文章目录
- 概述
- SCSI错误恢复处理
- 添加错误恢复命令
- 错误恢复线程
- scsi_eh_ready_devs
- IO超时处理
- 相关参考
概述
IO路径是一个漫长的过程,从SCSI命令请求下发到请求完成返回,中间的任何一个环节出现问题都会导致IO请求的失败。从SCSI子系统到低层驱动,再到实际的物理设备,每一层都应该在出现问题的时候,将错误的原因返回给上一层。SCSI子系统提供了错误恢复机制,对低层上报的错误IO执行可能的恢复策略,包括IO重试、复位设备,严重的还会对整个SCSI主机适配器进行复位等。
SCSI错误恢复处理
对于出错的IO请求,SCSI子系统会将其挂到SCSI主机适配器的错误处理链表中,然后唤醒错误恢复线程,对链表中的异常IO进行错误处理。
添加错误恢复命令
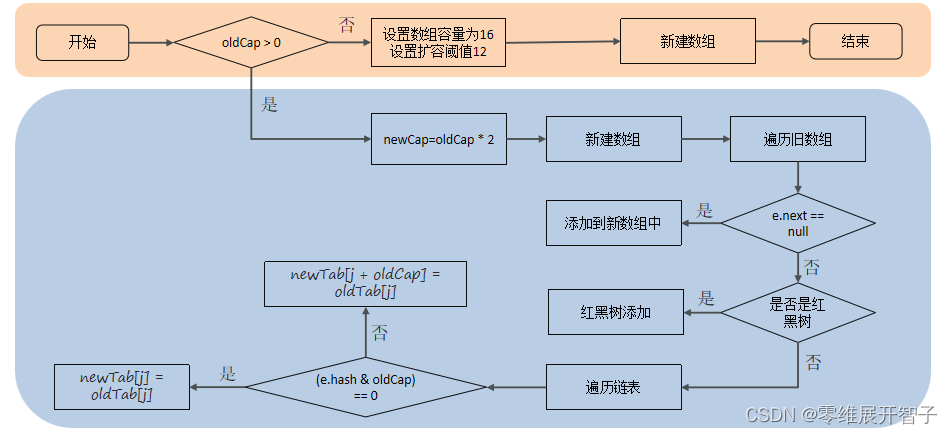
SCSI子系统调用scsi_eh_scmd_add接口将SCSI命令加入到错误处理中,scsi_eh_scmd_add处理流程如下:
- 将错误的scsi命令通过eh_entry字段链入到SCSI host维护的eh_cmd_q链表中;
- 设置SCSI host中shost_state中SHOST_RECOVERY位;
- 递增SCSI host的host_failed计数;
- 当SCSI host中host_busy统计等于host_failed相等时,唤醒SCSI错误处理线程。

错误恢复线程
SCSI使用单独的内核线程来完成错误恢复的处理,对于每个SCSI Host都会维护这样的一个线程,线程命名的方式是scsi_eh_#,其中#为系统为SCSI Host分配的唯一编号。错误恢复线程的入口函数是scsi_error_handler。

scsi_error_handler会优先调用SCSI Transport层定义错误恢复回调,若Transport层未定义,则会使用SCSI中层默认的错误恢复策略,入口函数为scsi_unjam_host。scsi_unjam_host维护两条临时队列:work_q和done_q,其中work_q存放错误的IO请求,done_q存放恢复的IO请求。scsi_unjam_host通过一系列修复动作,处理work_q中的错误IO请求,并在处理完成后转移到done_q,最后将done_q中的请求按照诊断结果统一进行处理。
scsi_eh_ready_devs
scsi_eh_ready_devs会执行一系列的修复动作,以试图修复错误的IO,在出现严重的IO错误时,甚至会将整个SCSI主机适配器进行复位;如果到最后还有错误的IO无法恢复,那么SCSI会将关联的设备置为离线状态,离线的设备将不允许再下发IO请求。

IO超时处理
通常来说,IO的完成状态是明确的,要么是成功返回,要么是出现IO错误返回,但还有一种异常场景是IO请求下发后,一直未返回,这种情况下,由于IO的状态是未知的,需要进行特殊处理。
从块层下发的IO请求,都会配置一个超时定时器,对于SCSI默认设置是30s。当IO请求下发后,超过这个时间没有返回,就会触发超时处理。SCSI注册的超时回调接口是scsi_times_out。当IO超时产生时,scsi_times_out函数将:
- 调用scsi host注册的eh_timed_out回调(如果有),由驱动决定超时IO的处理策略。eh_timed_out回调的返回结果有两种:
- BLK_EH_RESET_TIMER:重新设置超时定时器;
- BLK_EH_DONE:表示驱动未能处理这个超时IO,交由SCSI继续处理。
- 调用scsi_abort_command取消SCSI命令请求;
- 调用scsi_eh_scmd_add将超时的IO请求加入到错误处理队列中,等待错误恢复线程处理。

相关参考
- 《存储技术原理分析:基于Linux 2.6内核源代码分析》