文章目录
- 1.Mysql索引
- 2. b- tree 与 b + tree
- 3.覆盖索引和回表查询
- 4.查询优化
- 1.Explain
- 5.优化实战举例
- **用户搜索**
- **订单查询**
- **分页查询**
1.Mysql索引
MySQL索引是一种用于提高数据库查询效率的数据结构。它可以加快数据检索的速度,减少查询所需的IO操作和计算开销。
MySQL支持多种类型的索引,包括:
-
主键索引(Primary Key Index):主键索引是表中的唯一标识符,它能够快速的定位和访问表中的数据行。
-
唯一索引(Unique Index):唯一索引要求索引列的值在表中是唯一的,用于保证数据的唯一性。
-
普通索引(Normal Index):普通索引也被称为非唯一索引,它可以加快查询速度,但允许索引列中的重复值。
-
全文索引(Full-text Index):全文索引用于对文本内容进行全文搜索,支持关键词的模糊匹配。
-
多列索引(Composite Index):多列索引是基于多个列的索引,可以加速同时使用多个列进行查询的效率。
-
空间索引(Spatial Index):空间索引用于处理地理空间数据,通过R树等数据结构来实现对空间对象的快速查找。
在使用索引时,需要注意以下几点:
-
索引的选择应根据具体的查询需求和数据特点进行优化,合理选择索引列,避免过多无效的索引。
-
对于频繁更新的表,过多的索引可能会影响写入性能,因此需要权衡索引的数量和更新操作的频率。
-
统计信息(Statistics)对于MySQL的优化器来选择最优的查询计划至关重要,定期收集和更新统计信息可以提高查询的效率。
总之,MySQL索引是提高数据库查询效率的重要手段,适当地创建和使用索引可以显著改善查询性能。然而,索引的过度使用或不当使用也可能导致性能下降,所以在设计和使用索引时需要注意平衡各种因素。
2. b- tree 与 b + tree
b- tree又称btree,mysql中索引结构式b+ tree

b+ tree是b tree 的变体,它的所有数据都存储在叶子结点中。
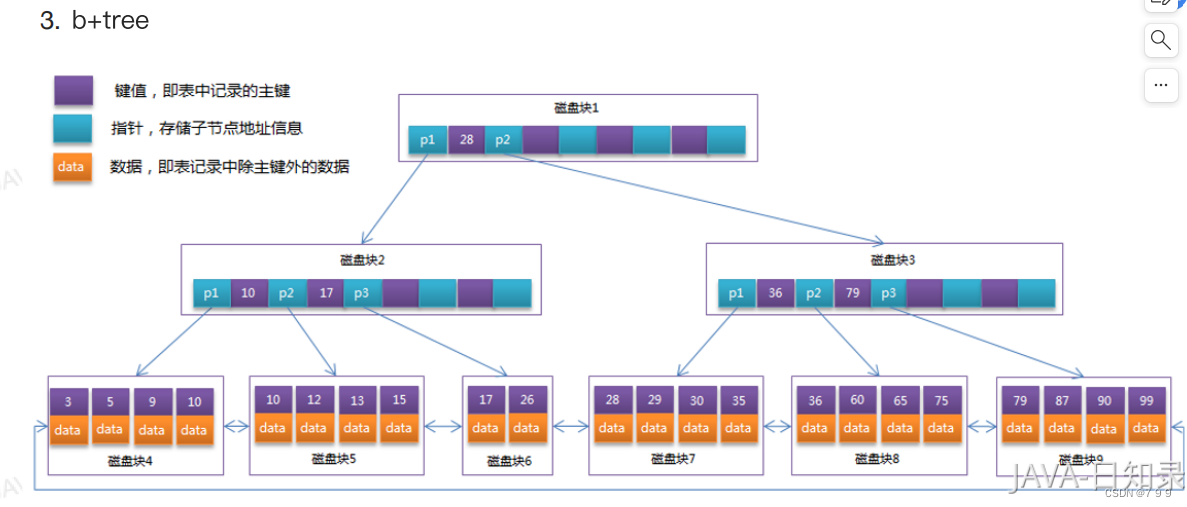
总结:b+tree 索引是双向链表结构,用b+tree 结构做检索要比b -tree快,b+tree结构可以降低树的高度,范围扫描将变得十分简单
3.覆盖索引和回表查询
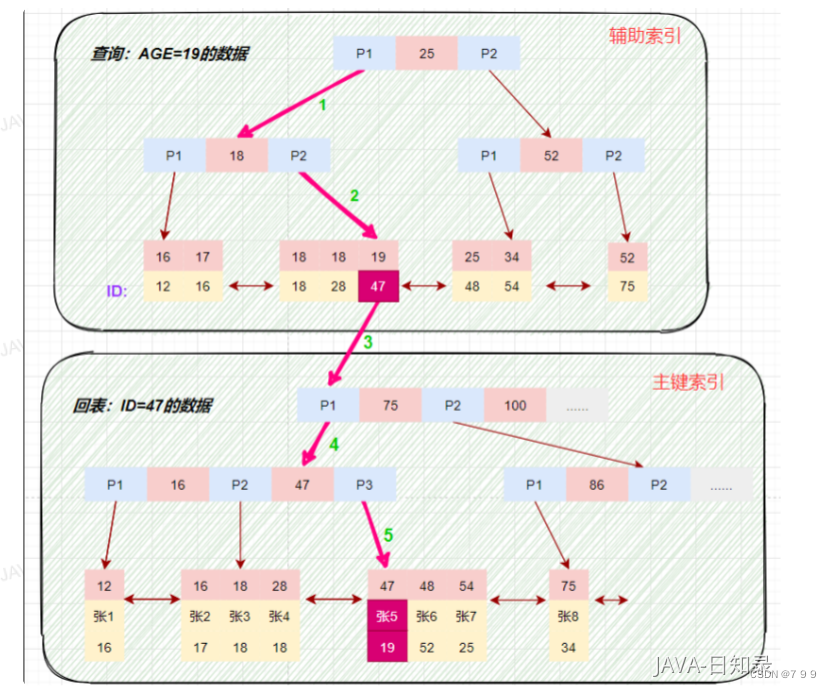
回表查询是指在使用非覆盖索引时进行查询时,当需要查询结果所需的数据
列不在索引中时,mysql需要通过索引的指针回到主索引的数据列。回表查询会增加磁盘IO次数。
回表查询的优化可以从多个方面入手,如使用聚合索引、覆盖索引、分页机制、合理使用缓存和优化查询语句等方法,从而减少回表查询的次数,提高查询效率。
覆盖索引是指在查询过程中,索引包含了查询所需的所有数据列,无需回表查询索引或数据页。换句话说,覆盖索引能够直接提供查询所需的数据,而不需要再去访问主索引或数据页,从而提高查询性能和效率。
4.查询优化
查询优化是数据库性能优化的一个关键方面,通过对查询语句、索引、表结构和系统参数等进行调整,以提高查询性能和响应时间。下面介绍几种常见的查询优化方法:
1.优化查询语句:
- 避免查询不必要的列:只选择需要的列,避免使用 SELECT *。
- 减少查询结果集大小:使用合适的条件和限制来缩小结果集。
- 使用 JOIN 替代子查询:优化复杂查询,尽量使用 JOIN 操作代替子查询。
- 使用 EXISTS 替代 IN:在某些情况下,使用 EXISTS 可以比 IN 更高效。
