数据并行DP
数据并行的核心思想是:在各个GPU上都拷贝一份完整模型,各自吃一份数据,算一份梯度,最后对梯度进行累加来更新整体模型。理念不复杂,但到了大模型场景,巨大的存储和GPU间的通讯量,就是系统设计要考虑的重点了。在本文中,我们将递进介绍三种主流数据并行的实现方式:
- DP(Data Parallelism):最早的数据并行模式,一般采用参数服务器(Parameters Server)这一编程框架。实际中多用于单机多卡
- DDP(Distributed Data Parallelism):分布式数据并行,采用Ring AllReduce的通讯方式,实际中多用于多机场景
- ZeRO:零冗余优化器。由微软推出并应用于其DeepSpeed框架中。严格来讲ZeRO采用数据并行+张量并行的方式,旨在降低存储。
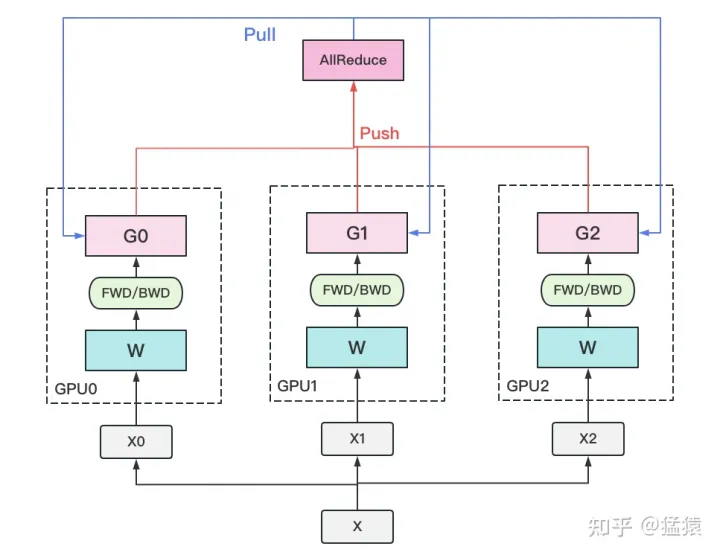
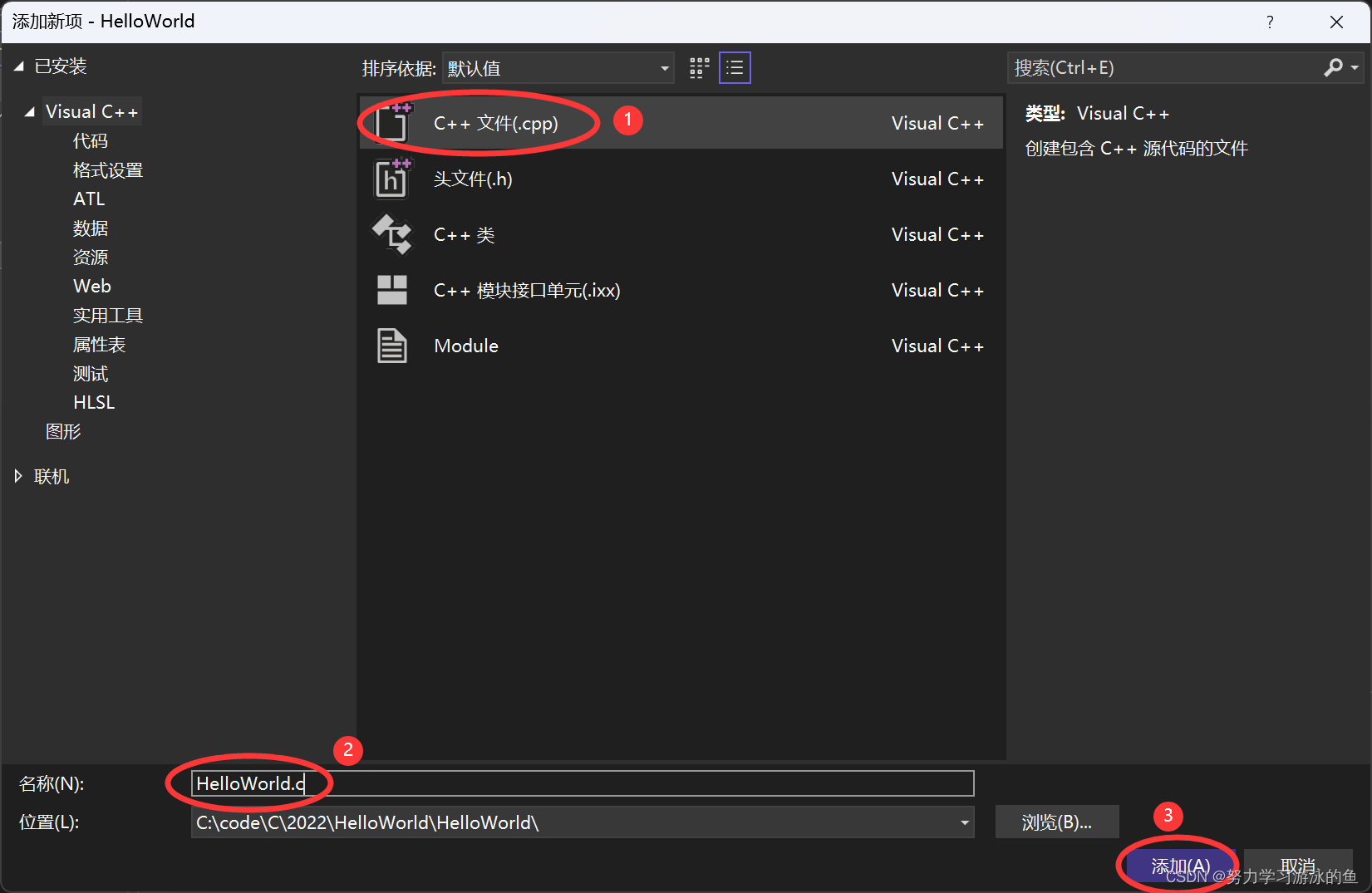
1)若干块计算GPU,如图中GPU0~GPU2;1块梯度收集GPU,如图中AllReduce操作所在GPU。
2)在每块计算GPU上都拷贝一份完整的模型参数。
3)把一份数据X(例如一个batch)均匀分给不同的计算GPU。
4)每块计算GPU做一轮FWD和BWD后,算得一份梯度G。
5)每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。
6)梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。
