网站:www.redis.cn
redis 部署
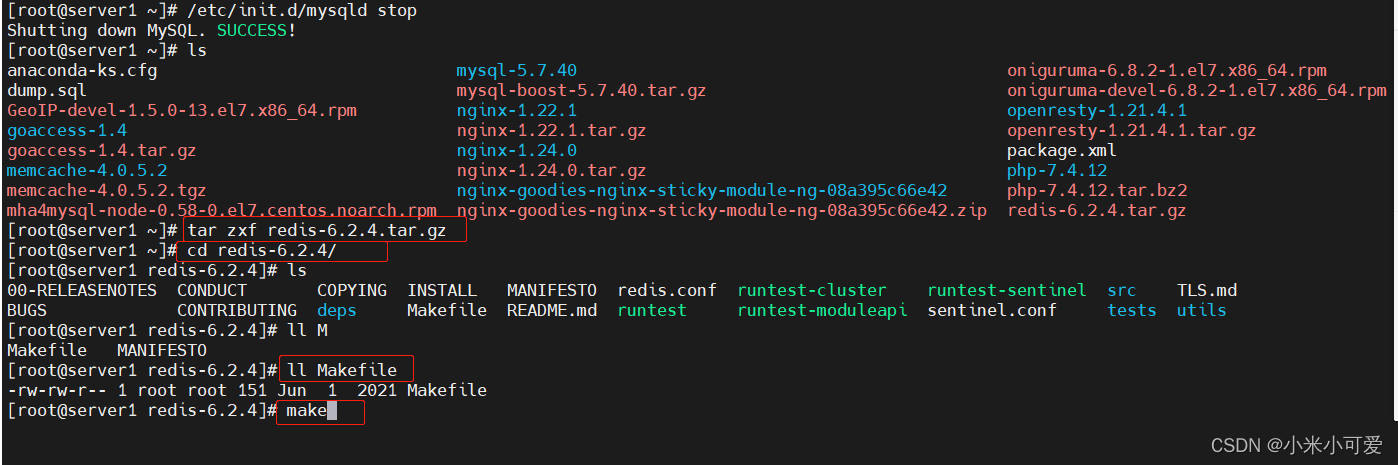
make的时候需要gcc和make 如果在纯净的环境下需要执行此命令
[root@server3 redis-6.2.4]# yum install make gcc -y
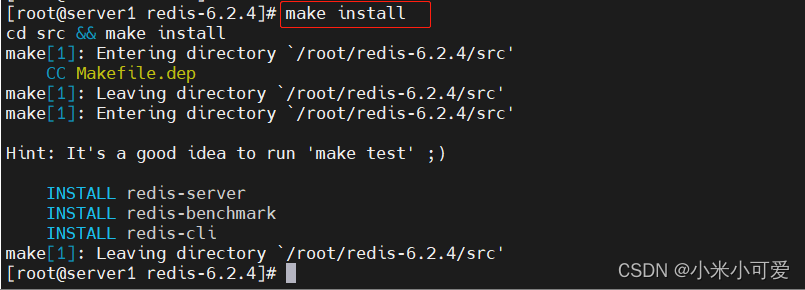
 注释一下这几行
注释一下这几行

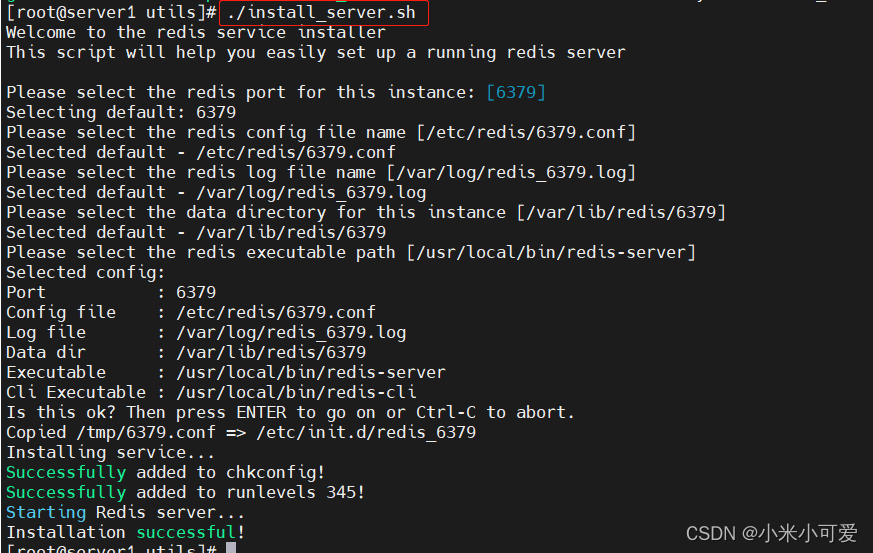

vim /etc/redis/6739.conf



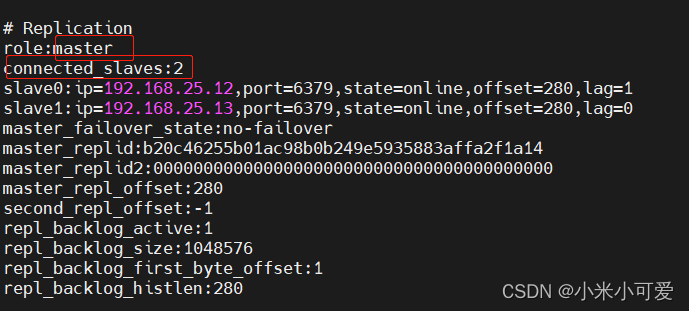
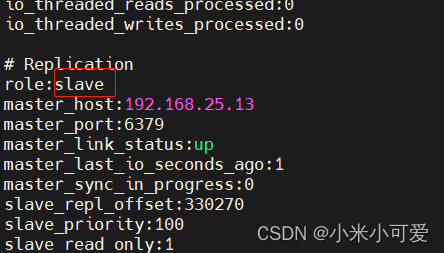
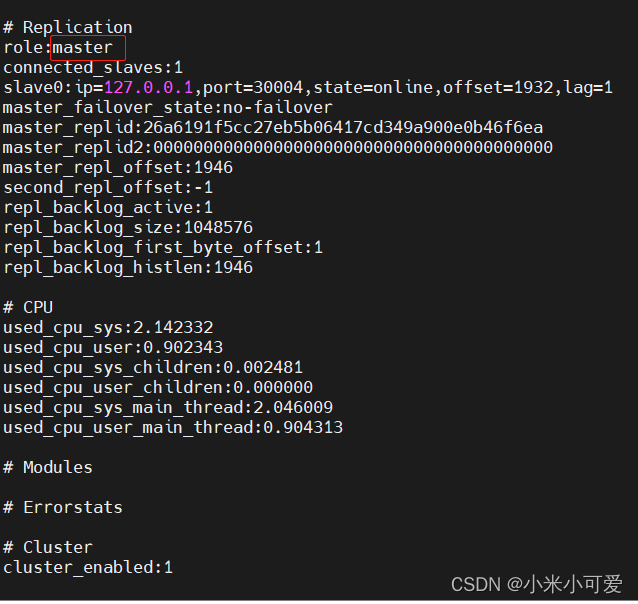
2.Redis主从复制
设置 11 是master 12 13 是slave
在12 上
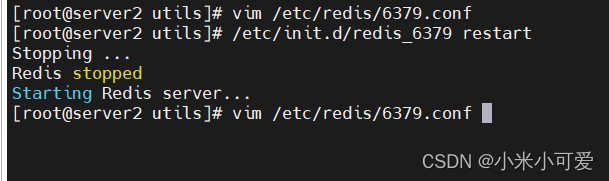