2.创建适当的索引:
- 确保被频繁查询的列上有索引。
- 考虑创建联合索引以支持多个列的查询。
- 避免过多或重复的索引,以减少维护开销。
3.优化表结构:
- 根据实际需求设计合理的表结构,避免数据冗余和无效的关联关系。
- 通过合理拆分表、使用分区表等方式,提高查询的并发性能。
4.统计信息的收集与更新:
- 定期收集和更新表的统计信息,以便优化查询计划的生成。
5.合理设置系统参数:
- 调整数据库参数,如内存分配、并发连接数等。
- 针对具体的数据库管理系统,查阅相关的官方文档和性能优化指南,了解合理的参数设置建议。
6.使用缓存技术:
- 对于经常被查询的数据,使用缓存技术(如Redis)可以显著提升查询性能。
除了上述方法,还可以通过数据库分片、使用存储过程和触发器等技术手段进行查询优化。最重要的是结合具体的业务需求和数据库特点进行综合考虑,选择合适的优化方法。
1.Explain
下面我们用EXPLAIN 这个命令来对 SQL语句进行优化
通过查看EXPLAIN输出,我们可以判断查询是否使用了合适的索引、是否进行了全表扫描以及是否存在潜在的性能瓶颈。我们可以根据这些信息来优化查询,例如添加缺失的索引、重构查询语句等。
执行EXPLAIN查询后,将返回一个结果集,其中包含了查询的执行计划信息。以下是一些常见的列和其含义:
id:表示查询计划中每个操作的唯一标识符。select_type:表示查询的类型。常见的类型包括SIMPLE(简单查询)、PRIMARY(主查询)和SUBQUERY(子查询)等。table:表示要访问的表。type:表示访问表的方式,通常有以下几种类型:ALL(全表扫描)、INDEX(使用索引扫描)、range(范围扫描)、ref(基于索引的等值查询),const(使用唯一索引或者主键)等。possible_keys:表示可能应用于此查询的索引。key:表示实际选择的索引。rows:表示估计需要检查的行数。Extra:提供额外的有关查询执行方法的信息,如Using where(表示过滤条件使用了WHERE子句)、Using index(表示覆盖索引)等。
5.优化实战举例
我们需要准备相关数据,我们都知道,在电商平台中,最核心的数据为:用户、商品、订单,因此,我们需要创建了对应三张表,以及批量初始化⼤量数据,其中,表结构简单设计如下
CREATE TABLE `my_customer` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(3) DEFAULT '20' COMMENT '年龄',`gender` tinyint(1) NOT NULL DEFAULT '0' COMMENT '性别 0-⼥ 1-男',`phone` varchar(20) DEFAULT '' COMMENT '地址',`address` varchar(100) DEFAULT NULL,`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `my_customer_name_IDX` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='客户';
CREATE TABLE `my_order` (`id` int(11) NOT NULL AUTO_INCREMENT,`customer_id` int(11) NOT NULL,`product_id` int(11) NOT NULL,`quantity` int(11) NOT NULL DEFAULT '1' COMMENT '数量',`total_price` int(11) NOT NULL DEFAULT '1' COMMENT '总价',`order_status` smallint(5) unsigned NOT NULL DEFAULT '0' COMMENT '订单状
