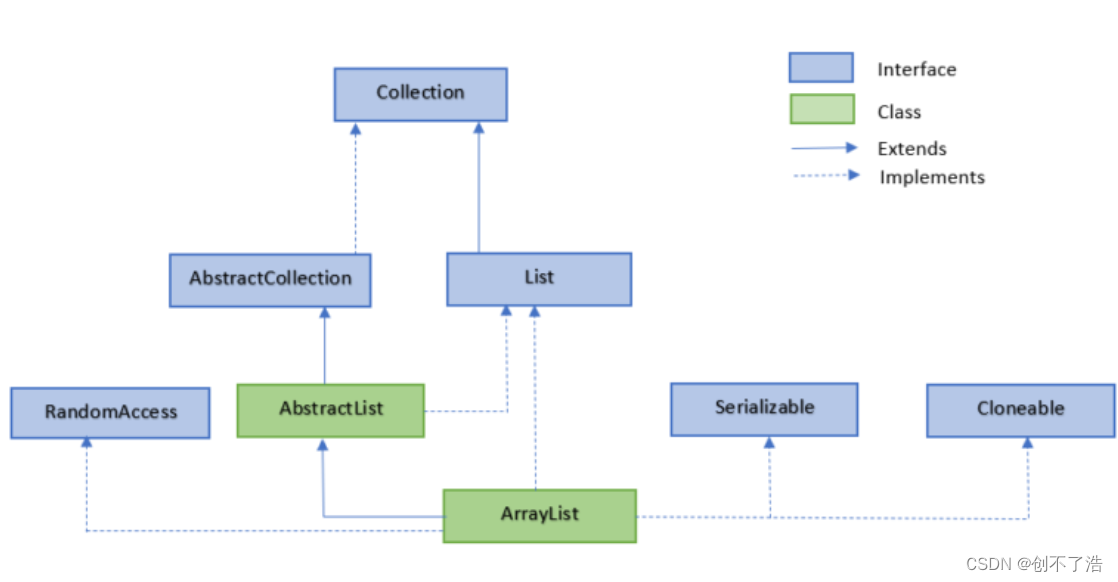
文章目录
- 1.1 机器学习概念
- 1.1.1 定义
- 统计机器学习与数据挖掘区别
- 机器学习前提
- 1.1.2 术语
- 1.1.3 特点
- 以数据为研究对象
- 目标
- 方法——基于数据构建模型
- SML三要素
- SML步骤
- 1.2 分类
- 1.2.1 参数化/非参数化方法
- 1.2.2 按算法分类
- 1.2.3 按模型分类
- 概率模型
- 非概率模型
- 逻辑斯蒂回归
- 1.2.4 基本分类
- 监督学习
- 分类
- 符号表示
- 形式化
- 特征
- 无监督模型
- 特征
- 符号表示
- 形式化
- 强化学习
- 半监督学习
- 主动学习
- 1.2.5 按技巧分类
- 贝叶斯方法
- 特点
- 步骤
- 核方法
- 1.3 统计学习三要素
- 1.3.1 模型
- 1.3.2 策略
- 常用损失函数
- 风险函数(期望损失)
- 经验函数(平均损失)
- 经验风险最小化和结构风险最小化
- 1.3.3 算法
- 1.4 模型评估与选择
- 1.4.1 误差
- 模型复杂度与测试误差
- 理想模型
- 1.4.2 欠拟合
- 1.4.3 过拟合
- 避免过拟合
- 正则化
- 正则化为什么防止过拟合
- 1.4.4 泛化能力
- 泛化误差上界
- 交叉验证
- 1.4.5 参数取值
- 1.4.6 维数诅咒
- 1.5 监督学习
- 1.5.1 学习方法
- 生成方法
- 判别方法
- 1.5.2 模型
- 生成模型
- 判别模型
- 1.5.3 监督学习应用
- 分类问题
- 二分类问题
- 标注问题
- 回归问题
- 1.6 频率派与贝叶斯派
- 1.6.1 频率派
- 1.6.2 贝叶斯派
- 1.6.3 区别
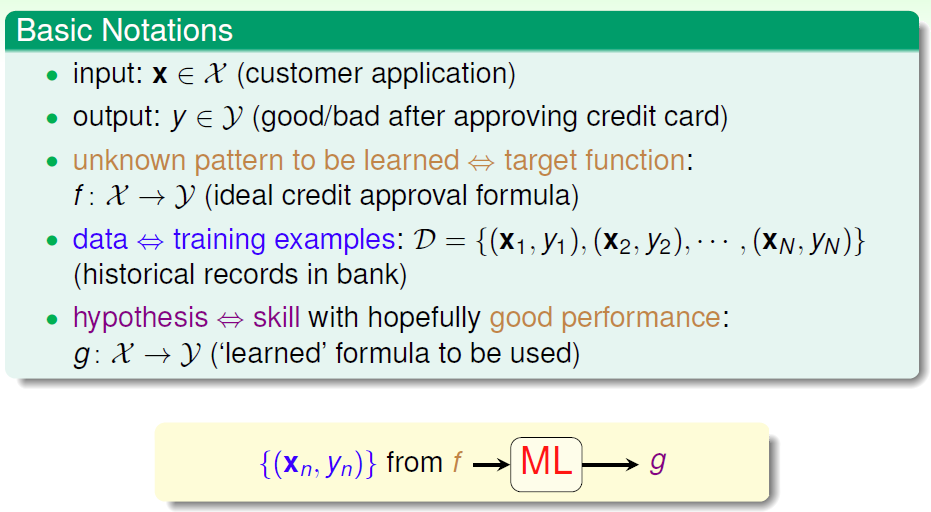
机器学习是计算机基于数据构建概率统计模型并运用模型对数据进行预测和分析的学科
根据输入输出类型的不同,机器学习分为:分类问题,回归问题,标注问题三类
过拟合是机器学习中不可避免的,可通过选择合适的模型降低影响
监督学习是机器学习的主流任务,包括生成方法和判别方法两类
1.1 机器学习概念
1.1.1 定义
人类学习机制:从大量现象中提取反复出现的规律与模式
A computer sprogram is said to learn from E with respect to some class of tasks T and performance measure P ,if its performance at tasks T as measured by P improves with experience E.
