目录
- 引言
- 历史背景
- 重要性
- 二、注意力机制
- 基础概念
- 定义
- 组件
- 注意力机制的分类
- 举例说明
- 三、注意力机制的数学模型
- 基础数学表达式
- 注意力函数
- 计算权重
- 数学意义
- 举例解析
- 四、注意力网络在NLP中的应用
- 机器翻译
- 代码示例
- 文本摘要
- 代码示例
- 命名实体识别(NER)
- 代码示例
- 五、注意力网络在计算机视觉中的应用
- 图像分类
- 代码示例
- 目标检测
- 代码示例
- 图像生成
- 代码示例
- 六、总结
在本文中,我们深入探讨了注意力机制的理论基础和实际应用。从其历史发展和基础定义,到具体的数学模型,再到其在自然语言处理和计算机视觉等多个人工智能子领域的应用实例,本文为您提供了一个全面且深入的视角。通过Python和PyTorch代码示例,我们还展示了如何实现这一先进的机制。
关注TechLead,分享AI技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
引言
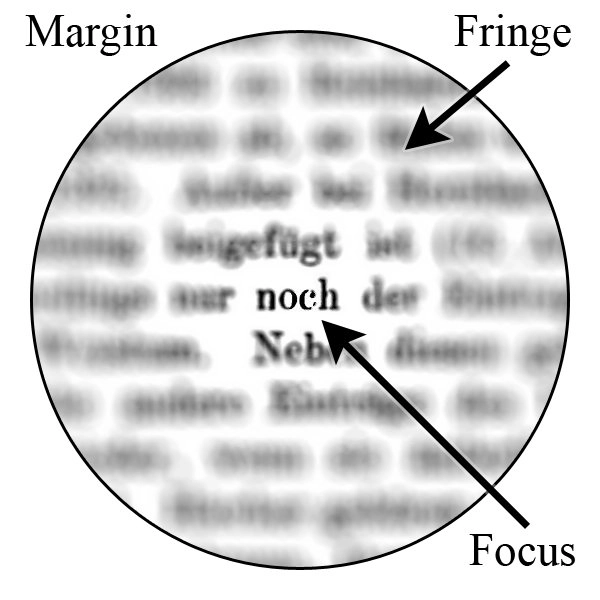
在深度学习领域,模型的性能不断提升,但同时计算复杂性和参数数量也在迅速增加。为了让模型更高效地捕获输入数据中的信息,研究人员开始转向各种优化策略。正是在这样的背景下,注意力机制(Attention Mechanism)应运而生。本节将探讨注意力机制的历史背景和其在现代人工智能研究和应用中的重要性。
历史背景
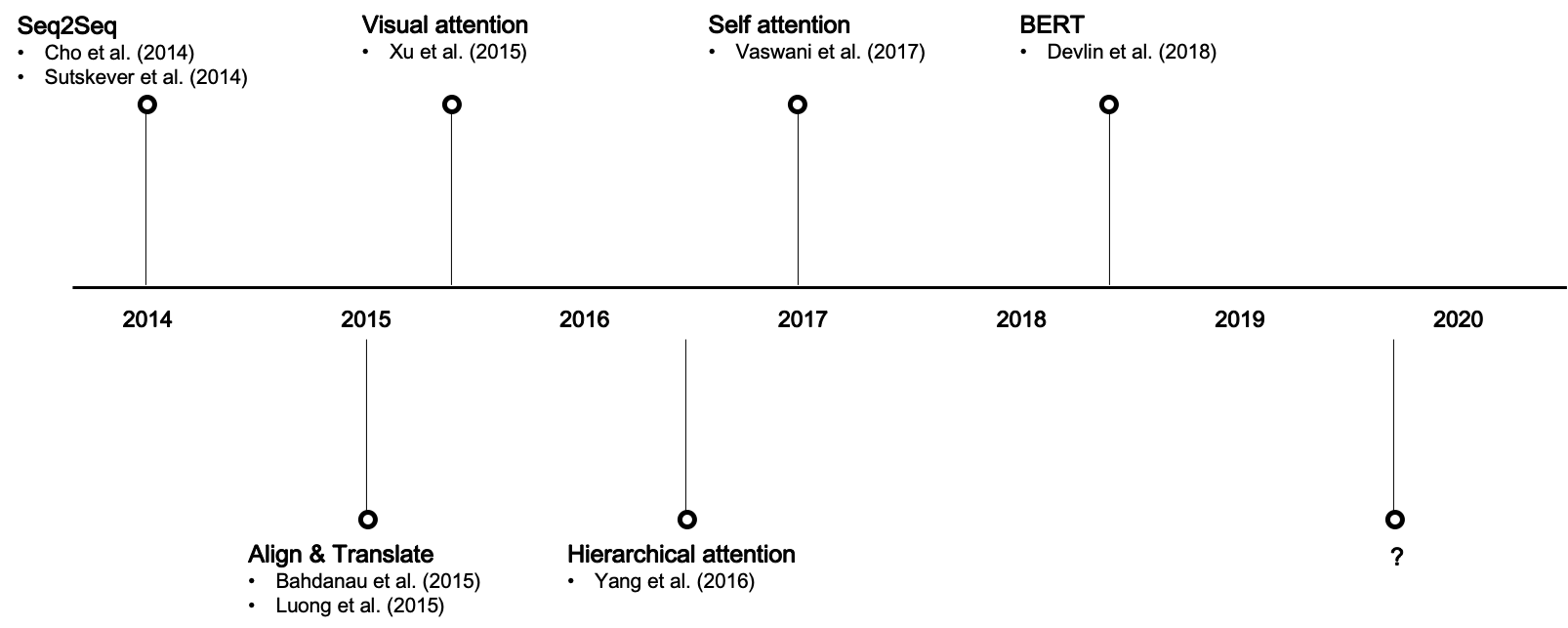
-
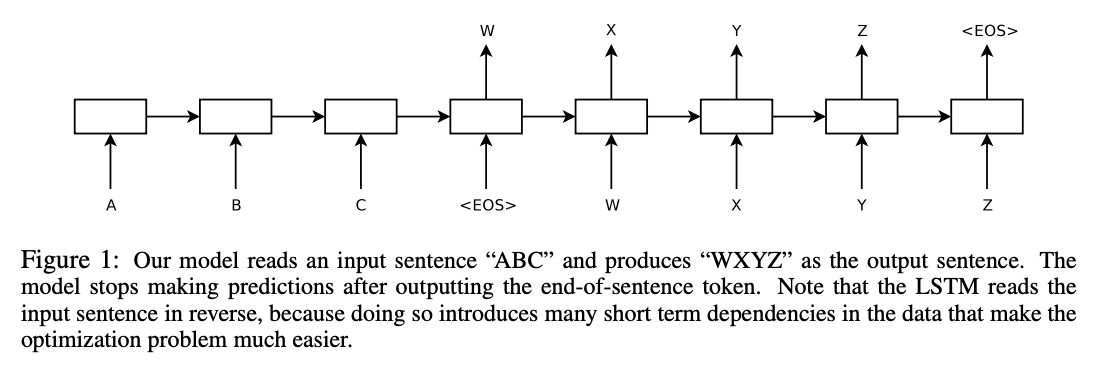
2014年:序列到序列(Seq2Seq)模型的出现为自然语言处理(NLP)和机器翻译带来了巨大的突破。
-
2015年:Bahdanau等人首次引入了注意力机制,用于改进基于Seq2Seq的机器翻译。
-
2017年:Vaswani等人提出了Transformer模型,这是第一个完全依赖于注意力机制来传递信息的模型,显示出了显著的性能提升。
-
2018-2021年:注意力机制开始广泛应用于不同的领域,包括计算机视觉、语音识别和生成模型,如GPT和BERT等。
-
2021年以后:研究者们开始探究如何改进注意力机制,以便于更大、更复杂的应用场景,如多模态学习和自监督学习。
重要性
-
性能提升:注意力机制一经引入即显著提升了各种任务的性能,包括但不限于文本翻译、图像识别和强化学习。
-
计算效率:通过精心设计的权重分配,注意力机制有助于减少不必要的计算,从而提高模型的计算效率。
-
可解释性:虽然深度学习模型常被批评为“黑盒”,但注意力机制提供了一种直观的方式来解释模型的决策过程。
-
模型简化:在多数情况下,引入注意力机制可以简化模型结构,如去除或减少递归网络的需要。
-
领域广泛性:从自然语言处理到计算机视觉,再到医学图像分析,注意力机制的应用几乎无处不在。
-
模型泛化:注意力机制通过更智能地挑选关联性强的特征,提高了模型在未见过数据上的泛化能力。
-
未来潜力:考虑到当前研究的活跃程度和多样性,注意力机制有望推动更多前沿科技的发展,如自动驾驶、自然语言界面等。
综上所述,注意力机制不仅在历史上具有里程碑式的意义,而且在当下和未来都是深度学习和人工智能领域内不可或缺的一部分。
二、注意力机制
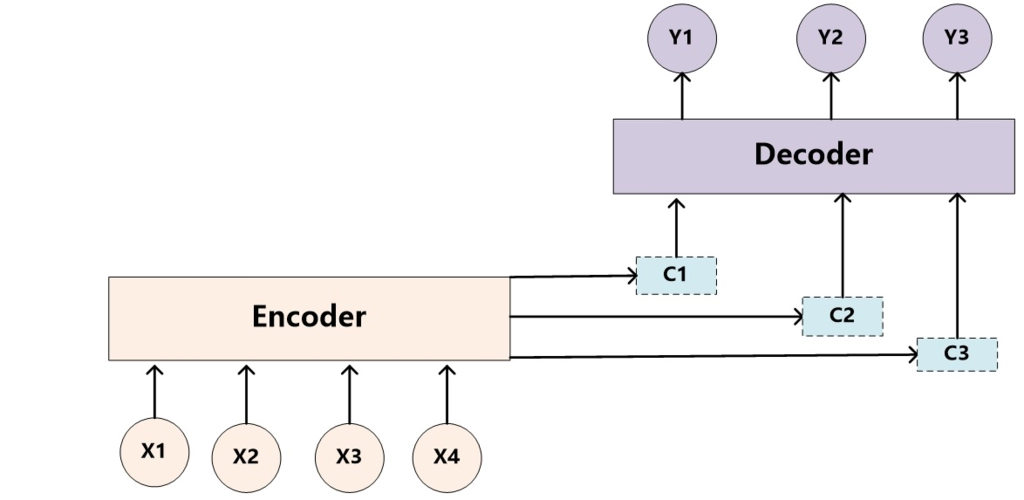
