全文链接:http://tecdat.cn/?p=31958
分析师:Yan Liu
我国有大量的资金都流入了房地产行业,同时与其他行业有着千丝万缕的联系,可以说房地产行业对推动我国深化改革、经济发展、工业化和城市化具有不可磨灭的作用(点击文末“阅读原文”获取爬虫代码)。
目前对于二手房交易价格的预测主要考虑的是房屋价格受宏观因素的影响,如国家政策、经济发展水平、人口数量等,并据此推测地区房价及其走势,很少有从微观的角度来准确预测每间房屋的价格。
相关视频
解决方案
任务/目标
从区位特征、房屋属性和交易指标3个角度,选取包括所属区域、建筑面积、楼层高度、周边银行数量、学校数量、电影院数量等在内的多维度特征,帮助客户来预测二手房的挂牌价格,实现基于数据的科学决策,做到一房一价的精准预测。
数据 获取
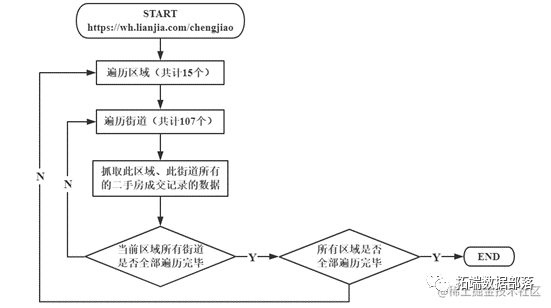
(1)在链家网上,武汉市区域被划分为15个区,共107个街道,每个页面展示30条房屋数据,通过翻页最多可以达到100页,即3000条数据。为了能尽可能保证抓取到链家上所有的数据(查看文末了解爬虫代码免费获取方式),根据深度优先算法思想,采用先遍历区域,再遍历街道的遍历思路来设计爬虫。
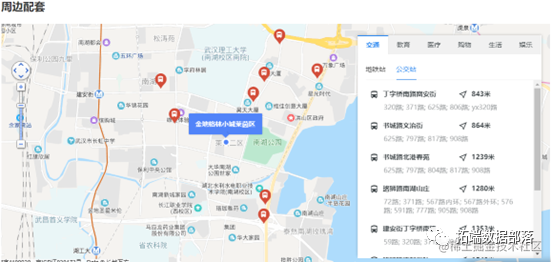
(2)周边配套设施,房屋所在小区的经纬度数据可以从网页源代码中获得,其关键词为:resblockPosition。通过调用百度地图API可以获得上图所示的周边配套设施数量,涵盖了交通、教育、医疗、购物、生活、文娱共6大类,19个特征变量。
特征 预处理
(1)缺失值处理
通过对数据缺失值统计发现有8个变量存在缺失值:

分别使用剔除法、填充法来处理缺失值。houseStructure共有四种类型:平层、复式、错层、跃层。考虑到位于同一小区的房屋,其房屋类型大多相同,故采用此方法对缺失值进行填充:对于缺失houseStructure的房屋A,根据community_id(所属小区ID)统计出与A同小区的所有房屋,再统计出这些房屋的houseStructure的众数对A进行填充。buildingTypes、liftEquip和premisesOwnership采用和houseStructure同样的填充方法。propertyFee数据的缺失选择使用均值填充法。
分类变量的处理
对于分布极不均衡的分类变量予以剔除,对于其他分类变量做硬编码或独热编码处理
数值变量的处理
buildingTime:建成年代,数据格式均为年份(如:2018),处理方法为构造新的变量YearsDelta,其值等于2020年与其差值。
通过三σ法则剔除异常值。周边配套设施包含了一公里内的地铁站数量、幼儿园数量、医院数量等19个数值变量,通过绘制分布直方图发现不少变量的分布存在偏态。
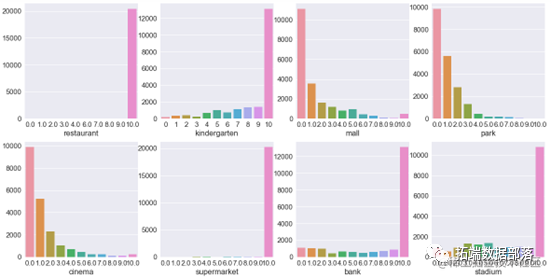
分别予以剔除或是将数值变量转换为二分类变量。
数据变换
通过绘制变量分布图,发现totalBuildings、totalHouses、totalDeals和Yearsdelta呈现出较为明显的右偏分布,而呈现偏态分布的数据是不利于最终所构建模型的效果的,因此需要对这几个变量进行纠偏处理,采用的方法为Johnson变换。

