机器学习是一项经验技能,实践是掌握机器学习、提高利用机器学习
解决问题的能力的有效方法之一。那么如何通过机器学习来解决问题呢?
本节将通过一个实例来一步一步地介绍一个回归问题。
本章主要介绍以下内容:
- 如何端到端地完成一个回归问题的模型。
- 如何通过数据转换提高模型的准确度。
- 如何通过调参提高模型的准确度。
- 如何通过集成算法提高模型的准确度。
1 定义问题
在这个项目中将分析研究波士顿房价(Boston House Price)数据集,这个数据集中的每一行数据都是对波士顿周边或城镇房价的描述。数据是1978年统计收集的。数据中包含以下14个特征和506条数据(UCI机器学习仓库中的定义)。
· CRIM:城镇人均犯罪率。
· ZN:住宅用地所占比例。
· INDUS:城镇中非住宅用地所占比例。
· CHAS:CHAS虚拟变量,用于回归分析。
· NOX:环保指数。
· RM:每栋住宅的房间数。
· AGE:1940年以前建成的自住单位的比例。
· DIS:距离5个波士顿的就业中心的加权距离。
· RAD:距离高速公路的便利指数。
· TAX:每一万美元的不动产税率。
· PRTATIO:城镇中的教师学生比例。
· B:城镇中的黑人比例。
· LSTAT:地区中有多少房东属于低收入人群。
· MEDV:自住房屋房价中位数。
通过对这些特征属性的描述,我们可以发现输入的特征属性的度量单位是不统一的,也许需要对数据进行度量单位的调整。
2 导入数据
首先导入在项目中需要的类库。代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
接下来导入数据集到Python中,这个数据集也可以从UCI机器学习仓库下载,在导入数据集时还设定了数据属性特征的名字。
代码如下:
#导入数据
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)
3 理解数据
对导入的数据进行分析,便于构建合适的模型。首先看一下数据维度,例如数据集中有多少条记录、有多少个数据特征。
代码如下:
print('data.shape=',data.shape)
执行之后我们可以看到总共有506条记录和14个特征属性,这与UCI提供的信息一致。
data.shape= (506, 14)
再查看各个特征属性的字段类型。代码如下:
#特征属性字段类型
print(data.dtypes)
可以看到所有的特征属性都是数字,而且大部分特征属性都是浮点
数,也有一部分特征属性是整数类型的。执行结果如下:
crim float64
zn float64
indus float64
chas int64
nox float64
rm float64
age float64
dis float64
rad int64
tax int64
ptratio float64
b float64
lstat float64
medv float64
dtype: object
接下来对数据进行一次简单的查看,在这里我们查看一下最开始的30条记录。代码如下:
print(data.head(30))
执行结果如下:
crim zn indus chas nox ... tax ptratio b lstat medv