其他节点以此内推
此时在 11 master 上
![]()
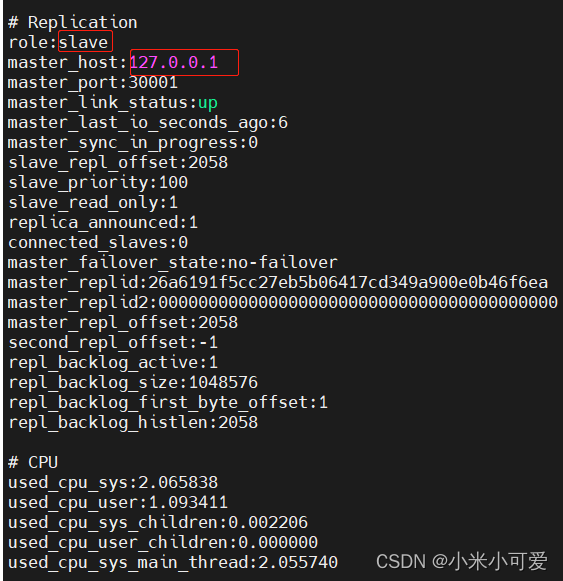
 slave 角色只能读 没有修改的权限
slave 角色只能读 没有修改的权限
当在master上
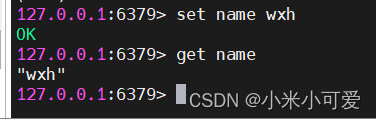
在slave会实现同步
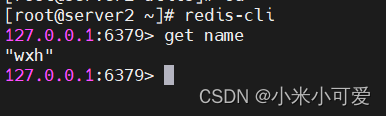

redis高可用
redis 主从切换
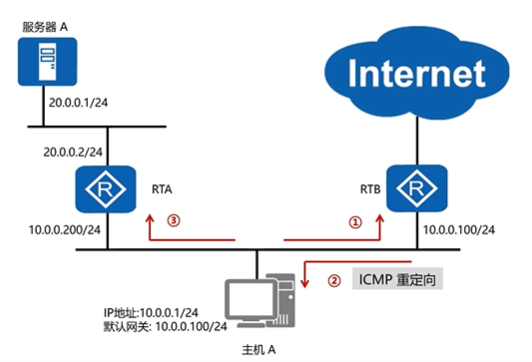
redis 主从原理:基于rdb 快照实现 它和MySQL的二进制日志的差别(数据类型不同)
在执行主从的时候:slave和master要先做一个认证 发起一个同步请求,master会执行一个bgsave(异步模式)/save(阻塞模式),异步模式的时候,bgsave会做一个rdb快照,然后把rdb快照发给slave,slave会做一个动作,清掉slave端所有的数据(flushall),然后slave会再次加载快照,
快照做完之后,还会有变更数据,所以放在缓存里面,然后接下来会用replicationfeedslave()增量函数 一条一条发给slave,然后再给slave端做同步 redis主从基于rdb快照格式出现
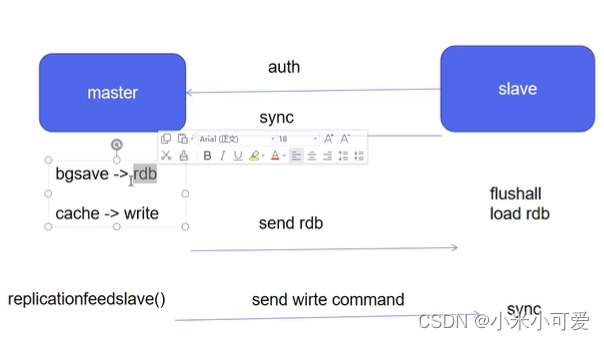
redis 主从基于快照rdb快照格式实现
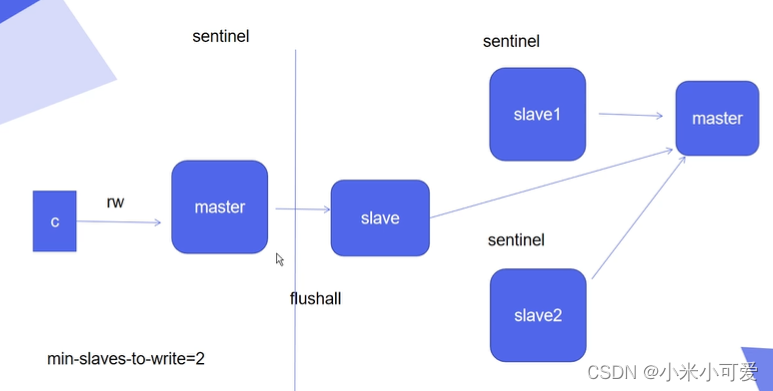
一主多从的架构中 做高可用切换 redis 里自带

2 表示的意思:怎么判断master出故障呢,必须要两个节点说master出故障了 才能发起故障切换
当第一个节点发现master出现故障 会进入一种主观下线状态
当第二个节点发现master出现故障 会再次进入一种主观下线状态
两次的主观下线会触发一次客观下线,这个时候master会开始真正进行主从切换
三个节点就设置为2 两个节点就设置为1
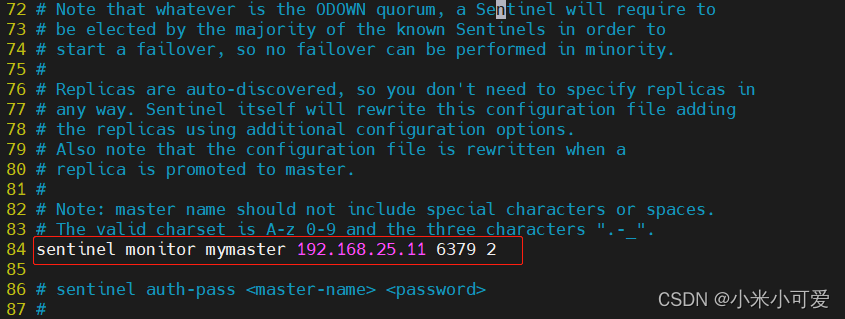
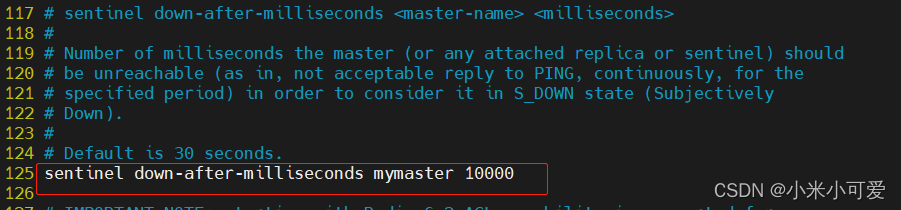
拷贝文件的动作 一定要在启动之前

