背景
需要大批量压测时,单机发出的压力能力有限,需要多台jmeter来同时进行压测;发压机资源不够,被压测系统没到瓶颈之前,发压机难免先发生资源不足的情形;反复压测时候也需要在不同机器中启动压测脚本,更改脚本变动麻烦,收集压测数据难,启动和关闭压测进程难,分布式压测可以让压测时机的把控更准确,实现自由伸缩,一次配置,随处运行。
本文可实现从0到1搭建体系
可能面对的缺点:
1. 单台并发量不够,发压机资源不足
2. 手动方式在不同发压机上脚本更改麻烦
3. 测试结果难以整理
4. 扩增新节点发压时调试麻烦
5. 压测开始/结束时间点无法统一,手动操作有误差
6.长时间压测时,压测数据积压问题。超过1G的压测结果会出问题,严重影响磁盘IO(可更改采点时间间隔,但不是所有场景都适用如果想看到更细粒度数据就会很吃力)。
7. 压测数据保存。每次压测默认会覆盖上次的结果,虽然可以更改复写机制,但总会有超过阈值大小的时间,如果可能 保存到数据库更好。
8. 压测数据展示,不太美观。每次压测完需要根据jtl文件生成html报告
9. 发压机资源监控,无法知道发压机是否达到资源瓶颈,是否需要添加额外服务器,此举可有效节约服务器资源。
10. 每次执行都需要登录服务器进行操作,是否可集成到Jenkins中,每次运行直接在web端指定IP地址,进行压测?(需详细调研加以尝试)
一台Master,一台Slave,每次扩展只需要对Slave打一个镜像,拷贝几个相应虚拟机,压测时直接指定相应IP地址
搭建阶段
1.集群压测+数据入库
2.发压机指标监控
3.CI/CD集成Jenkins (待定)
Jmeter 分布式集群搭建
一. 分布式压测注意点
1、运行相同版本的JMeter(两台机器版本不一致,需要重新升级)
2、使用相同的java版本
3、都在一个网段
4、server.rmi.ssl.disable开关一致
5、关闭防火墙
6、使用的JMeter插件一致
7、如果压测的是java脚本,需要将java脚本和相关lib包都放在jmeter目录lib/ext下,在每一台机器上都得有脚本文件和依赖的jar包(如果是http脚本,在Master的机器上有脚本文件即可)
8、将jmeter的场景文件jmx上传到Master jmeter的任意位置,参数文件需要放到每一台压力机上(如果脚本中涉及从外部读取的csv文件,那该文件就需要上传到各个slaver施压机上) 9、关闭运行时千万不要通过control+c终止运行,需要再开一个窗口,在主jmeter的bin目录下"./shutdown.sh" 就会向从压力机发布指令,结束运行;
