.git文件夹是Git版本控制系统在项目根目录下创建的隐藏文件夹,包含了Git仓库的所有相关信息。如下是.git文件夹中常见的一些内容及其作用:
-
HEAD:指向当前所在的分支(或者是一个特定的提交)。
-
branches:存储了每个远程分支的相关信息。
-
config:存储了项目级别的Git配置信息,包括用户名、邮箱、远程仓库等。
-
description:对于空的Git仓库,此文件内容为空。对于非空的Git仓库,描述该项目的文本。
-
hooks:存放各种Git钩子(hooks)的目录,包括预定义的钩子模板和用户自定义的钩子脚本。
-
index:包含了暂存区(stage)的内容,记录了即将提交的文件和相关元数据。
-
info:包含一些辅助性的信息。
-
logs:存储了每个引用(分支、标签等)的修改历史。
-
objects:存储了Git仓库的对象(commits、trees和blobs)。
-
refs:存储了所有的引用(分支、标签等)。
-
config、ignore等:其他配置文件和设置。
这些文件和目录组合起来构成了一个完整的Git仓库,用于追踪、管理和存储项目的版本控制历史。通常情况下,不需要直接操作.git文件夹中的内容,而是通过Git命令和工具来管理和操作仓库。
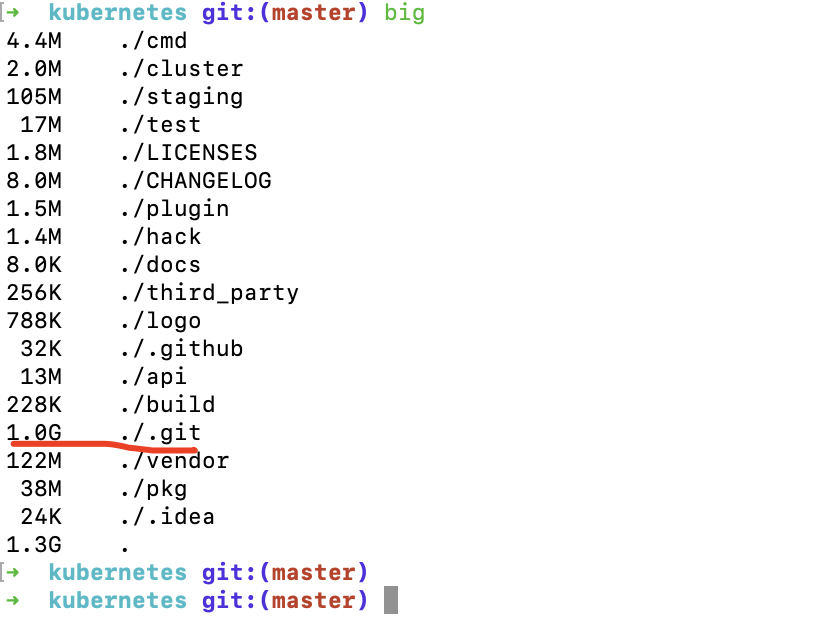
随着项目提交次数的增多,.git目录占用的空间大小,往往可能会比项目源代码本身要大得多。
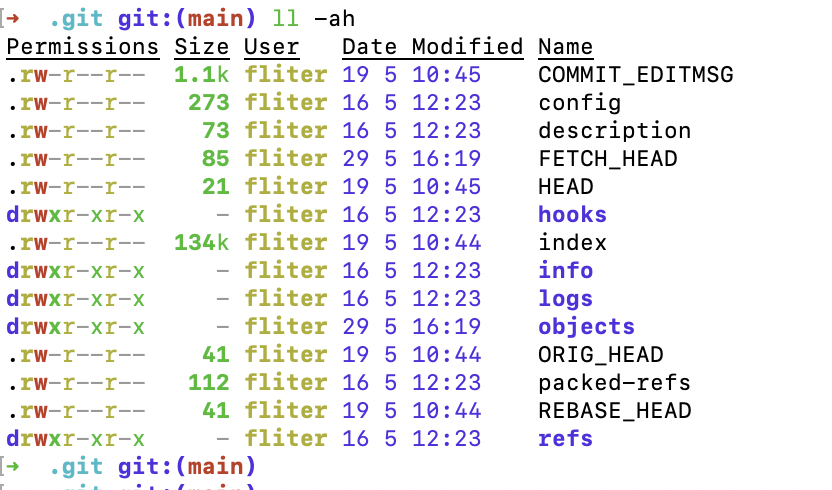
看一些知名项目,.git目录的大小
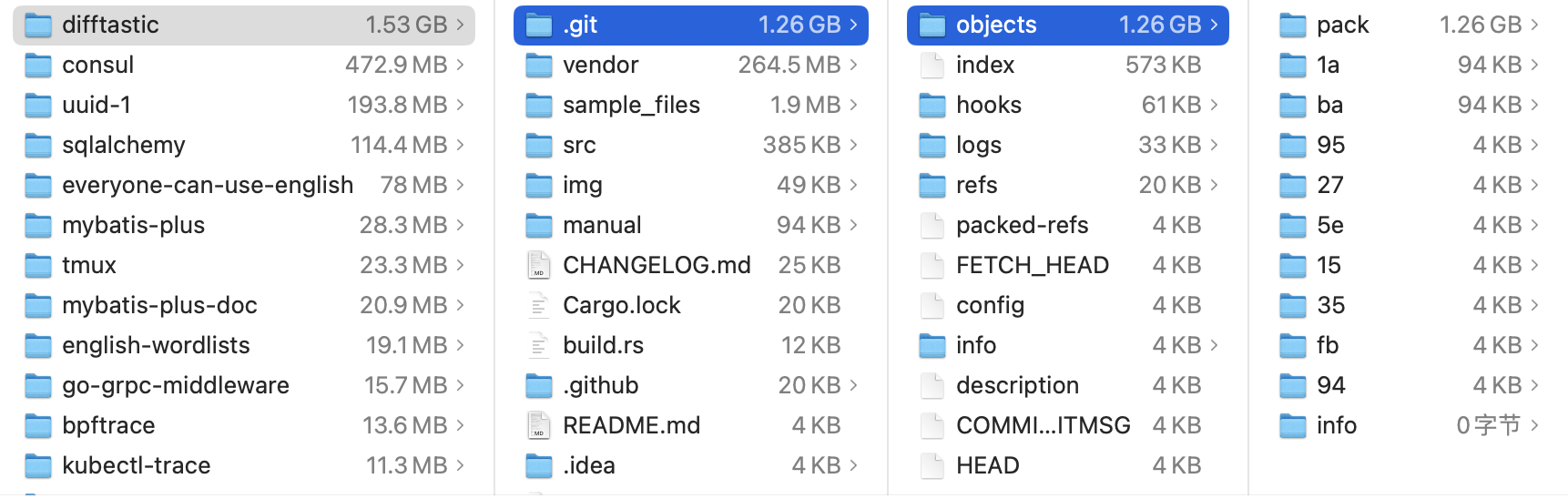
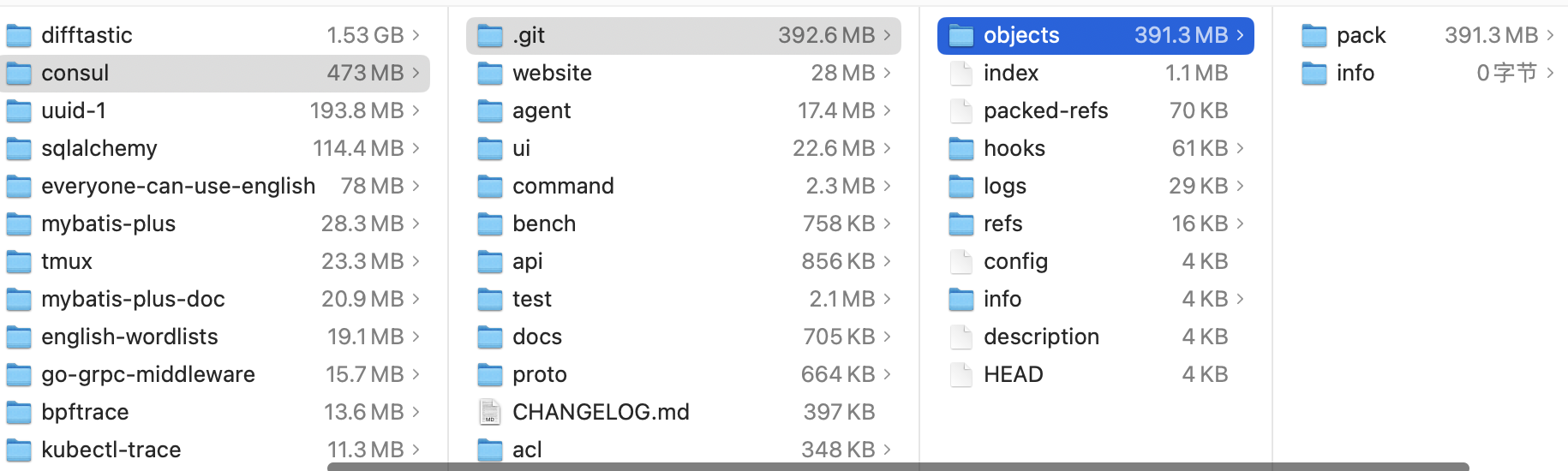
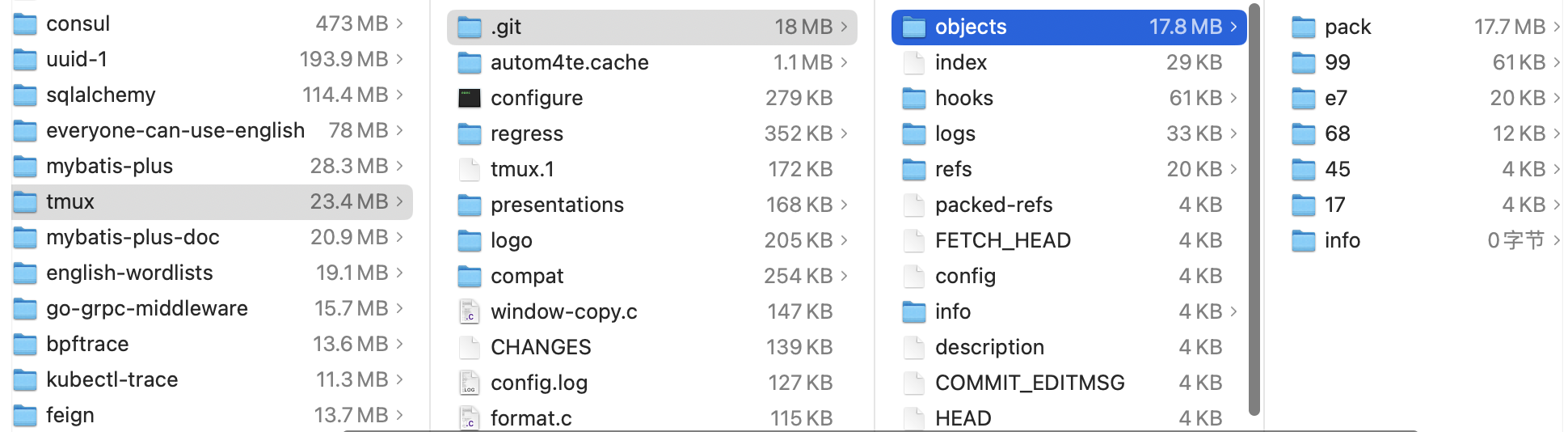
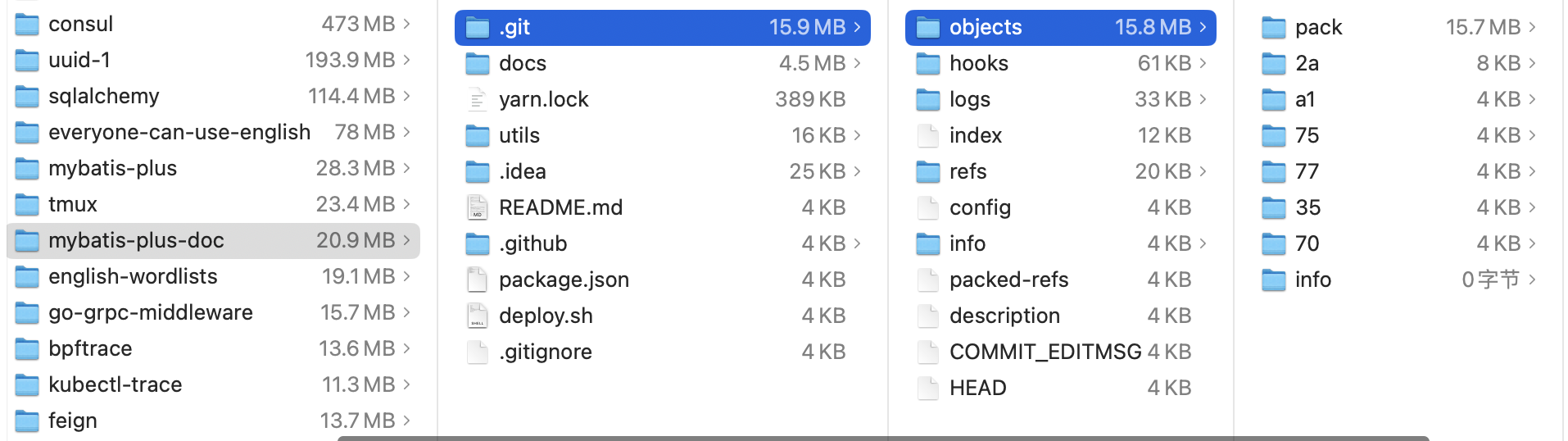
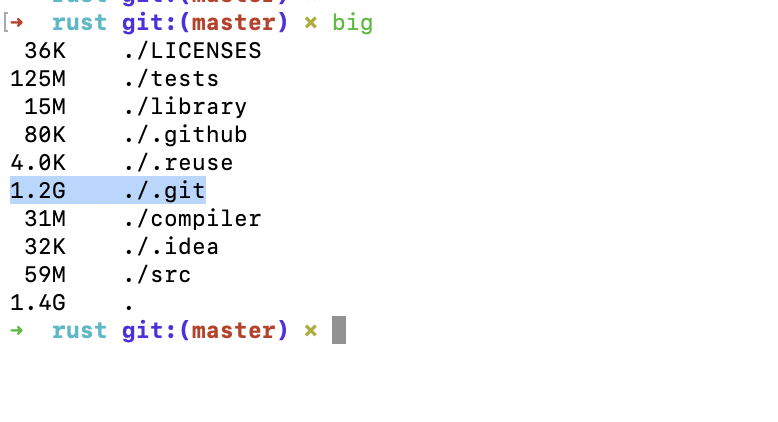
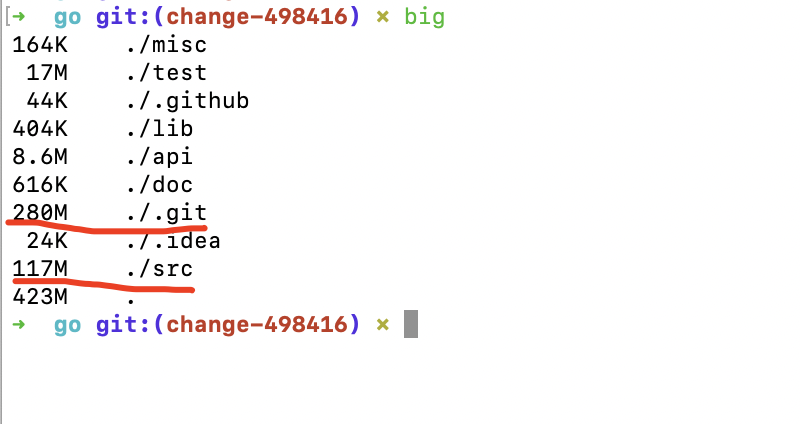
etcd:
rust:
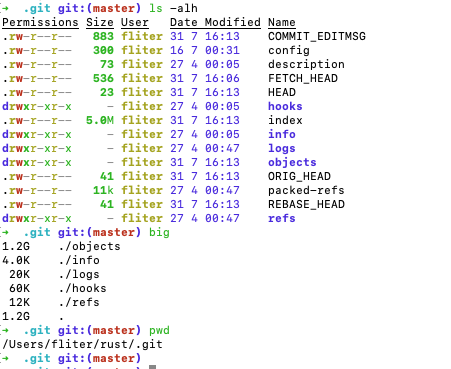