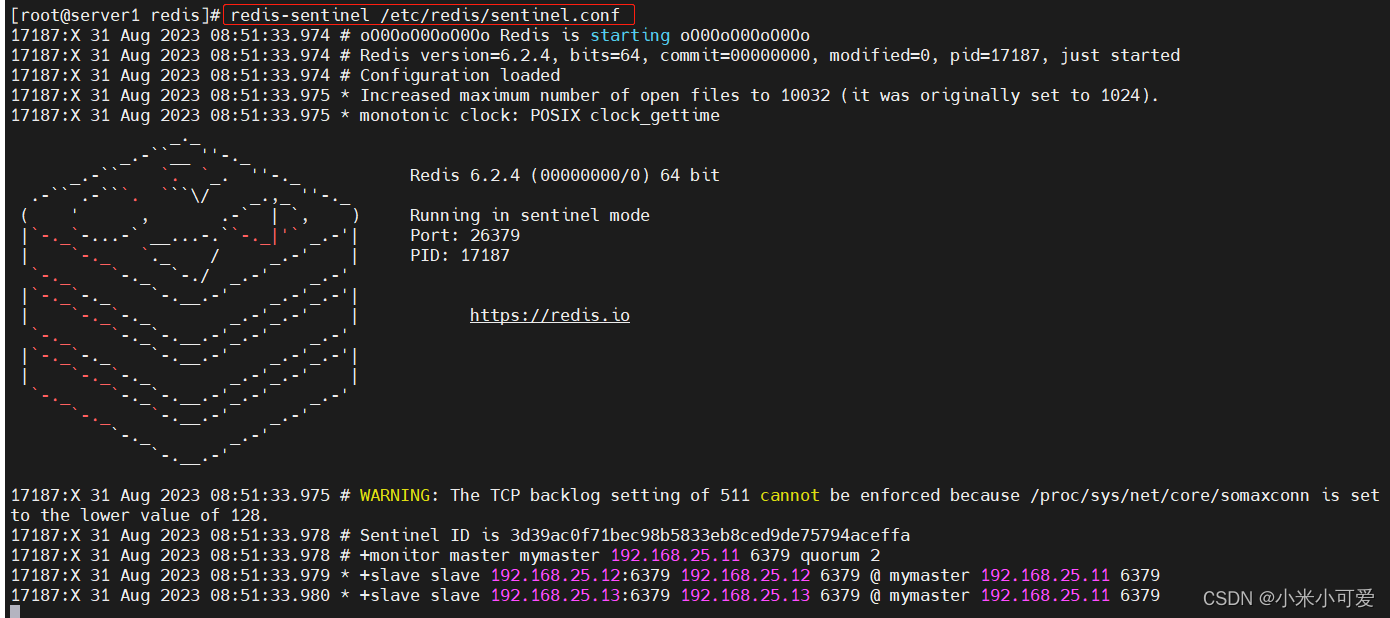
其它主机直接启动服务,无需更改配置文件
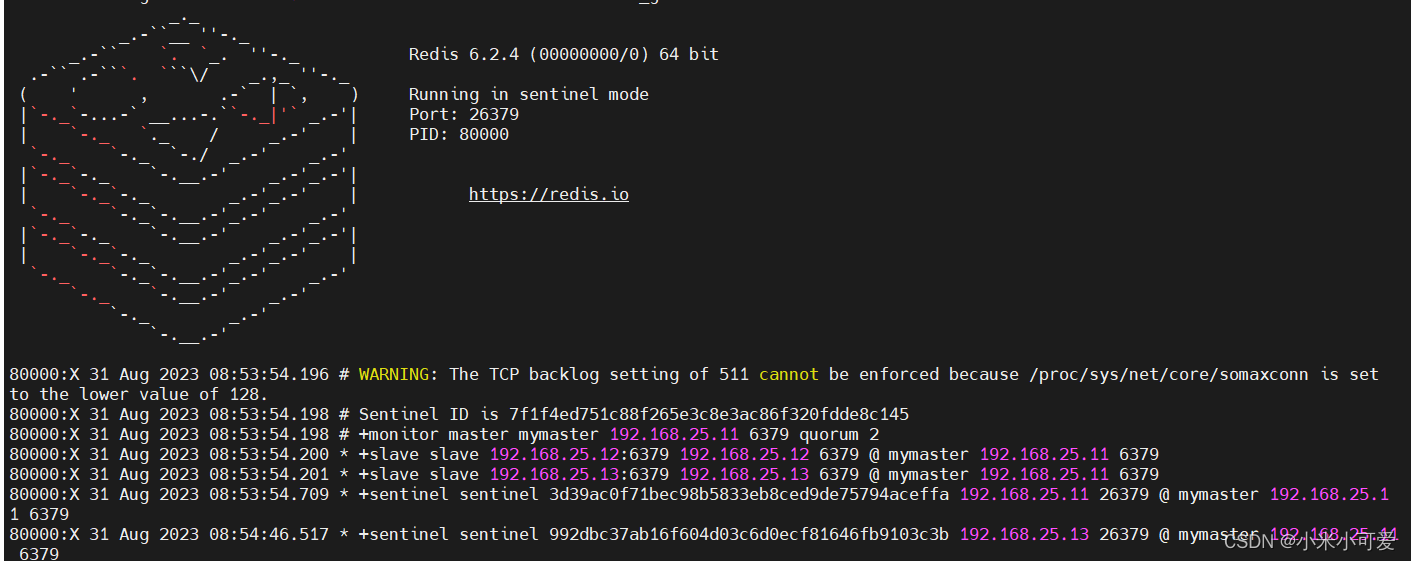

这就是哨兵模式
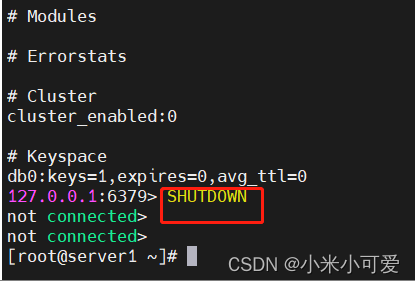
此时 在开一个终端11 11 此时是master
关闭master
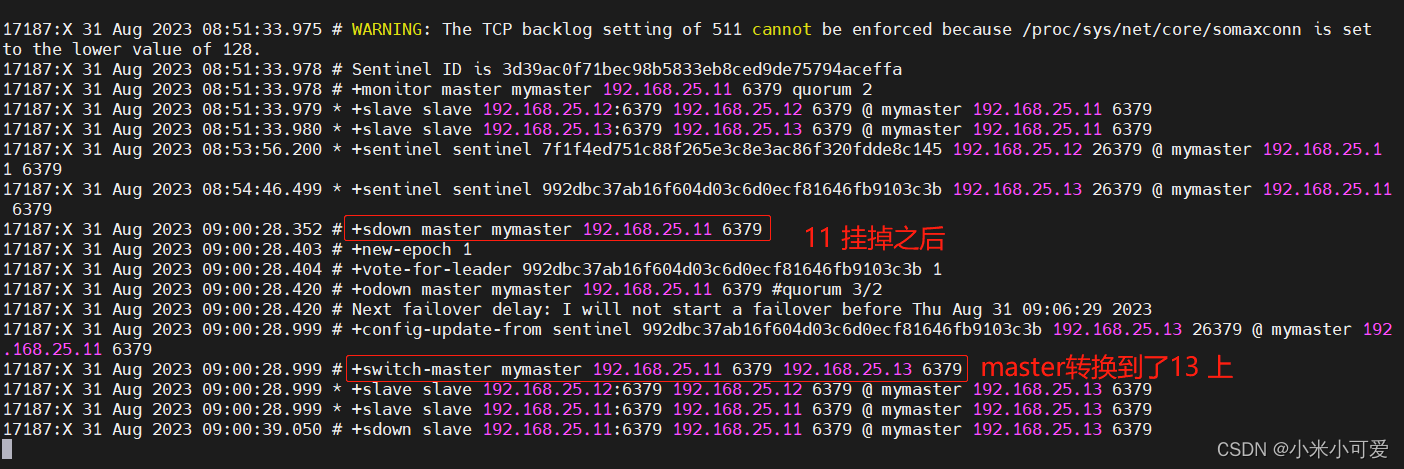
redis集群 会自动切换master
当原来的master再次启动后,会以slave身份加入集群