上述变量经过此方法处理前后分布对比图如下,显然,经过处理后的变量分布已近似于正态分布。

点击标题查阅往期内容

Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析

左右滑动查看更多
01
02

03
04
建模
分别建立Linear Regression模型、XGBoost模型和LightGBM模型,通过比较模型性能(评价指标使用MSE、MAE、R square)优劣,选出效果最佳的预测模型。
XGBoost和LightGBM模型的参数很多,参数取值不同,模型的性能也会有差别,因此需要对其主要参数进行调优,找出最佳参数组合。常用的调参方法为GridSearchCV(网络搜索法)和RandomizedSearchCV(随机搜索法),采用GridSearchCV进行参数调优。
XGBoost模型调优后的参数:

LightGBM模型调优后的参数:

模型性能对比
房价预测问题是一个回归问题,属于监督学习范畴。对于所得到的模型,其对未知数据的泛化能力直接决定了模型的性能优劣。因此为了对比不同模型对于未知数据的表现效果,采用十折交叉验证进行模型验证。
三种模型的10折交叉验证在测试集性能评估:

三种模型在测试集上预测情况对比:

调参后的XGBoost模型和LightGBM模型训练出的各个特征的重要性打分排序对比:

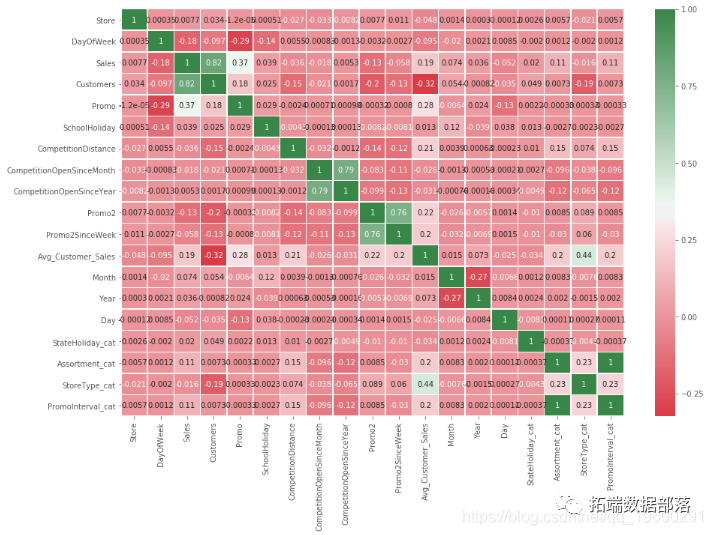
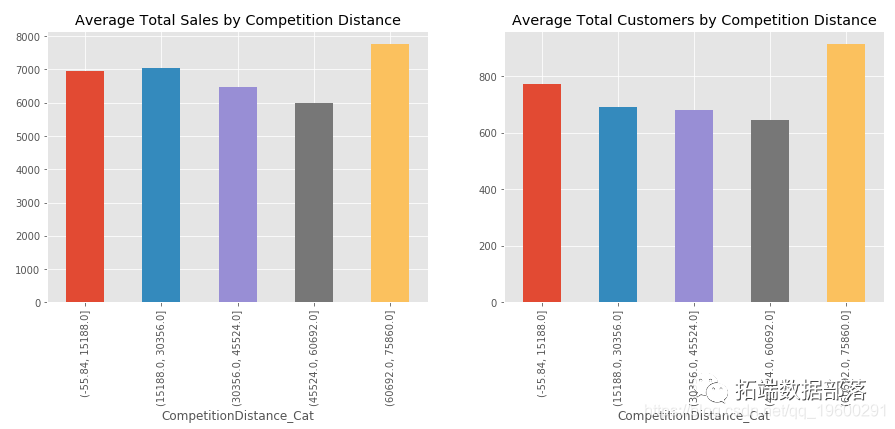
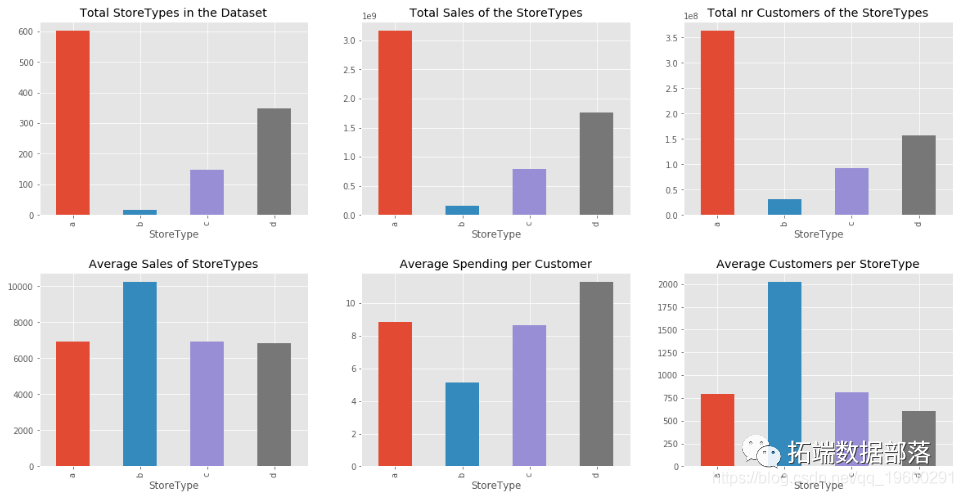