可见在.git目录下,objects文件夹占用了绝大多数空间
-
objects:存储了Git仓库的对象(commits、trees和blobs)
.git/objects目录存储了以下几种类型的对象:
-
Blob对象:Blob对象存储了文件的内容。
-
Tree对象:Tree对象表示一个目录。它引用了Blob对象和其他Tree对象,从而构建了文件系统的层次结构。
-
Commit对象:Commit对象表示了一个项目的特定状态。它引用了一个Tree对象,记录了该状态的项目结构,同时还记录了父提交,提交者的信息,以及提交信息。
-
Tag对象:Tag对象是对某个特定commit对象的引用,通常用于发布新版本等。
因此,.git/objects目录是Git仓库的核心,保存了你的所有提交历史和版本信息。如果删除这个目录,将会丢失你的所有版本历史。
然而,随着提交次数增多,会发现.git/objects目录变得非常大,尤其是在处理大型项目时。这种情况下,如果想要减小它的大小。以下是一些可能的方法:
-
Git GC:运行
git gc命令可以清理无用的对象并压缩Git仓库的大小。这个命令会删除那些不再被任何分支或标签引用的对象。 -
Git Prune:如果
git gc还不够,你可以尝试使用git prune命令,它会进一步清理那些不可达的对象。 -
Reduce Repo Size:如果你的仓库中有大量的大文件,你可能需要使用像
git-filter-repo这样的工具来删除这些文件并减小仓库的大小。 -
Git LFS:如果你的项目需要处理大文件,你应该考虑使用Git Large File Storage(Git LFS)来处理这些文件。Git LFS将大文件存储在一个单独的位置,而不是在
.git/objects目录中。
总之,不应该删除.git/objects目录,但可以使用上述方法来管理和减小它的大小。

在一个 Git 仓库中,.git/objects 目录下包含了所有 Git 对象,这些对象包括:
-
blob 对象:存储文件数据,每个文件都会被存储为一个 blob 对象。 -
tree 对象:存储树形结构,每个目录会被存储为一个 tree 对象,tree 对象包含了指向文件 blob 对象和子目录 tree 对象的指针。 -