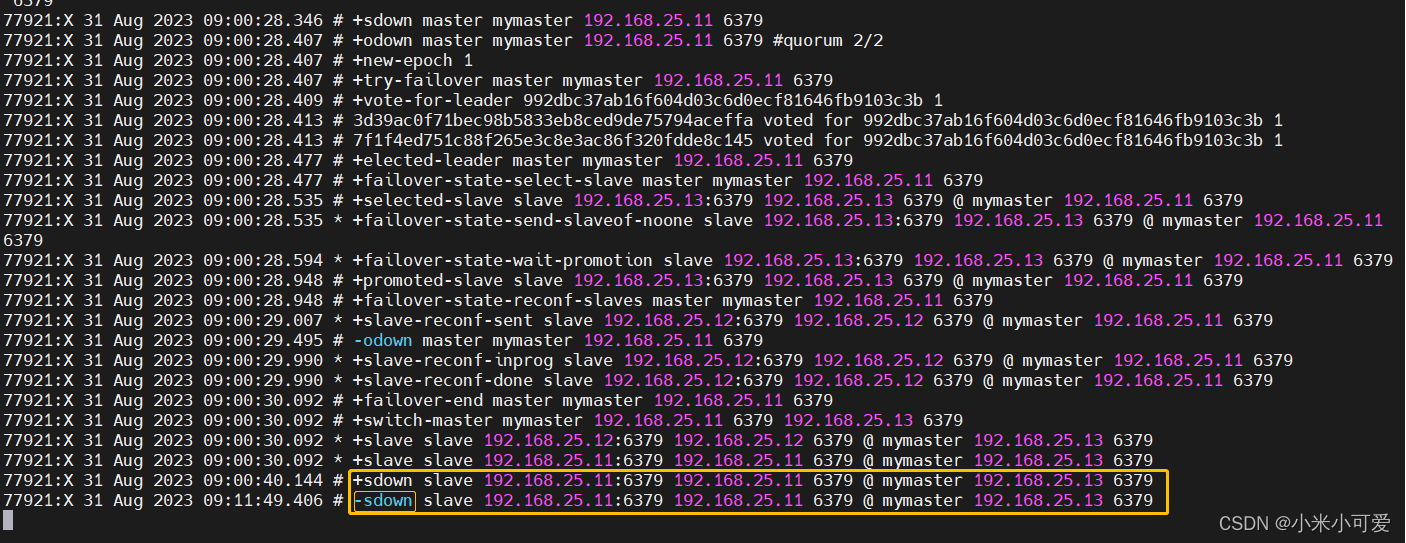
在切换的时候可能会出现的问题
客户端到master没什么问题,master 到slave端的网络如果出现故障
这个时候就会把master踢出去 选举出新的master slave接上去
当网络又正常 原来的master 会同步当前集群的配置 把自己变成slave 接入到新的master 这样的话 原来的master上所有数据都会丢失
但是 客户端到master是好的 这个时候 客户端会持续往master里写数据 客户一直在写 但是master到slave出现故障 master就会变为slave 数据就会被清掉
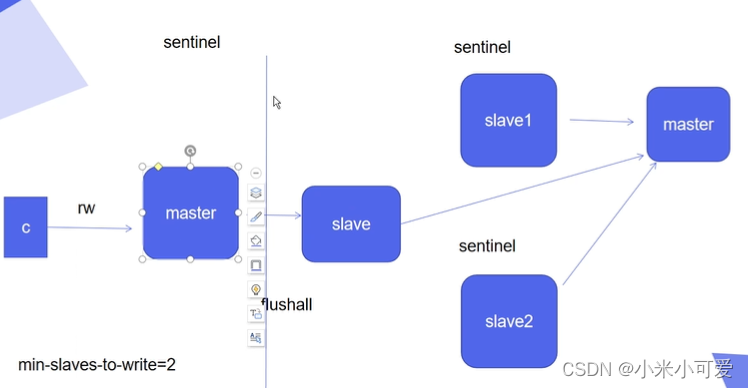
怎么解决呢
必需保证后端有两个slave可以写
添加 min-slave-to-write=2 到配置文件
保证在主从切换的时候 客户端不要给master里面写 如果master发现都连不上两个slave 就不要往里面写入数据了 避免数据丢失
Redis集群
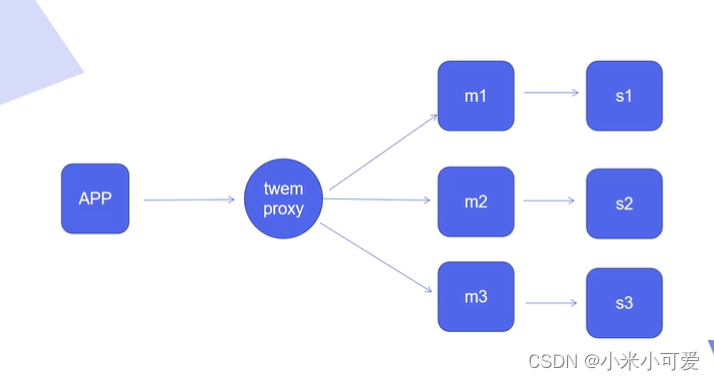
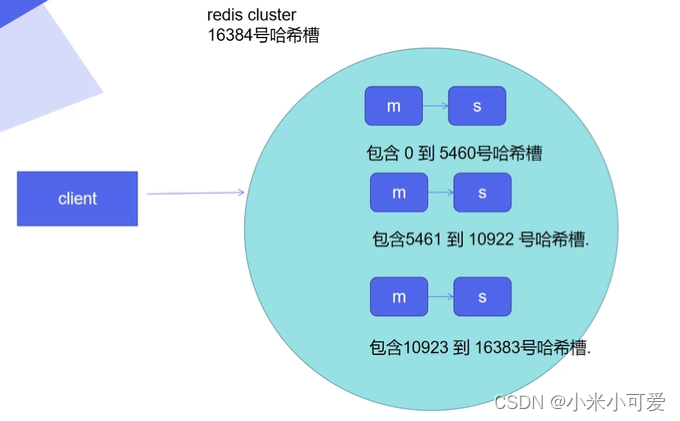
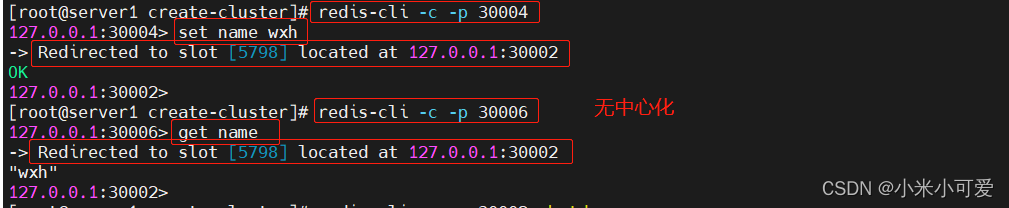
无中心化设计 每个节点都可以接入集群 不管是主从 都可以进行读写 在接入集群之后都可以做调度 做重定向 但是 它的整合度太高了 二次开发成本太高
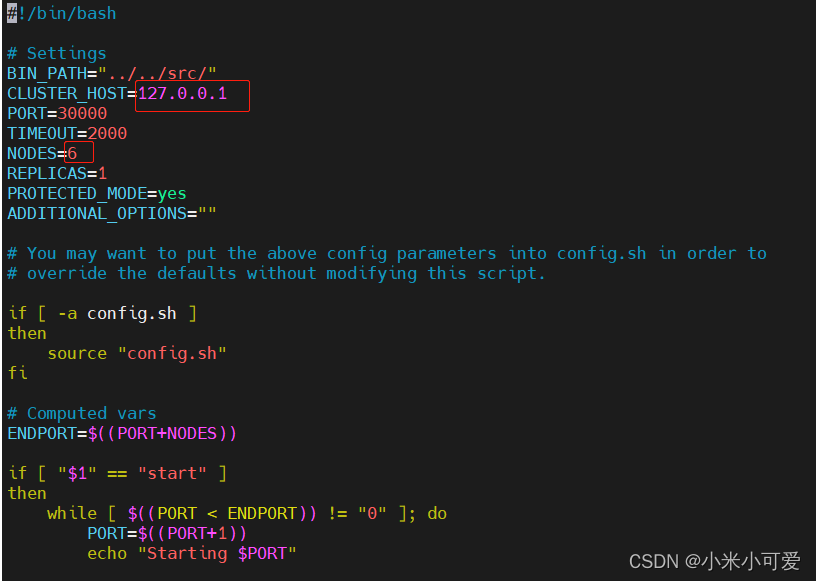
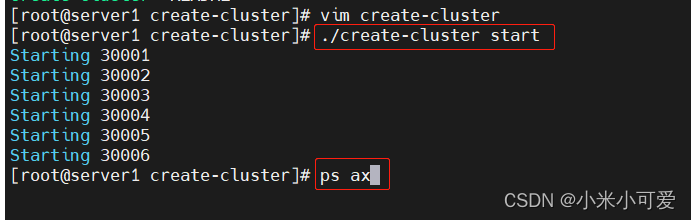
 会在当前的目录里 生成对应的配置文件和数据
会在当前的目录里 生成对应的配置文件和数据