10、若是脚本中设置的并发线程数是100,采用3台slaver机器去施加压力,那么对于服务端来说,此时的并发线程数是300。
二. Jmeter分布式压测原理了解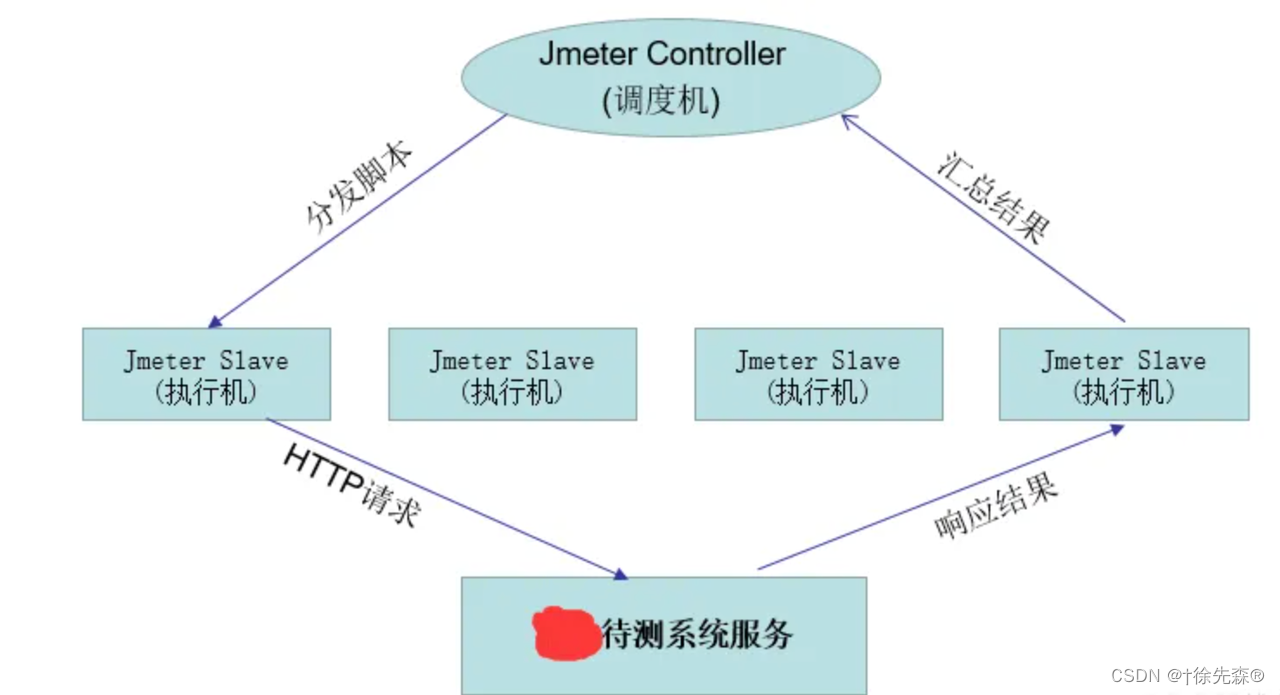
1、分为控制器(controller)和代理(agent),也有人叫master机和slave机(总控机器的节点master,其他产生压力的机器叫“肉鸡” server) 2、master会把压测脚本发送到 server上面
3、执行的时候,server上只需要把jmeter-server打开就可以了,不用启动jmeter 4、结束后,server会把压测数据回传给master,然后master汇总输出报告
controller 作为控制器不加入实际测试,只负责发送和收集 agent 信息。
三.参数优化
1. 控制台 取样 间隔的设置(linux中的日志输出时间间隔)
summariser.interval=10,默认时间为30秒,最低可修改为6秒 (在jmeter的bin目录下 jmeter.properties)2. JVM优化 (按照4c 8g配置)
因为整台服务器就是为性能测试使用,所以jvm堆栈可以调到最大比例,防止压测时发压机OOM异常。修改jmeter的bin目录下,vi jmeter,修改HEAP的size大小如下,也可以设置为6G,建议自测调整JVM大小
"${HEAP:="-Xms4g -Xmx4g -XX:MaxMetaspaceSize=512m"}"3. 修改默认编码
sampleresult.default.encoding=UTF-84. linux中没有实时输出日志
解决不输出实时日志:修改配置文件jmeter.properties中的配置项
找到 #summariser.ignore_transaction_controller_sample_result=true 改为 summariser.ignore_transaction_controller_sample_result=false5. 进入jmeter的bin目录下,修改reportgenerator.properties
修改 jmeter.reportgenerator.overall_granularity=1000 (报表中数据展示间隔1秒钟)6. 打开主从机器交互配置,修改jmeter.properties文件
将server.rmi.ssl.disable=true(去掉注释)【主从之间默认是https的,在局域网内部使用,没有必要使用https方式】7. 指定运行 slave节点,二选一配置
本机通过第二种方式