commit 对象:存储提交信息,每个提交都会被存储为一个 commit 对象,commit 对象包含了指向根目录 tree 对象、父提交、提交作者、提交时间等信息的指针。 -
tag 对象:存储标签信息,每个标签都会被存储为一个 tag 对象,tag 对象包含了指向某个 commit 对象、标签名、标签作者、标签信息等信息的指针。
在 .git/objects 目录下,每个对象都被存储为一个以 40 个字符的 SHA-1 值命名的文件,前两个字符作为目录名,后 38 个字符作为文件名。例如,一个 blob 对象的 SHA-1 值为 c4a7f3c8d5c9aeb7c6f6a7e1c4b8c7c2c8d5fc1f,那么它对应的对象文件就被存储在 .git/objects/c4/a7f3c8d5c9aeb7c6f6a7e1c4b8c7c2c8d5fc1f 中。
这些对象是 Git 仓库中的基本构建块,Git 使用这些对象来记录文件的历史版本和状态。在 Git 中,每个对象都可以通过唯一的 SHA-1 值来引用和访问。
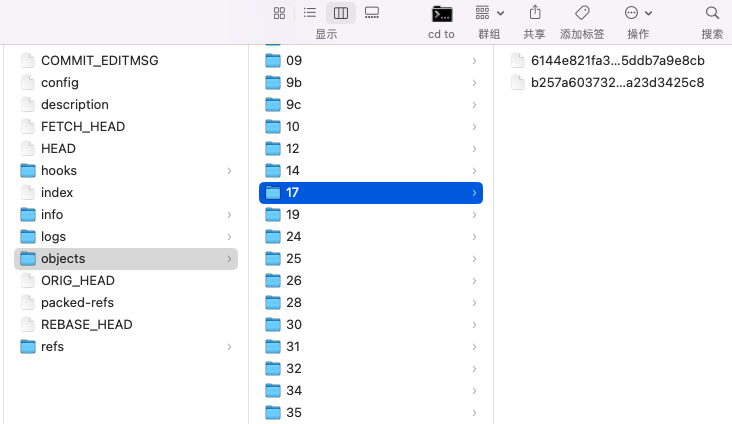
.git/objects/pack有什么作用?
