Problem: 129.求根节点到叶节点数字之和
文章目录
- 题目描述
- 思路
- 复杂度
- Code
题目描述

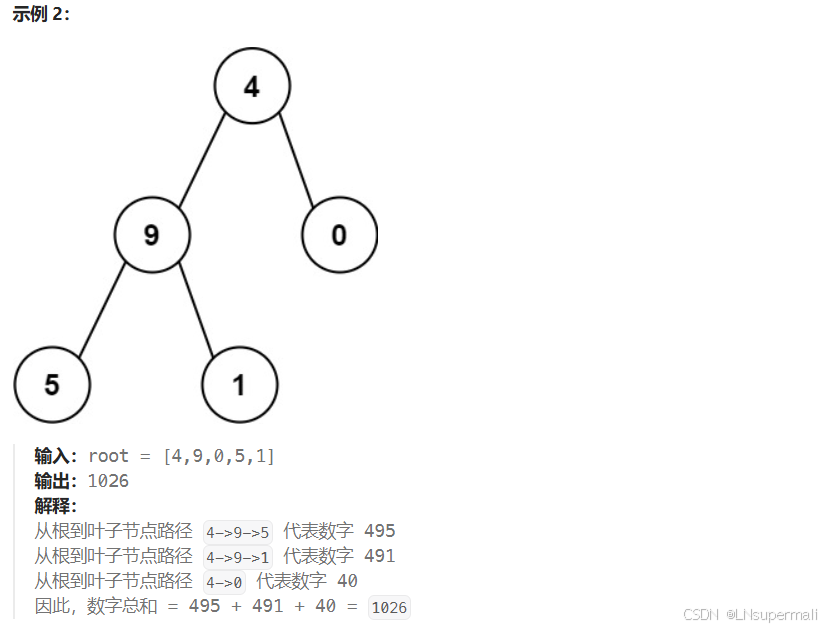

思路
遍历思想(利用二叉树的先序遍历)
直接利用二叉树的先序遍历,将遍历过程中的节点值先利用字符串拼接起来遇到根节点时再转为数字并累加起来,在归的过程中,要删除当前字符串的末尾的一个字符
复杂度
时间复杂度:
O ( n ) O(n) O(n);其中 n n n为二叉树的节点个数
空间复杂度:
O ( h ) O(h) O(h);其中 h h h为二叉树的高度
Code
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {StringBuilder path = new StringBuilder();int res = 0;public int sumNumbers(TreeNode root) {traverse(root); return res;}private void traverse(TreeNode root) {if (root == null) {return;}// In the preceding position, add the current node valuepath.append(root.val);// Values are added when the root node is encounteredif (root.left == null && root.right == null) {res += Integer.parseInt(path.toString());}//Traverse the left and right subtreestraverse(root.left);traverse(root.right);// Then iterate over the location and undo the node valuepath.deleteCharAt(path.length() - 1);}
}






![HTB:Alert[WriteUP]](https://i-blog.csdnimg.cn/direct/9539aadeb7d141c88823d4a41fc271d5.png)
![96,【4】 buuctf web [BJDCTF2020]EzPHP](https://i-blog.csdnimg.cn/direct/72964dc37a2e465b9e90cc11bdb03dce.png)