7)聚合再下发梯度的操作,称为AllReduce。
- 总结一下:打散 – 收集 – 反向分发(更新)
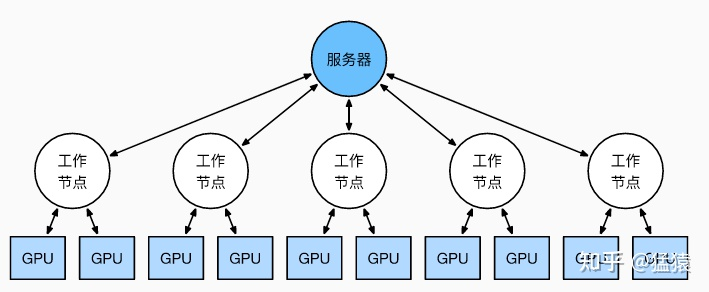
实现DP的一种经典编程框架叫“参数服务器”,在这个框架里,计算GPU称为Worker,梯度聚合GPU称为Server。在实际应用中,为了尽量减少通讯量,一般可选择一个Worker同时作为Server。比如可把梯度全发到GPU0上做聚合。需要再额外说明几点:
- 1个Worker或者Server下可以不止1块GPU。
- Server可以只做梯度聚合,也可以梯度聚合+全量参数更新一起做
- 在参数服务器的语言体系下,DP的过程又可以被描述下图
那么问题所在:
- 存储开销大。每块GPU上都存了一份完整的模型,造成冗余。
- 通讯开销大。Server需要和每一个Worker进行梯度传输。当Server和Worker不在一台机器上时,Server的带宽将会成为整个系统的计算效率瓶颈。
概括一下:每一个节点干完自己的活儿提交上去,等sever的反馈更新,这个等待的过程就是浪费时间,且sever的压力非常大。
所以,梯度异步更新的idea就出来了
在梯度异步更新的场景下,某个Worker的计算顺序为:
- 在第10轮计算中,该Worker正常计算梯度,并向Server发送push&pull梯度请求。
- 但是,该Worker并不会实际等到把聚合梯度拿回来,更新完参数W后再做计算。而是直接拿旧的W,吃新的数据,继续第11轮的计算。这样就保证在通讯的时间里,Worker也在马不停蹄做计算,提升计算通讯比。