注意力机制是一种模拟人类视觉和听觉注意力分配的方法,在处理大量输入数据时,它允许模型关注于最关键的部分。这一概念最早是为了解决自然语言处理中的序列到序列模型的一些局限性而被提出的,但现在已经广泛应用于各种机器学习任务。
基础概念
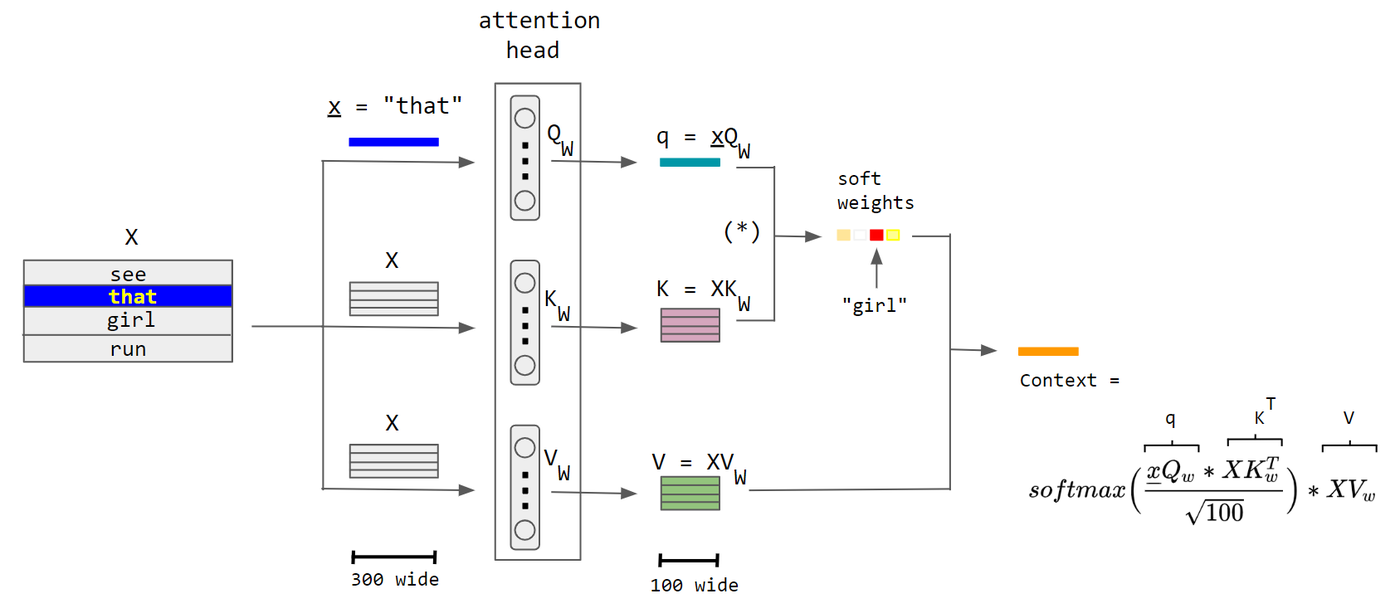
定义
在数学上,注意力函数可以被定义为一个映射,该映射接受一个查询(Query)和一组键值对(Key-Value pairs),然后输出一个聚合后的信息,通常称为注意力输出。
注意力(Q, K, V) = 聚合(权重 * V)
其中,权重通常是通过查询(Q)和键(K)的相似度计算得到的:
权重 = softmax(Q * K^T / sqrt(d_k))
组件
- Query(查询): 代表需要获取信息的请求。
- Key(键): 与Query相关性的衡量标准。
- Value(值): 包含需要被提取信息的实际数据。
- 权重(Attention Weights): 通过Query和Key的相似度计算得来,决定了从各个Value中提取多少信息。
注意力机制的分类
- 点积(Dot-Product)注意力
- 缩放点积(Scaled Dot-Product)注意力
- 多头注意力(Multi-Head Attention)
- 自注意力(Self-Attention)
- 双向注意力(Bi-Directional Attention)
举例说明
假设我们有一个简单的句子:“猫喜欢追逐老鼠”。如果我们要对“喜欢”这个词进行编码,一个简单的方法是只看这个词本身,但这样会忽略它的上下文。“喜欢”的对象是“猫”,而被“喜欢”的是“追逐老鼠”。在这里,“猫”和“追逐老鼠”就是“喜欢”的上下文,而注意力机制能够帮助模型更好地捕获这种上下文关系。
# 使用PyTorch实现简单的点积注意力
import torch
import torch.nn.functional as F# 初始化Query, Key, Value
Q = torch.tensor([[1.0, 0.8]]) # Query 对应于 "喜欢" 的编码
K = torch.tensor([[0.9, 0.1], [0.8, 0.2], [0.7, 0.9]]) # Key 对应于 "猫", "追逐", "老鼠" 的编码
V = torch.tensor([[1.0, 0.1], [0.9, 0.2], [0.8, 0.3]]) # Value 也对应于 "猫", "追逐", "老鼠" 的编码# 计算注意力权重
d_k = K.size(1)
scores = torch.matmul(Q, K.transpose(0, 1)) / (d_k ** 0.5)
weights = F.softmax(scores, dim=-1)# 计算注意力输出
output = torch.matmul(weights, V)print("注意力权重:", weights)
print("注意力输出:", output)
输出:
注意力权重: tensor([[0.4761, 0.2678, 0.2561]])
注意力输出: tensor([[0.9529, 0.1797]])
这里,“喜欢”通过注意力权重与“猫”和“追逐老鼠”进行了信息的融合,并得到了一个新的编码,从而更准确地捕获了其在句子中的语义信息。
通过这个例子,我们可以看到注意力机制是如何运作的,以及它在理解序列数据,特别是文本数据中的重要性。
三、注意力机制的数学模型
在深入了解注意力机制的应用之前,我们先来解析其背后的数学模型。注意力机制通常由一系列数学操作组成,包括点积、缩放、Softmax函数等。这些操作不仅有助于计算注意力权重,而且也决定了信息如何从输入传递到输出。