.git/objects/pack 目录是 Git 用来存储压缩后的 Git 对象文件的目录,这些文件是通过 Git 的打包(packing)算法生成的。打包算法可以将多个 Git 对象文件压缩成一个更小的文件,这样可以减小 Git 仓库的占用空间,提高 Git 的性能。
在使用 Git 进行版本控制时,每次提交都会产生新的 Git 对象,这些对象会被直接存储为单独的文件。如果 Git 对象文件过多,会导致 Git 仓库的大小变得很大,从而影响 Git 的性能。为了解决这个问题,Git 提供了打包算法,将多个 Git 对象文件打包成一个文件,从而减小 Git 仓库的大小。
.git/objects/pack 目录中的文件都是经过压缩的 Git 对象文件,这些文件的文件名通常以 .pack 结尾。当 Git 需要访问某个 Git 对象时,它会先查找 .git/objects 目录下是否存在对应的 Git 对象文件,如果不存在,Git 会查找 .git/objects/pack 目录下的 .idx 文件,根据索引信息找到对应的 .pack 文件,并从中解压出需要的 Git 对象。
总之,.git/objects/pack 目录存储了 Git 对象的压缩文件,通过打包算法可以减小 Git 仓库的占用空间,提高 Git 的性能。
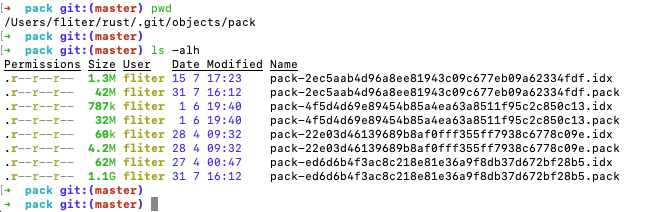
.git/objects/pack中的pack和idx都是干什么用的?
.git/objects/pack 目录中的 .pack 文件和 .idx 文件都是用来存储 Git 对象的压缩文件的。
.pack 文件是经过打包算法压缩后的 Git 对象文件,多个 Git 对象文件被打包成一个 .pack 文件,从而减小 Git 仓库的占用空间。.pack 文件中包含了多个 Git 对象,每个对象都是经过 zlib 压缩的二进制数据。
.idx 文件是 .pack 文件的索引文件,它包含了 .pack 文件中压缩的 Git 对象的索引信息,包括每个 Git 对象的 SHA-1 值、偏移量和大小等信息。.idx 文件可以提高 Git 对象的访问速度,因为 Git 可以通过快速查找 .idx 文件中的索引信息,而不需要解压整个 .pack 文件来查找对应的 Git 对象。
当 Git 需要访问某个 Git 对象时,它会先查找 .git/objects 目录下是否存在对应的 Git 对象文件,如果不存在,Git 会查找 .git/objects/pack 目录下的 .idx 文件,根据索引信息找到对应的 .pack 文件,并从中解压出需要的 Git 对象。
总之,.git/objects/pack 目录中的 .pack 文件和 .idx 文件都是用来存储经过压缩的 Git 对象的,通过打包算法和索引文件可以减小 Git 仓库的占用空间,并提高 Git 对象的访问速度。

图片来自一文讲透 Git 底层数据结构和原理[1]
“可以用 git cat-file -t 查看每个 SHA-1 的类型,用 git cat-file -p 查看每个对象的内容和简单的数据结构。git cat-file 是 git 的瑞士军刀,是底层核心命令
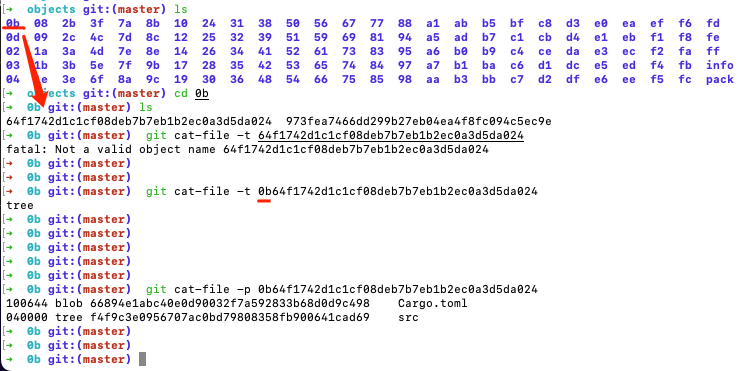
git原理:pack打包[2]
Git 仓库拆分[3]
Git 内部原理[4]
删除Git仓库中的大文件[5]
参考资料
一文讲透 Git 底层数据结构和原理: https://toutiao.io/posts/8ps7l8l/preview
[2]git原理:pack打包: https://blog.csdn.net/dingfu6404/article/details/102410997
[3]Git 仓库拆分: https://www.cnblogs.com/yazhidev/p/13737197.html
[4]Git 内部原理: https://iissnan.com/progit/html/zh/ch9_4.html
[5]删除Git仓库中的大文件: https://vra.github.io/2018/05/20/git-remove-large-file/
本文由 mdnice 多平台发布