形式化角度:如果算法利用某些经验,使自身在特定任务类上的性能得到改善,则认为该算法实现了人工智能
机器角度:计算机系统通过运用数据及统计方法提高系统性能
方法论角度:机器学习是 计算机基于数据构建概率统计模型,并 运用该模型对数据进行预测与分析 的学科
- 所有模型都是错的,但有一些是有用的
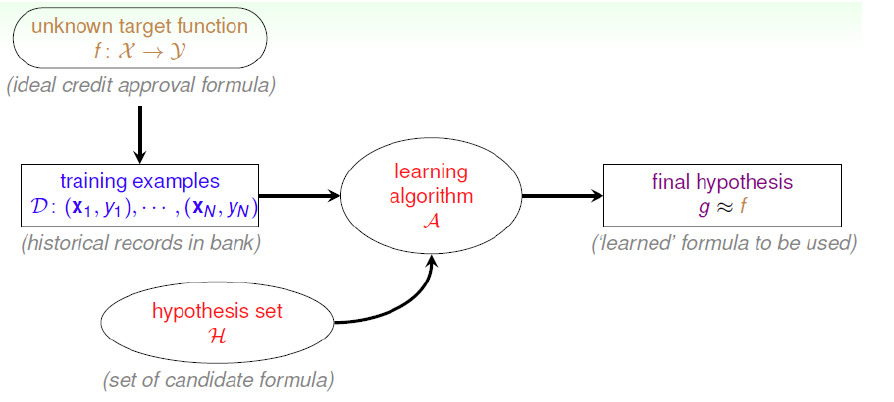
Learning algorithm运用数据计算想假设空间 H \mathcal{H} H 中的 g g g 用以近似 f f f
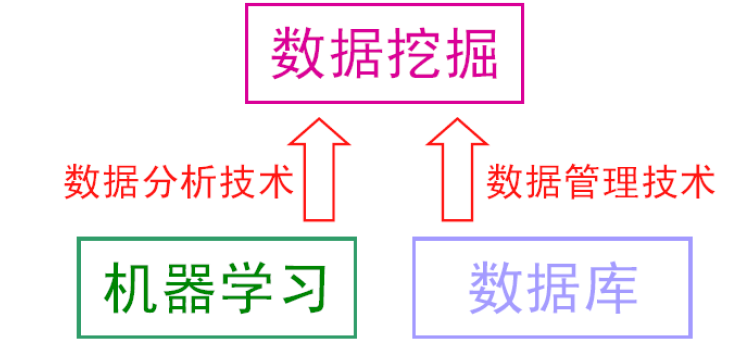
统计机器学习与数据挖掘区别
数据挖掘:运用机器学习的数据分析方法来分析海量数据,由数据库提供的技术管理海量数据
机器学习前提
可判别任务 T T T 是否使用 M L ML ML
存在需学习的模型
没有明确可定义的规则
有某种形式的数据供学习
1.1.2 术语
数据(实例):对对象某些性质的描述,不同的属性值有序排列得到的向量
- 属性:被描述的性质
- 属性值:属性的取值
不同的属性之间视为相互独立,每个属性都代表了不同的维度,这些属性共同张成了 特征空间
每个实例(数据)都可以看做特征空间中的一个向量—— 特征向量
1.1.3 特点
- 以计算机及网络为平台
- 以数据为研究对象
- 目的是对数据进行分析和预测
- 以方法为中心:基于数据构建模型
- 交叉学科
以数据为研究对象
提取数据特征,抽象为模型。利用模型对未知数据进行分析预测
前提:同类数据有一定统计规律,可以用概率统计的方法处理
随机变量 数据特征 概率分布 数据的统计规律 变量 / 变量组 一个数据点 \begin{array}{c|c} \hline 随机变量&数据特征\\ 概率分布&数据的统计规律\\ 变量/变量组&一个数据点\\ \hline \end{array} 随机变量概率分布变量/变量组数据特征数据的统计规律一个数据点
目标
机器学习目标:根据已有的训练数据推导出所有数据的模型,并根据得出的模型实现对未知测试数据的最优预测
总目标:学习什么样的模型,如何构建模型
方法——基于数据构建模型
从给定的、有限的、用于学习的训练数据集(Training data)出发,且训练集中的数据具有一定的统计特性,可以视为满足 独立同分布 的样本。
假设待学习的模型属于某个函数集合——假设空间(Hypothesis space)
应用某个评价准则(Evaluation criterion)——风险最小
通过算法(Algorithm)选取一个最优化模型
使它在已知的训练集和测试集上在给定的评价标准下有最优预测
SML三要素
模型Model:from Hypothesis space
策略Strategy:evaluation criterion
算法Algorithm:调参过程
SML步骤
- 得到有限的训练数据集合
- 确定学习模型的集合——Model
- 确定模型选择的准则(评价准则)——Strategy 风险
- 实现最优模型求解算法——Algorithm 最优化理论
- 运行算法 ⇒ \Rightarrow ⇒ 最优化模型
- 预测新数据,分析
eg
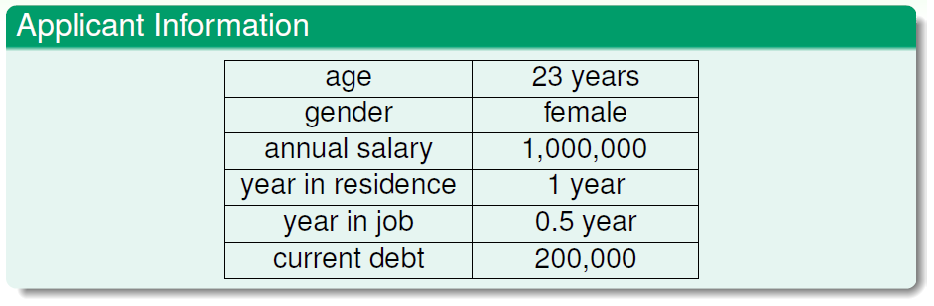
需要学习的未知潜藏模式:批准信用卡是否对银行有利(good/bad)
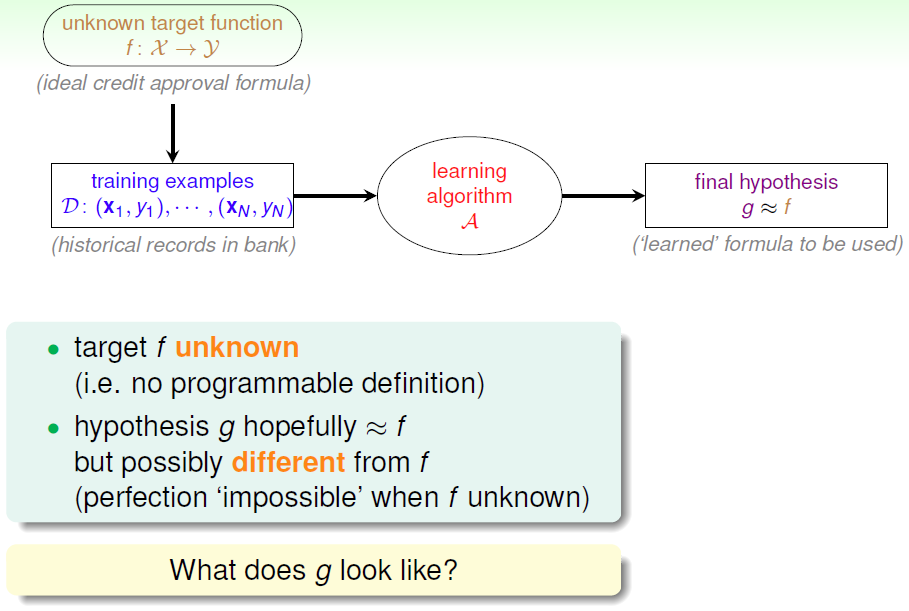
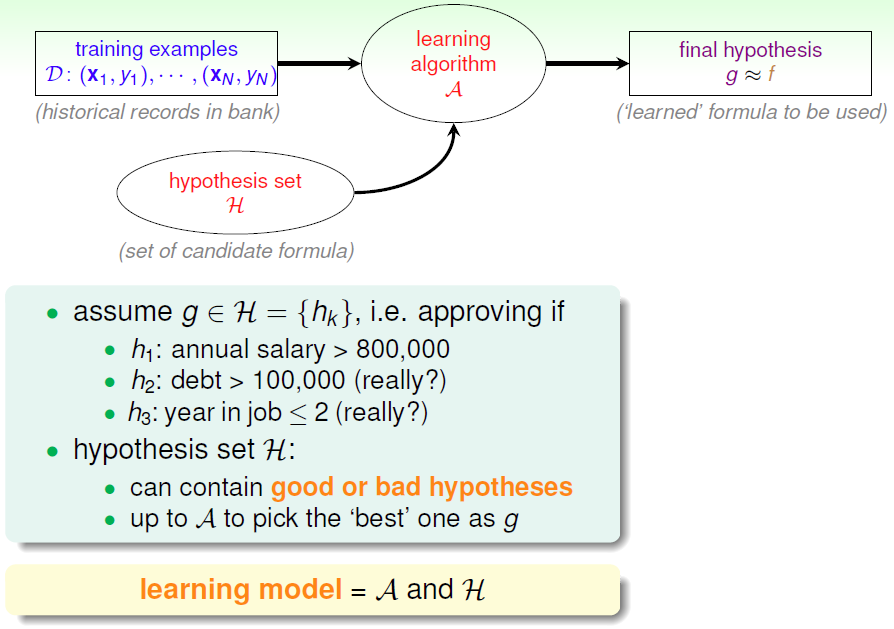
1.2 分类
基本分类 { 监督学习 s u p e r v i s e d l e a r n i n g 无监督学习 u n s u p e r v i s e d l e a r n i n g 半监督学习 s e m i − s u p e r v i s e d l e a r n i n g 强化学习 r e i n f o r c e d l e a r n i n g 主动学习 按模型分类 { { 概率模型 p r o b a b i l i s t i c m o d e l 非概率模型 n o n − p r o b a b i l i s t i c m o d e l { 线性模型 l i n e r m o d e l 非线性模型 n o n − l i n e r m o d e l { 参数化方法 p a r a m e t e r i c m o d e l 非参数化方法 n o n − p a r a m e t e r i c m o d e l 按技巧分类 { 贝叶斯 : 贝叶斯定理 B a y e s i a n l e a r n i n g 核方法 : 核函数 k e r n e l m e t h o d 按算法分类 { 在线学习 o n l i n e l e a r n i n g 批量学习 b a t c h l e a r n i n g 基本分类\left\{ \begin{aligned} &监督学习supervised\quad learning\\ &无监督学习unsupervised\quad learning\\ &半监督学习semi-supervised\quad learning\\ &强化学习reinforced\quad learning\\ &主动学习\\ \end{aligned} \right.