- 当然,异步也不能太过份。只计算梯度,不更新权重,那模型就无法收敛。图中刻画的是延迟为1的异步更新,也就是在开始第12轮对的计算时,必须保证W已经用第10、11轮的梯度做完2次更新了。
意思就是,work的参数阶段性更新,隔多久更新一次由延迟时间步决定
三种更新方式:
(a) 无延迟
(b) 延迟但不指定延迟步数。也即在迭代2时,用的可能是老权重,也可能是新权重,听天由命。
(c ) 延迟且指定延迟步数为1。例如做迭代3时,可以不拿回迭代2的梯度,但必须保证迭代0、1的梯度都已拿回且用于参数更新。
总结一下,异步很香,但对一个Worker来说,只是等于W不变,batch的数量增加了而已,在SGD下,会减慢模型的整体收敛速度。异步的整体思想是,比起让Worker闲着,倒不如让它多吃点数据,虽然反馈延迟了,但只要它在干活在学习就行。
分布式数据并行(DDP)
受通讯负载不均的影响,DP一般用于单机多卡场景。
因此,DDP作为一种更通用的解决方案出现了,既能多机,也能单机。
- DDP首先要解决的就是通讯问题:将Server上的通讯压力均衡转到各个Worker上。实现这一点后,可以进一步去Server,留Worker。
聚合梯度 + 下发梯度这一轮操作,称为AllReduce。
接下来我们介绍目前最通用的AllReduce方法:Ring-AllReduce。它由百度最先提出,非常有效地解决了数据并行中通讯负载不均的问题,使得DDP得以实现。
- 太妙了,直接看图吧
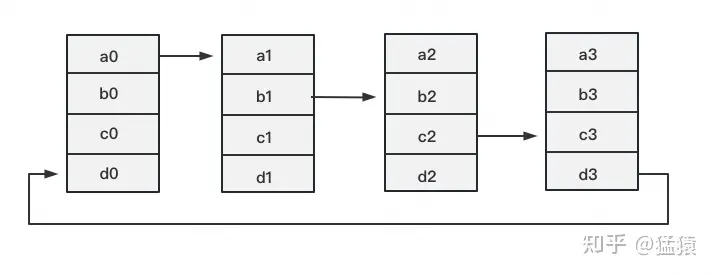