更改bin/jmeter-server,指定RMI_HOST_DEF=-Djava.rmi.server.hostname=本机内网ip,或者通过运行命令指定本机IP来启动nohup ./jmeter-server -Djava.rmi.server.hostname=192.168.0.107 &
否则会报错如下:
Server failed to start: java.rmi.RemoteException: Cannot start. localhost.localdomain is a loopback address. An error occurred: Cannot start. localhost.localdomain is a loopback address.8.压测执行 顺序
1. slave以server方式执行
执行命令如下(需要确认下新开的slave 是否会执行该命令 加载环境变量 将本机IP刷到Jmeter参数中)
该命令会将slave上的Jmeter以后台方式运行,并且将当前机器ip添加到jmeter-server配置中
localhostPrivateIp=$(/sbin/ifconfig -a eth0 |grep inet|grep -v 127.0.0.1|grep -v inet6 | awk '{print $2}' | tr -d "addr:") && nohup ./jmeter-server -Djava.rmi.server.hostname=$localhostPrivateIp &2.Master压测
运行时需要指定—R 127.0.0.1 128.0.0.1
jmeter -n -t getUserInfoById.jmx -l res.jtl -R 112.16.63.227(slave的内网ip地址英文逗号分隔)如果想要压测执行,请在Master节点中
进入jmeter/bin/目录下
运行 ./shundown.sh 实时数据展示平台搭建
使用Docker+Nginx+Prometheus+Grafana+Influxdb+Node-exporter方式
1.InfluxDb部署和配置
拉取镜像
docker pull influxdb:1.7.10启动容器
(后面的命令是为了让容器和宿主机的时间一致,避免因时间不一致导致的数据不显示问题)docker run -d --name=influxdb -p 8086:8086 -v ${PWD}:/var/lib/influxdb influxdb:1.7.10 /etc/localtime:/etc/localtime进入容器
docker exec -it influxdb bash 输入命令