\\按模型分类\begin{cases} \begin{cases} 概率模型probabilistic\quad model\\ 非概率模型non-probabilistic\quad model\begin{cases} 线性模型 liner\quad model\\ 非线性模型non-liner\quad model \end{cases} \end{cases}\\ \begin{cases} 参数化方法parameteric\quad model\\ 非参数化方法non-parameteric\quad model \end{cases} \end{cases}\\ 按技巧分类\begin{cases} 贝叶斯:贝叶斯定理Bayesian \quad learning\\ 核方法:核函数kernel\quad method \end{cases}\qquad 按算法分类\begin{cases} 在线学习online\quad learning\\ 批量学习batch\quad learning \end{cases} 基本分类⎩ ⎨ ⎧监督学习supervisedlearning无监督学习unsupervisedlearning半监督学习semi−supervisedlearning强化学习reinforcedlearning主动学习按模型分类⎩ ⎨ ⎧⎩ ⎨ ⎧概率模型probabilisticmodel非概率模型non−probabilisticmodel{线性模型linermodel非线性模型non−linermodel{参数化方法parametericmodel非参数化方法non−parametericmodel按技巧分类{贝叶斯:贝叶斯定理Bayesianlearning核方法:核函数kernelmethod按算法分类{在线学习onlinelearning批量学习batchlearning
1.2.1 参数化/非参数化方法
参数化:假设模型的参数维度固定
- 感知机
- 朴素贝叶斯
- 逻辑斯蒂回归
- K均值
- 高斯混合模型
非参数化:参数维度不固定,随数据量的增加而增加
- 决策树
- Adaboosting
- K近邻
- 语义分析
- 潜在狄利克雷分配
1.2.2 按算法分类
在线学习:一次一个数据,动态调整模型
- 接收一个输入 X t X_t Xt ,用已知模型给出 f ^ ( X t ) \hat{f}(X_t) f^(Xt) 后,得到反馈 y t y_t yt
- 系统用损失函数计算 f ^ ( X t ) \hat{f}(X_t) f^(Xt) 与 y t y_t yt 的差异,更新模型
批量学习:一次所有数据,学习模型
随机梯度下降感知机
ω = ω − α ∂ l ∂ ω 在线学习: ω i + 1 ← ω i − α ∂ l ∂ ω ——振荡 批量学习: ω i + 1 ← ω i − α ∂ l ‾ ∂ ω ——稳定下降 \begin{aligned} &\omega=\omega-\alpha\frac{\partial l}{\partial \omega}\\ &在线学习:\omega_{i+1}\leftarrow \omega_i-\alpha\frac{\partial l}{\partial \omega}——振荡\\ &批量学习:\omega_{i+1}\leftarrow \omega_i-\alpha\frac{\overline{\partial l}}{\partial \omega}——稳定下降 \end{aligned} ω=ω−α∂ω∂l在线学习:ωi+1←ωi−α∂ω∂l——振荡批量学习:ωi+1←ωi−α∂ω∂l——稳定下降
10个数据, 1 10 ∑ i = 1 10 ∂ l ( X i ) ∂ ω i = ∂ l ‾ ∂ ω \frac{1}{10}\sum\limits_{i=1}^{10}\frac{\partial l(X_i)}{\partial \omega_i}=\frac{\overline{\partial l}}{\partial \omega} 101i=1∑10∂ωi∂l(Xi)=∂ω∂l
1.2.3 按模型分类
概率模型——条件概率
非概率模型(确定性模型)——决策函数
监督学习 { 概率模型: P ( y ∣ X ) ——生成模型 非概率模型: y = f ( X ) ——判别模型 监督学习\begin{cases} 概率模型:P(y\vert X)——生成模型\\ 非概率模型:y=f(X)——判别模型 \end{cases} 监督学习{概率模型:P(y∣X)——生成模型非概率模型:y=f(X)——判别模型