基础数学表达式
注意力函数
注意力机制最基础的形式可以用以下函数表示:
[
\text{Attention}(Q, K, V) = \text{Aggregate}(W \times V)
]
其中,( W ) 是注意力权重,通常通过 ( Q )(查询)和 ( K )(键)的相似度计算得出。
计算权重
权重 ( W ) 通常是通过 Softmax 函数和点积运算计算得出的,表达式为:
[
W = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)
]
这里,( d_k ) 是键和查询的维度,( \sqrt{d_k} ) 的作用是缩放点积,以防止梯度过大或过小。
数学意义
-
点积 ( QK^T ):这一步测量了查询和键之间的相似性。点积越大,意味着查询和相应的键更相似。
-
缩放因子 ( \sqrt{d_k} ):缩放因子用于调整点积的大小,使得模型更稳定。
-
Softmax 函数:Softmax 用于将点积缩放的结果转化为概率分布,从而确定每个值在最终输出中的权重。
举例解析
假设我们有三个单词:‘apple’、‘orange’、‘fruit’,用三维向量 ( Q, K_1, K_2 ) 表示。
import math
import torch# Query, Key 初始化
Q = torch.tensor([2.0, 3.0, 1.0])
K1 = torch.tensor([1.0, 2.0, 1.0]) # 'apple'
K2 = torch.tensor([1.0, 1.0, 2.0]) # 'orange'# 点积计算
dot_product1 = torch.dot(Q, K1)
dot_product2 = torch.dot(Q, K2)# 缩放因子
d_k = Q.size(0)
scale_factor = math.sqrt(d_k)# 缩放点积
scaled_dot_product1 = dot_product1 / scale_factor
scaled_dot_product2 = dot_product2 / scale_factor# Softmax 计算
weights = torch.nn.functional.softmax(torch.tensor([scaled_dot_product1, scaled_dot_product2]), dim=0)print("权重:", weights)
输出:
权重: tensor([0.6225, 0.3775])
在这个例子中,权重显示“fruit”与“apple”(0.6225)相比“orange”(0.3775)更相似。这种计算方式为我们提供了一种量化“相似度”的手段,进一步用于信息聚合。
通过深入理解注意力机制的数学模型,我们可以更准确地把握其如何提取和聚合信息,以及它在各种机器学习任务中的应用价值。这也为后续的研究和优化提供了坚实的基础。
四、注意力网络在NLP中的应用

注意力机制在自然语言处理(NLP)中有着广泛的应用,包括机器翻译、文本摘要、命名实体识别(NER)等。本节将深入探讨几种常见应用,并提供相应的代码示例。
机器翻译
机器翻译是最早采用注意力机制的NLP任务之一。传统的Seq2Seq模型在处理长句子时存在信息损失的问题,注意力机制通过动态权重分配来解决这一问题。
代码示例
import torch
