JUC系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解JMM内存模型的底层实现原理 | https://zhenghuisheng.blog.csdn.net/article/details/132400429 |
| 【二】深入理解CAS底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132478786 |
| 【三】熟练掌握Atomic原子系列基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132543379 |
熟练掌握Atomic原子系列基本使用
- 一,深入理解atomic原子系列基本操作
- 1,初识atomic原子系列
- 2,CAS的方式实现atomic原子类的底层
- 3,五种数据类型的基本使用
- 3.1,基本数据类型
- 3.2,数组数据类型
- 3.3,引用数据类型
- 3.4,对象属性修改器
- 3.5,原子类型累加器(重点)
一,深入理解atomic原子系列基本操作
1,初识atomic原子系列
在jvm单进程中,往往会涉及到在多线程下一些关于数据的增加的问题,如典型的数据类加问题,通常情况是可以直接采用悲观锁 synchronized 关键字来实现的,但是由于悲观锁需要涉及到用户态到内核态直接的切换,会严重的影响该场景下的性能问题,因此在后面,通过cas底层实现的atomic算法就此而生。
在java.util.concurrent下面有一个atomic的原子包,里面有着多个关于atomic的原子实现类,atomic主要能实现的数据类型可以归纳为五种:基本数据类型、引用数据类型、数组数据类型、对象属性修改器、原子类型累加器

2,CAS的方式实现atomic原子类的底层
在上一篇中,谈到了cas的底层实现,主要是通过内部自旋加调用硬件层面的指令来实现数据的原子性,通过cmpxchg 指令来实现比较和交换的操作,从而实现总线加锁,并通过一个 #lock 前缀指令来实现storeLoad内存屏障的功能,从而解决在多线程中共享变量的可见性、原子性和有序性
在atomic中,其底层实现就是通过cas的原理来实现的,由于cas的缺点之一就是只能操作一个变量,atomic原子包的主要思想就是对单个变量进行操作,因此atomic采用cas作为底层实现最好不过,并且可以减少用户态到内核态之间的切换,在一定的数据范围内,其效率是远远高于这个synchronized这些锁的
如初始化一个 AtomicInteger 原子类,如下
AtomicInteger atomicInteger = new AtomicInteger(0);
接下来对这个类进行一个自增的操作,就是调用其 incrementAndGet 方法
//先自增,再将值放回
atomicInteger.incrementAndGet()
其底层的实现如下,会通过一个unsafe类的一个实例,unsafe类就是介于java类和硬件层面打交道的类
public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
随后再查看这个unsafe类调用的这个 getAndAddInt 方法,很明显,这个方法就是比较和交换的底层实现
public final int getAndAddInt(Object var1, long var2, int var4) {int var5;do {//var5 工作内存中的初始值,就是旧值var5 = this.getIntVolatile(var1, var2);//var1 当前值所占的字节数 var2 offset偏移量//var5 + var4 累加完的值} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));//最终返回的是工作内存的初始值。因此需要在外面再+1return var5;
}
而最终调用这个 native 本地方法栈中的 compareAndSwapInt 方法,再去调用底层的硬件实现比较和交换的操作。在本人上一篇cas的文章中,有着更为详细的描述。
public final native boolean compareAndSwapInt(Object var1,long var2,int var4,int var5);
3,五种数据类型的基本使用
3.1,基本数据类型
基本数据类型主要有:AtomicInteger、AtomicBoolean、AtomicLong 这三种,以AtomicInteger来举例,其用法主要如下
//初始化 AtomicInteger 对象
AtomicInteger atomicInteger = new AtomicInteger(0);
在这个AtomicInteger类中,里面可以使用的方法主要如下图,如一些getAndAdd,addAndGet,getAndIncrement,getAndDecrement,incrementAndGet,deCrementAndGet等等。都会涉及到是先自增在获取值还是先获取值再自增的操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ikbbfrI2-1693214340918)(img/1693187864610.png)]](https://img-blog.csdnimg.cn/80b8d2066d84494bb41c78fd35256adf.png)
相关的AtomicInteger类的api的使用命令如下
/*** @author zhenghuisheng* @date : 2023/8/28*/
