目录
概述
Pipeline Dataflow
代码示例WorldCount.py
执行脚本WorldCount.py
概述
Apache Flink 提供了 DataStream API,用于构建健壮的、有状态的流式应用程序。它提供了对状态和时间细粒度控制,从而允许实现高级事件驱动系统。
用户实现的Flink程序是由Stream和Transformation这两个基本构建块组成。
Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
当一个Flink程序被执行的时候,它会被映射为Streaming Dataflow。一个Streaming Dataflow是由一组Stream和Transformation Operator组成,它类似于一个DAG图,在启动的时候从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
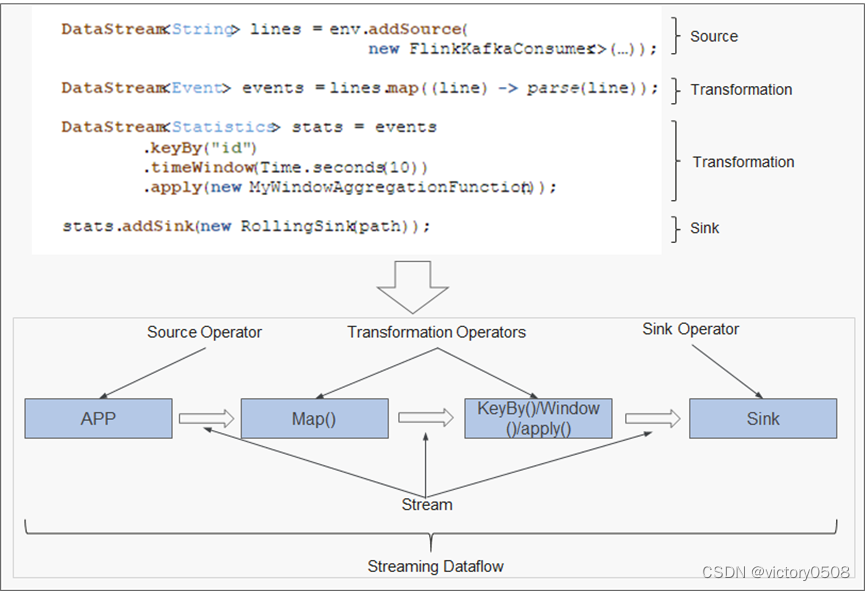
FlinkKafkaConsumer是一个Source Operator,Map、KeyBy、TimeWindow、Apply是Transformation Operator,RollingSink是一个Sink Operator。
Pipeline Dataflow
在Flink中,程序是并行和分布式的方式运行。一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask。
Flink内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。
紧密度低的算子则不能进行优化,而是将每一个Operator Subtask放在不同的线程中独立执行。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度(分区总数)等于生成它的Operator的并行度。
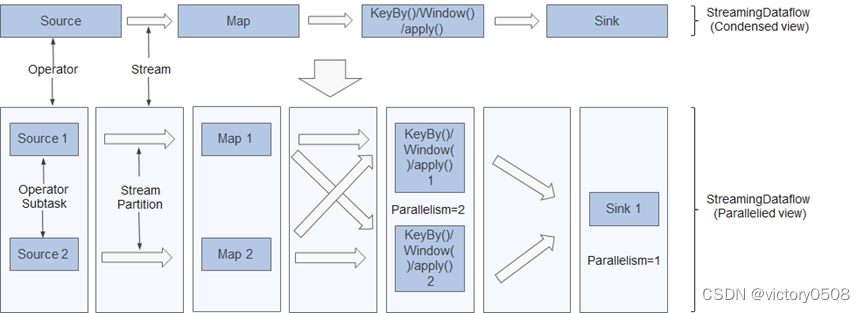
紧密度高的算子可以进行优化,优化后可以将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
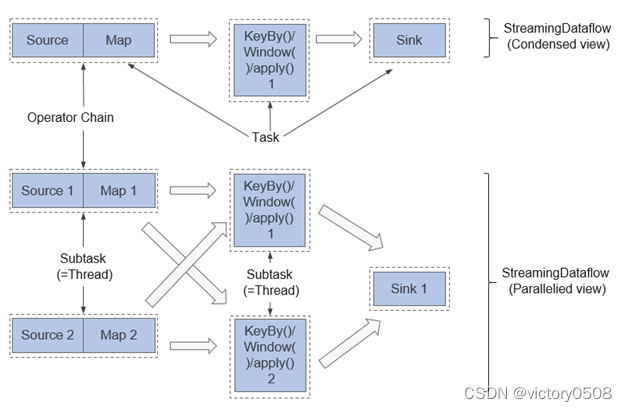
图中上半部分表示的是将Source和map两个紧密度高的算子优化后串成一个Operator Chain,实际上一个Operator Chain就是一个大的Operator的概念。图中的Operator Chain表示一个Operator,keyBy表示一个Operator,Sink表示一个Operator,它们通过Stream连接,而每个Operator在运行时对应一个Task,也就是说图中的上半部分有3个Operator对应的是3个Task。
图中下半部分是上半部分的一个并行版本,对每一个Task都并行化为多个Subtask,这里只是演示了2个并行度,Sink算子是1个并行度。
代码示例WorldCount.py
在本章中,你将学习如何使用 PyFlink 和 DataStream API 构建一个简单的流式应用程序。
编写一个简单的 Python DataStream 作业。
该程序读取一个 csv 文件,计算词频,并将结果写到一个结果文件中。
import argparse
import logging
import sys
from pyflink.common import WatermarkStrategy, Encoder, Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors import (FileSource, StreamFormat, FileSink, OutputFileConfig,RollingPolicy)word_count_data = ["To be, or not to be,--that is the question:--","Whether 'tis nobler in the mind to suffer","The slings and arrows of outrageous fortune","Or to take arms against a sea of troubles,","And by opposing end them?--To die,--to sleep,--","No more; and by a sleep to say we end","The heartache, and the thousand natural shocks","That flesh is heir to,--'tis a consummation","Devoutly to be wish'd. To die,--to sleep;--","To sleep! perchance to dream:--ay, there's the rub;","For in that sleep of death what dreams may come,","When we have shuffled off this mortal coil,","Must give us pause: there's the respect","That makes calamity of so long life;","For who would bear the whips and scorns of time,","The oppressor's wrong, the proud