import torch.nn as nnclass AttentionSeq2Seq(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(AttentionSeq2Seq, self).__init__()self.encoder = nn.LSTM(input_dim, hidden_dim)self.decoder = nn.LSTM(hidden_dim, hidden_dim)self.attention = nn.Linear(hidden_dim * 2, 1)self.output_layer = nn.Linear(hidden_dim, output_dim)def forward(self, src, tgt):# Encoderencoder_output, (hidden, cell) = self.encoder(src)# Decoder with Attentionoutput = []for i in range(tgt.size(0)):# 计算注意力权重attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))attention_weights = torch.softmax(attention_weights, dim=1)# 注意力加权和weighted = torch.sum(encoder_output * attention_weights, dim=1)# Decoderout, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))out = self.output_layer(out)output.append(out)return torch.stack(output)
文本摘要
文本摘要任务中,注意力机制能够帮助模型挑选出文章中的关键句子或者词,生成一个内容丰富、结构紧凑的摘要。
代码示例
class TextSummarization(nn.Module):def __init__(self, vocab_size, embed_size, hidden_size):super(TextSummarization, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_size)self.encoder = nn.LSTM(embed_size, hidden_size)self.decoder = nn.LSTM(hidden_size, hidden_size)self.attention = nn.Linear(hidden_size * 2, 1)self.output = nn.Linear(hidden_size, vocab_size)def forward(self, src, tgt):embedded = self.embedding(src)encoder_output, (hidden, cell) = self.encoder(embedded)output = []for i in range(tgt.size(0)):attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))attention_weights = torch.softmax(attention_weights, dim=1)weighted = torch.sum(encoder_output * attention_weights, dim=1)out, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))out = self.output(out)output.append(out)return torch.stack(output)