概率模型
- 决策树
- 朴素贝叶斯
- 隐马尔科夫模型
- 条件随机场
- 高斯混合模型
- 概率混合模型
- 潜在狄利克雷分配
概率模型的代表为 概率图模型
-
联合概率分布由有向图和无向图表示
-
遵循加法,乘法原则
{ P ( x ) = ∑ y P ( x , y ) P ( x , y ) = P ( x ) P ( y ) \begin{cases} P(x)=\sum\limits_{y}P(x,y)\\ P(x,y)=P(x)P(y) \end{cases} ⎩ ⎨ ⎧P(x)=y∑P(x,y)P(x,y)=P(x)P(y)
非概率模型
{ 线性模型 非线性模型 \begin{cases} 线性模型\\ 非线性模型 \end{cases} {线性模型非线性模型
线性模型
- 感知机
- 线性SVM
- K近邻
- K均值
- 潜在语义分析
非线性模型
-
核函数SVM
核函数: 线性不可分的低维空间 → 线性可分的高维空间 线性不可分的低维空间\rightarrow 线性可分的高维空间 线性不可分的低维空间→线性可分的高维空间
核技巧
R 2 : X = ( X ( 1 ) , X ( 2 ) ) T Φ ( X ) R 2 → H : Φ ( ( X ( 1 ) ) 2 , 2 X ( 1 ) X ( 2 ) , ( X ( 2 ) ) 2 ) R^2:X=(X^{(1)},X^{(2)})^T\\ \Phi(X)R^2\rightarrow \mathcal{H}:\Phi\left((X^{(1)})^2,\sqrt{2}X^{(1)}X^{(2)},(X^{(2)})^2\right) R2:X=(X(1),X(2))TΦ(X)R2→H:Φ((X(1))2,2X(1)X(2),(X(2))2) -
AdaBoost
-
神经网络
逻辑斯蒂回归

将线性回归模型 ω T x + b = 0 \omega^T x+b=0 ωTx+b=0 代入 z z z ,归一化可得到概率分布,故逻辑斯蒂回归既是概率模型又是非概率模型
1.2.4 基本分类
{ 监督学习 基于已知类别的训练数据进行学习 无监督学习 基于未知类别的训练数据进行学习 半监督学习 同时使用已知类别和未知类别的数据进行学习 \begin{cases} 监督学习&基于已知类别的训练数据进行学习\\ 无监督学习&基于未知类别的训练数据进行学习\\ 半监督学习&同时使用已知类别和未知类别的数据进行学习 \end{cases} ⎩ ⎨ ⎧监督学习无监督学习半监督学习基于已知类别的训练数据进行学习基于未知类别的训练数据进行学习同时使用已知类别和未知类别的数据进行学习
监督学习
从标注的数据中学习预测模型
- 标注:已知实例的分类,某些特征的取值
本质:学习输入与输出间映射的统计规律
分类
根据输入输出类型:
- 分类问题:输出变量为有限个离散变量,SP:二分类问题
- 回归问题(预测):输入变量与输出变量均为连续变量
- 标注问题:输入变量和输出变量均为变量序列
符号表示
输入变量: X X X ,取值空间 x ∈ χ ( 所有可能取值集合 ) x\in \chi(所有可能取值集合) x∈χ(所有可能取值集合) ——输入空间
输出变量: Y Y Y ——输出空间
每个具体输入:实例(instance) 用特征向量 (feature vcector) 表示
- 实例 : 线性空间中的一个点 ∈ 特征空间 实例:线性空间中的一个点\in 特征空间 实例:线性空间中的一个点∈特征空间
输入实例 x 的特征向量 { X = ( X ( 1 ) X ( 2 ) ⋮ X ( i ) ⋮ X ( m ) ) 表示第 i 个特征的取值 x j = ( X j ( 1 ) X j ( 2 ) ⋮ X j ( i ) ⋮ X j ( m ) ) 表示第 j 个变量的第 i 个特征的取值 输入实例 x 的特征向量\begin{cases} X=\left( \begin{aligned} &X^{(1)}\\ &X^{(2)}\\ &\vdots\\ &X^{(i)}\\ &\vdots\\ &X^{(m)} \end{aligned} \right)表示第 i 个特征的取值\\ x_j=\left( \begin{aligned} &X_j^{(1)}\\ &X_j^{(2)}\\ &\vdots\\ &X_j^{(i)}\\ &\vdots\\ &X_j^{(m)} \end{aligned} \right)表示第j个变量的第i个特征的取值 \end{cases} 输入实例x的特征向量⎩ ⎨ ⎧X= X(1)X(2)⋮X(i)⋮X(m) 表示第i个特征的取值xj= Xj(1)Xj(2)⋮Xj(i)⋮Xj(m) 表示第j个变量的第i个特征的取值
注 : 特征空间 ≠ 输入空间 特征空间\neq 输入空间 特征空间=输入空间
训练数据集:
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\} T={(x1,y1),(x2,y2),⋯,(xn,yn)}
联合概率分布:给出 X X X 与 Y Y Y 之间遵循的关系—— P ( X , Y ) P(X,Y) P(X,Y)
假设空间: 输入到输出的映射由模型表示 ∈ \in ∈ 假设空间 hypothesis space 所有可能的模型的集合
- 概率模型: P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 条件概率分布
- 决策函数: Y = f ( X ) Y=f(X) Y=f(X)
形式化
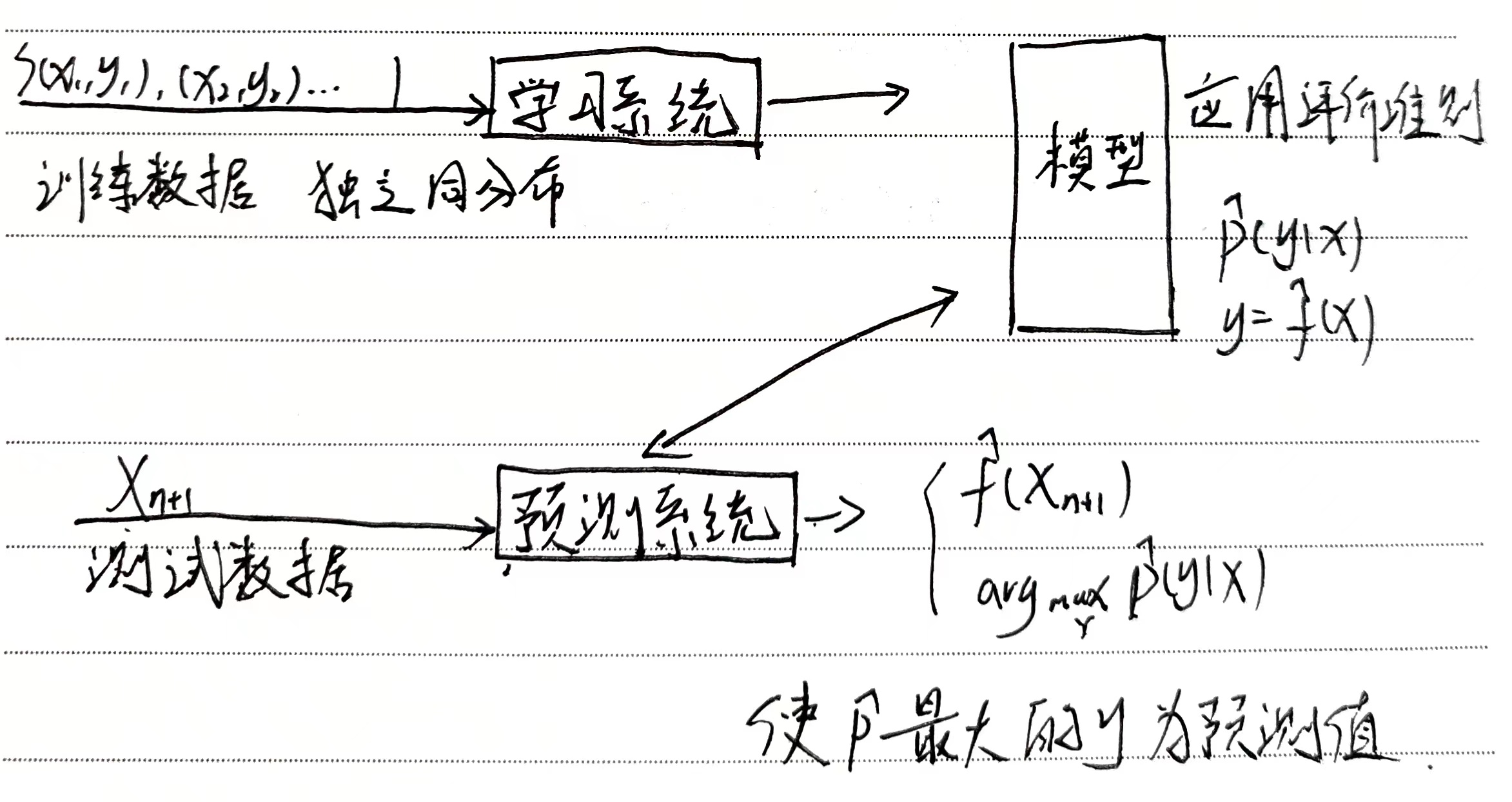
学习的模型分为概率模型和非概率模型
- 概率模型由条件概率表示,在预测时,通过 a r g max y P ( y ∣ x ) arg\max\limits_{y}P(y\vert x) argymaxP(y∣x) 得到输出
- 非概率模型由决策函数表示,在预测时,给出一个输出结果
特征
- 数据有标注
- 输入产生相应的输出
- 本质是学习输入与输出映射的统计规律
无监督模型
从无标注的数据中学习预测模型
特征
- 数据无标注——自然得到的数据
- 预测模型:每个输出都是对输入的分析结果,表示数据的类别(聚类)、转换(降维)、概率估计
- 本质是学习数据中的统计规律与潜在结构
符号表示
χ \chi χ :输入空间
z z z :隐式结构
- 降维
- 硬聚类:一对一,只属于一个类别
- 软聚类:一对多,可能属于多个类别
模型: { z = g θ ( x ) P θ ( z ∣ X ) , P ( X ∣ z ) \begin{cases}z=g_{\theta}(x)\\P_{\theta}(z\vert X),P(X\vert z)\end{cases} {z=gθ(x)Pθ(z∣X),P(X∣z)
H \mathcal{H} H :所有可能模型的集合——假设空间
训练数据: U = { X 1 , X 2 , ⋯ , X n } U=\left\{X_1,X_2,\cdots,X_n\right\} U={X1,X2,⋯,Xn} , X i X_i Xi 表示样本
形式化

强化学习
系统与环境连续互动中学习最优行为策略
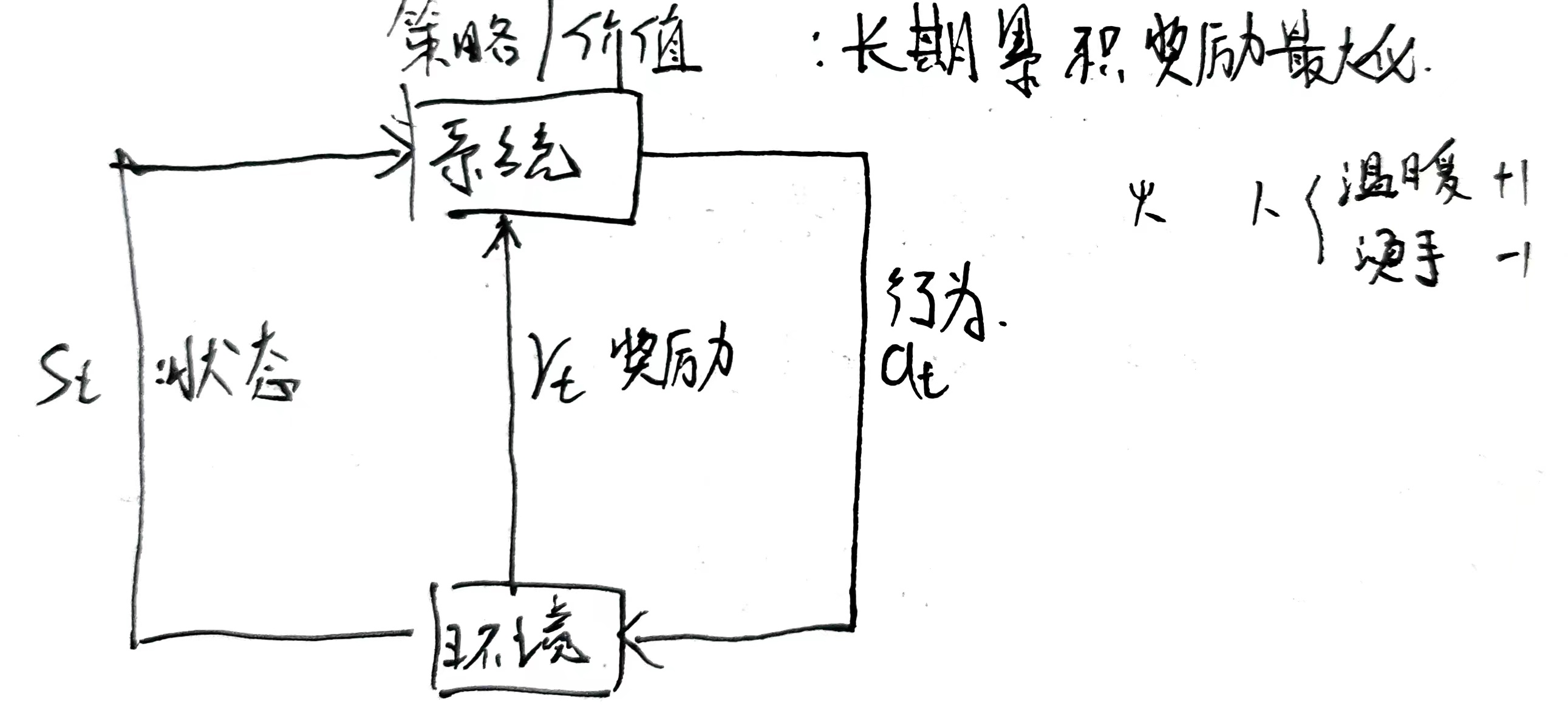
半监督学习
少量标注,大量未标注数据
主动学习
机器找到对学习最有帮助的实例,给出实例让人标注
1.2.5 按技巧分类
- 贝叶斯学习
- 核方法
贝叶斯方法
利用贝叶斯原理,计算在给数据下,模型的后验概率 P ( θ ∣ D ) P(\theta\vert D) P(θ∣D) ,并进行模型估计、数据预测 P ( x ∣ D ) = ∫ P ( x ∣ θ , D ) P ( θ ∣ D ) d θ P(x\vert D)=\int P(x\vert \theta,D)P(\theta\vert D)d\theta P(x∣D)=∫P(x∣θ,D)P(θ∣D)dθ
特点
- 模型参数、未知量用变量表示
- 使用模型的先验概率
步骤
-
D : 数据 , θ : 参数 D:数据,\theta:参数 D:数据,θ:参数
后验概率 P ( θ ∣ D ) = P ( θ ) P ( D ∣ θ ) P ( D ) P(\theta\vert D)=\frac{P(\theta)P(D\vert \theta)}{P(D)} P(θ∣D)=P(D)P(θ)P(D∣θ) 变先验 P ( θ ) P(\theta) P(θ)
-
预测,并计算期望
P ( x ∣ D ) = ∫ P ( x ∣ θ , D ) P ( θ ∣ D ) d θ P(x\vert D)=\int P(x\vert \theta,D)P(\theta\vert D)d\theta P(x∣D)=∫P(x∣θ,D)P(θ∣D)dθ
取贝叶斯估计最大,可得到极大似然最大
D → M L E θ ^ = a r g max θ P ( D ∣ θ ) D → B a y e s i a n θ ^ = a r g max θ P ( θ ∣ D ) = a r g max θ P ( D ∣ θ ) P ( θ ) P ( D ) D\xrightarrow{MLE}\hat{\theta}=arg\max\limits_{\theta}P(D\vert \theta)\\ D\xrightarrow{Bayesian}\hat{\theta}=arg\max\limits_{\theta}P(\theta\vert D)=arg\max\limits_{\theta}\frac{P(D\vert \theta)P(\theta)}{P(D)} DMLEθ^=argθmaxP(D∣θ)DBayesianθ^=argθmaxP(θ∣D)=argθmaxP(D)P(D∣θ)P(θ)
-