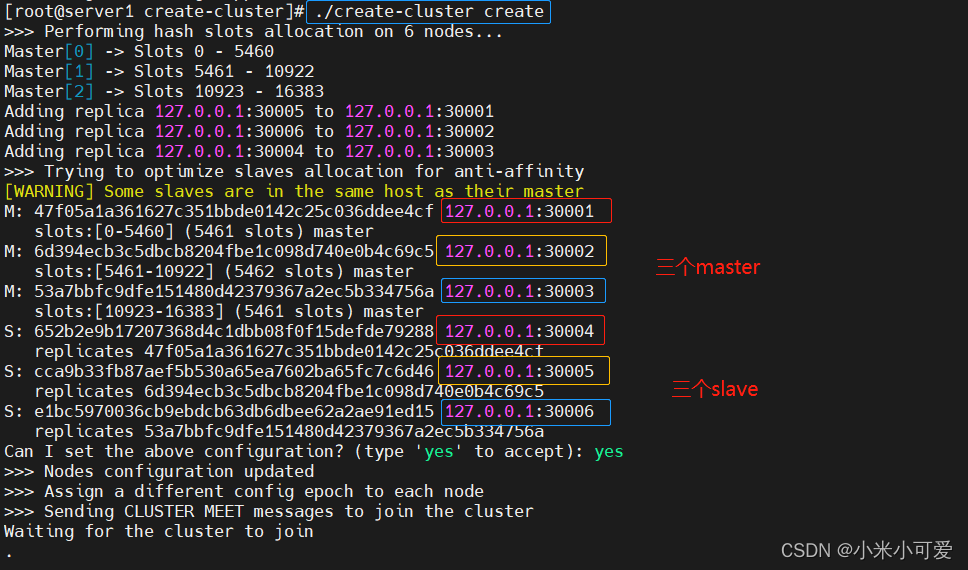
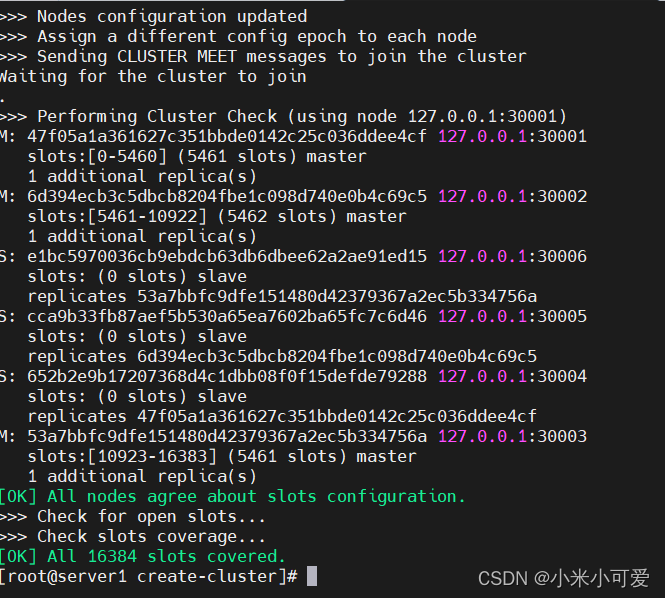
这样就创建好了一个集群
查看命令帮助
redis-cli --help
获取集群状态

主从关系的详细信息

redis-cli --cluster 实际就是把总共16384个哈希槽 ,均摊到这三个master 进行存储 每个节点都会分得一定比例的哈希槽,哈希槽就是存数据用的
连接集群
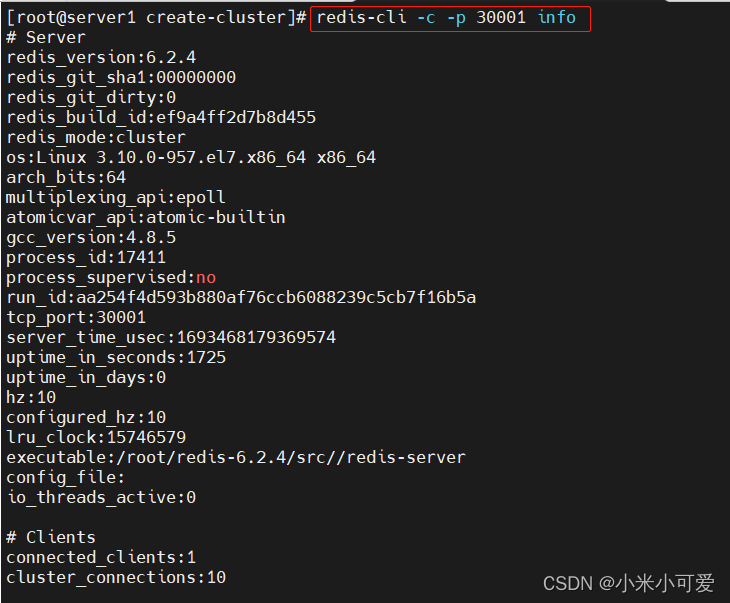