命名实体识别(NER)
在命名实体识别任务中,注意力机制可以用于捕捉文本中不同实体之间的依赖关系。
代码示例
class NERModel(nn.Module):def __init__(self, vocab_size, embed_size, hidden_size, output_size):super(NERModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.LSTM(embed_size, hidden_size, bidirectional=True)self.attention = nn.Linear(hidden_size * 2, 1)self.fc = nn.Linear(hidden_size * 2, output_size)def forward(self, x):embedded = self.embedding(x)rnn_output, _ = self.rnn(embedded)attention_weights = torch.tanh(self.attention(rnn_output))attention_weights = torch.softmax(attention_weights, dim=1)weighted = torch.sum(rnn_output * attention_weights, dim=1)output = self.fc(weighted)return output
这些只是注意力网络在NLP中应用的冰山一角,但它们清晰地展示了注意力机制如何增强模型的性能和准确性。随着研究的不断深入,我们有理由相信注意力机制将在未来的NLP应用中发挥更加重要的作用。
五、注意力网络在计算机视觉中的应用
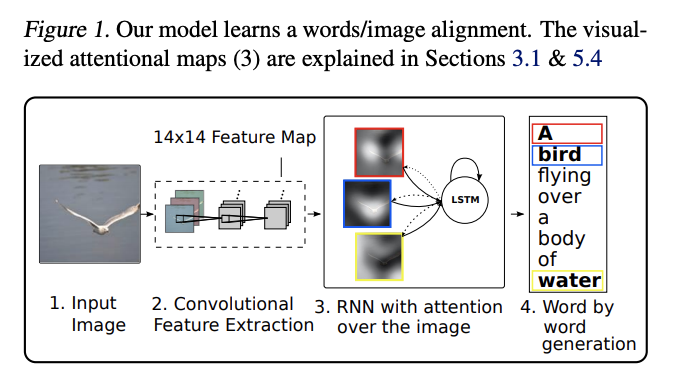
注意力机制不仅在NLP中有广泛应用,也在计算机视觉(CV)领域逐渐崭露头角。本节将探讨注意力机制在图像分类、目标检测和图像生成等方面的应用,并通过代码示例展示其实现细节。
图像分类
在图像分类中,注意力机制可以帮助网络更加聚焦于与分类标签密切相关的图像区域。
代码示例
import torch
import torch.nn as nnclass AttentionImageClassification(nn.Module):def __init__(self, num_classes):super(AttentionImageClassification, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.conv2 = nn.Conv2d(32, 64, 3)self.attention = nn.Linear(64, 1)self.fc = nn.Linear(64, num_classes)def forward(self, x):x = self.conv1(x)x = self.conv2(x)attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))attention_weights = torch.softmax(attention_weights, dim=2)x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)x = self.fc(x)return x
