目录
1、概念
2、数据集介绍与划分
2.1、数据集的划分
2.2、sklearn数据集介绍
2.2.1、API
2.2.2、分类和回归数据集
分类数据集
回归数据集
返回类型
3、sklearn转换器和估计器
3.1、转换器
三种方法的区别
3.2、估计器
3.2.1、简介
3.2.2、API
3.3、工作流程
1、概念
整个系列中总共需要掌握的内容:
知道数据集的分为训练集和测试集
知道sklearn的转换器和估计器流程
了解sklearn的分类、回归数据集
说明K-近邻算法的距离公式
说明K-近邻算法的超参数K值以及取值问题
说明K-近邻算法的优缺点
应用KNeighborsClassifier实现分类
了解分类算法的评估标准准确率
说明朴素贝叶斯算法的原理
说明朴素贝叶斯算法的优缺点
应用MultinomialNB实现文本分类
应用模型选择与调优
说明决策树算法的原理
说明决策树算法的优缺点
应用DecisionTreeClassifier实现分类
说明随机森林算法的原理
说明随机森林算法的优缺点
应用RandomForestClassifier实现分类当谈到机器学习的分类算法时,我们通常可以将其分为以下几个主要类别:监督学习、无监督学习、半监督学习和强化学习。每个类别都有其独特的特点和适用场景。
1、监督学习(Supervised Learning): 在监督学习中,模型从有标签的训练数据中学习,目标是根据输入特征预测输出标签。最常见的监督学习算法包括:
- 回归(Regression):用于预测连续值输出,例如线性回归、岭回归、Lasso回归等。
- 分类(Classification):用于预测离散类别输出,例如逻辑回归、决策树、支持向量机、随机森林等。
2、无监督学习(Unsupervised Learning): 在无监督学习中,模型从无标签的数据中寻找模式和结构,帮助我们理解数据的内在关系。常见的无监督学习算法包括:
- 聚类(Clustering):将数据分成组别,例如K均值聚类、层次聚类。
- 降维(Dimensionality Reduction):将高维数据映射到低维空间,例如主成分分析(PCA)、独立成分分析(ICA)。
3、半监督学习(Semi-Supervised Learning): 半监督学习结合了监督学习和无监督学习,使用有标签和无标签数据来训练模型。这对于数据标注困难的情况下可能很有用。
4、强化学习(Reinforcement Learning): 强化学习是让模型通过与环境的互动来学习,以最大化累积奖励。它适用于需要做出一系列决策的问题。主要包括智能体、环境、行动和奖励信号。
2、数据集介绍与划分
学习目标
目标
知道数据集的分为训练集和测试集
知道sklearn的分类、回归数据集
拿到的数据是否全部都用来训练一个模型?
2.1、数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
API:
sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return ,测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
结合后面的数据集作介绍
2.2、sklearn数据集介绍
2.2.1、API
sklearn.datasets:
- 加载获取流行数据集
- datasets.load_*()
-
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
-
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
2.2.2、分类和回归数据集
分类数据集
sklearn.datasets.load_iris():加载并返回鸢尾花数据集

sklearn.datasets.load_digits():加载并返回数字数据集

sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset: 'train'或者'test','all',可选,选择要加载的数据集。
训练集的“训练”,测试集的“测试”,两者的“全部”
回归数据集
sklearn.datasets.load_boston():加载并返回波士顿房价数据集
sklearn.datasets.load_diabetes():加载并返回糖尿病数据集

返回类型
load和fetch返回的数据类型datasets.base.Bunch(字典格式):
- data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
3、sklearn转换器和估计器
3.1、转换器
想一下之前做的特征工程的步骤?
- 实例化 (实例化的是一个转换器类(Transformer))
- 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式
- fit_transform
- fit
- transform
这几个方法之间的区别是什么呢?