关闭redis实例,集群自动切换
30002的 master 关闭 30005之前是slave 就会接管变成master
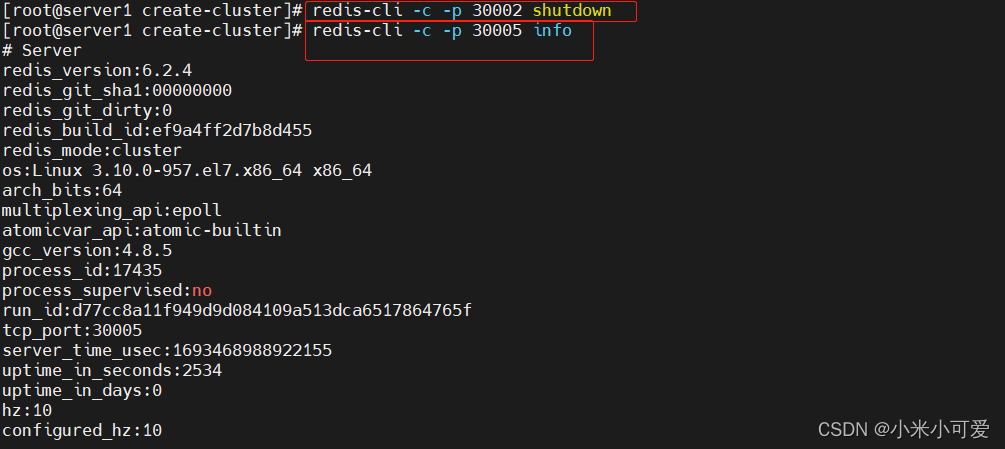
此时 数据就会在30005上 数据不会丢失

以上就是 redis 内置的高可用切换
如果再把脚本启动起来 这时候 刚才关闭的30002 就会被再次拉起来
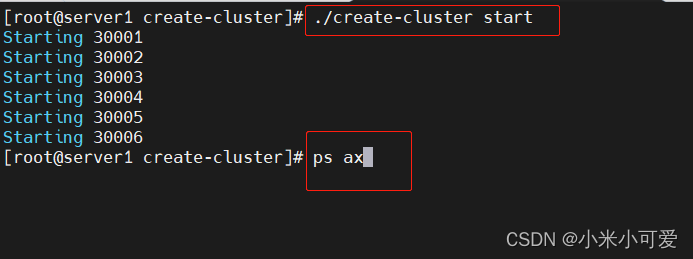
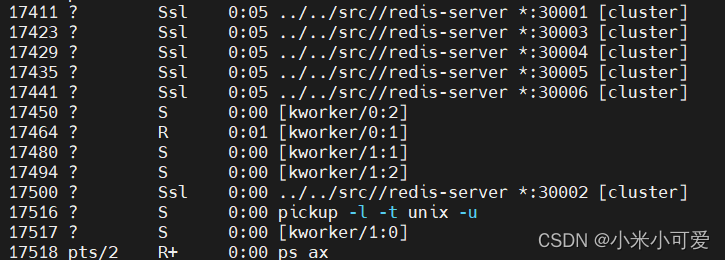
拉起来之后 30002 就是slave
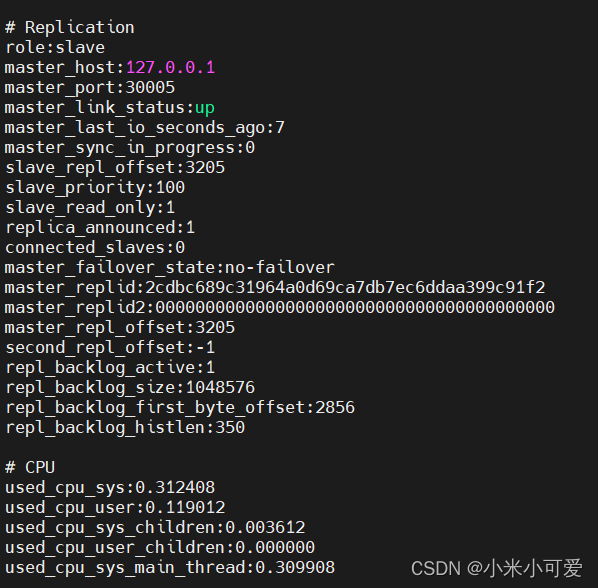
此时 互换了角色
设么么时候会导致这个进群节点不可用
1 这16384这些哈希槽如果不完整集群不可用
2.同一这个集群的半数master同时挂掉
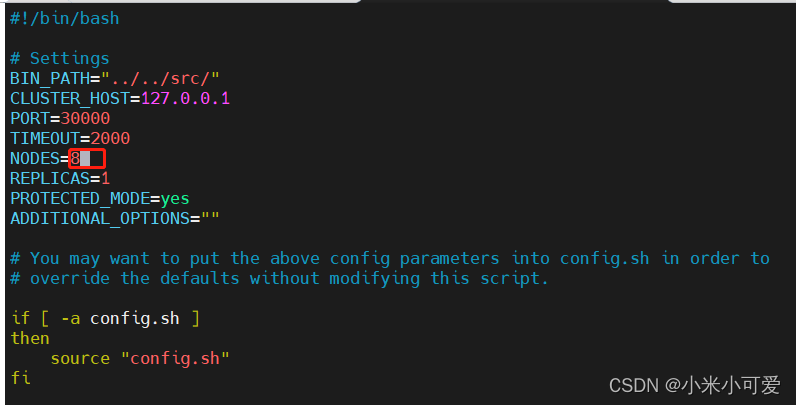
再启动两个redis实例