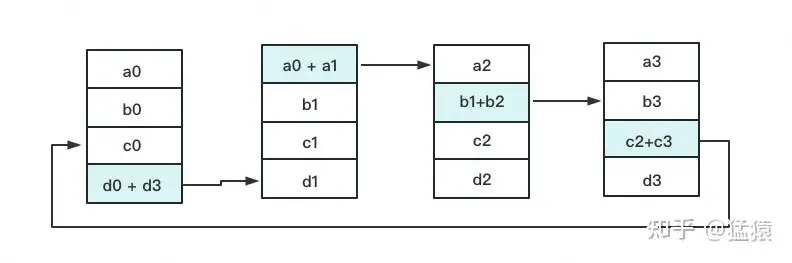
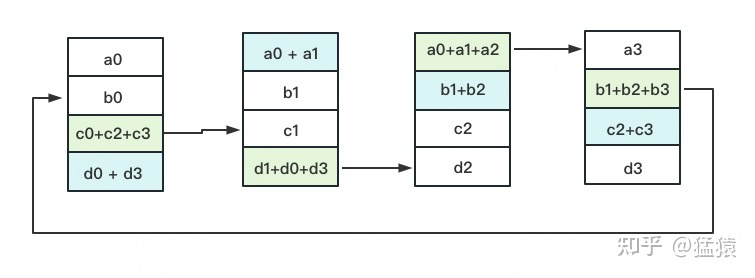
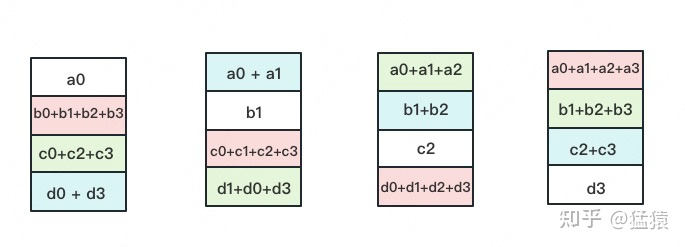
- 通过分组累加到此,每一块GPU上都有了一个分块完整的梯度,即1/4的完整梯度。谓之,Reduce-Scatter
- 下面就是将每个分开的1/4完整的梯度同步到其他的GPU,也就是替换操作。谓之,ALLTOGETHER
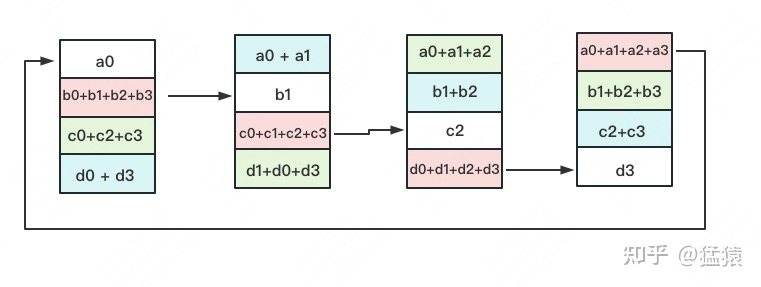
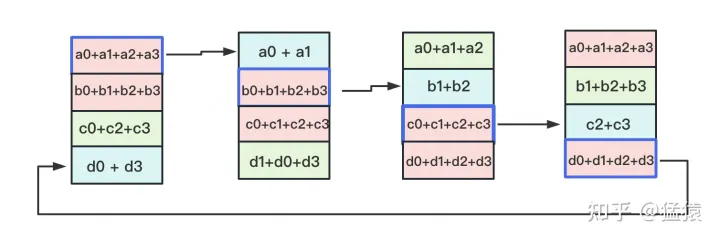
- 再迭代两轮,就OK了
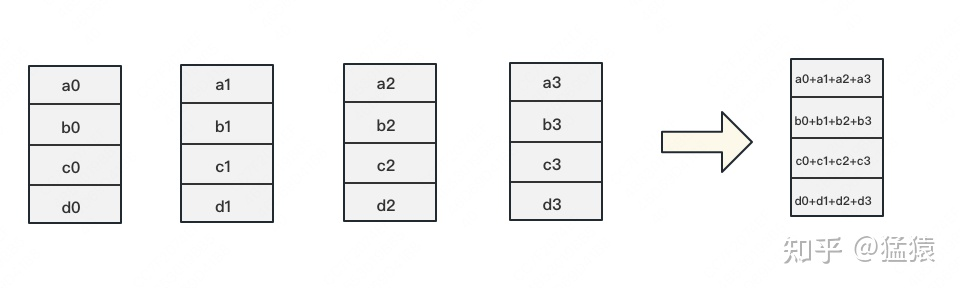

小结一下:
朴素数据并行(DP)与分布式数据并行(DDP)。两者的总通讯量虽然相同,但DP存在负载不均的情况,大部分的通讯压力集中在Server上,而Server的通讯量与GPU数量呈线性关系,导致DP一般适用于单机多卡场景。而DDP通过采用Ring-AllReduce这一NCCL操作,使得通讯量均衡分布到每块GPU上,且该通讯量为一固定常量,不受GPU个数影响,因此可实现跨机器的训练。
- DDP做了通讯负载不均的优化,但还遗留了一个显存开销问题:数据并行中,每个GPU上都复制了一份完整模型,当模型变大时,很容易打爆GPU的显存
ZeRO
由微软开发的ZeRO(零冗余优化),它是DeepSpeed这一分布式训练框架的核心,被用来解决大模型训练中的显存开销问题。
