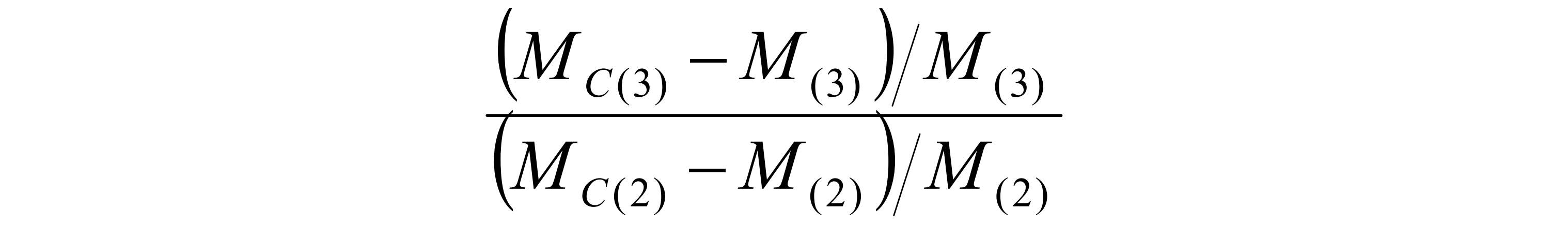DETR(基于Transformer架构的目标检测方法开山之作)
End-to-End Object Detection with Transformers
参考:跟着李沐学AI-DETR 论文精读【论文精读】
摘要
在摘要部分作者,主要说明了如下几点:
- DETR是一个端到端(end-to-end)框架,释放了传统基于CNN框架的一阶段(YOLO等)、二阶段(FasterRCNN等)目标检测器中需要大量的人工参与的步骤,例如:NMS后处理或proposals/anchors/centers生成等。使其成为一个真正意义上的端到端(end-to-end)的目标检测框架;
- DETR还可以很方便地迁移到诸如全景分割等其他任务当中,只需要在最后的FFN(前向传播头)之后增加分割头等即可;
- DETR在当时发表出来的时候(2020年5月左右)已经达到了和经过长时间调参的FasterRCNN基线一样的精度/速度/内存占用(基准为COCO2017);
介绍
DETR模型架构