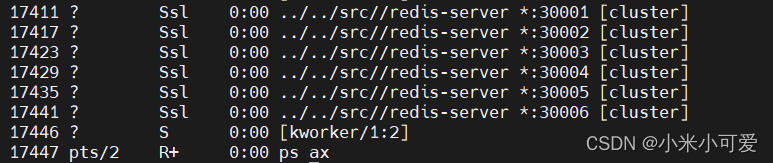
 ps ax
ps ax
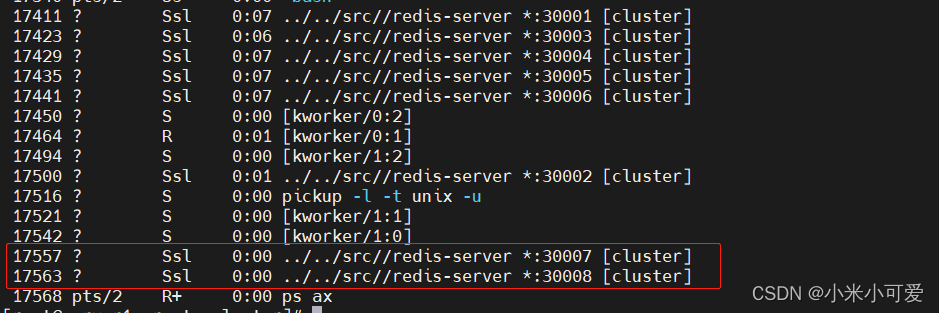
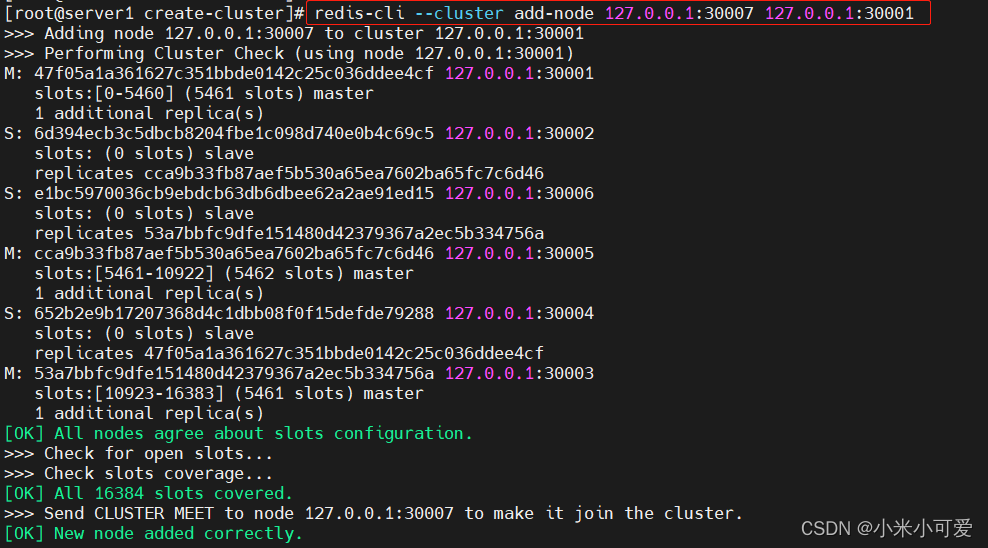
在线添加集群节点
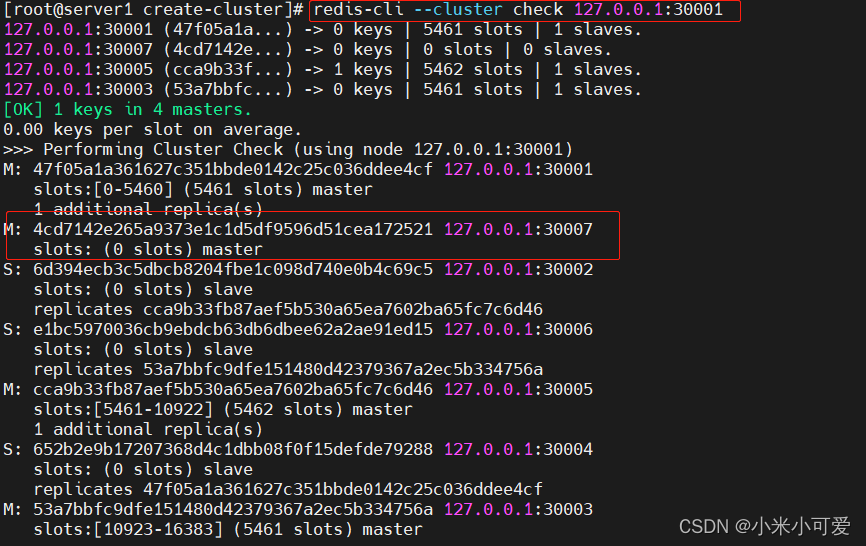
新添加的节点没有hash槽,角色时是master
添加slave节点
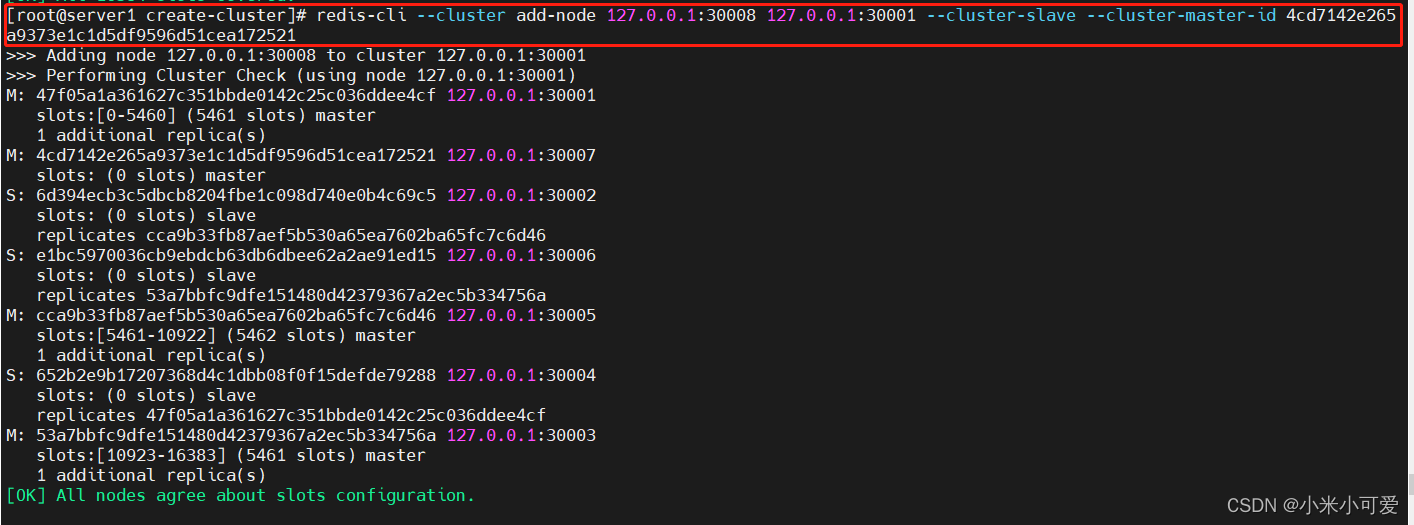

