🔆 文章首发于我的个人博客:欢迎大佬们来逛逛
主成分分析法
算法流程
- 构建原始数据矩阵 X X X ,其中矩阵的形状为 x ∗ n x * n x∗n ,有 m m m 个对象, n n n 个评价指标。
- 然后进行矩阵的归一化处理。
- 首先计算矩阵的指标之间的相关系数矩阵 R R R。使用matlab 的
corr即可得到。 - 计算相关系数矩阵 R R R 的****特征值 D D D 和特征向量 V V V** ,并且特征值从大到小排序,由特征向量组成 n n n 个新的指标向量。
- y 1 , y 2 , y 3 y_1 , y_2 , y_3 y1,y2,y3 为新的主成分。
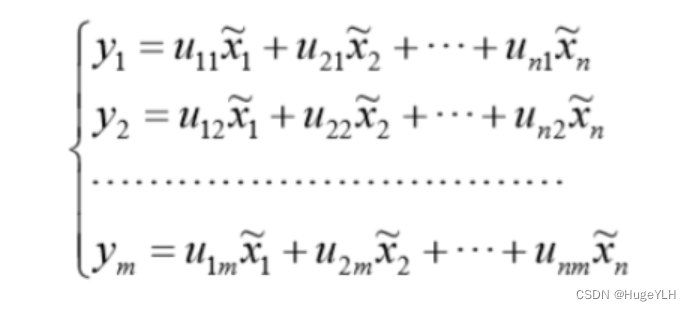
-
选择 p p p 个主成分,计算综合评价值:
-
计算特征值 λ i , i ∈ ( 1 , 2 , . . . n ) \lambda _i,i\in(1,2,...n) λi,i∈(1,2,...n) 的信息贡献率与累计贡献率:
α i = ∑ k = 1 n λ k ∑ k = 1 m λ k \alpha_i=\frac{\sum_{k=1}^n\lambda_k}{\sum_{k=1}^m\lambda_k} αi=∑k=1mλk∑k=1nλk
b j = λ j ∑ k = 1 m λ k ( j = 1 , 2 , ⋯ , m ) b_j=\frac{\lambda_j}{\sum_{k=1}^m\lambda_k}(j=1,2,\cdots,m) bj=∑k=1mλkλj(j=1,2,⋯,m)
-
找到累计贡献达到85%的位置,选择前 p p p 个指标变量 y 1 y 2 . . . y p y_1 y_2 ... y_p y1y2...yp作为新的主成分,代替原来的 n n n 个指标,从而对 p p p 个主成分进行综合分析。
Z = ∑ j = 1 p b j y j Z=\sum_{j=1}^{p}b_{j}y_{j} Z=j=1∑pbjyj
代码实现
%% A_data 是一个 m*n列的矩阵,包含 n个指标%% corr_A = corrcoef(A_data); [a,b,c] = pcacov(corr_A);%% 最后根据c的前 85% 来得到降维后的指标个数自实现:
function [Score,Vec,p]=mfunc_PCA(data)% 进行主成分分析% paramts:% data: 传递一个原始数据矩阵,需要首先进行数据的标准化mapminmax。Shape: (m*n),m为对象个数,n为指标个数% returns:% Score: 综合评价得分% Vec: (n,3)的矩阵,第一列:特征值;第二列:贡献率,第三列:累计贡献率% p:指标降维后的个数% 计算指标的相关系数矩阵R=corr(data);%计算特征向量和特征值[V,D] = eig(R); %V特征向量,D特征值对角线矩阵lam=diag(D);%取出对角线元素%对特征值从大到小排列[lam_sort,index]=sort(lam,'descend');V_sort=V(:,index);Vec = zeros(length(lam_sort),3);Vec(:,1) = lam_sort;contribution=lam_sort./sum(lam_sort); %贡献率Vec(:,2) = contribution;cContribution=cumsum(contribution); %累计贡献率Vec(:,3) = cContribution;p=find(cContribution>=0.85); p=p(1); %找到累计贡献达到85%的位置第一个位置%M=data*V_sort;M=M(:,1:p); %这就是得到的新的累计贡献率超过85%主成分%以下为用新的主成分评分M(:,find(sum(M)<0))=-M(:,find(sum(M)<0));%M(find(sum()))=-M(:,2);a=contribution(1:p);F=M.*a';s=sum(F');Score=100*s/max(s); end -