P ( D ∣ θ ) P(D\vert \theta) P(D∣θ) 似然概率,在已知参数 θ \theta θ 取值时,取得数据 D D D 的概率
对于极大似然估计,目标是调整参数 θ \theta θ 使数据 D D D 出现的概率最大化,即令 L ( θ ) = P ( D ∣ θ ) = 样本 i i d ∏ i = 1 n P ( X i ∣ θ ) L(\theta)=P(D\vert \theta)\xlongequal{样本iid}\prod\limits_{i=1}^nP(X_i\vert \theta) L(θ)=P(D∣θ)样本iidi=1∏nP(Xi∣θ) 最大化,此时的 θ ^ \hat{\theta} θ^ 作为参数的估计值
-
P ( θ ) P(\theta) P(θ) :为先验知识,通过统计数据可得,作为已知数据
P ( D ) P(D) P(D) 是固定的,后验概率 P ( θ ∣ D ) P(\theta\vert D) P(θ∣D) 可以通过计算似然概率与先验概率求得
贝叶斯估计:使后验概率最大的 θ ^ \hat{\theta} θ^ 为贝叶斯估计的参数
所以重点来到对似然概率的求解
核方法
使用核函数表示和学习非线性模型,可以将线性模型扩展到非线性模型
- SVM
- 核PCA
- K均值
显式定义: 输入空间 → 特征空间,进行内积运算 输入空间\rightarrow特征空间,进行内积运算 输入空间→特征空间,进行内积运算
输入空间 < X 1 , X 2 > ↓ 特征空间 < ϕ ( X 1 ) , ϕ ( X 2 ) > 输入空间 <X_1,X_2>\\ \downarrow\\ 特征空间 <\phi(X_1),\phi(X_2)> 输入空间<X1,X2>↓特征空间<ϕ(X1),ϕ(X2)>
隐式定义:直接定义核函数,在输入空间中内积运算
K ( X 1 , X 2 ) = < ϕ ( X 1 ) , ϕ ( X 2 ) > K(X_1,X_2)=<\phi(X_1),\phi(X_2)> K(X1,X2)=<ϕ(X1),ϕ(X2)>
1.3 统计学习三要素
方法=模型+策略+算法
- 模型:选定某一类模型——SVM/EM
- 策略:模型选择标准、准则—— J ( θ ) J(\theta) J(θ) ,风险最小化
- 算法:怎样快速确定模型
1.3.1 模型
监督学习 { 条件概率 决策函数 ⇒ 假设空间 F :模型的所有可能的集合 监督学习\begin{cases} 条件概率\\ 决策函数 \end{cases}\Rightarrow 假设空间\mathcal{F}:模型的所有可能的集合 监督学习{条件概率决策函数⇒假设空间F:模型的所有可能的集合
{ F = { f ∣ Y = f ( x ) } ,由参数决定的参数族 决策函数 { 线性模型 : ω , b S V M : ω , b , α E M : π , θ F = { f ∣ Y = f θ ( X ) , θ ∈ R n } P θ ( Y ∣ X ) 条件概率分布 { 用于分类,预测 a r g max Y P ( Y ∣ X ) \begin{cases} \mathcal{F}=\{f\vert Y=f(x)\},由参数决定的参数族\\ \quad决策函数\begin{cases} 线性模型:\omega,b\\ SVM:\omega,b,\alpha\\ EM:\pi,\theta \end{cases}\\\\ \mathcal{F}=\{f\vert Y=f_{\theta}(X),\theta\in R^n\}\\ \quad P_{\theta}(Y\vert X)条件概率分布\begin{cases} 用于分类,预测arg\max\limits_{Y}P(Y\vert X) \end{cases} \end{cases} ⎩ ⎨ ⎧F={f∣Y=f(x)},由参数决定的参数族决策函数⎩ ⎨ ⎧线性模型:ω,bSVM:ω,b,αEM:π,θF={f∣Y=fθ(X),θ∈Rn}Pθ(Y∣X)条件概率分布{用于分类,预测argYmaxP(Y∣X)
1.3.2 策略
按什么样准则选择模型的最优参数组
损失:度量模型 一次 预测的好坏
风险:度量 平均 意义下预测的好坏
常用损失函数
预测模型得出的预测值 f ( X ) f(X) f(X) 与 y y y 有差距,用损失函数 L ( y , f ( X ) ) L(y,f(X)) L(y,f(X)) 表示
