特征缩放
- 🍀特征缩放的重要性
- 🌱归一化
- 🌱标准化
- 🌱更高级的缩放方法
- 🌸导入数据集&将数据集划分为训练集和测试集
- 🌸Sklearn-Learn算法实现归一化
- 🌸Sklearn-Learn算法实现标准化
🍀特征缩放的重要性
特征缩放是数据预处理中一个容易被遗忘的步骤。
决策树和随机森林是两种维数不多的不需要特征缩放的机器学习算法,这些算法不受特征缩放的影响。梯度下降优化算法的实现,如果将特征缩放到同一尺度,大多数机器学习和优化算法将会表现得更好。
可以通过一个简单的例子,来说明特征缩放的重要性。
假设有两个特征,一个特征的值为在1到10之间,另一个特征的值在1到100000之间。
例如使用Adaline的平方差损失函数,可以说算法主要根据第二个特征优化权重,因为第二个特征主导平方差损失函数值。
另一个例子是k近邻算法,k近邻算法使用欧式距离度量样本间的距离,这样样本间的距离将由第二个特征轴控制。
标准化和归一化是两种常见的可以将特征值调整到同一尺度的方法。
🌱归一化
通常,归一化指的是将特征缩放到**[0,1]范围内,是最小最大缩放(min-max scaling)的一种特殊情况。
为了是数据归一化,可以简单地对每一个特征进行最大最小缩放**。
在下面式子中,使用最大最小缩放方法归一化一个样本的第i个特征:
x n o r m ( i ) = x i − x m i n x m a x − x m i n x_{norm}^{(i)}=\frac{x^i-x_{min}}{x_{max}-x_{min}} xnorm(i)=xmax−xminxi−xmin
其中, x i x^{i} xi是一个特定样本的第i个特征, x m i n x_min xmin是所有数据第i个特征中的最小值, x m a x x_max xmax是所有数据第i个特征中的最大值, x n o r m i x_{norm}^{i} xnormi是特定样本缩放后的第i个特征。
使用最大最小缩放进行数据归一化是一种常用的方法,在需要特征值位于有界区间时非常有用。
要注意的是,只能训练数据拟合MinMaxScaler类,再用拟合后的参数转换测试数据集或任何新的数据样本,这一点非常重要。
🌱标准化
但对许多机器学习算法,尤其是梯度下降类型的算法,标准化更加实用,因为许多线性模型,如逻辑回归和支持向量机,将权重初始化为0或者接近0的随机数。
标准化将特征列的中心值设置为0,标准差设置为1,这样,特征列的参数与标准正态分布(零均值和单位方差)的参数相同,从而使模型更容易学习权重。
然而,应该强调,标准化不会改变特征列的分布形状,也不会将非正态分布的特征列转换为正态分布。
除了将数据进行平移缩放使其具有零均值和单位方差之外,标准差保留了特征列的其他信息,包括异常值等。
这样,学习算法对异常值的敏感度会降低,而最小最大缩放则将数据放到有限的范围从而丢失了异常值的信息。
标准化可以用以下表达式表示:
x s t d ( i ) = x i − μ x σ x x_{std}^{(i)}=\frac{x^{i}- \mu_x}{\sigma_x} xstd(i)=σxxi−μx