man's contumely,","The pangs of despis'd love, the law's delay,","The insolence of office, and the spurns","That patient merit of the unworthy takes,","When he himself might his quietus make","With a bare bodkin? who would these fardels bear,","To grunt and sweat under a weary life,","But that the dread of something after death,--","The undiscover'd country, from whose bourn","No traveller returns,--puzzles the will,","And makes us rather bear those ills we have","Than fly to others that we know not of?","Thus conscience does make cowards of us all;","And thus the native hue of resolution","Is sicklied o'er with the pale cast of thought;","And enterprises of great pith and moment,","With this regard, their currents turn awry,","And lose the name of action.--Soft you now!","The fair Ophelia!--Nymph, in thy orisons","Be all my sins remember'd."]def word_count(input_path, output_path):env = StreamExecutionEnvironment.get_execution_environment()env.set_runtime_mode(RuntimeExecutionMode.BATCH)# write all the data to one fileenv.set_parallelism(1)# define the sourceif input_path is not None:ds = env.from_source(source=FileSource.for_record_stream_format(StreamFormat.text_line_format(),input_path).process_static_file_set().build(),watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),source_name="file_source")else:print("Executing word_count example with default input data set.")print("Use --input to specify file input.")ds = env.from_collection(word_count_data)def split(line):yield from line.split()# compute word countds = ds.flat_map(split) \.map(lambda i: (i, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \.key_by(lambda i: i[0]) \.reduce(lambda i, j: (i[0], i[1] + j[1]))# define the sinkif output_path is not None:ds.sink_to(sink=FileSink.for_row_format(base_path=output_path,encoder=Encoder.simple_string_encoder()).with_output_file_config(OutputFileConfig.builder().with_part_prefix("prefix").with_part_suffix(".ext").build()).with_rolling_policy(RollingPolicy.default_rolling_policy()).build())else:print("Printing result to stdout. Use --output to specify output path.")ds.print()# submit for executionenv.execute()if __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')parser.add_argument('--output',dest='output',required=False,help='Output file to write results to.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input, known_args.output)执行脚本WorldCount.py
python word_count.py