三种方法的区别
StandardScaler是scikit-learn库中用于数据标准化的类。它有三个主要方法:fit、transform和fit_transform。这些方法的区别如下:
1、fit方法:
- fit方法用于计算数据的均值(mean)和标准差(standard deviation)。
- 当调用fit方法时,StandardScaler会分析数据,计算每个特征的均值和标准差,并将这些值存储在StandardScaler对象的内部状态中。
- 这个方法通常在训练数据上调用一次,以计算出用于标准化的参数。
- 示例:std_scaler.fit(X_train),其中X_train是训练数据。
2、transform方法:
- transform方法用于应用先前计算得到的均值和标准差对数据进行标准化。
- 当调用transform方法时,StandardScaler将使用存储在对象内部的均值和标准差,对传入的数据进行标准化操作。
- 这个方法通常在训练数据和测试数据上分别调用,以保证数据集在相同的标准化范围内。
- 示例:X_train_scaled = std_scaler.transform(X_train)。
3、fit_transform方法:
- fit_transform方法是一个组合方法,等效于先调用fit再调用transform。
- 它在数据上执行计算均值和标准差的操作,然后使用这些计算结果对数据进行标准化。
- 这个方法通常在训练数据上调用一次,以获取均值和标准差,并将训练数据标准化后的结果返回。
- 示例:X_train_scaled = std_scaler.fit_transform(X_train)。
通常情况下,fit方法应该在训练数据上调用一次,然后使用transform方法对训练数据和测试数据进行标准化。fit_transform方法在训练数据上调用一次即可。这样可以确保使用相同的均值和标准差来对所有数据进行标准化,避免了数据泄露和不一致性。
fit_transform的作用相当于transform加上fit。但是为什么还要提供单独的fit呢
虽然fit_transform的作用在很多情况下与分别调用fit和transform相同,但是提供独立的fit方法的原因在于灵活性和适用性。
以下是为什么提供单独的fit方法的一些原因:
- 分步骤操作:有时候你可能需要在进行标准化之前先检查计算得到的均值和标准差。独立的fit方法允许你在进行标准化之前查看这些参数,以便更好地理解数据。
- 跨数据集使用:在实际情况中,你可能会在多个不同的数据集上使用相同的标准化参数。例如,如果你训练了一个模型并将其保存下来,然后在生产环境中使用,你可能会希望使用与训练数据相同的标准化参数。单独的fit方法允许你将标准化参数存储下来,并在不同的数据集上重复使用。
- 控制标准化参数:有时候,你可能希望手动调整标准化的参数,例如通过添加一个偏移或缩放因子。使用独立的fit方法允许你在标准化之前对参数进行调整。
- 定制化处理:独立的fit方法为开发者提供了更大的自由度,可以根据具体需求进行定制化的处理。
虽然在大多数情况下,fit_transform会更方便,但是独立的fit方法确保了库的灵活性和适应性,使其能够应对更广泛的使用情况。这种设计哲学允许开发者根据需求选择适当的方法来达到最佳效果。
3.2、估计器
3.2.1、简介
"估计器"(Estimator)是scikit-learn中一个重要的概念,它是一种用于机器学习模型的通用接口。估计器的目标是封装模型的训练和预测过程,使其能够统一地使用相似的方法,无论是分类、回归还是其他类型的任务。
估计器在scikit-learn中有两个基本的角色:
- Transformer(转换器):转换器是一种估计器,它可以从输入数据中计算特征、过滤或转换数据。例如,StandardScaler就是一个转换器,可以将数据标准化。转换器通常有fit方法用于学习变换所需的参数,以及transform方法用于应用学习到的变换。
- Predictor(预测器):预测器是一种估计器,它可以根据输入数据进行预测。例如,线性回归模型就是一个预测器,它可以根据输入特征预测目标变量。预测器通常有fit方法用于训练模型,以及predict方法用于进行预测。
使用估计器的一般步骤包括:
- 创建估计器对象:通过实例化一个估计器类,例如LinearRegression()或RandomForestClassifier()。
- 使用fit方法:使用训练数据调用fit方法来训练模型(对于预测器)或计算变换参数(对于转换器)。
- 使用估计器对象:根据需要使用估计器的其他方法,例如predict(对于预测器)或transform(对于转换器)来进行预测或转换。
- 评估和优化:根据模型表现进行评估,可能需要调整模型参数以优化性能。
这种统一的接口使得在scikit-learn中可以轻松地切换不同的估计器,并将其组合在一起以构建复杂的机器学习流水线。同时,它也有助于保持代码的整洁和一致性,使得不同算法的比较和实验更加便捷。
3.2.2、API
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
1、用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
2、用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
3、用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
3.3、工作流程
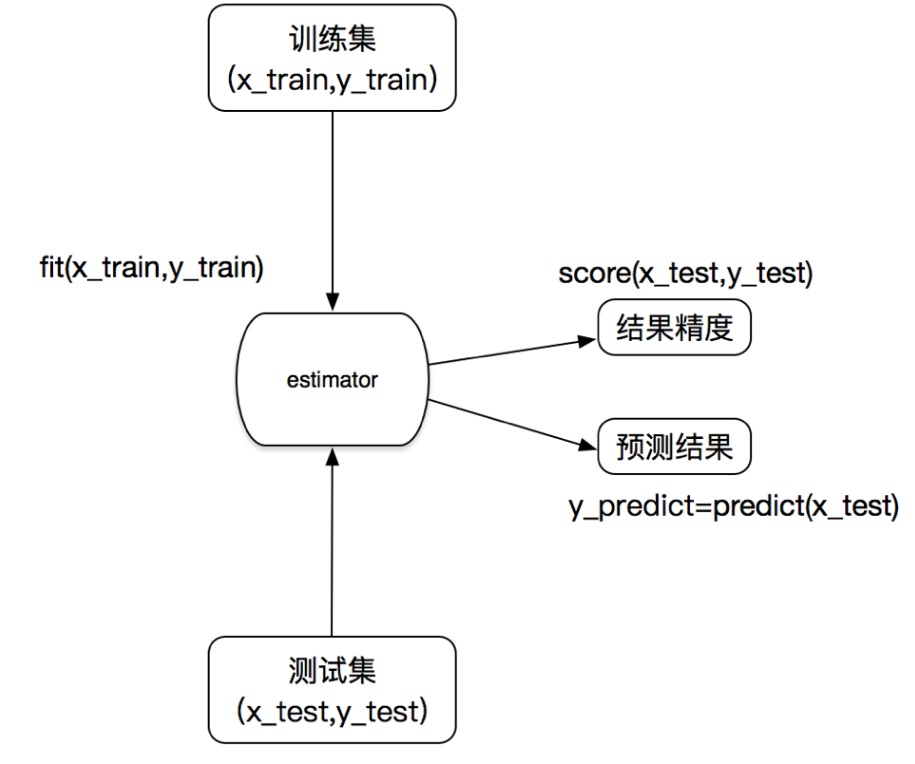
估计器(Estimator)在scikit-learn中是一个统一的接口,用于训练模型和进行预测。以下是估计器的基本工作流程:
- 选择估计器类: 首先,根据你的任务选择合适的估计器类。估计器类的选择取决于你要解决的问题,例如分类、回归、聚类等。你可以从scikit-learn的估计器列表中选择一个适合的类,例如LinearRegression、RandomForestClassifier等。
- 实例化估计器对象: 通过实例化选定的估计器类,创建一个估计器对象。这个对象将包含模型的参数和方法。
- 拟合(训练)模型: 对于预测器类(Predictor),使用训练数据调用估计器对象的fit方法,将模型适应到训练数据。这个过程涉及学习模型的参数,以使其能够在输入特征上预测目标值。
- 进行预测: 对于已经训练好的预测器,你可以使用predict方法来进行预测。将输入特征传递给predict方法,它会返回模型对这些特征的预测值。
- 转换数据(对于转换器类): 对于转换器类(Transformer),使用训练数据调用估计器对象的fit方法,学习需要用于数据转换的参数。然后,使用transform方法对新的数据进行转换,以应用已学习的转换规则。
- 评估和调整: 通过评估模型在测试数据上的性能,来衡量模型的质量。你可以使用各种评估指标,如准确率、均方误差等。如果需要,你可以调整估计器的参数,以优化模型的性能。
总结起来,估计器的工作流程涉及选择合适的类、实例化估计器对象、拟合(训练)模型、进行预测或转换数据,以及根据评估结果进行调整。这种统一的接口使得在scikit-learn中可以方便地使用不同的估计器,构建复杂的机器学习流水线,并进行模型选择和性能优化。