{ 0 − 1 L ( y , f ( X ) ) = { 1 , y ≠ f ^ ( X ) 0 , y = f ^ ( X ) I ( y ≠ f ^ ( X ) ) 表示不等则为 1 平方损失 L ( y , f ( X ) ) = ( y − f ( X ) ) 2 ——放大损失 绝对损失 L ( y , f ( X ) ) = ∣ y − f ( X ) ∣ 对数损失 L ( y , P ( Y ∣ X ) ) = − l o g P ( Y ∣ X ) \begin{cases} 0-1&L(y,f(X))=\begin{cases} 1,y\neq \hat{f}(X)\\ 0,y=\hat{f}(X) \end{cases}\\ &I(y\neq \hat{f}(X))表示不等则为1\\\\ 平方损失&L(y,f(X))=(y-f(X))^2——放大损失\\\\ 绝对损失&L(y,f(X))=\vert y-f(X)\vert\\\\ 对数损失&L(y,P(Y\vert X))=-logP(Y\vert X) \end{cases} ⎩ ⎨ ⎧0−1平方损失绝对损失对数损失L(y,f(X))={1,y=f^(X)0,y=f^(X)I(y=f^(X))表示不等则为1L(y,f(X))=(y−f(X))2——放大损失L(y,f(X))=∣y−f(X)∣L(y,P(Y∣X))=−logP(Y∣X)
风险函数(期望损失)
关于联合分布的期望损失(expectation risk)
R e x p ( f ) = E [ L ( y , f ( X ) ) ] 期望损失对 P ( Y ∣ X ) 进行评价 = ∫ X Y L ( y , f ( X ) ) P ( X , Y ) d x d y \begin{aligned} R_{exp}(f)&=E\left[L(y,f(X))\right]\quad 期望损失对P(Y\vert X) 进行评价\\ &=\int_{\mathcal{XY}}L(y,f(X))P(X,Y)dxdy\\ \end{aligned} Rexp(f)=E[L(y,f(X))]期望损失对P(Y∣X)进行评价=∫XYL(y,f(X))P(X,Y)dxdy
表示 f ( X ) f(X) f(X) 关于联合分布 P ( X , Y ) P(X,Y) P(X,Y) 的平均意义下的损失
R e x p ( f ) R_{exp}(f) Rexp(f) 不可计算: P ( X , Y ) P(X,Y) P(X,Y) 未知。
- 若 P ( X , Y ) P(X,Y) P(X,Y) 已知,则可通过 P ( Y ∣ X ) P(Y\vert X) P(Y∣X) 计算
- 病态:期望损失用到 P ( Y ∣ X ) P(Y\vert X) P(Y∣X)
朴素贝叶斯后验概率最大化是期望风险最小化策略
经验函数(平均损失)
empirical risk
D = { ( X 1 , y 1 ) , ( X 2 , y 2 ) , ⋯ , ( X N , y n ) } D=\{(X_1,y_1),(X_2,y_2),\cdots,(X_N,y_n)\} D={(X1,y1),(X2,y2),⋯,(XN,yn)}
R e m p ( f ) = 1 N ∑ i = 1 N L ( y i , f ( X i ) ) → N → ∞ R e x p ( f ) R_{emp}(f)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i))\xrightarrow{N\rightarrow\infty}R_{exp}(f) Remp(f)=N1i=1∑NL(yi,f(Xi))N→∞Rexp(f)
极大似然估计是经验风险最小化策略
X 1 , X 2 , ⋯ , X N ∼ i i d P ( X ) ,求 X 服从分布的参数 X_1,X_2,\cdots,X_N\overset{iid}{\sim}P(X),求X服从分布的参数 X1,X2,⋯,XN∼iidP(X),求X服从分布的参数
可观测样本的联合概率分布一定是最大(小概率事件原理)可采样的, P P P 越大,联合概率 P P P 越大
P ( X 1 ) P ( X 2 ) , ⋯ , P ( X N ) = ∏ i = 1 N P ( X i ) max ∏ i = 1 N P ( X i ) = m a x ∑ i = 1 N l o g P ( X i ) = − m i n ∑ i = 1 N l o g P ( X i ) P(X_1)P(X_2),\cdots,P(X_N)=\prod\limits_{i=1}^NP(X_i)\\ \max\prod\limits_{i=1}^NP(X_i)=max\sum\limits_{i=1}^NlogP(X_i)=-min\sum\limits_{i=1}^NlogP(X_i) P(X1)P(X2),⋯,P(XN)=i=1∏NP(Xi)maxi=1∏NP(Xi)=maxi=1∑NlogP(Xi)=−mini=1∑NlogP(Xi)
可得损失函数,也即对数损失函数。即经验风险最小化策略
由于现实中 N N N 很小,需要对 R e m p R_{emp} Remp 矫正
{ 经验风险最小化 结构风险最小化 + 正则化项,控制过拟合程度 \begin{cases} 经验风险最小化\\ 结构风险最小化+正则化项,控制过拟合程度 \end{cases} {经验风险最小化结构风险最小化+正则化项,控制过拟合程度
经验风险最小化和结构风险最小化