influx进入influx内部
show databases;
查看influxdb现有数据库使用命令
create database jmeter;
创建名为jmeter的数据库use jmeter;
使用该数据库 show measurements;
查看下面具备哪些表select * from "表名字";
查看表中具有哪些数据
效果展示

2.Grafana部署
Grafana就是一个报表展示平台,相比来说配置和安装更加容易,Grafana版本之间可能会有稍许差别,此处使用版本9.3.2;
拉取镜像
docker pull grafana/grafana:9.3.2运行镜像
(--link 是为了让grafana和influxd网络互通)
docker run -d --name=grafana --link=influxdb:influxdb -p 3000:3000 grafana/grafana:9.3.2效果截图

3.Prometheus部署和配置
注意
首先在tmp目录下新建prometheus和prometheus.yml文件
prometheus+docker方式部署+加载Nginx端口转发配置+允许热加载node-exporter+挂在配置文件到宿主机+prometheus允许后缀名方式访问(和Nignx配置对应)
拉取镜像
docker pull pro/prometheus 运行镜像
docker run -d -p 9090:9090 -v /tmp/prometheus:/etc/prometheus --name=prometheus prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.route-prefix=/ --web.external-url=/prometheus/ --web.enable-lifecycle 安装完prometheus并配置好Nginx和Node-exporter 后可访问IP/prometheus/ ,查看prometheus配置了几个node-exporter

4.Nginx 部署(Yum方式)
yum install -y nginx 安装完nginx , 修改配置文件,在/etc/nginx/nginx.conf
运维给我开通的是外网80端口,所以我就直接用80端口代理Grafana的web页面
完整http块内的配置如下(可能有的配置冗余,但也懒得去排查修改了)