0 0.00632 18.0 2.31 0 0.538 ... 296 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 ... 242 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 ... 242 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 ... 222 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0 0.458 ... 222 18.7 396.90 5.33 36.2
5 0.02985 0.0 2.18 0 0.458 ... 222 18.7 394.12 5.21 28.7
6 0.08829 12.5 7.87 0 0.524 ... 311 15.2 395.60 12.43 22.9
7 0.14455 12.5 7.87 0 0.524 ... 311 15.2 396.90 19.15 27.1
8 0.21124 12.5 7.87 0 0.524 ... 311 15.2 386.63 29.93 16.5
9 0.17004 12.5 7.87 0 0.524 ... 311 15.2 386.71 17.10 18.9
10 0.22489 12.5 7.87 0 0.524 ... 311 15.2 392.52 20.45 15.0
11 0.11747 12.5 7.87 0 0.524 ... 311 15.2 396.90 13.27 18.9
12 0.09378 12.5 7.87 0 0.524 ... 311 15.2 390.50 15.71 21.7
13 0.62976 0.0 8.14 0 0.538 ... 307 21.0 396.90 8.26 20.4
14 0.63796 0.0 8.14 0 0.538 ... 307 21.0 380.02 10.26 18.2
15 0.62739 0.0 8.14 0 0.538 ... 307 21.0 395.62 8.47 19.9
16 1.05393 0.0 8.14 0 0.538 ... 307 21.0 386.85 6.58 23.1
17 0.78420 0.0 8.14 0 0.538 ... 307 21.0 386.75 14.67 17.5
18 0.80271 0.0 8.14 0 0.538 ... 307 21.0 288.99 11.69 20.2
19 0.72580 0.0 8.14 0 0.538 ... 307 21.0 390.95 11.28 18.2
20 1.25179 0.0 8.14 0 0.538 ... 307 21.0 376.57 21.02 13.6
21 0.85204 0.0 8.14 0 0.538 ... 307 21.0 392.53 13.83 19.6
22 1.23247 0.0 8.14 0 0.538 ... 307 21.0 396.90 18.72 15.2
23 0.98843 0.0 8.14 0 0.538 ... 307 21.0 394.54 19.88 14.5
24 0.75026 0.0 8.14 0 0.538 ... 307 21.0 394.33 16.30 15.6
