linux 出现内存一致性的场景
1、编译器优化 ,代码上下没有关联的时候,因为编译优化,会有执行执行顺序不一致的问题(多核单核都会出现)
2、多核cpu乱序执行,cpu的乱序执行导致内存不一致(多核出现)
3、dma 操作,dma操作外设,或者内存数据,cpu无法感知,仍然使用cache 数据,导致内存不一致(多核单核都会出现)
内存屏障
cpu 乱序导致的问题
如果CPU需要读取的地址中的数据已经已经缓存在了cache line中,即使是cpu需要对这个地址重复进行读写,对CPU性能影响也不大,但是一旦发生了cache miss(对这个地址进行第一次写操作),如果是有序处理器,CPU在从其他CPU获取数据或者直接与主存进行数据交互的时候需要等待不可用的操作对象,这样就会非常慢,非常影响性能。举个例子:
如果CPU0发起一次对某个地址的写操作,但是其local cache中没有数据,这个数据存放在CPU1的local cache中。为了完成这次操作,CPU0会发出一个invalidate的信号,使其他CPU的cache数据无效(因为CPU0需要重新写这个地址中的值,说明这个地址中的值将被改变,如果不把其他CPU中存放的该地址的值无效,那么就有可能会出现数据不一致的问题)。只有当其他之前就已经存放了改地址数据的CPU中的值都无效了后,CPU0才能真正发起写操作。需要等待非常长的时间,这就导致了性能上的损耗。
但是乱序处理器山就不需要等待不可用的操作对象,直接把invalidate message放到invalidate queues中,然后继续干其他事情,提高了CPU的性能,但也带来了一个问题,就是程序执行过程中,可能会由于乱序处理器的处理方式导致内存乱序,程序运行结果不符合我们预期的问题。
解决的办法-内存屏障
CPU内存屏障,指令
1、通用barrier,保证读写操作有序, mb()和smp_mb()
2、写操作barrier,仅保证写操作有序,wmb()和smp_wmb()
3、读操作barrier,仅保证读操作有序,rmb()和smp_rmb()
编译器重排导致的问题
int flag, data;void write_data(int value)
{data = value;flag = 1;
}void read_data(void)
{int res;while (flag == 0);res = data;flag = 0;return res;
}
我们拥有2个线程,一个用来更新数据,也就是更新data的值。使用flag标志data数据已经准备就绪,其他线程可以读取。另一个线程一直调用read_data(),等待flag被置位,然后返回读取的数据data。
如果compiler产生的汇编代码是flag比data先写入内存。那么,即使是单核系统上,我们也会有问题。在flag置1之后,data写45之前,系统发生抢占。另一个进程发现flag已经置1,认为data的数据已经准别就绪。但是实际上读取data的值并不是45(可能是上次的历史数据或者非法数据)。为什么compiler还会这么操作呢?因为,compiler是不知道data和flag之间有严格的依赖关系。这种逻辑关系是我们人为强加的
解决的办法-显式编译屏障
#define barrier() __asm__ __volatile__("": : :"memory")int a, b;void foo(void)
{a = b + 1;barrier();b = 0;
}
barrier()就是compiler提供的屏障,作用是告诉compiler内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,barrier()之后的内存操作需要重新从内存load,而不能使用之前寄存器缓存的值。并且可以防止compiler优化barrier()前后的内存访问顺序。barrier()就像是代码中的一道不可逾越的屏障
对于单个变量可以使用 volatile 或者是指针变量
dma 内存不一致
那DMA为什么和CPU的cache会产生cache一致性的问题呢,基本的原因的什么呢?我这里总结了几个。
1、DMA直接操作系统总线来读写内存地址,而CPU并不感知。