http {log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 65;types_hash_max_size 4096;include /etc/nginx/mime.types;default_type application/octet-stream;# Load modular configuration files from the /etc/nginx/conf.d directory.# See http://nginx.org/en/docs/ngx_core_module.html#include# for more information.include /etc/nginx/conf.d/*.conf;server {listen 80;listen [::]:80;server_name _;root /usr/share/nginx/html;location /prometheus/{proxy_pass http://127.0.0.1:9090/;proxy_set_header X-Real-IP $remote_addr;proxy_redirect default;proxy_http_version 1.1;proxy_set_header Upgrade $http_upgrade;proxy_set_header Connection "Upgrade";proxy_set_header Host $http_host;}location /influxdb/ {proxy_pass http://127.0.0.1:8086/;}location ^~ / {index index.html index.htm;proxy_pass http://127.0.0.1:3000/;proxy_set_header X-Real-IP $remote_addr;proxy_redirect default;proxy_http_version 1.1;proxy_set_header Upgrade $http_upgrade;proxy_set_header Connection "Upgrade";proxy_set_header Host $http_host;}# Load configuration files for the default server block.include /etc/nginx/default.d/*.conf;error_page 404 /404.html;location = /404.html {}error_page 500 502 503 504 /50x.html;location = /50x.html {}}5. Jmeter压测数据写入Influxdb