态 0-未⽀付 1-已⽀付 2-派送中 3-已签收',`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单';
CREATE TABLE `my_product` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) NOT NULL COMMENT '商品名',`type` int(11) NOT NULL DEFAULT '1' COMMENT '类型 1-⾐服 2-⻝品 3-书籍',`brand` varchar(100) DEFAULT '' COMMENT '品牌',`shop_id` int(11) NOT NULL DEFAULT '1' COMMENT '店铺ID',`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品';
用户搜索
不使用索引查询
select * from `my_customer` where phone like '157%'
我们来用explain看下这个sql语句的执行计划

我们可以看到该sql语句的执行计划中,type字段为ALL , 表示全表扫描,这会导致查询效率过低,耗时
过长。
2.使用索引
CREATE INDEX my_customer_phone_IDX USING BTREE ON store.my_customer(phone);
这里要注意,模糊匹配查询使用 % 在开头会导致索引失效。
explain select * from `my_customer` where phone like '157%';

我们可以看到sql执行过程中实际用到了 my_customer_phone_IDX 索引 , 相比全表扫描,这里预计扫描
函数仅10w多行。
订单查询
不管是用户App端还是在电商后台,都存在订单查询的场景,例如我们需要根据品牌查询对应品牌下商品的订单,我们首先给商品表加个以品牌字段作为索引
CREATE INDEX my_product_brand_IDX USING BTREE ON store.my_product (brand);我们看下这个语句的查询执行计划
select * from my_order mo where product_id in (select id from my_product m
p where brand = 'Apple');
我们来看一下查询的执行计划
explain select * from my_order mo where product_id in (select id from my_pr
oduct mp where brand = 'Apple');

这时候我们看到订单表的查询使用了全表扫描,我们再给订单表的product_id字段加上索引
CREATE INDEX my_order_product_id_IDX USING BTREE ON store.my_order(product_
id);
再次查看执行计划
explain select * from my_order mo where product_id in (select id from my_pr
oduct mp where brand = 'Apple');

