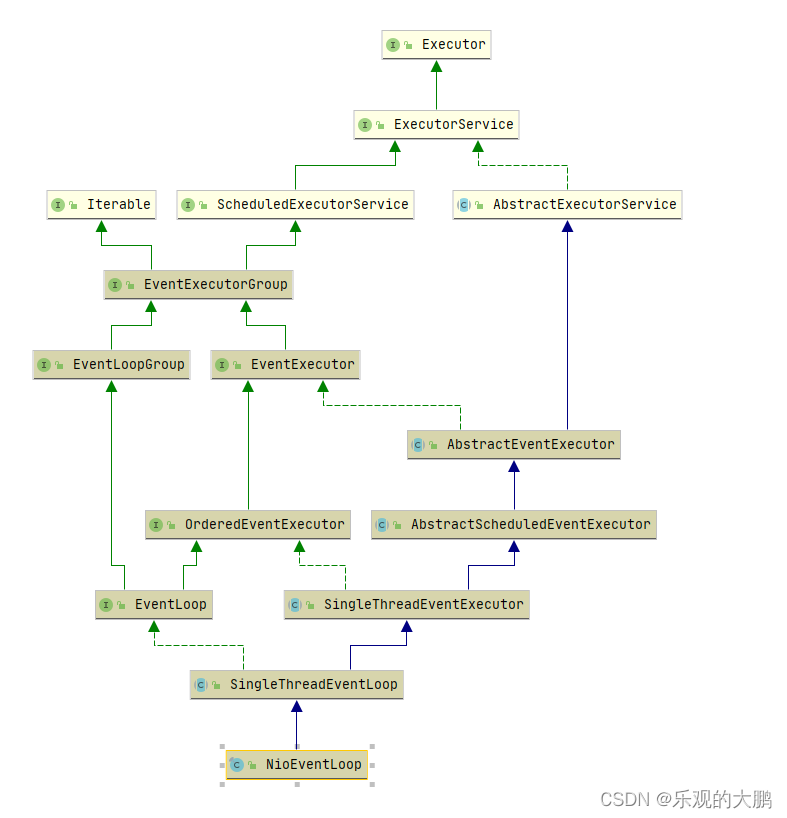
EventLoop可以说是 Netty 的调度中心,负责监听多种事件类型:I/O 事件、信号事件、定时事件等,然而实际的业务处理逻辑则是由 ChannelPipeline 中所定义的 ChannelHandler 完成的,ChannelPipeline 和 ChannelHandler应用开发的过程中打交道最多的组件,为用户提供了 I/O 事件的全部控制权。
文章目录
- 一、ChannelPipeline 是什么?🤔️
- 二、ChannelPipeline 的内部结构🔍
- 1、HeadContext
- 2、TailContext
- 3、addLiast() 方法🔍
- 三、ChannelPipeline 事件传播机制
- 四、ChannelPipeline 异常传播机制
- 五、统一的异常处理器
一、ChannelPipeline 是什么?🤔️
pipeline 有管道,流水线的意思,最早使用在 Unix 操作系统中,可以让不同功能的程序相互通讯,使软件更加”高内聚,低耦合”,它以一种”链式模型”来串起不同的程序或组件,使它们组成一条直线的工作流。
ChannelPipeline 也是 Netty 中的一个比较重要的组件,从上面的 Channel 实例化过程可以看出,每一个 Channel 实例中都会包含一个对应的 ChannelPipeline 属性。ChannelPipeline维护着处理或拦截channel的进站事件和出站事件的双向链表,事件在ChannelPipeline中流动和传递,可以增加或删除ChannelHandler来实现对不同业务逻辑的处理。通俗的说,ChannelPipeline是工厂里的流水线,ChannelHandler是流水线上的工人。
二、ChannelPipeline 的内部结构🔍