在相应Thread Group中添加Backend Listener,最好给不同的Backend Listener 起不同的名字,防止同时多脚本压测时出现数据写入混乱的问题;
-
1. 选择指定implementation
-
2.填写influxdb所在地址和端口,以及数据库名,如下截图(因为脚本要跑在Linux内网环境,所以 URL 我写的是内网IP)
-
3.measurement名字填写jmeter
-
4.application 可以填写指定名称(不同脚本)
-
5.填写的application名称会在Dashboard中的 application内显示,执行压测脚本时,会显示实时数据
-
6.Transaction 显示的是Samper名称
效果展示

6. Node-exporter部署,监控发压机
在需要监控的机器上,使用docker方式部署node-exporter
新服务器部署node-exporter 步骤
docker pull prom/node-exporterdocker run -d --net="host" --name node_exporter --restart=unless-stopped -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter然后在prometheus中配置该node-exporter所在地址和端口号 - job_name: 'Jmeter-slave-'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['IP:9100']加上新配置的node-exporter之后,使用命令在prometheus所在机器 进行 prometheus热加载更新,然后访问Prometheus web页面,确认该node-exporter是否添加到监控体系当中
curl -X POST http://ip:9090/-/reload7.Grafana展示Jmeter实时压测数据+展示Node-exporter数据
点击grafana的logo看到COMPLETE,add data source 新增数据源
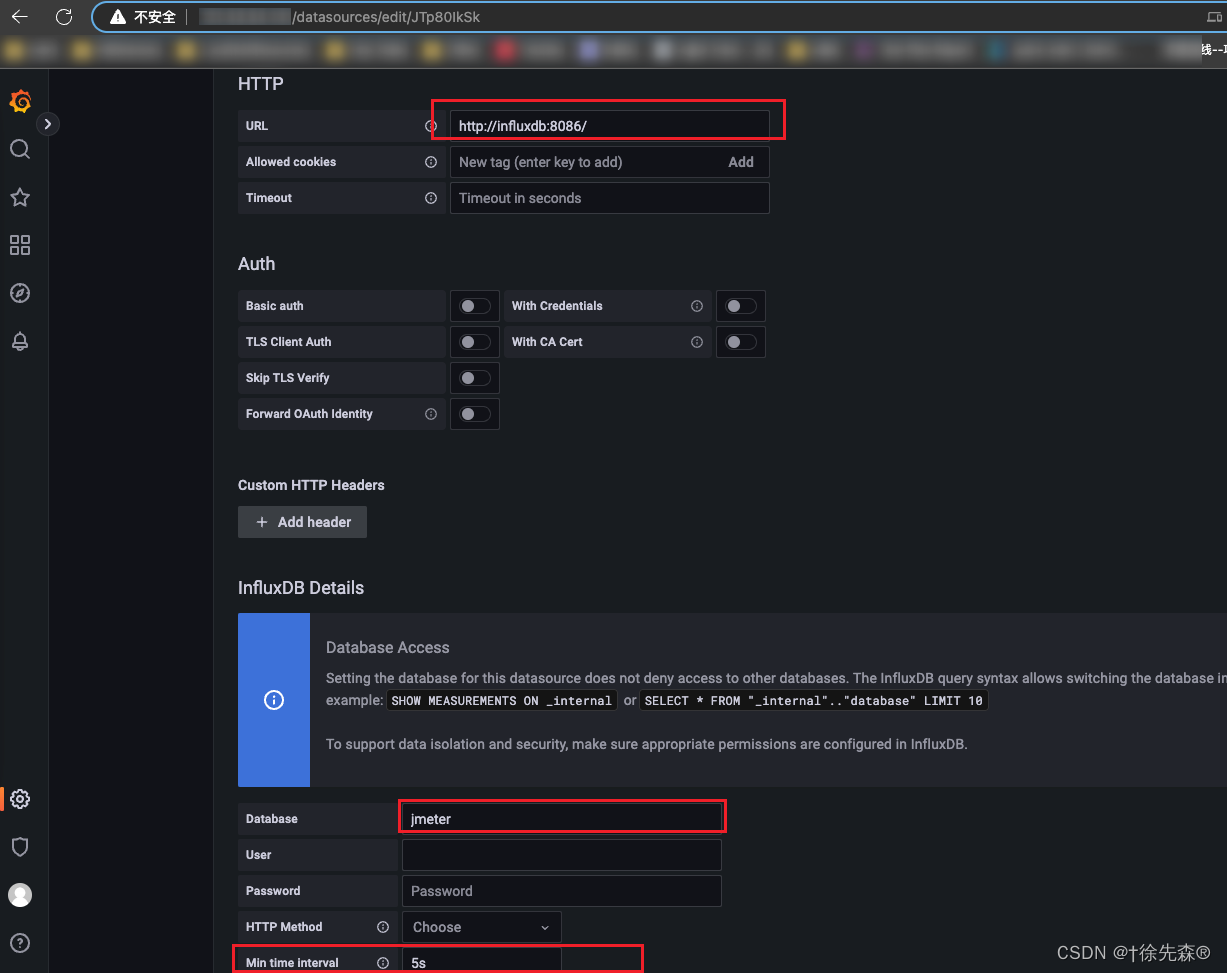
1.Grafana 配置 Jmeter压测数据源
指定docker中的influxdb:8086,并指定jmeter数据库,点击save and test 通过即成功;
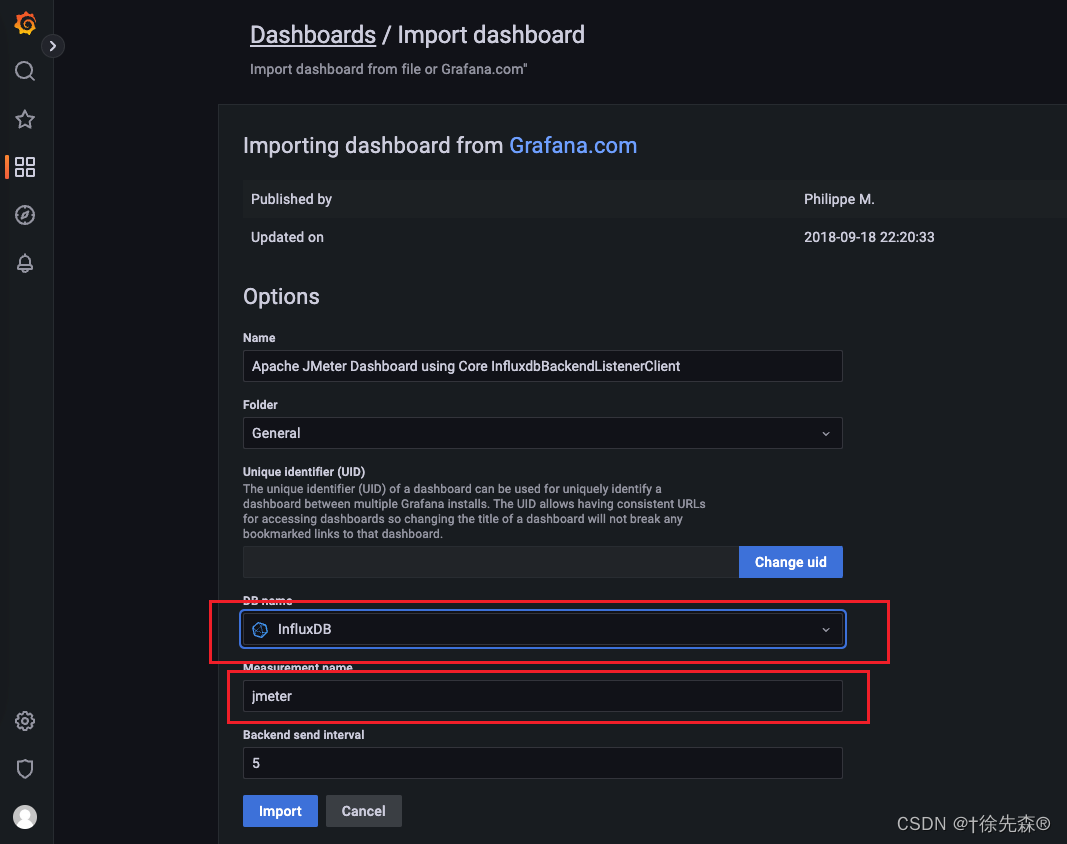
2. 展示Jmeter实时压测数据