2、如果DMA修改的内存地址,在CPU的cache中有缓存,那么CPU并不知道内存数据被修改了,CPU依然去访问cache的旧数据,导致Cache一致性问题。
dam cache 一致性解决方法
1、使用硬件cache一致性的方案,需要CCI这种IP的支持。这个需要去查看一下你用的soc是否支持CCI控制器。
2、使用non-cacheable的内存来进行DMA传输,这种方案最简单,但效率最低,严重降低性能,还增加功耗。
3、使用软件主动干预的方法来帮助cache一致性。这个是比较常规的方法,特别是在类似CCI这种缓存一致性控制器没有出来之前,都用这种方式。对于DMA的操作,我们需要考虑两种情况。
软件干预dma 操作
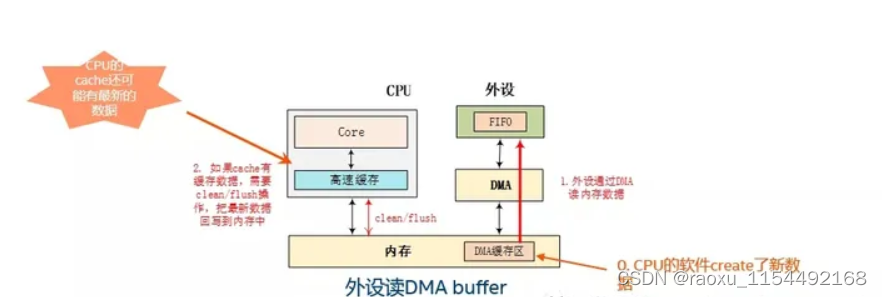 理解这里为什么要先做cache的clean或者flush操作的一个关键点是:比如这个图里,大家要想清楚,在DMA开始传输之前,最新的数据在哪里?很明显,在这个图里,在这个场景下的逻辑,最新数据有可能还在cache里,因为主机的软件产生数据,比如网卡发包,CPU的网络软件去组包,这个组包的过程,其实可以看成是CPU去create了新的数据,然后CPU把数据存在内存的DMA buffer里,这个过程中,有可能还有新的数据在CPU的cache里。所以,在启动DMA之前,我们需要调用cache的flush操作,把cache的数据回写到DMA buffer里。这个就是这个逻辑。
理解这里为什么要先做cache的clean或者flush操作的一个关键点是:比如这个图里,大家要想清楚,在DMA开始传输之前,最新的数据在哪里?很明显,在这个图里,在这个场景下的逻辑,最新数据有可能还在cache里,因为主机的软件产生数据,比如网卡发包,CPU的网络软件去组包,这个组包的过程,其实可以看成是CPU去create了新的数据,然后CPU把数据存在内存的DMA buffer里,这个过程中,有可能还有新的数据在CPU的cache里。所以,在启动DMA之前,我们需要调用cache的flush操作,把cache的数据回写到DMA buffer里。这个就是这个逻辑。
1、 在DMA拷贝前,进行一次CACHE CLEAN,将cache内容dirty回写,清除cache,保证在DMA传输时间内不会有回写动作,(也叫做写回(Writeback):DMA从内存中读取数据时,先强制将Cache中的内容写回到内存中)
2、 在DMA拷贝完成之后,进行一次CACHE FLUSH,保证CPU访问目的地址时cache会重新构建,目的地址的值一定是从DDR上读取最新数据。(也叫做写无效(Invalidate):DMA向内存中写入数据完成后,直接令Cache中的内容无效。这样CPU在读取Cache时必然要先从内存中读取数据到Cache)
一些嵌入式平台可能包括两级Cache,称为Inner Cache和Outer Cache。前者是内部Cache,位于CPU内部,也称为一级Cache或L1 Cache;后者是外部Cache,位于CPU外部,也称为二级Cache或L2 Cache。
几个常见的嵌入式平台如ARM、MIPS、PPC都采用软件管理Cache,提供相应的接口来管理Cache,但需要我们编写代码主动操作Cache。以ARM平台为例,Linux对DMA的数据一致性操作函数为dmac_flush_range()函数和outer_flush_range()函数,两个函数都同时进行了写无效操作和写回操作确保数据一致性。
1、针对Inner Cache。
extern void dmac_flush_range(const void *, const void *);
2、针对Outer Cache。
static inline void outer_flush_range(phys_addr_t start, phys_addr_t end)
参考网址:
https://blog.csdn.net/baidu_38797690/article/details/123234019
https://zhuanlan.zhihu.com/p/465411610
https://www.cnblogs.com/jerry116/articles/9206061.html
https://zhuanlan.zhihu.com/p/505956490?utm_id=0