final AbstractChannelHandlerContext head;
final AbstractChannelHandlerContext tail;private final Channel channel;
private final ChannelFuture succeededFuture;
private final VoidChannelPromise voidPromise;protected DefaultChannelPipeline(Channel channel) {this.channel = ObjectUtil.checkNotNull(channel, "channel");succeededFuture = new SucceededChannelFuture(channel, null);voidPromise = new VoidChannelPromise(channel, true);tail = new TailContext(this);head = new HeadContext(this);head.next = tail;tail.prev = head;
}
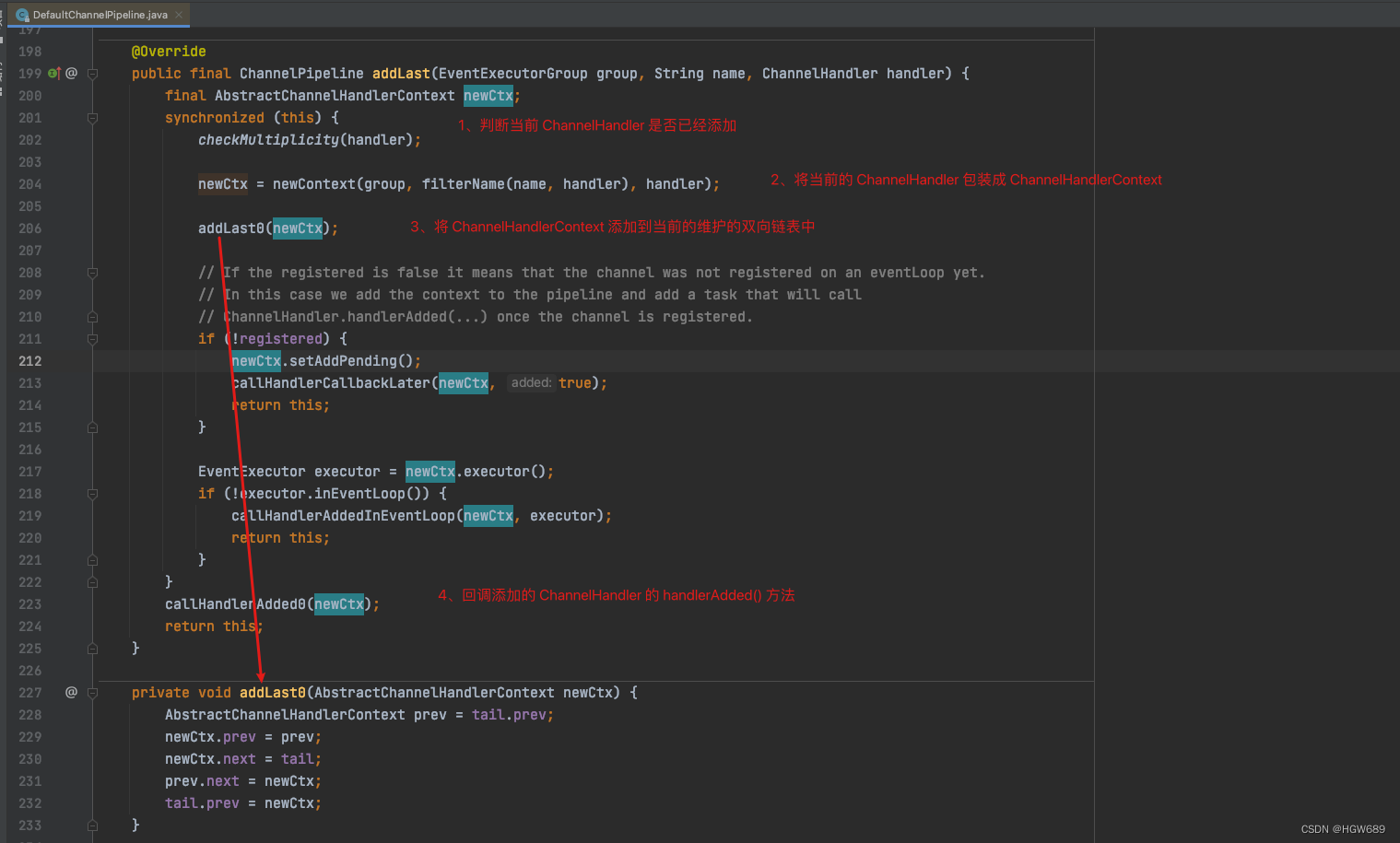
从 ChannelPipeline 的构造函数可以看出,ChannelPipeline 维护了一组 ChannelHandlerContext 实例组成双向链表。默认会包含 head 和 tail 头尾节点,用来进行一些默认的逻辑处理。我们自定义的ChannelHandler会插入到 head 和 tail 之间,这两个节点在 Netty 中已经默认实现了,它们在ChannelPipeline 中起到了至关重要的作用。
那么你可能会有疑问,为什么这里会多一层 ChannelHandlerContext 的封装呢?