Import 5496,点击load,加载出来后指定刚增加的data source Influxdb,指定表名字 jmeter,点击import ;

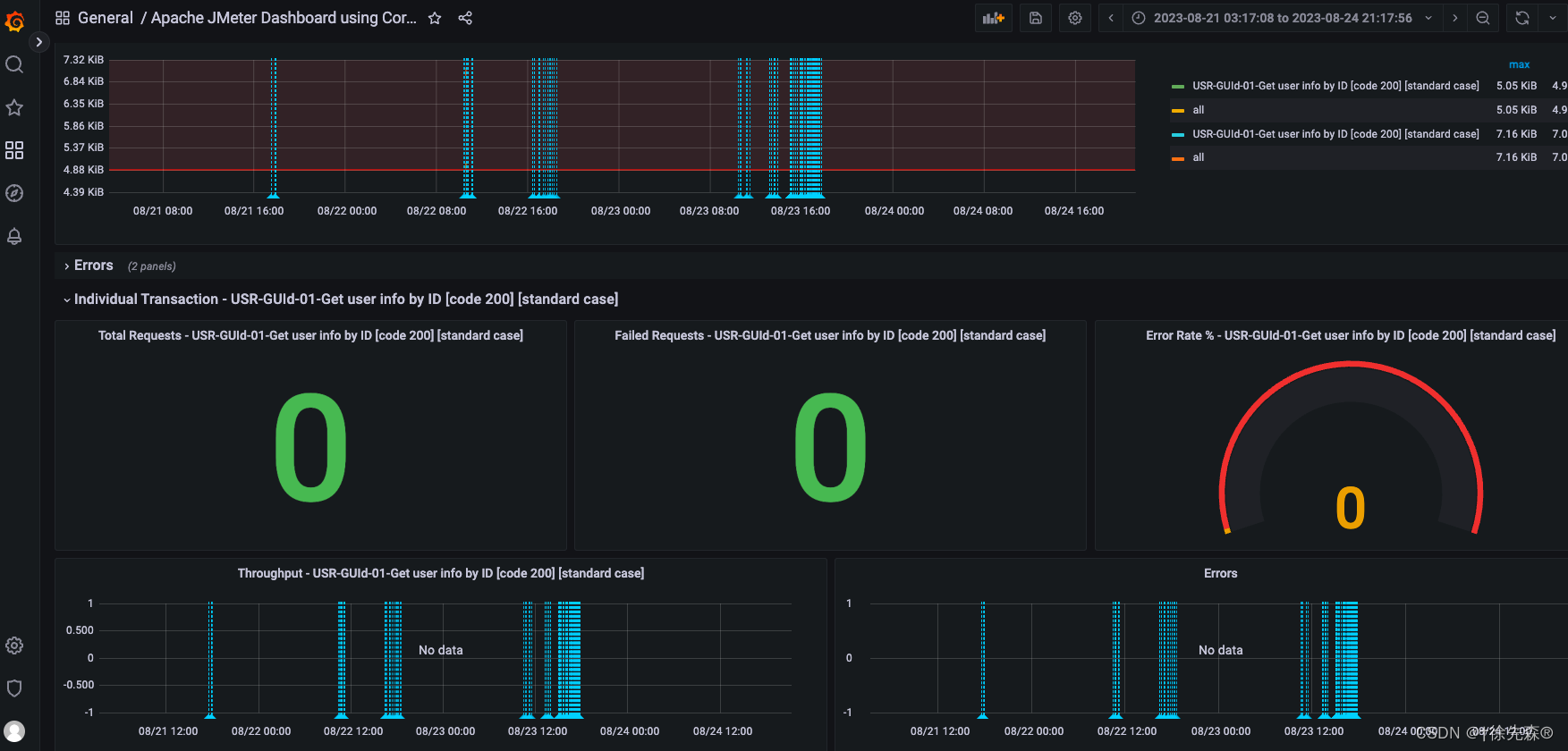
压测时即可看到实时数据,展示效果如下
application名称是Backend listener中填写的application 名称
Transaction 显示的是Samper名称

3.添加Prometheus+node-exporter主机监控数据源
仿照上述新增数据源,内网ip/prometheus/,测试通过即可

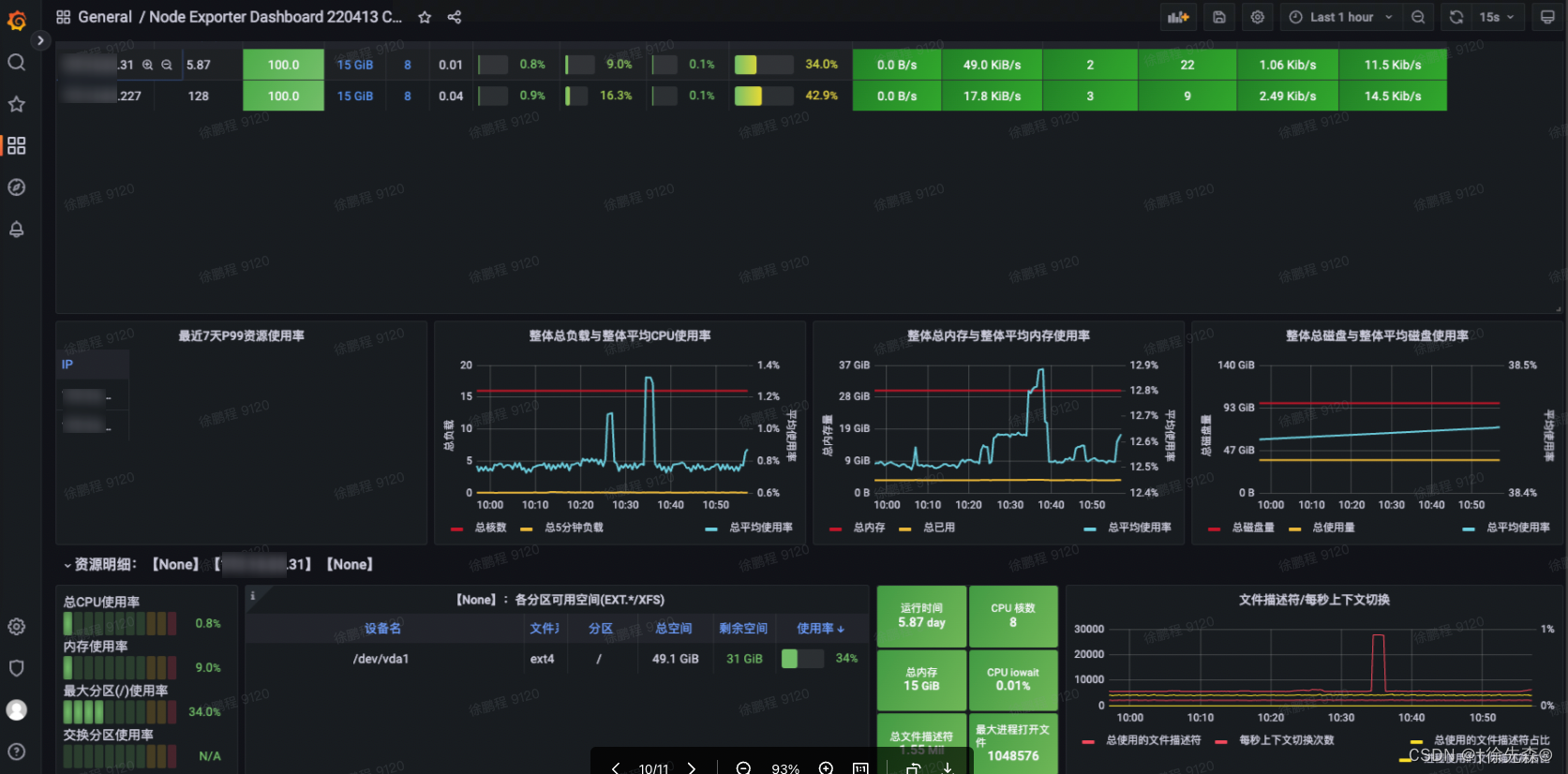
4. 展示主机监控数据,添加Dashboard
import dash board 8919,导入并保存即可
效果展示
问题总结
1. 为什么用Nginx?
因为运维只给开一个端口,但是还有那么多服务需要用,所以用作端口代理。
2. 为什么用Docker?
因为Docker部署更加方便。
3. Docker和Jmeter压测时时间不一致,无法写入数据(Grafana和Jmeter压测时间)
docker run -p 3306:3306 --name mysql -v /etc/localtime:/etc/localtime
根据需求更改启动容器时的参数,将宿主机的时间和docker时间一致(docker和宿主机在同一台机器)4. Jmeter数据无法写入Influxdb数据库,查询measurements为空
Jmeter:配置后端监听器(Backend Listener),使用Nginx作为端口转发,将Influxdb的服务映射到/influxdb路径
5.Jmeter入库后,Grafana配置数据源失败
在docker中运行时指定docker内influx的网络,配置时使用influxdb:8086
6.Grafana展示Jmeter中的数据为空
配置后端监听器measurement值为jmeter,否则读取不到数据
7.多个脚本同时执行添加了后端监听器,压测数据被写入到同一个Application库中
默认根据监听器名称进行判断监听器有没有执行,解决方案,不同后端监听器起不同的名称
8. Grafana 监控发压机 指标数据显示 no data
使用curl查看9100是否能取到node-exporter数据,如果可以取到 去prometheus web页面查看prometheus是否配置成功


![java八股文面试[JVM]——类初始化过程](https://img-blog.csdnimg.cn/06e632d5532a48cea0a0c10202c2952d.png)