否被打断的依据。当时间间隔小于ts时,说明没有发生操作系统调度,此时的时间间隔为空闲任务的执行时间。当时间间隔大于ts时,说明已经发生了任务切换,此时的时间间隔为其他高优先级任务或者中断服务函数的执行时间,即为CPU被占用的时间。因此,将所有大于ts的时间间隔相加,就可以得到 CPU 被占用的总时间。
CPU的负载率一般是实时变化的,因此,每经过一段时间,就应该计算出相应的负载率,即负载率应该周期性地进行计算。而CPU负载率算法运行的周期应该根据操作系统中所有任务的周期确定,一般来说,算法运行的周期定为所有任务的超周期 THp。而在实际操作中,算法的周期是靠STM模块计时器的溢出值来决定的,由于计时器分辨率的原因,往往实际的算法周期只能在超周期Thp附近。假设选取STM计时器的低bstm位用来计时。STM的工作频率为 fstm,这样,bstm位计时器的溢出值为2bstm-1,溢出时间为t。=(2bstm-1)/fstm≈THP此时,算法程序每过时间 t。就会计算一次CPU 的负载率,CPU 的运行总时间即为时间 t。,CPU 被占用的时间为所有大于 ts的时间间隔之和。在每次 bstm位计时器溢出时计算CPU的负载率,并在计算完成后将累计的时间间隔清零以便于下一次计算。
以上的过程针对的是一个内核,而目标是在多核操作系统中进行内核负载率的测量,因此需要判断当前算法在哪个内核中运行,操作系统中有相应的服务函数可以获取当前的内核编号。以AURIX TC275系列单片机为例,该系列单片机具有3个核,每个核都需要计算其负载率。因此,在进入空闲任务后要先获取CoreID,每个核都会根据CoreID值分别计算各自的 CPU 负载率。算法逻辑框图如下图所示。
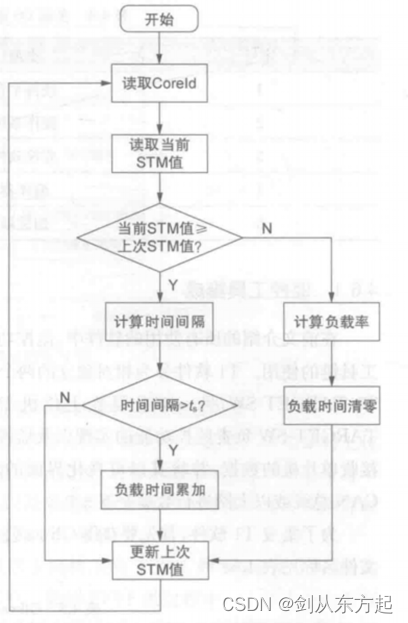
算法运行流程如下
首先获取内核编号,根据内核编号值进入不同核的代码。然后读取当前的STM计时器的值,并取出bstm位作为当前的STM值,再判断当前STM值是否大于等于上次得到的STM值。如果是。则说明bstm位STM计时器未溢出,还在当次的内核负载率计算中,继续进行时间间隔的累加计算。否则,说明bstm位STM计时器已溢出,则计算当前的内核负载率,并清零累计的时间间隔。当STM未溢出时,需要根据当前的 STM 值与上次STM 值之差计算出时间间隔。如果时间间隔大于ts,则将时间间隔累加到总的内核被占用的时间中。
2.6.2、监控方法的评价
一般来说,主要从两方面对某一种监控方法进行评价。一方面,是从这一套监控方法所要占用的内存大小来评价,即内存开销;另一方面,要从执行具体监控代码所需的时间多少来评价,即时间开销。内存是硬件平台的一种宝贵的硬件资源,主要是用来存储功能代码以及一些变量,监控功能实现所需内存越小,表明测量方法对系统功能影响越小,是我们希望达到的目标。此外,内核的运行时间也是系统的重要资源,如果一套监控方法的代码执行需要消耗太多时间,那么将大大增加CPU负载率,不利于系统重要功能任务的运行。因此,这两个指标越小,该监控方法就越良好。