其实这是一种比较常用的编程思想。ChannelHandlerContext用于保存ChannelHandler。ChannelHandlerContext包含了ChannelHandler生命周期的所有事件,如 connect、bind、read、 flush、write、close 等。
可以试想一下,如果没有ChannelHandlerContext 的这层封装,那么我们在做 ChannelHandler 之间传递的时候。前置后置的通用逻辑就要在每个 ChannelHandler 里都实现一份。
首先我们看下 HeadContext 和 TailContext 的继承关系

1、HeadContext
通过集成关系我们发现 HeadContext 分别实现了ChannelInboundHandler 和 ChannelOutboundHandler,即 HeadContext 既是 入站处理器,也是出站处理器。
HeadContext是入站的第一站,出站的最后一站。对于1个请求先由HeadContext处理入栈,经过一系列的入栈处理器然后传递到TailContext,由TailContext往下传递经过一系列的出栈处理器,最后再经过HeadContext返回。
2、TailContext
TailContext 只实现了 ChannelInboundHandler 接口。它会在 ChannelInboundHandler 调用链路的最后一步执行,主要用于终止 入站事件传播,例如释放 Message 数据资源等。
TailContext是入站的最后一站,出站的第一站。TailContext节点作为出站事件传播的第一站,仅仅是将出站事件传递给下一个节点。
从整个 ChannelPipeline 调用链路来看,如果由 Channel 直接触发事件传播,那么调用链路将贯穿整个 ChannelPipeline。然而也可以在其中某一个 ChannelHandlerContext 触发同样的方法,这样只会从当前的 ChannelHandler 开始执行事件传播,该过程不会从头贯穿到尾,在一定场景下,可以提高程序性能。
3、addLiast() 方法🔍
addLast() 方法是向 ChannelPipeline 中添加 ChannelHandler 用来进行业务处理,关于ChannelHandler将会在下文中详细讲解!