第一步,将图片输入到一个CNN中,得到feature map。
第二步,将图片拉直,送入到transformer encoder-decoder。其中,encoder的作用是为了进一步学习全局的信息,为最后的decoder(也就是为最后的出预测框做铺垫)。使用transformer的encoder是为使得图片中每一个特征点与图片中的其他特征有交互,这样就知道了哪块是哪个物体。这种全局的特征非常有利于移除冗余的框(全局建模)。
第三步,decoder生成框的输出,其中输入decoder的不只有encoder的输出,还有object query(用来限制decoder输出多少个框),通过object query和特征不停的做交互(在decoder中间去做self-attention操作),从而得到最后输出的框(论文中,作者选择的框数量为N=100)。
第四步,计算出来的N=100个框与Ground Truth做匹配然后计算loss(本部分是DETR这篇文章中最重要的一个贡献)。作者使用二分图匹配的方法去计算loss,从而决定出在预测出来的100个框中,有哪几个框是与ground-truth框对应的。匹配之后,就会和普通的目标检测一样去计算分类的loss、再算bounding box的loss。剩下的没有匹配上的框就会被标记为没有物体,也就是所谓的背景类。
DETR推理流程
推理的时候前三步和训练时保持一样,第四步因为是test过程,因此只需要在最后的输出上设置一下置信度阈值即可得到预测框,(原始论文中,将置信度设置为0.7,即置信度大于0.7的预测就是前景物体,所有置信度小于0.7的就被当做背景)。
DETR特性
对大物体识别效果很好(归功于Transformer架构的全局建模能力,而不是像原来一样,预测的物体大小受限制于你设置的anchor大小),对小物体识别效果较差(后续的Deformable DETR就提出了多尺度的DETR,同时解决了DETR训练太慢的问题);
相关工作
- 集合预测(因为使用集合预测来解决目标检测问题的工作其实并不多);
- Transformer架构(同时也介绍了parallel decoding,如何不像原来的transformer一样去做自回归预测);
- 介绍了一下目标检测之前的相关工作,其中重点引用了一篇当时最近的工作,指出原来的一阶段或二阶段的目标检测器的性能与初始的猜测(proposals/anchors/centers等)密切相关,这里作者重点想讲的就是不想使用这些复杂的人工先验知识,因此DETR在这个方面具有优势;
- 然后作者介绍了基于RNN的目标检测方法,使用的是自回归模型,时效性就比较差,性能也会比较差;DETR使用了不带掩码信息的decoder之后,可以使得预测输出同时进行,所以DETR的时效性大大增强了;
文章主体部分
作者首先介绍了基于二分图匹配的loss目标函数(因为这点比DETR这种架构来说更新,同时DETR架构是比较标准的,比较容易理解的,即便是其中的object query思想,也比较容易讲解,因此作者首先介绍了目标函数),也正是因为这种目标函数,DETR才能做到一对一的预测出框方式。
二分图匹配
举例理解:假如说有三个工人abc,然后需要完成三个工作xyz,因为所有工人的特点不一样,因此三个工人完成工作的时间等都不一致,因此对三个工人和三个不同的工作来说,会有一个 3 × 3 3\times3 3×3的矩阵,矩阵中对应的每个格子具有不同的数值(这个矩阵就叫做cost matrix,也就是损失矩阵);那么,这个二分图匹配的最终目的是:我可以给每个工人找到最擅长的工作,然后使得这三个人完成工作之后的代价最低;
匈牙利算法就是解决这样一个问题的比较好的方式。
scripy库中,包含匈牙利算法的实现:line_sum_assignment。DETR原始论文中使用的也是这个;
这个方法返回的结果就是一个全面的排列:告诉你哪个人应该做哪个事;
其实,DETR将目标检测问题看成是集合预测问题,其中每个工人可以看成是对应的N=100的预测框,然后xyz表示GroundTruth框;
那么,这个cost matrix矩阵的每个格子中放的就是每个预测框与GroundTruth框之间的cost(也就是loss);
这里的每个格子中表示的loss,就是分类损失和bbox loss,总的来说就是遍历所有预测的框,将这些框与GroundTruth进行计算loss,然后使用匈牙利算法得到最匹配的对应的图片中目标数量的框;
然后,作者又说,这里与一阶段/二阶段的目标检测器一样的道理,都是拿着预测出来的框与GroundTruth逐个计算loss。但是,唯一不同的地方在于DETR是只得到一对一的匹配关系,而不像之前方法一样得到一对多的匹配关系,这样DETR就不需要做后边的NMS后处理步骤。
loss目标函数
接下来,由于前边步骤得到了所有匹配的框,那么现在才计算真正的loss来做梯度回传。DETR在计算真正的loss(分类loss和bbox loss),其中对于分类loss,作者和原来的计算分类loss方法不一样,而是将DETR中这个地方的log去掉(作者发现去掉之后效果会更好一些)。然后对于bbox loss这里,与之前的loss计算方式也有所不同,原来计算bbox loss是使用L1 loss,但是l1 loss会出现框越大,计算出来的loss容易越大。而同时DETR这种基于Transformer架构的模型,对大目标(预测出大框很友好),那么得到的loss就会比较大,不利于优化。因此,作者不光使用了l1 loss,还使用了GIoU loss。这里的GIoU loss就是一个与框大小无关的loss函数。
DETR详细架构