这里 μ x \mu_x μx是第i个特征列的样本均值, σ x \sigma_x σx是第i个特征列的标准差。
对于由数字0到5组成的简单样本数据集,下面展示标准化和归一化两种特征缩放方法之间的差异:
| 输入 | 标准化 | 最大最小归一化 |
|---|---|---|
| 0.0 | -1.46385 | 0.0 |
| 1.0 | -0.87831 | 0.2 |
| 2.0 | -0.29277 | 0.4 |
| 3.0 | 0.29277 | 0.6 |
| 4.0 | 0.87831 | 0.8 |
| 5.0 | 1.46385 | 1.0 |
同样,要注意的是,只能训练数据拟合StandardScaler类,再用拟合后的参数转换测试数据集或任何新的数据样本,这一点非常重要。
🌱更高级的缩放方法
Scikit-Learn还提供了其他更高级的特征缩放方化,例如RobustScaler。如果数据集是包含许多异常值的小数据集,那么RobustScaler尤其有用,并推荐使用。
类似地,如果机器学习算法很容易过拟合该数据集,那么RobustScaler也是一个不错的选择。RobustScaler独立处理数据的每个特征列。具体来讲,RobustScaler调整中位数为0,并根据数据集的第1和第3四分位数对数据进行缩放,以减小极值和异常值的影响。
🌸导入数据集&将数据集划分为训练集和测试集
import pandas as pd
df=pd.read_excel("D:\A_data\Data_wine数据\wine.xlsx")
from sklearn.model_selection import train_test_split
X,y=df.iloc[:,1:].values,df.iloc[:,0].values
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.3,random_state=0,stratify=y)
🌸Sklearn-Learn算法实现归一化
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
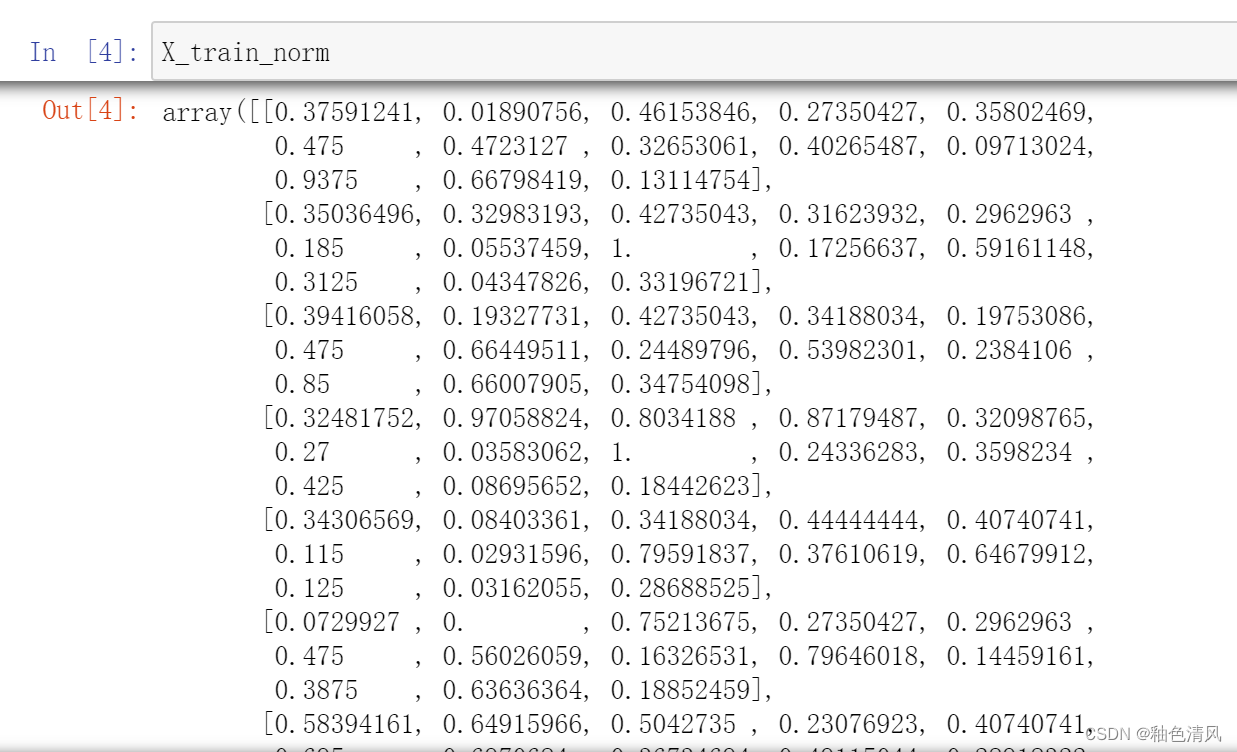
X_train_norm=mms.fit_transform(X_train)
X_test_norm=mms.transform(X_test)
🌸Sklearn-Learn算法实现标准化
from sklearn.preprocessing import StandardScaler
stdsc=StandardScaler()
X_train_std=stdsc.fit_transform(X_train)
X_test_std=stdsc.transform(X_test)

![[Linux]进程程序替换](https://img-blog.csdnimg.cn/img_convert/1c00060c235a79e036660c24ca8b853d.png)