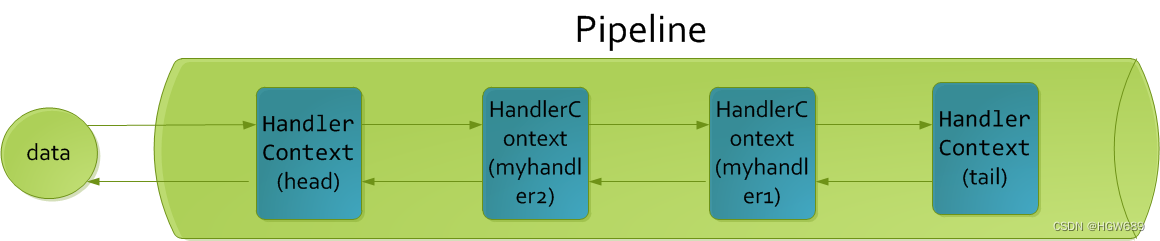
三、ChannelPipeline 事件传播机制
入站事件是由I/O线程被动触发,由入站处理器按自下而上的方向处理,在中途可以被拦截丢弃,出站事件由用户handler主动触发,由出站处理器按自上而下的方向处理。
接下来用一个示例来讲解~
服务端代码,
public class PipelineServer {public static void main(String[] args) throws InterruptedException {NioEventLoopGroup boss = new NioEventLoopGroup(1);NioEventLoopGroup worker = new NioEventLoopGroup(2);new ServerBootstrap().group(boss, worker).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel ch) throws Exception {ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(1);super.channelRead(ctx, msg);}});ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(2);super.channelRead(ctx, msg);}});ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(3);super.channelRead(ctx, msg);}});ch.pipeline().addLast(new ChannelOutboundHandlerAdapter() {@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {System.out.println(4);super.write(ctx, msg, promise);}});ch.pipeline().addLast(new