目标检测
在目标检测任务中,注意力机制能够高效地定位和识别图像中的多个对象。
代码示例
class AttentionObjectDetection(nn.Module):def __init__(self, num_classes):super(AttentionObjectDetection, self).__init__()self.conv = nn.Conv2d(3, 64, 3)self.attention = nn.Linear(64, 1)self.fc = nn.Linear(64, 4 + num_classes) # 4 for bounding box coordinatesdef forward(self, x):x = self.conv(x)attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))attention_weights = torch.softmax(attention_weights, dim=2)x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)x = self.fc(x)return x
图像生成
图像生成任务,如GANs,也可以从注意力机制中受益,尤其在生成具有复杂结构和细节的图像时。
代码示例
class AttentionGAN(nn.Module):def __init__(self, noise_dim, img_channels):super(AttentionGAN, self).__init__()self.fc = nn.Linear(noise_dim, 256)self.deconv1 = nn.ConvTranspose2d(256, 128, 4)self.attention = nn.Linear(128, 1)self.deconv2 = nn.ConvTranspose2d(128, img_channels, 4)def forward(self, z):x = self.fc(z)x = self.deconv1(x.view(x.size(0), 256, 1, 1))attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))attention_weights = torch.softmax(attention_weights, dim=2)x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)x = self.deconv2(x.view(x.size(0), 128, 1, 1))return x
这些应用示例明确地展示了注意力机制在计算机视觉中的潜力和多样性。随着更多的研究和应用,注意力网络有望进一步推动计算机视觉领域的发展。
六、总结
注意力机制在人工智能行业中的应用已经远远超出了其初始的研究领域,从自然语言处理到计算机视觉,乃至其他多种复杂的任务和场景。通过动态地分配不同级别的“注意力”,这一机制有效地解决了信息处理中的关键问题,提升了模型性能,并推动了多个子领域的前沿研究和应用。这标志着人工智能从“硬编码”规则转向了更为灵活、自适应的计算模型,进一步拓宽了该领域的应用范围和深度。
关注TechLead,分享AI技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。