- ZeRO的思想就是用通讯换显存
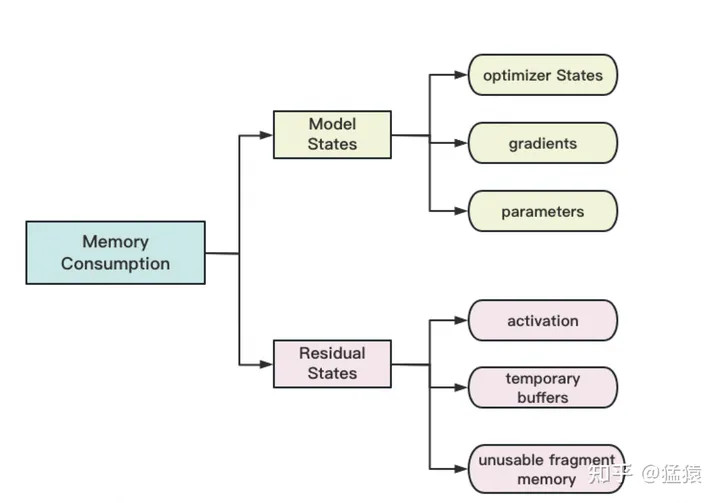
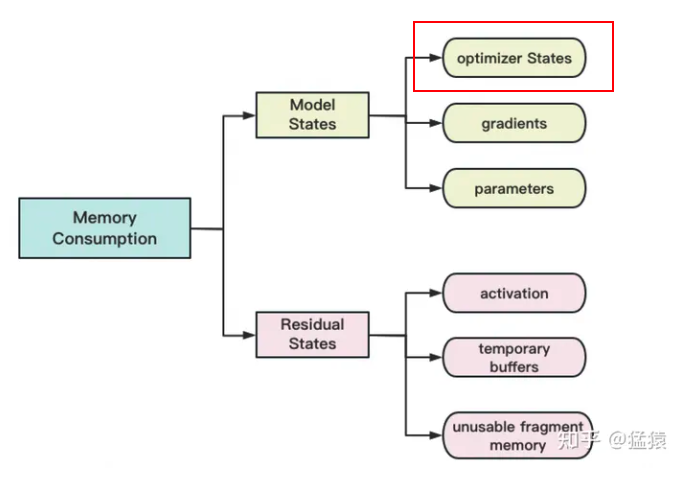
存储主要分为两大块:Model States和Residual States
Model States指和模型本身息息相关的,必须存储的内容,具体包括:
optimizer states:Adam优化算法中的momentum和variance
gradients:模型梯度
parameters:模型参数W
Residual States指并非模型必须的,但在训练过程中会额外产生的内容,具体包括:
activation:激活值。在流水线并行中我们曾详细介绍过。在backward过程中使用链式法则计算梯度时会用到。有了它算梯度会更快,但它不是必须存储的,因为可以通过重新做Forward来算它。
temporary buffers: 临时存储。例如把梯度发送到某块GPU上做加总聚合时产生的存储。
unusable fragment memory:碎片化的存储空间。虽然总存储空间是够的,但是如果取不到连续的存储空间,相关的请求也会被fail掉。对这类空间浪费可以通过内存整理来解决。
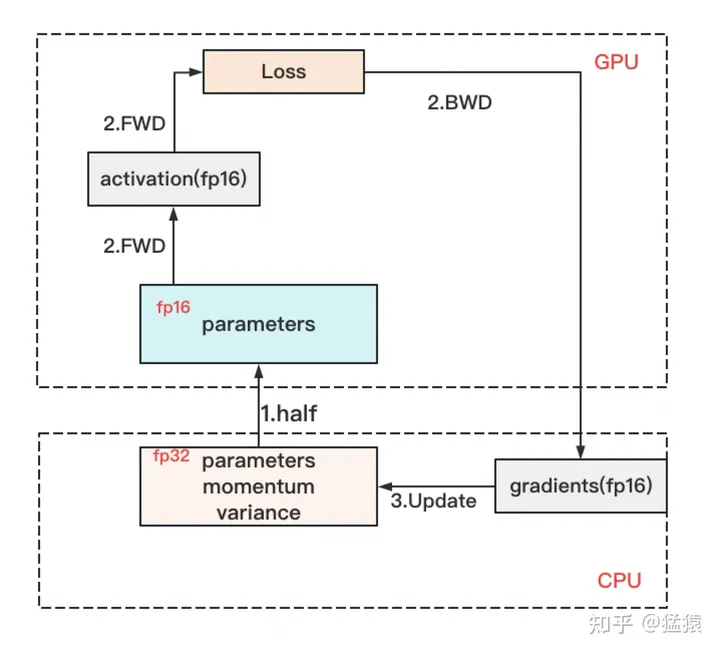
混合精度运算
精度混合训练,对于模型,我们肯定希望其参数越精准越好,也即我们用fp32(单精度浮点数,存储占4byte)来表示参数W。但是在forward和backward的过程中,fp32的计算开销也是庞大的。那么能否在计算的过程中,引入fp16或bf16(半精度浮点数,存储占2byte),来减轻计算压力呢?