我们可以看到两条计划都用到了字段索引 加快了查询效率
虽然子查询在当前情况下实现了查询需求,但使用子查询可能会导致⼀些性能问题,因此在优化查询时,通常不建议过度依赖子查询。以下是⼀些原因:
执行多次查询:效率太差,执行子查询时,MYSQL需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响,这里多了⼀个创建和销毁临时表的过程。可读性和维护性差:复杂的嵌套子查询可能会使查询语句变得难以理解和维护。子查询通常需要理解嵌套层次和各个子查询之间的关系,使查询语句变得冗长且难以阅读。
缺乏优化灵活性:数据库优化器在处理子查询时的优化能力相对较弱。优化器很难对复杂的嵌套子查询进行全面的优化,可能无法选择最佳执行计划,导致性能下降。可能引发性能问题:子查询可能导致全表扫描或临时表的创建,增加系统的 I/O 负担和内存消耗。特别是当子查询涉及大量数据或涉及多表关联时,性能问题可能更加明显。
对于能够使用连接查询(JOIN)或其他更有效方法替代的⼦查询,通常建议使用更简洁和高效的查询方式。连接查询可以更好地利用索引和优化执行计划,同时提供更好的可读性和维护性。
然而,并非所有情况下都不推荐使用子查询。在某些特定的场景下,子查询是合理的选择,例如需要进行存在性检查或在查询中嵌套聚合函数等情况。在使用子查询时,需要根据实际情况综合考虑性能、可读性和维护性的权衡,确保达到最佳的查询效果。
下面我们改为连接查询
SELECT mo.id as orderId, mo.customer_id as customerId, mp.name as productName, mo.order_status as orderStatus FROM my_order mo JOIN my_product mp ON mo.product_id = mp.id WHERE mp.brand = 'Apple';
但是一旦join涉及到的数据量很大,效率就很难保证,这种情况下最好在应用层里面做join,merge数据
分页查询
一般情况下分页查询的优化就是不让语句做没用的遍历
假设要查超过1000000的10个元素,那么一般的语句是这样也就是 先遍历了前1000000个 但是limit在小数据范围中的分页查询性能才最好
SELECT mo.id as orderId, mo.customer_id as customerId, mo.order_status as orderStatus FROM my_order mo where mo.order_status = 1 order by mo.id asc limit 1000000, 10
所以我们如何优化呢
我们可以利用索引来进行优化,例如我们分页查询到第1000000条数据,订单ID为9397780,那么下个分页的所有订单ID都是大于9397780。
SELECT mo.id as orderId, mo.customer_id as customerId, mo.order_status as orderStatus FROM my_order mo inner join (select id from my_order where id > 9397780 and order_status = 1 limit 10) mo2 on mo.id = mo2.id order by mo.id asc
我们用explain来看一下

从查询计划我们看到,首先子查询根据主键索引,获取最多10条订单ID, 然后再根据这10条id 获取数据详情。不需要再查询上百万条数据后排序取所需几行数据。