ChannelOutboundHandlerAdapter() {@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {System.out.println(5);super.write(ctx, msg, promise);}});ch.pipeline().addLast(new ChannelOutboundHandlerAdapter() {@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {System.out.println(6);super.write(ctx, msg, promise);}});}}).bind(8080);}
}
客户端代码,
public class PipelineClient {public static void main(String[] args) throws InterruptedException {new Bootstrap().group( new NioEventLoopGroup()).channel(NioSocketChannel.class).handler(new ChannelInitializer<Channel>() {@Overrideprotected void initChannel(Channel ch) throws Exception {ch.pipeline().addLast(new StringDecoder());ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {System.out.println(msg);super.channelRead(ctx, msg);}});ch.pipeline().addLast(new StringEncoder());}}).connect("127.0.0.1", 8080).sync().channel().writeAndFlush("Hello,server!");}
}
依次启动服务端和客户端,服务端打印如下:
1
2
3
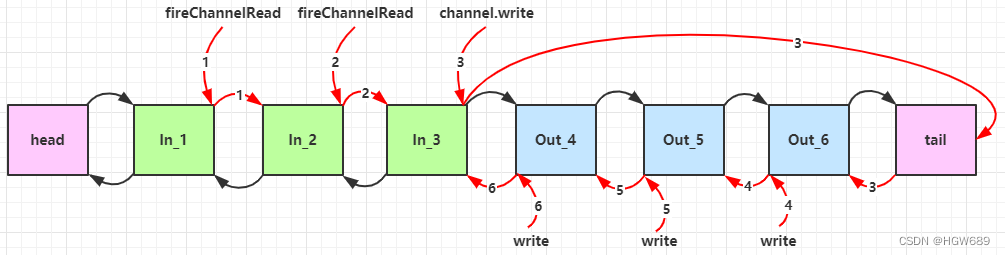
以上我们通过 Pipeline 的 addLast 方法分别添加了三个 ChannelInboundHandlerAdapter 和 ChannelOutboundHandlerAdapter,添加顺序分别是 1 -> 2 -> 3,4 -> 5 -> 6。