于是,混合精度训练就产生了
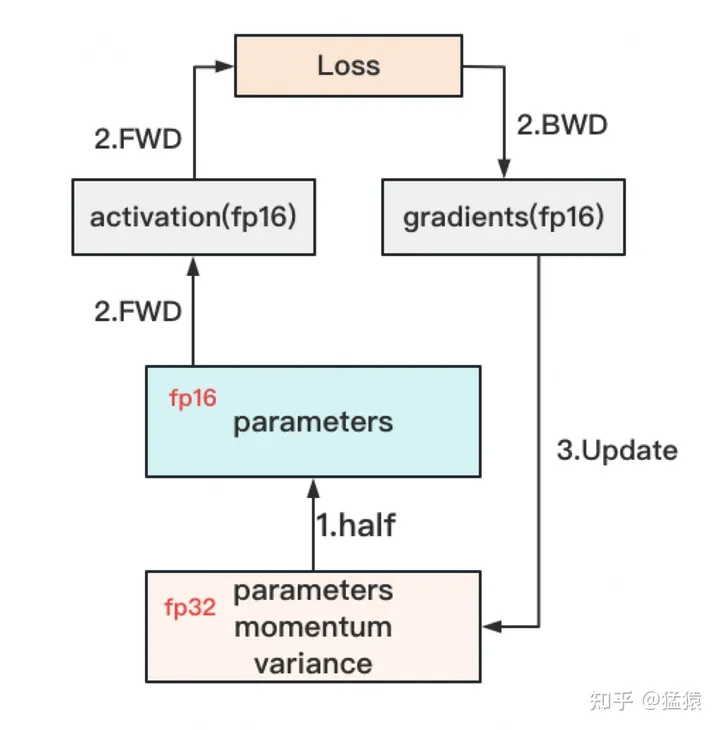
- 存储一份fp32的parameter,momentum和variance(统称model states)
- 在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter。
- 正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储。
- 用fp16 gradients去更新fp32下的model states。
- 当模型收敛后,fp32的parameter就是最终的参数输出。
也就是,模型参数存储时使用fp32,模型fw,bw计算时使用fp16
即设模型参数w为 ϕ \phi ϕ
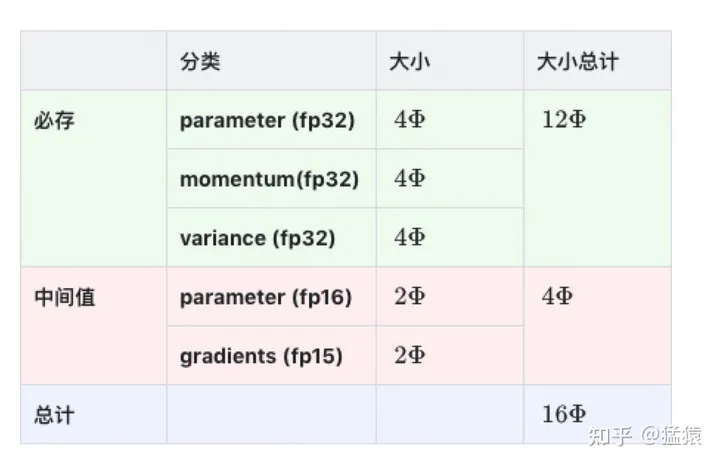
- 因为采用了Adam优化,所以才会出现momentum和variance,adam好像很费内存
这里暂不将activation纳入统计范围,原因是:
- activation不仅与模型参数相关,还与batch size相关
- activation的存储不是必须的。存储activation只是为了在用链式法则做backward的过程中,计算梯度更快一些。但你永远可以通过只保留最初的输入X,重新做forward来得到每一层的activation(虽然实际中并不会这么极端)。