25 0.84054 0.0 8.14 0 0.538 ... 307 21.0 303.42 16.51 13.9
26 0.67191 0.0 8.14 0 0.538 ... 307 21.0 376.88 14.81 16.6
27 0.95577 0.0 8.14 0 0.538 ... 307 21.0 306.38 17.28 14.8
28 0.77299 0.0 8.14 0 0.538 ... 307 21.0 387.94 12.80 18.4
29 1.00245 0.0 8.14 0 0.538 ... 307 21.0 380.23 11.98 21.0
接下来看一下数据的描述性统计信息。代码如下:
#pandas 新版本
pd.options.display.precision=1
#pandas老版本
#pd.set_option("precision", 1)
在描述性统计信息中包含数据的最大值、最小值、中位值、四分位值
等,分析这些数据能够加深对数据分布、数据结构等的理解。结果如下
crim zn indus chas ... ptratio b lstat medv
count 5.1e+02 506.0 506.0 5.1e+02 ... 506.0 506.0 506.0 506.0
mean 3.6e+00 11.4 11.1 6.9e-02 ... 18.5 356.7 12.7 22.5
std 8.6e+00 23.3 6.9 2.5e-01 ... 2.2 91.3 7.1 9.2
min 6.3e-03 0.0 0.5 0.0e+00 ... 12.6 0.3 1.7 5.0
25% 8.2e-02 0.0 5.2 0.0e+00 ... 17.4 375.4 6.9 17.0
50% 2.6e-01 0.0 9.7 0.0e+00 ... 19.1 391.4 11.4 21.2
75% 3.7e+00 12.5 18.1 0.0e+00 ... 20.2 396.2 17.0 25.0
max 8.9e+01 100.0 27.7 1.0e+00 ... 22.0 396.9 38.0 50.0
接下来看一下数据特征之间的两两关联关系,这里查看数据的皮尔逊相关系数。代码如下:
crim zn indus chas nox ... tax ptratio b lstat medv
crim 1.00 -0.20 0.41 -5.59e-02 0.42 ... 0.58 0.29 -0.39 0.46 -0.39
zn -0.20 1.00 -0.53 -4.27e-02 -0.52 ... -0.31 -0.39 0.18 -0.41 0.36
indus 0.41 -0.53 1.00 6.29e-02 0.76 ... 0.72 0.38 -0.36 0.60 -0.48
chas -0.06 -0.04 0.06 1.00e+00 0.09 ... -0.04 -0.12 0.05 -0.05 0.18
nox 0.42 -0.52 0.76 9.12e-02 1.00 ... 0.67 0.19 -0.38 0.59 -0.43
rm -0.22 0.31 -0.39 9.13e-02 -0.30 ... -0.29 -0.36 0.13 -0.61 0.70
