1.创建基础物体
层级面板右键

2.创建C#脚本
点击资源浏览器 - 右键



脚本组件需要挂在到一个物体上才能运行
点击立方体 - 添加组件

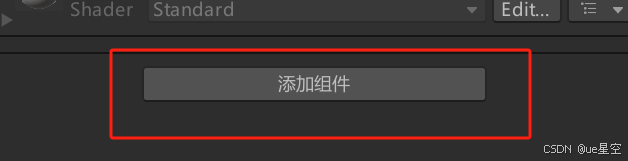

点击运行

3.安装Shader Graph


1.创建基础物体
层级面板右键
2.创建C#脚本
点击资源浏览器 - 右键
脚本组件需要挂在到一个物体上才能运行
点击立方体 - 添加组件
点击运行
3.安装Shader Graph
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/11483.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!







![HTB:Alert[WriteUP]](https://i-blog.csdnimg.cn/direct/9539aadeb7d141c88823d4a41fc271d5.png)
![96,【4】 buuctf web [BJDCTF2020]EzPHP](https://i-blog.csdnimg.cn/direct/72964dc37a2e465b9e90cc11bdb03dce.png)