因为activation的这种灵活性,纳入它后不方便衡量系统性能随模型增大的真实变动情况。因此在这里不考虑它,在后面会单开一块说明对activation的优化。
知道了什么东西会占存储,以及它们占了多大的存储之后,我们就可以来谈如何优化存储了。
注意到,在整个训练中,有很多states并不会每时每刻都用到,举例来说;
- Adam优化下的optimizer states只在最终做update时才用到
- 数据并行中,gradients只在最后做AllReduce和updates时才用到
- 参数W只在做forward和backward的那一刻才用到
所以,ZeRO想了一个简单粗暴的办法:如果数据算完即废,等需要的时候,我再想办法从个什么地方拿回来,那不就省了一笔存储空间吗?
优化状态分割
- 优化参数在模型的W中,优化状态分割的意思是把W切开,每一个GPU单独自己更新属于自己的,然后在同步一下
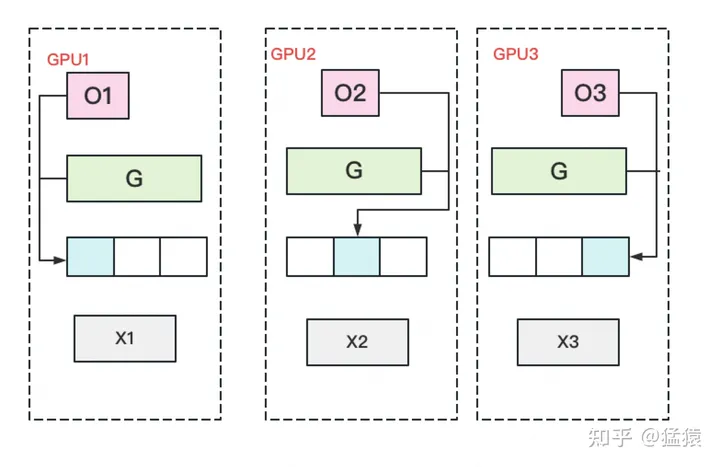
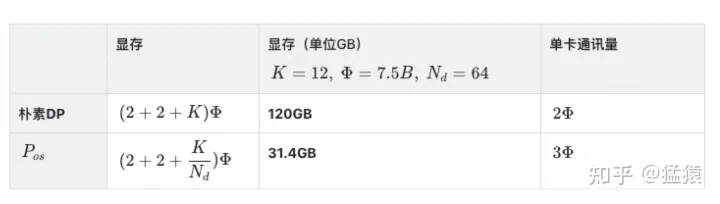
- 显存下降的非常明显, 在增加1.5倍单卡通讯开销的基础上,将单卡存储降低了4倍。看起来是个还不错的trade-off
接着切,同理可得,切梯度G
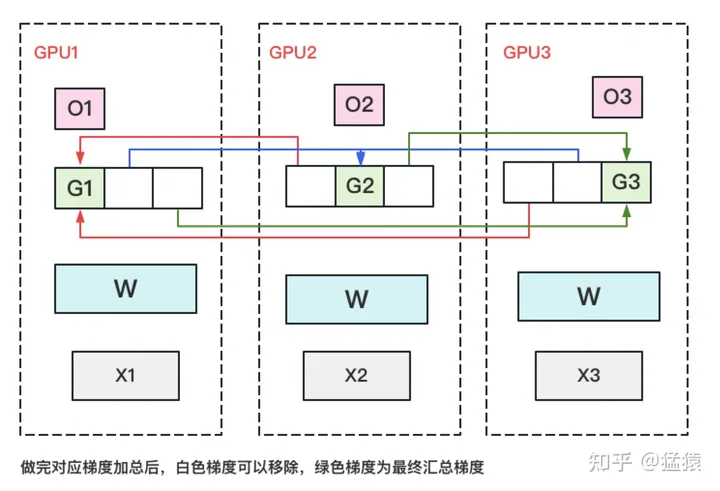
每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次All-Gather,将别的GPU算好的W同步到自己这来

全部都切开!!!