age 0.35 -0.57 0.64 8.65e-02 0.73 ... 0.51 0.26 -0.27 0.60 -0.38
dis -0.38 0.66 -0.71 -9.92e-02 -0.77 ... -0.53 -0.23 0.29 -0.50 0.25
rad 0.63 -0.31 0.60 -7.37e-03 0.61 ... 0.91 0.46 -0.44 0.49 -0.38
tax 0.58 -0.31 0.72 -3.56e-02 0.67 ... 1.00 0.46 -0.44 0.54 -0.47
ptratio 0.29 -0.39 0.38 -1.22e-01 0.19 ... 0.46 1.00 -0.18 0.37 -0.51
b -0.39 0.18 -0.36 4.88e-02 -0.38 ... -0.44 -0.18 1.00 -0.37 0.33
lstat 0.46 -0.41 0.60 -5.39e-02 0.59 ... 0.54 0.37 -0.37 1.00 -0.74
medv -0.39 0.36 -0.48 1.75e-01 -0.43 ... -0.47 -0.51 0.33 -0.74 1.00[14 rows x 14 columns]
通过上面的结果可以看到,有些特征属性之间具有强关联关系(>0.7或<-0.7),如:
· NOX与INDUS之间的皮尔逊相关系数是0.76。
· DIS与INDUS之间的皮尔逊相关系数是-0.71。
· TAX与INDUS之间的皮尔逊相关系数是0.72。
· AGE与NOX之间的皮尔逊相关系数是0.73。
· DIS与NOX之间的皮尔逊相关系数是-0.77。
4 数据可视化
单一特征图表
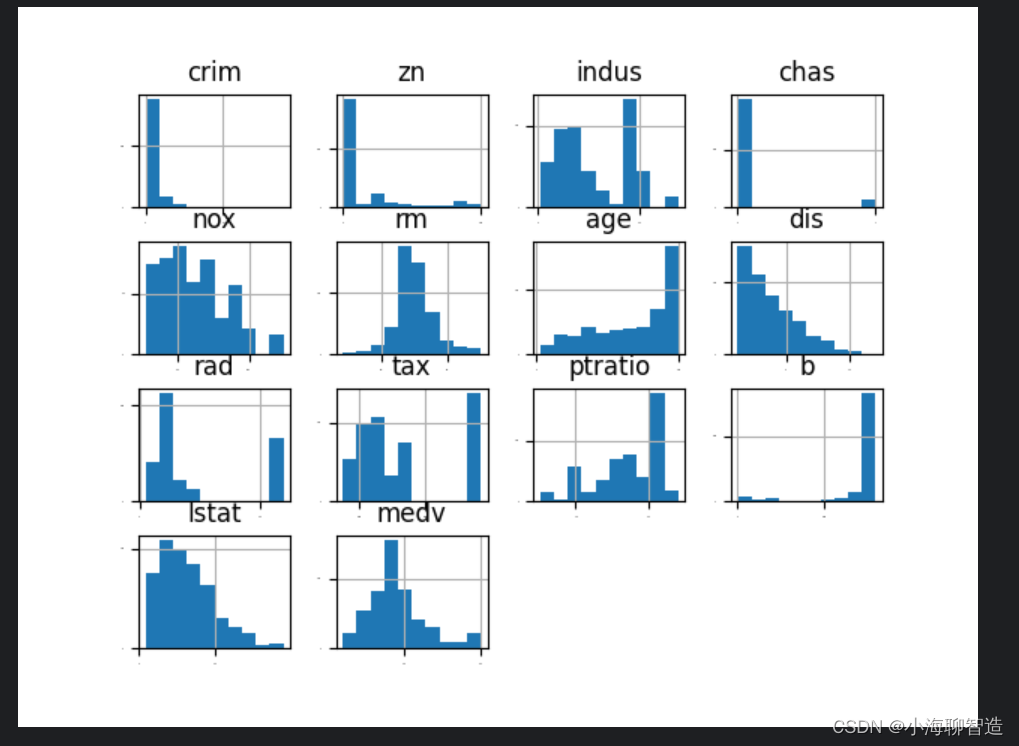
首先查看每一个数据特征单独的分布图,多查看几种不同的图表有助于发现更好的方法。我们可以通过查看各个数据特征的直方图,来感受一下数据的分布情况。代码如下:
data.hist(sharex=False,sharey=False,xlabelsize=1,ylabelsize=1)
pyplot.show()
执行结果如下图所示,从图中可以看到有些数据呈指数分布,如
CRIM、ZN、AGE和B;有些数据特征呈双峰分布,如RAD和TAX。
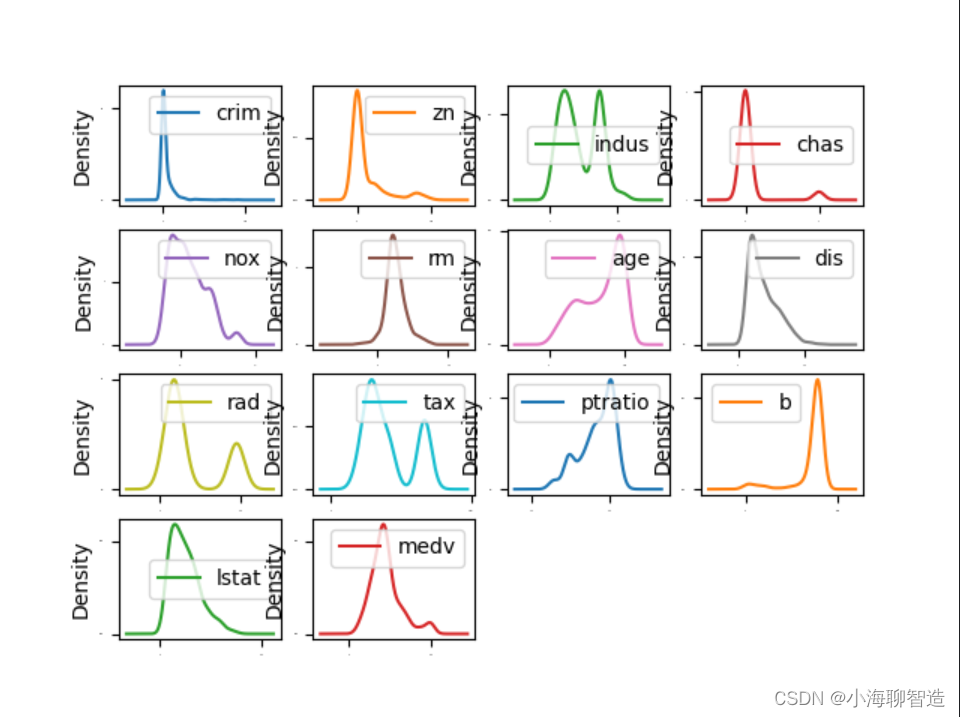
通过密度图可以展示这些数据的特征属性,密度图比直方图更加平滑地展示了这些数据特征。代码如下:
data.plot(kind='density',subplots=True,layout=(4,4),sharex=False,fontsize=1)
pyplot.show()在密度图中,指定layout=(4,4),这说明要画一个四行四列的图
形。执行结果如图所示
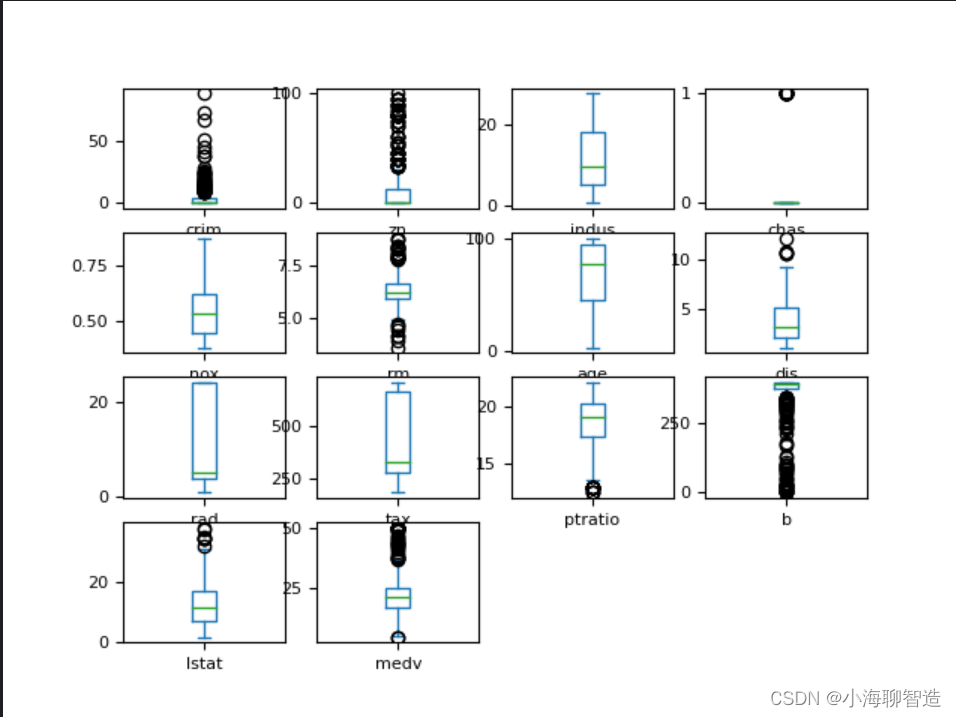
通过箱线图可以查看每一个数据特征的状况,也可以很方便地看出数据分布的偏态程度。代码如下:
data.plot(kind='box',subplots=True,layout=(4,4),sharex=False,fontsize=8)
pyplot.show()
执行结果:
多重数据图表
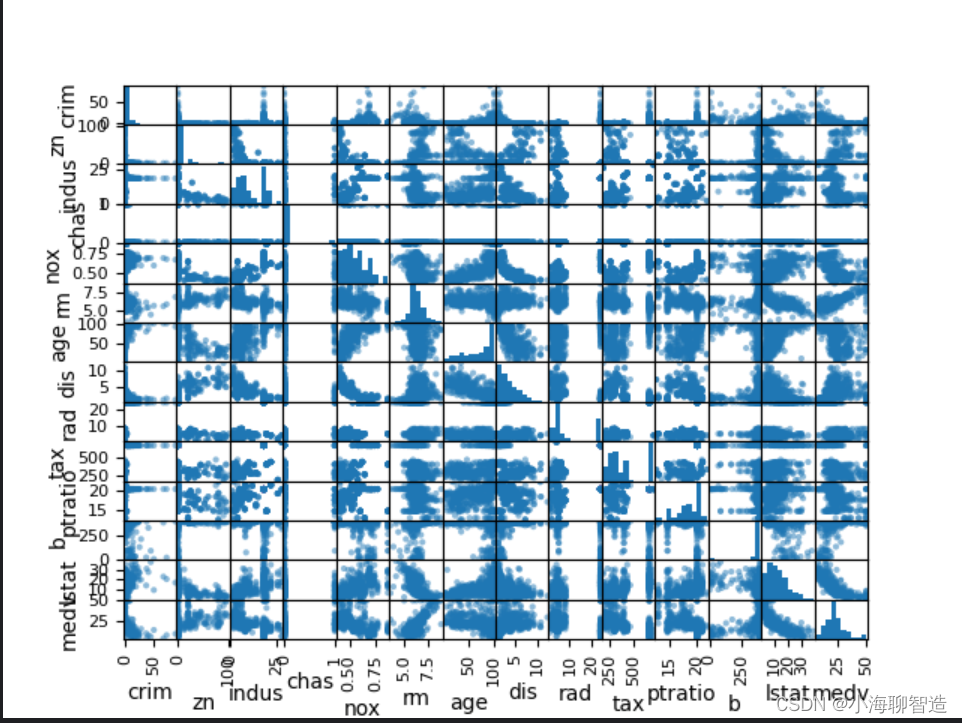
接下来利用多重数据图表来查看不同数据特征之间的相互影响关系。首先看一下散点矩阵图。代码如下:
#散点矩阵图
scatter_matrix(data)
pyplot.show()
通过散点矩阵图可以看到,虽然有些数据特征之间的关联关系很强,但是这些数据分布结构也很好。即使不是线性分布结构,也是可以很方便进行预测的分布结构,执行结果如图所示。
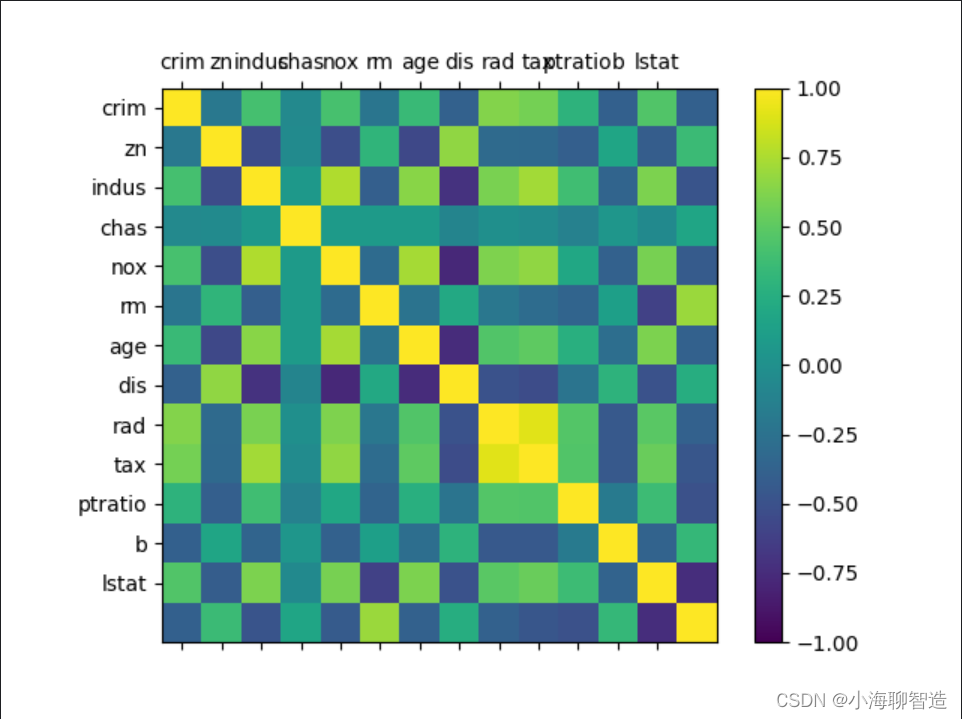
再看一下数据相互影响的相关矩阵图。代码如下:
#相关矩阵图
names = ['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax','ptratio', 'b', 'lstat']
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(data.corr(), vmin =-1,vmax =1, interpolation='none')
fig.colorbar(cax)
ticks = np.arange(0,13,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show()执行结果如图所示,根据图例可以看到,数据特征属性之间的两
两相关性,有些属性之间是强相关的,建议在后续的处理中移除这些特征属性,以提高算法的准确度。
通过数据的相关性和数据的分布等发现,数据集中的数据结构比较复杂,需要考虑对数据进行转换,以提高模型的准确度。可以尝试从以下几个方面对数据进行处理:
· 通过特征选择来减少大部分相关性高的特征。
· 通过标准化数据来降低不同数据度量单位带来的影响。
· 通过正态化数据来降低不同的数据分布结构,以提高算法的准确度。
可以进一步查看数据的可能性分级(离散化),它可以帮助提高决策树算法的准确度。
5.分离评估数据集
分离出一个评估数据集是一个很好的主意,这样可以确保分离出的数据集与训练模型的数据集完全隔离,有助于最终判断和报告模型的准确度。在进行到项目的最后一步处理时,会使用这个评估数据集来确认模型的准确度。这里分离出 20%的数据作为评估数据集,80%的数据作为训练数据集。
代码如下:
#分离数据集,分离出 20%的数据作为评估数据集,80%的数据作为训练数据集
array = data.values
X = array[:, 0:13]
Y = array[:, 13]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)6评估算法
分析完数据不能立刻选择出哪个算法对需要解决的问题最有效。我们直观上认为,由于部分数据的线性分布,线性回归算法和弹性网络回归算法对解决问题可能比较有效。另外,由于数据的离散化,通过决策树算法或支持向量机算法也许可以生成高准确度的模型。
到这里,依然不清楚哪个算法会生成准确度最高的模型,因此需要设计一个评估框架来选择合适的算法。我们采用10折交叉验证来分离数据,通过均方误差来比较算法的准确度。均方误差越趋近于0,算法准确度越高。
代码如下:
seed = 7
num_folds = 10
scoring = 'neg_mean_squared_error'