3、基于WDGM模块热舞时序监控方法
AUTOSAR架构服务层的基础软件模块看门狗管理器(Watchdog Manager,WdgM)可以用于对软件运行的时序和状态进行监督,在状态发生切换时及时通知应用层。如果程序执行与预期时间或逻辑配置不一致,它会采取一系列安全措施来覆盖这些故障。
被监督的逻辑单元称为监督实体(Supervised Entity,SE),一般指的是安全相关的软件组件或复杂驱动中具有严格执行时间要求并且具有特定功能的代码段。监督实体中一些重要的部分称为检查点(Checkpoint),用于获取程序执行过程中的时间点(定时器值),相当于一个数组,其个数(数组长度)需要根据需求进行设置。监督实体的代码与看门狗管理器的函数调用相交错,这些函数调用用于通知看门狗管理器代码已运行至检查点。如下图所示,通过在安全软件组件或安全复杂驱动中设置检查点,并根据实际需求在安全看门狗管理器模块中配置检查点的到达次数、时间和顺序,能够有效地对软件执行时序进行监督。如果监督实体运行出现异常情况,看门狗管理器指示看门狗接口不再触发硬件看门狗。如果硬件看门狗发生超时,看门狗会重启ECU或MCU,这会导致ECU或MCU硬件以及整个软件重新初始化。
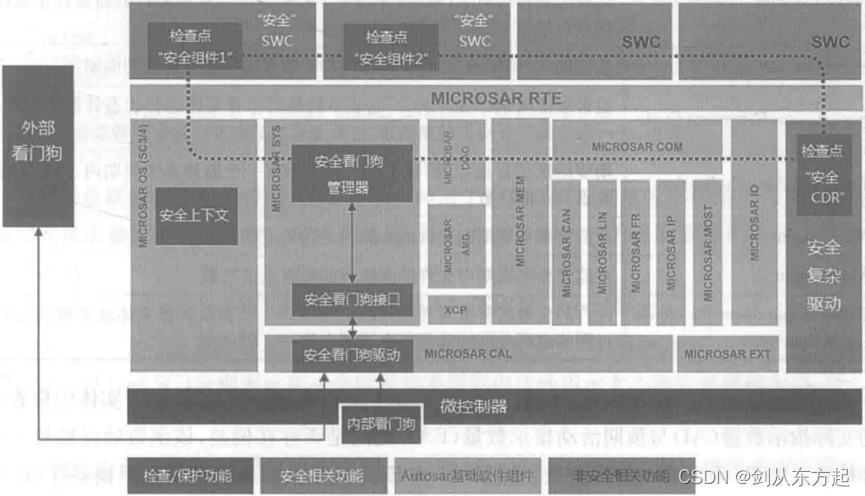
看门狗管理器提供三种监督机制对应用程序的运行时序进行监督:
1、活跃监督
2、截止时间监督
3、逻辑监督
3.1、活跃监督
活跃监督用来周期性地检查一个或多个监督实体在周期和最大超时周期条件下运行的可靠性。周期性的监视实体对其运行的周期存在约束,通过在周期性任务中设置检查点,在软件运行监控中,看门狗管理器周期性检查是否在限定的时间中到达监视实体的检查点,从而能够监控该任务是否正常执行且执行周期是否在容忍度范围内。
活跃监督的每个检查点都有一系列参数需要进行设置,见下表。这些参数的设置取决于看门狗管理器的运行模式。该机制下的检查点不带转移,即监督实体只存在一个检查点或者即使存在多个检查点,但这些检查点之间是相互独立的。
应用层通过调用检查点到达函数WdgM-CheckpointReached()检测监督实体中检查点的实际指示数量(AI)与预期活动指示数量(EAI)之间是否存在偏差,该函数通过监督实体和检查点的 ID 确定唯一的检查点。如果 AI 和 EAI不存在偏差或有偏差但偏差在(EAIMinMargin,EAI+MaxMargin)范围内,看门狗管理器认为任务属于正常(OK)运行状态;否则,为失败(FAILED)状态。而在监督参考周期中,这种失败次数未超过允许的失败监督参考周期值,则保持在失败状态;否则,进入过期状态(EXPIRED)。以上算法在看门狗管理器模块的 WdgM_MainFunction()中执行,部分参考代码如下:

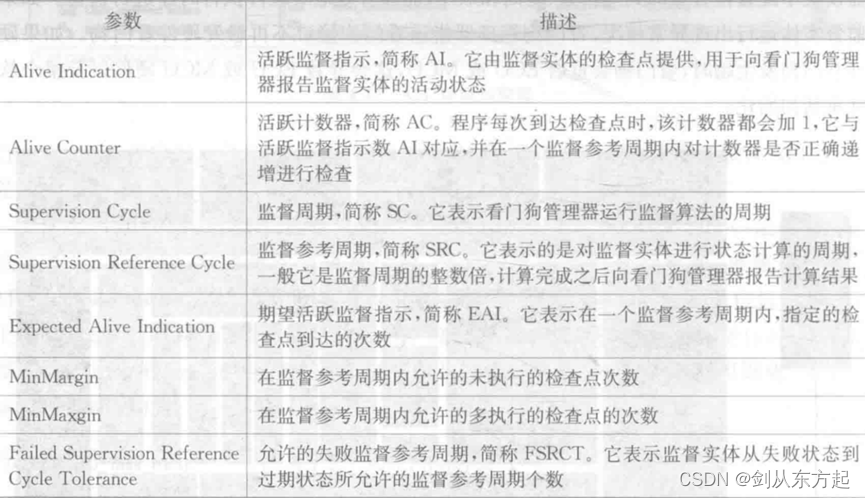