每块GPU置维持对应的optimizer states,gradients和parameters
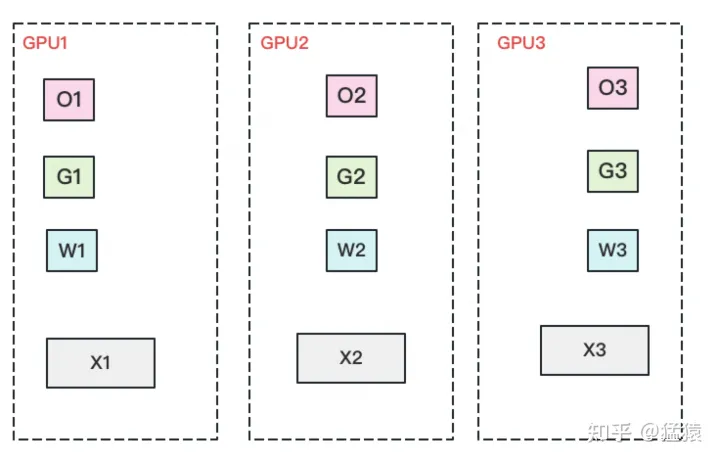
最后数据并行的流程如下:
(1)每块GPU上只保存部分参数W。将一个batch的数据分成3份,每块GPU各吃一份。
(2)做forward时,对W做一次All-Gather,取回分布在别的GPU上的W,得到一份完整的W,单卡通讯量 。forward做完,立刻把不是自己维护的W抛弃。
(3)做backward时,对W做一次All-Gather,取回完整的W,单卡通讯量 。backward做完,立刻把不是自己维护的W抛弃。
(4)做完backward,算得一份完整的梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度,单卡通讯量 。聚合操作结束后,立刻把不是自己维护的G抛弃。
(5)用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何AllReduce操作。

ZeRO - R
现在来看对residual states的优化
固定大小的内存buffer:
- 提升带宽利用率。当GPU数量上升,GPU间的通讯次数也上升,每次的通讯量可能下降(但总通讯量不会变)。数据切片小了,就不能很好利用带宽了。所以这个buffer起到了积攒数据的作用:等数据积攒到一定大小,再进行通讯。
- 使得存储大小可控。在每次通讯前,积攒的存储大小是常量,是已知可控的。更方便使用者对训练中的存储消耗和通讯时间进行预估。
设置机制,对碎片化的存储空间进行重新整合,整出连续的存储空间。
防止出现总存储足够,但连续存储不够而引起的存储请求fail
ZeRO-Offload
最后,简单介绍一下ZeRO-Offload。它的核心思想是:显存不够,内存来凑。如果我把要存储的大头卸载(offload)到CPU上,而把计算部分放到GPU上,这样比起跨机,是不是能既降显存,也能减少一些通讯压力呢?
- forward和backward计算量高,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU。
- update的部分计算量低,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等
核心思想是:显存不够,内存来凑。