对原始数据不做任何处理,对算法进行一个评估,形成一个算法的评估基准。这个基准值是对后续算法改善优劣比较的基准值。我们选择三个线性算法和三个非线性算法来进行比较。
线性算法:线性回归(LR)、套索回归(LASSO)和弹性网络回归(EN)。
非线性算法:分类与回归树(CART)、支持向量机(SVM)和K近邻算法(KNN)。
算法模型初始化的代码如下:
#评估算法models = {}models['LR'] = LogisticRegression()
models['LASSO'] = Lasso()
models['EN'] = ElasticNet()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVR()X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)results = []for key in models:kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)result = cross_val_score(models[key], X_train, Y_train.astype('int'), cv=kflod,scoring= scoring)results.append(result)print("%s: %.3f (%.3f)" % (key, result.mean(), result.std()))
从执行结果来看,套索回归(LASSO)具有最优的 MSE,接下来是弹性网络回归(EN))算法。执行结果如下:
LR: -59.150 (17.584)
LASSO: -27.313 (13.573)
EN: -28.251 (13.577)
KNN: -62.158 (28.251)
CART: -31.000 (19.562)
SVM: -68.676 (33.776)
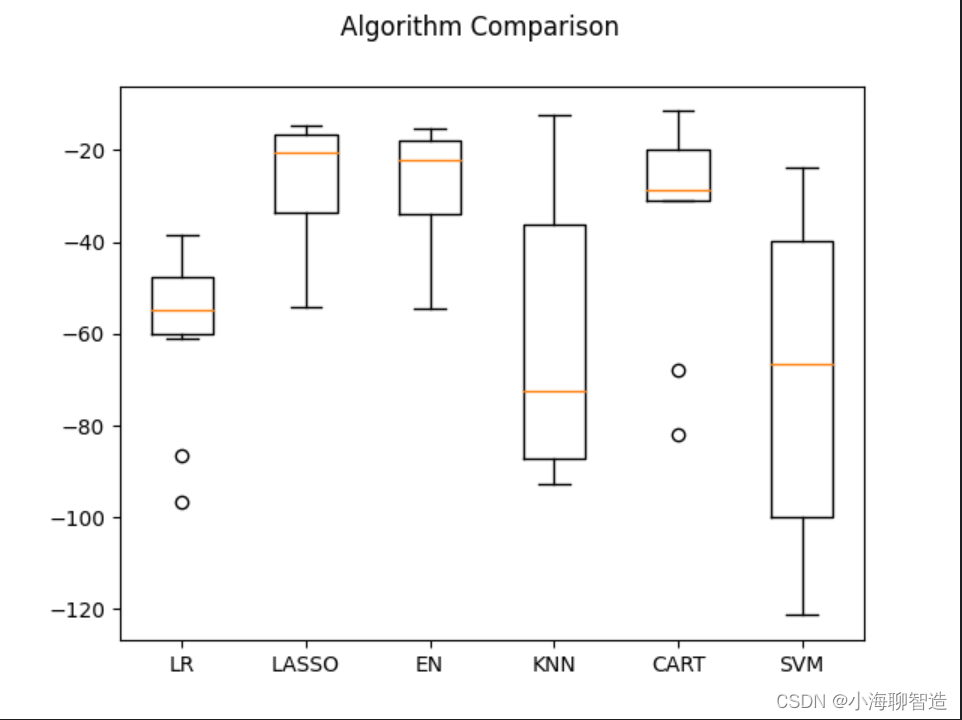
再查看所有的10折交叉分离验证的结果。代码如下:
#评估算法箱线图fig = pyplot.figure()
fig.suptitle("Algorithm Comparison")
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()执行结果如图所示,从图中可以看到,线性算法的分布比较类
似,并且分类与回归树(CART)算法的结果分布非常紧凑。
评估算法——正态化数据
在这里猜测也许因为原始数据中不同特征属性的度量单位不一样,导致有的算法的结果不是很好。接下来通过对数据进行正态化,再次评估这些算法。在这里对训练数据集进行数据转换处理,将所有的数据特征值转化成“0”为中位值、标准差为“1”的数据。对数据正态化时,为了防止数据泄露,采用 Pipeline 来正态化数据和对模型进行评估。为了与前面的结果进行比较,此处采用相同的评估框架来评估算法模型。
代码如下:
#评估算法--正态化数据pipelines ={}pipelines['ScalerLR'] = Pipeline([('Scaler',StandardScaler()),('LR',LinearRegression())])