可以看出,buildingArea特征重要性得分最高,与小区情况有关的5个变量得分都排在前列;与房屋属性相关的变量,如houseFloor、houseDecoration等,得分均位于中游,对房价的影响不大;属于房屋周边设施的变量,如subwayStation、park、stadium等,得分普遍都很低,对房价影响很小。
从区位特征、房屋属性和交易指标3个角度,从链家网上通过Python网络爬虫有针对性的获取武汉市二手房成交记录中的特征数据。对原始数据通过一系列预处理,运用机器学习中的XGBoost算法、LightGBM算法和GridSearchCV算法,对处理后的数据进行建模与参数调优。将两种模型在测试集上的预测效果与训练好的Linear Regression模型进行对比,XGBoost和LightGBM在预测效果上有着显著优势。通过XGBoost和LightGBM模型学习后的特征重要性得分可知,在三类因素中,房屋建筑面积对房价的影响最大,反映房屋所属小区情况的变量重要性得分均排在前列,而其他房屋自身属性、周边配套设施的变量对价格影响较小,与大众的直观感受基本吻合。
数据获取
在公众号后台回复“爬虫代码数据”,可免费获取完整爬虫代码。

本文中分析的爬虫代码分享到会员群,扫描下面二维码即可加群!

关于分析师

在此对Yan Liu对本文所作的贡献表示诚挚感谢,他擅长数据采集、机器学习、深度学习。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python互联网大数据的武汉市二手房价格分析:Linear Regression模型、XGBoost模型和LightGBM模型》。


点击标题查阅往期内容
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()