上图中,CONV卷积神经网络的输出向量维度为:2048x25x34,然后使用1x1的卷积将该向量维度减少到256,得到256x25x34的向量,然后使用positional embeddings进行位置编码得到的向量维度也是256x25x34,然后将两个向量相加。
相加之后,将对应的256x25x34这个向量的HW维度进行拉直得到850x256的向量,其中850就是序列的长度,256就是Transformer的head dimension。然后,经过encoder仍然得到850x256的向量。DETR中作者使用了6个encoder。
然后,将最后一个encoder的输出向量(维度为:850x256),输入到decoder中。这里,一同输入的还有object queries(可以看作是learned embeddings,可学习的嵌入),准确地说,它就是一个可学习的positional embeddings。其维度为100x256。这里可以将这个object queries作为一个条件condition,就是告诉模型,我给你一个条件,你需要得到什么结果。接着,将两个输入(一个来自encoder编码器的输出,一个来自object queries)反复做cross attention自注意力操作。最后得到一个100x256的特征。
然后,将最后一个decoder的输出100x256维度的向量通过一个FFN(feed forward network,标准检测头,全连接层)。然后FFN做出来两个预测,一个是类别,一个是bbox位置。原始的DETR是在COCO2017上进行实验的,因此,这里的类别数量就是91类。
最后,将FFN的输出与Ground Truth根据匈牙利算法计算最佳匹配,然后根据最佳匹配计算loss,然后将loss反向传播,更新模型权重。
DETR中的一些细节
-
decoder部分,首先在object query做自注意力操作,目的是为了移除冗余的框。因为这些object query做自注意力操作之后,就大概之后每个query可能得到什么样的一个框。
-
最后做loss的时候,作者为了让这个模型收敛得更快或训练更稳定。作者在decoder之后加了auxiliary loss。作者在6个decoder的输出之后都做了这个loss。这里的FFN都是共享权重。
文章实验部分

首先,作者介绍了DETR和FasterRCNN在COCO数据集上的结果。发现DETR在大物体上检测的性能更好,而小物体上还是FasterRCNN模型更好一些。这说明DETR使用了Transformer架构,具有较高的全局建模能力,因此DETR想检测多大的目标就检测多大的目标,所以对大目标友好一些。
(延伸)写论文的技巧:当你的想法在一个数据集a上不work的时候,有可能在数据集b上work,如果你的想法很好,但是就是不work的时候,找到一个合适的研究动机其实也是很重要的,找到一个合适的切入点也很重要。

上图中,作者将Transformer encoder-decoder的自注意力机制可视化。可以看到自注意力机制的巨大威力,三只牛基本上的轮廓基本上都出来了。
实际上,当你使用transformer的encoder之后,图像上的东西就可以分的很开了,那么这个时候再去做检测、分割等任务就很简单了。

上图展示了不同的encoder数量对DETR最后目标检测精度AP的影响。可以发现,随着encoder层数的增加,AP精度是一直在上升的,且没有饱和的趋势,但是层数的增加带来了计算量的增加。

上图中展示了DETR中decoder attention的分布情况,可以明显看到在遮挡很严重的情况下,大象和小象身上的不同颜色注意力也是很区分开来的。总之,DETR这里的encoder-decoder架构的作用与CNN的encoder-decoder架构的作用其实差不多是一致的。

上图展示了20个object query的可视化结果,其中每个正方形代表一个object query,每个object query中出现的多个点表示bounding box。其中,绿色的点表示小目标物体,红色点表示水平方向的目标物体,蓝色点表示垂直方向的目标物体。实际上,这里的object query和一阶段目标检测器中的anchors差不多,只不过anchors是预先设定的,而这里的object query是通过学习得到的。总之,这100个query中就像100个问问题的人一样,每个人都会有不同的问问题的方式。需要注意的是,这些object query中都在中间有一个红线,这表示,每个query都会去询问图片中间是否包含大的目标物体,这是因为COCO数据集的问题,因为COCO数据集中很多图片中心都会有一些大物体。
总结
一些基于DETR改进的新工作:
Omni DETR, Up DETR, PnP DETR, Smac DETR, Deformable DETR, DAB DETR, Sam DETR, DN DETR, OW DETR, OV DETR,
pixel to sequence(把输入输出全部搞成序列形式,从而与NLP那边完美兼容)