对于活跃监督参数的设置,需要提供一种用于检测不匹配的监督实体的定时限制算法,根据该算法参数之间能形成一种约束关系,从而能够为参数的明确配置提供指导。具体监督算法为
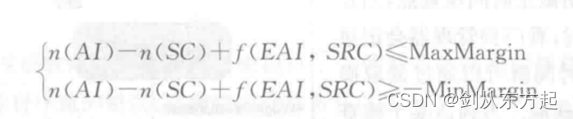

3.2、截至时间监督
在嵌入式软件开发过程中,可能会遇到任务的执行存在时间冲突或代码运行进入无限循环的情况,尤其对于执行时间要求比较严格的代码段,比如制动、发动机控制等,如果出现运行异常,将可能导致系统出现严重后果。安全行为要求必须对这些代码块进行执行时间的监督,如果出现运行异常,能够及时报告错误,采取相应措施使系统进入安全状态。
AUTOSAR 的基础软件模块看门狗管理器提供了一种用于检查监督实体暂时的、动态的行为,它可以对监督实体的执行时间加以限定,能够极大地增加探测随机跳转或者无规则更新时间基准的概率。如果在预期时间内监督实体未完成执行,将被视为错误监督并向看门狗管理器报告错误。这样的监督机制称为截止时间监督。
对于非周期监督实体的时间限制,可以通过截止时间监督机制进行检查。在这样的监督实体中,如果某一事件发生后,紧接着即将要发生的事件会有一定的发生时间限制,这样的时间限制会在预设的最大截止时间与最小截止时间之内,可以通过检查点来刻画事件。与活跃监督实体中不带转移的独立检查点不同,截止时间监督实体中的检查点之间必须存在转移,即至少存在两个检查点并且这两个检查点之间存在时序关系。最先到达的检查点称为起始检查点,最后到达的检查点称为结束检查点。最简单的情况则是在监督实体SE1中只存在起始和结束两个检查点CP1-1 和CP1-2,如下图所示。但为了能够比较清楚地了解代码结构,一般会在监督实体中设置多个检查点。
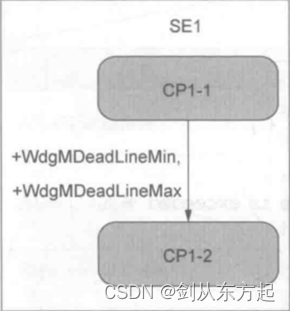
截止时间监督有两个重要参数需要进行设置,分别为WdgMDeadLineMin 和 WdgMDeadLineMax,即截止时间的最小值和最大值。对于两个检查点,从一个检查点转移到另一个检查点所用的时间介于截止时间的最大值和最小值之间。检查点和检查点之间的转移就构成了程序流图。在监督实体中可以存在多个转移,从而与检查点之间构成链形结构,也可以形成若干独立的程序流图,如下图所示。
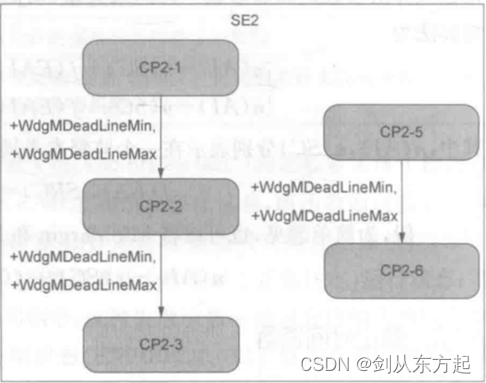
截止时间监督是一系列带有时间约束的检查点之间的转移,一个转移可以定义两个参考的检查点,即起始截止时间检查点和结束截止时间检查点。
对于每个起始截止时间检查点,当程序到达该检查点时,看门狗管理器会记录对应的时间戳。时间戳可以通过读取操作系统的ticks来获取。当到达某个检查点并且该检查点处于活跃模式时,监督实体会调用看门狗管理器提供的服务函数WdgM_CheckpointReached(),表明监督实体开始进行截止时间监督,记录当前检查点对应的时间戳并将其作为下一个检查点的参考时间。