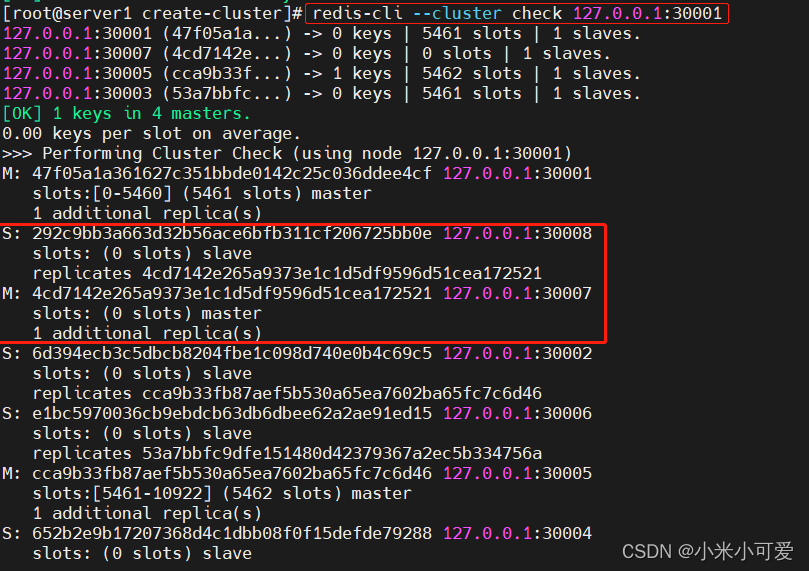
重新迁移hash槽
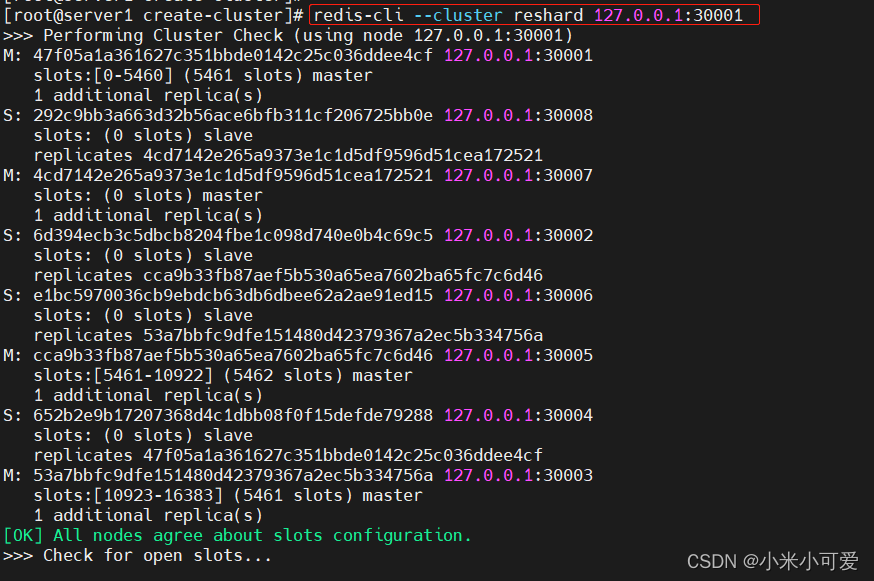
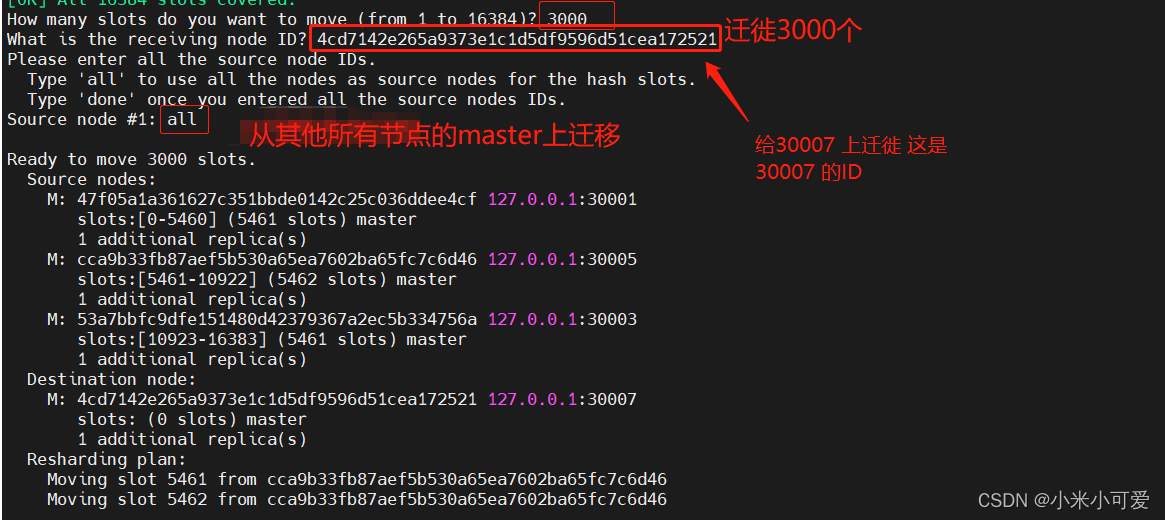
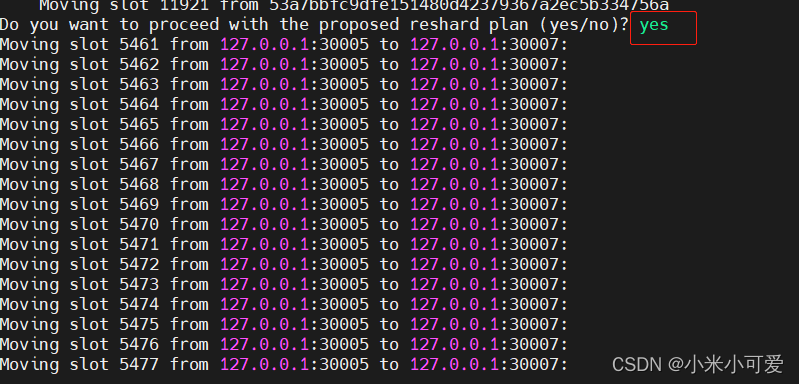
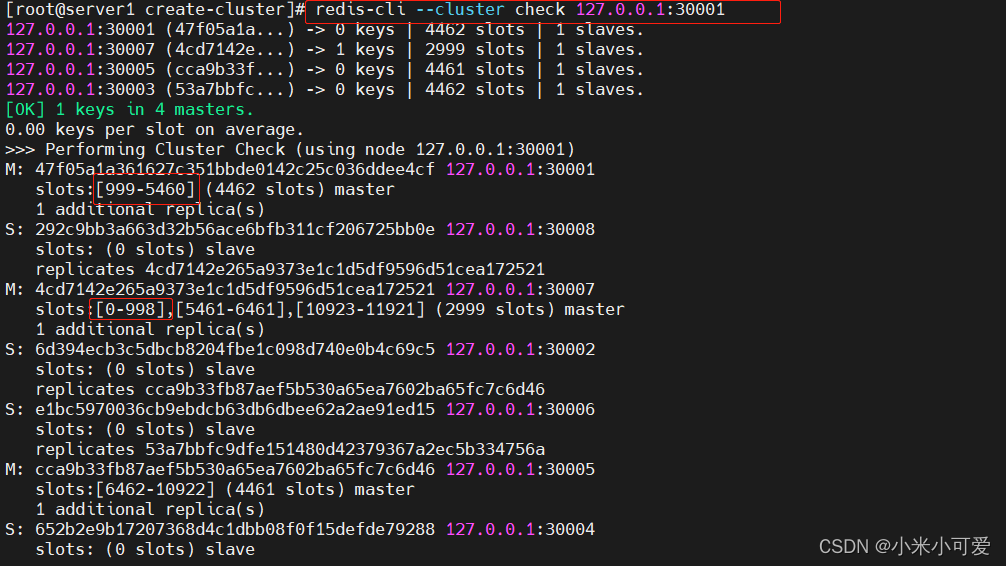
删除哪个节点的时候
就得把这个节点上的哈希槽迁徙到别的机器上
要不然就会造成哈希槽不完整 集群就会shutdown