pipelines['ScalerLASSO'] = Pipeline([('Scaler',StandardScaler()),('LASSO',Lasso())])
pipelines['ScalerEN'] = Pipeline([('Scaler',StandardScaler()),('EN',ElasticNet())])
pipelines['ScalerKNN'] = Pipeline([('Scaler',StandardScaler()),('KNN',KNeighborsRegressor())])pipelines['ScalerCART'] = Pipeline([('Scaler',StandardScaler()),('CART',DecisionTreeRegressor())])
pipelines['ScalerSVM'] = Pipeline([('Scaler',StandardScaler()),('SVM',SVR())])X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)results = []for key in pipelines:kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)cv_result = cross_val_score(pipelines[key], X_train, Y_train, cv=kflod,scoring= scoring)results.append(cv_result)print("%s: %.3f (%.3f)" % (key, cv_result.mean(), cv_result.std()))
执行后发现K近邻算法具有最优的MSE。执行结果如下:
ScalerLR: -22.006 (12.189)
ScalerLASSO: -27.206 (12.124)
ScalerEN: -28.301 (13.609)
ScalerKNN: -21.457 (15.016)
ScalerCART: -27.813 (20.786)
ScalerSVM: -29.570 (18.053)
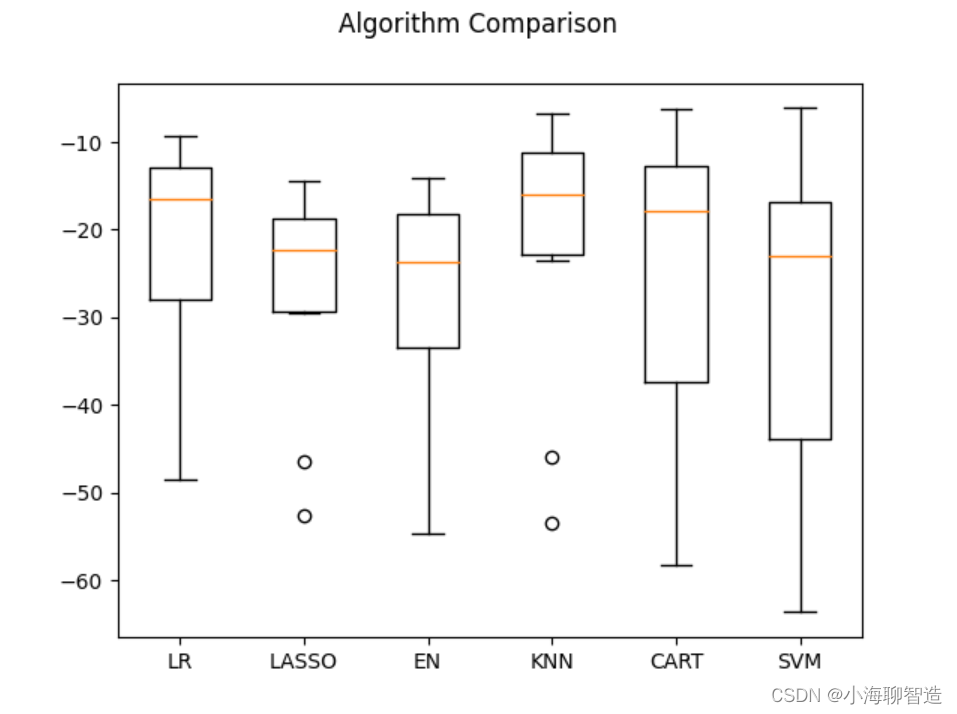
接下来再来看一下所有的10折交叉分离验证的结果。代码如下:
#评估算法箱线图fig = pyplot.figure()
fig.suptitle("Algorithm Comparison")
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
执行结果,生成的箱线图如图所示,可以看到K近邻算法具有最优的MSE和最紧凑的数据分布。
目前来看,K 近邻算法对做过数据转换的数据集有很好的结果,但是是否可以进一步对结果做一些优化呢?
K近邻算法的默认参数近邻个数(n_neighbors)是5,下面通过网格搜索算法来优化参数。代码如下:
#调参改善算法-knn
scaler = StandardScaler().fit(X_train) # fit生成规则
#scaler = StandardScaler.fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid ={'n_neighbors':[1,3,5,7,9,11,13,15,19,21]}