public class AtomicIntegerTest {public static void main(String[] args) {//初始化 AtomicInteger 对象AtomicInteger atomicInteger = new AtomicInteger(0);System.out.println("先获取再自增:" + atomicInteger.getAndIncrement());System.out.println("先自增再获取:" + atomicInteger.incrementAndGet());System.out.println("比较和交换值:" + atomicInteger.compareAndSet(2, 10));System.out.println("读取当前值为:" + atomicInteger.get());System.out.println(atomicInteger.intValue());System.out.println("先自增再获取:" + atomicInteger.addAndGet(10));atomicInteger.set(5);System.out.println("读取当前值为:" + atomicInteger.get());// lazySet在多线程的场景下不能保证缓存立马被刷新atomicInteger.lazySet(10);System.out.println("读取当前值为:" + atomicInteger.get());}
}
3.2,数组数据类型
数组数据类型主要有:AtomicIntegerArray、AtomicReferenceArray、AtomicLongArray这三种数据类型
接下来再以这个 AtomicIntegerArray 为例,首先先创建一个AtomicIntegerArray对象和一个整型数组
int[] currentData = {1,2,3,4};
AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(currentData);
在这个 AtomicIntegerArray 类的构造方法中,会克隆出一个新的数组,所以在获取数据得调用get方法
public AtomicIntegerArray(int[] array) {// Visibility guaranteed by final field guaranteesthis.array = array.clone();
}
通过下图可知 AtomicIntegerArray 的方法其实和AtomicInteger的类似,只是操作的对象不同
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5EAu5ID9-1693214340918)(img/1693202518345.png)]](https://img-blog.csdnimg.cn/779934d6bfcf4c449306c4f4b3d2b636.png)
相关AtomicIntegerArray类的api的使用如下
public class AtomicIntegerArrayTest {public static void main(String[] args) {//定义一个数组int[] currentData = {1,2,3,4};AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(currentData);System.out.println("获取数组下标为1的值:" + atomicIntegerArray.get(1));System.out.println("获取数组下标为2的值:" + atomicIntegerArray.incrementAndGet(2));//比较和交换System.out.println(atomicIntegerArray.compareAndSet(3, 4, 5));System.out.println(atomicIntegerArray.get(3));//先累加,再将值放回System.out.println(atomicIntegerArray.addAndGet(1, 10));//在多线程中不会立即刷新缓存,不能保证可见性atomicIntegerArray.lazySet(2,10);System.out.println(atomicIntegerArray.get(2));}
}
3.3,引用数据类型
引用数据类型的主要有:AtomicReference、AtomicStampedRerence、AtomicMarkableReference类,
接下来依旧以这个AtomicReference类作为实例,先创建一个 AtomicReference类实例
//原子类
AtomicReference<Student> objectAtomicReference = new AtomicReference<>();
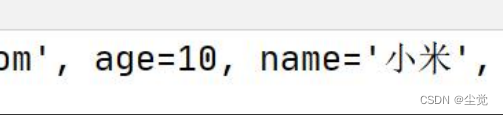
Student类比较简单,只有两个属性,分别是name和age
class Student{String name;int age;public Student(String name,int age){this.name = name;this.age = age;}
}
在使用这个类之前,先查看一下这个类里面有哪些方法,以及变量等
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VZGSQ5MR-1693214340919)(img/1693206590488.png)]](https://img-blog.csdnimg.cn/c395116529f34d79881aa65d508c2dc1.png)
接下来详细的描述一下该类的具体是如何使用的
public static void main(String[] args) {//原子类AtomicReference < Student > objectAtomicReference = new AtomicReference < > ();Student stu1 = new Student("zhenghuisheng", 18);Student stu2 = new Student("zhansan", 22);//设置值objectAtomicReference.set(stu1);System.out.println(objectAtomicReference.get().name + "---" + objectAtomicReference.get().age);//比较和交换System.out.println(objectAtomicReference.compareAndSet(stu1, stu2));//获取值System.out.println(objectAtomicReference.get().name + "---" + objectAtomicReference.get().age);}