此时为什么没有打印 4、5、6呢,即没有触发出站的操作❓
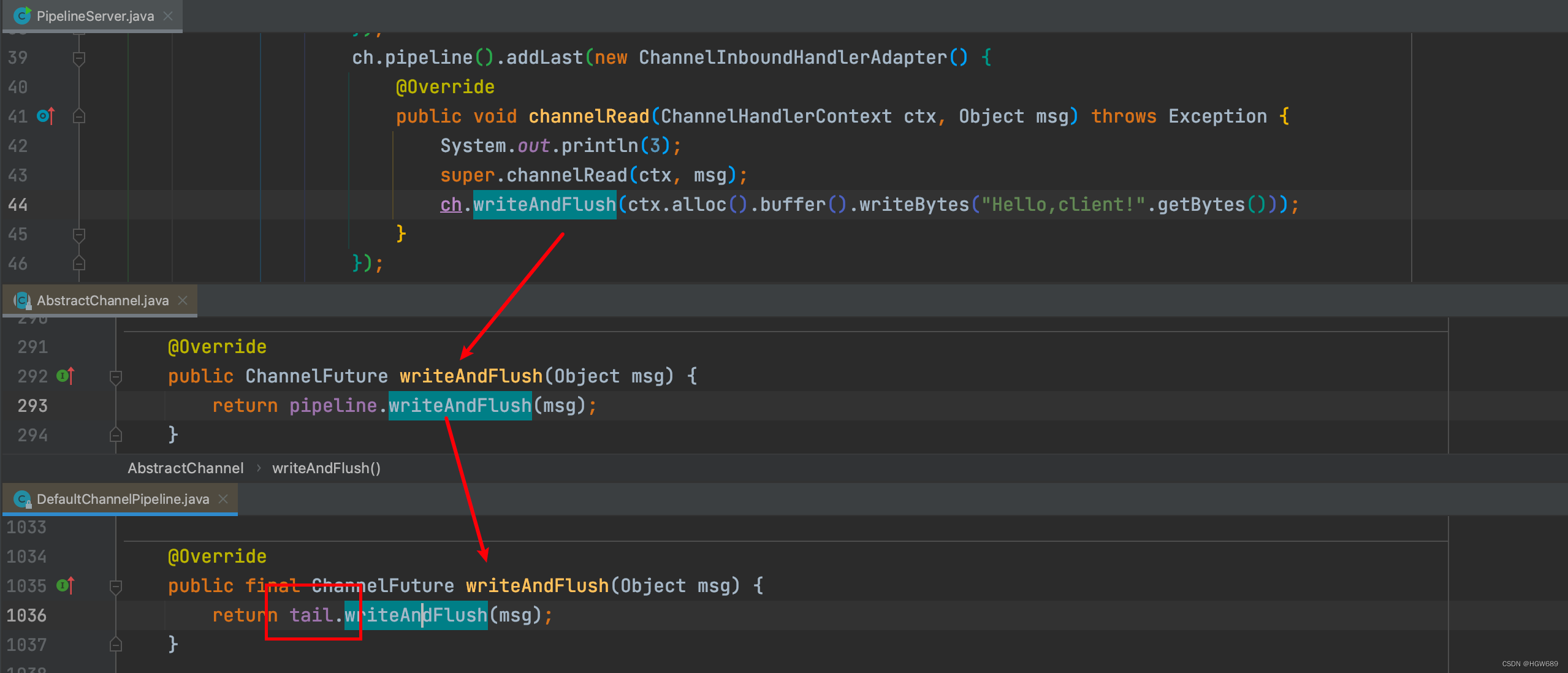
出站处理器只有向channel中写入数据才会触发,我们在第三个 ChannelInboundHandlerAdapter 实现类中加入以下代码!
通过依次点入,我们发现最终是调用了 tail节点 的writeAndFlush 方法,即TailContext节点作为出站事件传播的第一站!

最终服务端打印如下:
1
2
3
6
5
4
可以看到,ChannelInboundHandlerAdapter 是按照 addLast 的顺序执行的,而 ChannelOutboundHandlerAdapter 是按照 addLast 的逆序执行的。ChannelPipeline 的实现是一个 ChannelHandlerContext(包装了 ChannelHandler) 组成的双向链表

- 入站处理器中,ctx.fireChannelRead(msg) 是 调用下一个入站处理器
- 如果注释掉 1 处代码,则仅会打印 1
- 如果注释掉 2 处代码,则仅会打印 1 2
- 3 处的 ctx.channel().write(msg) 会 从尾部开始触发 后续出站处理器的执行
- 如果注释掉 3 处代码,则仅会打印 1 2 3
- 类似的,出站处理器中,ctx.write(msg, promise) 的调用也会 触发上一个出站处理器
- 如果注释掉 6 处代码,则仅会打印 1 2 3 6
- ctx.channel().write(msg) vs ctx.write(msg)
- 都是触发出站处理器的执行
- ctx.channel().write(msg) 从尾部开始查找出站处理器
- ctx.write(msg) 是从当前节点找上一个出站处理器
- 3 处的 ctx.channel().write(msg) 如果改为 ctx.write(msg) 仅会打印 1 2 3,因为节点3 之前没有其它出站处理器了