当到达下一个检查点且该检查点处于活跃模式时,再次记录其对应时间戳。如果上一个检查点的时间戳不为零,服务函数WdgM_CheckpointReached()会测量两个时间戳的差值,从而计算出二者之间的时间间隔并比较其与最大截止时间、最小截止时间的大小,判断截止时间监督是否与预期设置一致。当然,如果上一个检查点的时间戳恰好为零,则无须计算二者差值。如果时间差值介于预先设定的截止时间的最小值与最大值之间,看门狗管理器不会报告错误;如果时间差值超出此范围,则被视为错误的截止时间监督。以上算法在CheckDeadlineViolation()函数中实现,部分参考代码如下:

3.3、逻辑监督
对于嵌入式系统,时序是其重要的指标。活跃监督和截止时间监督都是对监督实体执行时间方面的监督,这只是满足了时间要求。对于执行顺序的错误,安全行为也要求对其进行监督。
AUTOSAR基础软件看门狗管理器也提供了一种对程序流的监督机制,称为逻辑监督。逻辑监督关注程序流的错误,这些错误会导致在应用程序无错误执行期间与有效的程序序列产生偏差。如果一个或多个程序指令以不正确的顺序处理,或者根本没有处理,就会出现不正确的控制流。控制流错误可能导致数据损坏或单片机重置。
逻辑监督有两种类型,分别为内部流图监督和外部流图监督。内部流图指的是所有的检查点属于同一个监督实体并且这些检查点由内部转移进行连接,如下图所示。

在监督实体 SE3 中,检查点 CP3-1 和 CP3-6 分别为起始检查点和结束检查点,而检查点 CP3-2 中包含多个检查点,这些检查点之间构成一种循环逻辑关系。每个监督实体中可以没有内部流图或有多个内部流图。
外部流图是指至少存在两个检查点属于不同的监督实体,检查点由外部转移连接,如下图所示。其中检查点CP4-1-CP4-4 均属于监督实体 SE4,检查点CP5-1-CP5-2 属于监督实体 SE5,但CP4-4和CP5-1 存在转移关系,因此,该流图为外部流图。
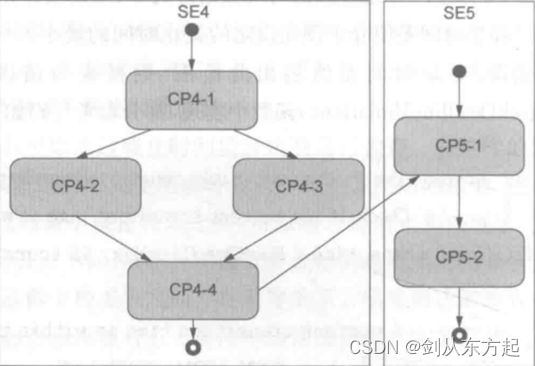
每个内部流图代表一种逻辑监督,如果一个监督实体存在多个内部流图,则会产生多个逻辑监督结果。同理,外部流图也代表一种逻辑监督,它可能连接多个监督实体。假设多个外部流图跨越一个监督实体,则该监督实体也将产生多个逻辑监督结果。
为了验证转移有效,看门狗管理器需要存储上一次到达的检查点信息,该信息中包含检查点的时间戳,因此,根据时间戳就可以判断程序运行至不同检查点的时间,从而得出代码的执行顺序。判断原理与截止时间监督类似,只是根据时间大小判断软件执行顺序。如果WdgM_CheckpointReached()函数的调用顺序与预期配置一致,则本次监督实体状态为正常状态,否则视为失败状态,同时,计数器ProgramFlowViolationCnt记录失败次数。如果在监督参考周期内,失败次数未超过所配置的允许失败次数,监督实体状态保持在失败状态,否则视为过期状态。
同理,该算法同样适用于判断外部流图的检查点。以上要求表明如果存在错误的内部转移,那么,向看门狗管理器报告的那个错误检查点所在的监督实体的逻辑监督是错误的。