3.4,对象属性修改器
对象属性修改器主要有:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferencrFieldUpdater 这三个类
以AtomicIntegerFieldUpdater为例子,依旧使用上面那个Student类,接下来创建一个AtomicIntegerFieldUpdater的对象,随后对这个对象里面的属性值age进行操作
//初始化 AtomicIntegerFieldUpdater 对象
static AtomicIntegerFieldUpdater<Student> atomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Student.class, "age");
public static void main(String[] args) {//初始化对象Student stu1 = new Student("zhenghuisheng", 18);atomicIntegerFieldUpdater.set(stu1,18);System.out.println(atomicIntegerFieldUpdater.get(stu1));System.out.println(atomicIntegerFieldUpdater.addAndGet(stu1, 10));System.out.println(atomicIntegerFieldUpdater.incrementAndGet(stu1));
}
3.5,原子类型累加器(重点)
原子类型累加器主要有以下五种类型,分别是:Striped64、DoubleAccumulator、LongAccumulator、LongAdder、DoubleAdder,这种类型的数据是在jdk1.8之后才新增的类。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IMIG3Awa-1693214340920)(img/1693208753361.png)]](https://img-blog.csdnimg.cn/ee77f7d2ab014a158113a4f77e3973a4.png)
由于atomic底层是通过这个cas实现的,但是cas也存在着一个缺陷,就是不利于在并发量很大的场景下使用,因为自旋会随着大量的比较和交换耗废大量的cpu资源,但是在jdk8开始,就引入了一个重要的算法:写热点分散。
cas主要是单线程执行,因此为了解决这个问题,就可以将一个大的累加操作,拆分成多个小的累加操作,最后再进行汇总累加,这样解决出现在高并发的场景下。总而言之就是先分再合的思想。
举一个简单的例子,假设此时有10000个线程需要进行类加操作,那么这10000个线程就得不断的进行自旋,进行比较和交换的操作,由于底层保证了原子性,因此可以看成就是一个线程执行;现在优化思路就是,将这10000次的类加,拆分成10个数组,每个线程只需要对应一个下标,每个数组的值进行类加,只需要累加1000次,最后进行汇总即可,数据量越大的情况,耗费的时间越短,占用的cpu资源越少。
接下来以这个 LongAdder 为例,首先先实例化一个longAdder对象,随后进行一个自增的操作
LongAdder longAdder = new LongAdder();
// 自增操作
longAdder.increment();
随后查看这个 increment 方法的底层源码,其内部会调用一个add方法,内部会进行比较交互操作
public void add(long x) {Cell[] as; long b, v; int m; Cell a;if ((as = cells) != null || !casBase(b = base, b + x)) {boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 ||//求余操作,判断会进入哪个槽位(a = as[getProbe() & m]) == null ||//自旋,比较和交换的操作!(uncontended = a.cas(v = a.value, v + x)))//计算longAccumulate(x, null, uncontended);}
}
随后通过调用 longAccumulate 方法,对这些值进行计算的操作,计算的方法如下,内部会涉及到的一些变量也快给列了出来
//处理器的个数,inter中一个cpu对应两个处理器
static final int NCPU = Runtime.getRuntime().availableProcessors();
//拆分数组
transient volatile Cell[] cells;
//如果不存在竞争,则直接在这个比那里上面累加
transient volatile long base;
//加锁的标记
transient volatile int cellsBusy;
接下来直接看这个longAccumulate方法吧,有点复杂,我直接把图片贴出来了…(头痛),感兴趣的大大大佬可以自行研究一下。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xzHiWfqE-1693214340920)(img/1693212919552.png)]](https://img-blog.csdnimg.cn/648e8bb9096e4fd1be04e8fa7c31a6bb.png)
LongAdder设计的精妙之处:减少热点冲突,尽量将CAS操作延迟



![[ACL2023] Exploring Lottery Prompts for Pre-trained Language Models](https://img-blog.csdnimg.cn/7bad4bb5346f4e9081126103c162b419.png)

![[当前就业]2023年8月25日-计算机视觉就业现状分析](https://img-blog.csdnimg.cn/88bb0bfd339e4e7ea61104600df0fe0a.png)