model = KNeighborsRegressor()kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)
grid = GridSearchCV(estimator =model,param_grid=param_grid,scoring=scoring,cv = kflod)grid_result = grid.fit(X=rescaledX,y = Y_train)print('最优:%s 使用%s'%(grid_result.best_score_,grid_result.best_params_))cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['params'])for mean,param in cv_results:print(mean,param)
最优结果——K近邻算法的默认参数近邻个数(n_neighbors)是1。执
行结果如下:
最优:-19.497828658536584 使用{'n_neighbors': 1}
-19.497828658536584 {'n_neighbors': 1}
-19.97798367208672 {'n_neighbors': 3}
-21.270966658536583 {'n_neighbors': 5}
-21.577291737182684 {'n_neighbors': 7}
-21.00107515055706 {'n_neighbors': 9}
-21.490306228582945 {'n_neighbors': 11}
-21.26853270313177 {'n_neighbors': 13}
-21.96809222222222 {'n_neighbors': 15}
-23.506900689142622 {'n_neighbors': 19}
-24.240302870416464 {'n_neighbors': 21}
确定最终模型
我们已经确定了使用极端随机树(ET)算法来生成模型,下面就对该算法进行训练和生成模型,并计算模型的准确度。代码如下:
#训练模型caler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
gbr = ExtraTreeRegressor()
gbr.fit(X=rescaledX,y=Y_train)
#评估算法模型rescaledX_validation = scaler.transform(X_validation)
predictions = gbr.predict(rescaledX_validation)
print(mean_squared_error(Y_validation,predictions))
执行结果如下:
14.392352941176469
本项目实例从问题定义开始,直到最后的模型生成为止,完成了一个完整的机器学习项目。通过这个项目,理解了上一节中介绍的机器学习项目的模板,以及整个机器学习模型建立的流程。



![[贪心] 拼接最小数](https://img-blog.csdnimg.cn/ab666d684033472b9bd64d2d5ef84bf1.png)