- 6 处的 ctx.write(msg, promise) 如果改为 ctx.channel().write(msg) 会打印 1 2 3 6 6 6… 因为 ctx.channel().write() 是从尾部开始查找,结果又是节点6 自己
如图,服务端 pipeline 触发的原始流程,图中数字代表了处理步骤的先后次序
四、ChannelPipeline 异常传播机制
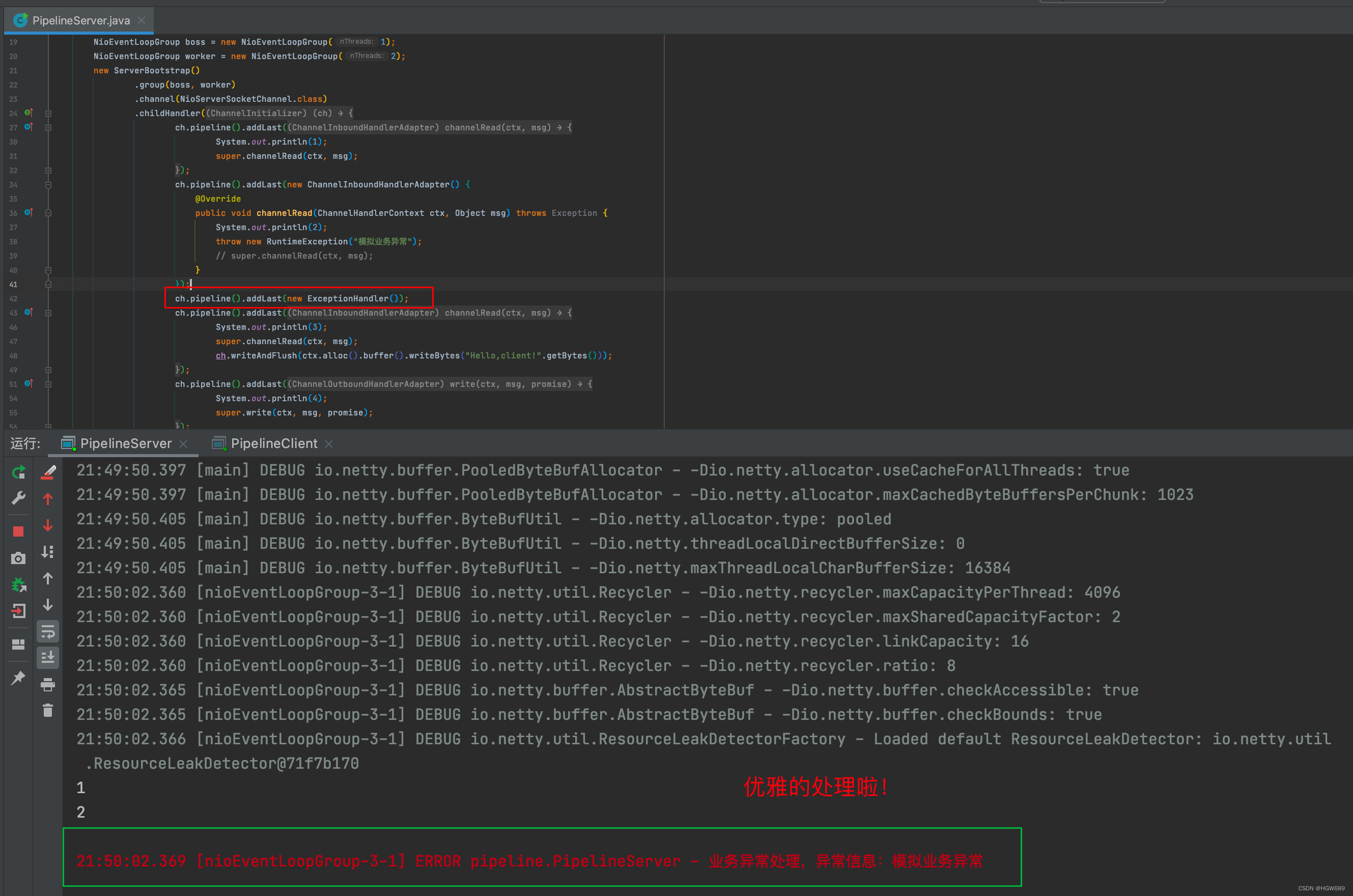
ChannelPipeline 事件传播的实现采用了经典的责任链模式,调用链路环环相扣。那么如果有一个节点处理逻辑异常会出现什么现象呢?我们通过修改 第二个 ChannelInboundHandlerAdapter 实现类 的实现来模拟业务逻辑异常:

由输出结果可以看出 ctx.fireExceptionCaugh 会将异常按顺序从 Head 节点传播到 Tail 节点。
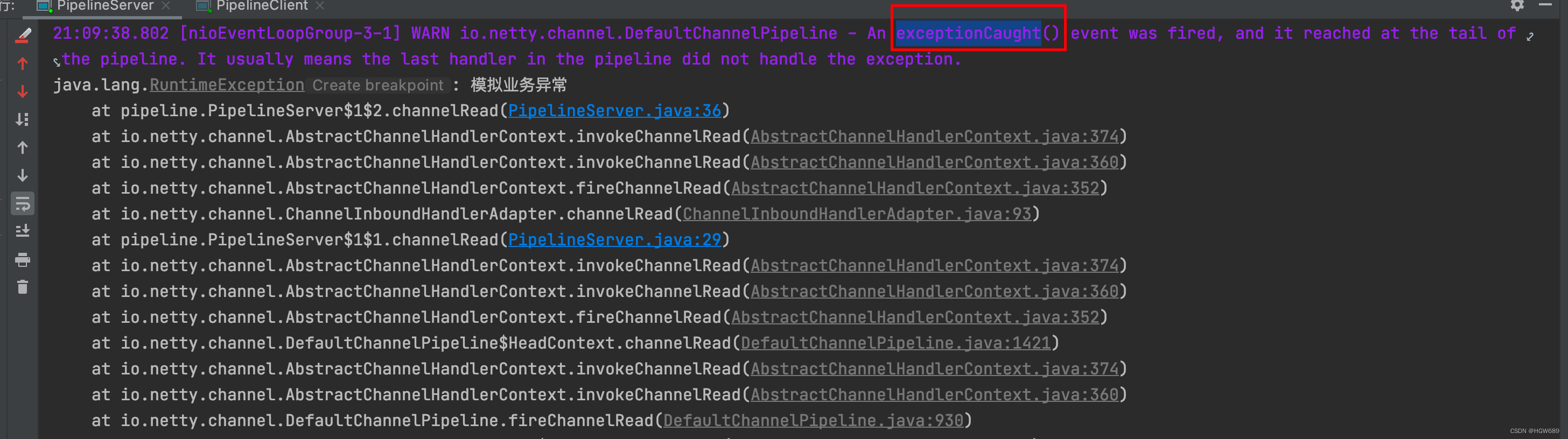
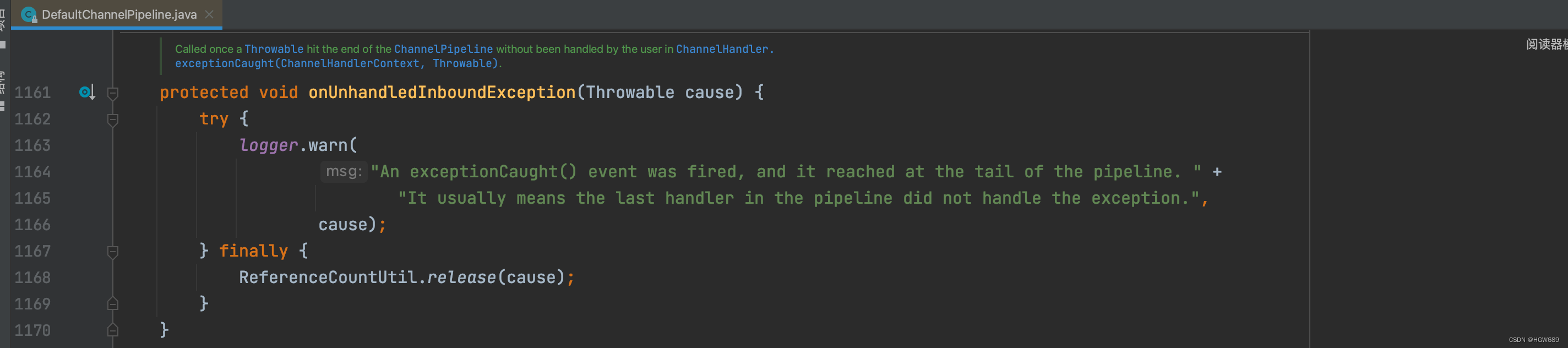
如果用户没有对异常进行拦截处理,最后将由 Tail 节点统一处理,在 TailContext 源码中可以找到具体实现:
五、统一的异常处理器
在 Netty 应用开发的过程中,良好的异常处理机制会让开发在排查问题的时候事半功倍。虽然 Netty 中 TailContext 提供了兜底的异常处理逻辑,但是在很多场景下,并不能满足我们的需求。假如你需要拦截指定的异常类型,并做出相应的异常处理,应该如何实现呢?
小编个人推荐用户对异常进行统一拦截,然后根据实际业务场景实现更加完善的异常处理机制。
通过异常传播机制的学习,我们应该可以想到最好的方法是在 ChannelPipeline 自定义处理器的末端添加统一的异常处理器!
/*** 自定义异常处理器*/
public static class ExceptionHandler extends ChannelDuplexHandler {@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {if (cause instanceof RuntimeException) {System.out.println();log.error("业务异常处理,异常信息:{}", cause.getMessage());}}
}