样本量足够大,用经验风险最小化策略 —— empirical risk minimization,ERM
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( X i ) ) \min\limits_{f\in \mathcal{F}} \frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i)) f∈FminN1i=1∑NL(yi,f(Xi))
样本容量小 ——过拟合 ← \leftarrow ← 参数过多
过拟合解决思路 { 加样本容量 加正则化项 \begin{cases}加样本容量\\加正则化项\end{cases} {加样本容量加正则化项
用结构风险最小化策略——structural risk minimization SRM
R s r m ( f ) = 1 N ∑ i = 1 N L ( y i , f ( X i ) ) + λ J ( f ) { f 越简单,参数量越少 , J ( f ) 越小 f 越复杂,参数量越多, J ( f ) 越大 R_{srm}(f)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i))+\lambda J(f)\begin{cases} f越简单,参数量越少,J(f)越小\\ f越复杂,参数量越多,J(f)越大 \end{cases} Rsrm(f)=N1i=1∑NL(yi,f(Xi))+λJ(f){f越简单,参数量越少,J(f)越小f越复杂,参数量越多,J(f)越大
- λ ≥ 0 \lambda\ge 0 λ≥0 用于权衡 s r m srm srm 与 e r m erm erm
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( X i ) ) + λ J ( f ) \min\limits_{f\in \mathcal{F}}\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i))+\lambda J(f) f∈FminN1i=1∑NL(yi,f(Xi))+λJ(f)
1.3.3 算法
用什么样方法,求最优模型
梯度下降求损失函数的极值,最优解
解析解 → 数值解 → 转化为对偶问题 解析解\rightarrow 数值解\rightarrow 转化为对偶问题 解析解→数值解→转化为对偶问题
1.4 模型评估与选择
噪声数据:训练样本本身还可能包含一些噪声,这些随机噪声会给模型精确性带来误差
1.4.1 误差
学习器的预测输出与样本真实输出之间的差异被定义为机器学习中的误差
分类问题中, 误差率 = 分类错的样本数 全部样本数 × 100 % 误差率=\frac{分类错的样本数}{全部样本数}\times 100\% 误差率=全部样本数分类错的样本数×100%
训练误差 :学习器在训练集上的平均误差,经验误差
R e m p = 1 N ∑ i = 1 N L ( y i , f ^ ( X i ) ) R_{emp}=\frac{1}{N}\sum\limits_{i=1}^N L(y_i,\hat{f}(X_i)) Remp=N1i=1∑NL(yi,f^(Xi))
- 描述输入属性和输出分类之间的相关性,能够判定给定的问题是不是一个容易学习的问题
测测误差 :学习器在测试集上的误差,泛化误差
e t e s t = 1 N ′ ∑ i = 1 N ′ L ( y i , f ^ ( X i ) ) e_{test}=\frac{1}{N'}\sum\limits_{i=1}^{N'} L(y_i,\hat{f}(X_i)) etest=N′1i=1∑N′L(yi,f^(Xi))
- 反映了学习器对未知测试数据集的预测能力
实用的学习器都是测试误差较低,即在新样本上变现比较好的学习器
eg:
0-1损失 L ( y , f ^ ( X ) ) L(y,\hat{f}(X)) L(y,f^(X))
e t e s t = 1 N ′ ∑ i = 1 N ’ I ( y i ≠ f ^ ( X i ) ) e_{test}=\frac{1}{N'}\sum\limits_{i=1}^{N’} I(y_i\neq \hat{f}(X_i)) etest=N′1i=1∑N’I(yi=f^(Xi)) 误差率 error
r t e s t = 1 N ′ ∑ i = 1 N ’ I ( y i = f ^ ( X i ) ) r_{test}=\frac{1}{N'}\sum\limits_{i=1}^{N’} I(y_i= \hat{f}(X_i)) rtest=N′1i=1∑N’I(yi=f^(Xi)) 正确率 right
模型复杂度与测试误差
当模型复杂度较低时,测试误差较高
随着模型复杂度增加,测试误差将逐渐下降并达到最小值
之后当模型复杂度继续上升,测试误差会随之增加,对应过拟合的发生
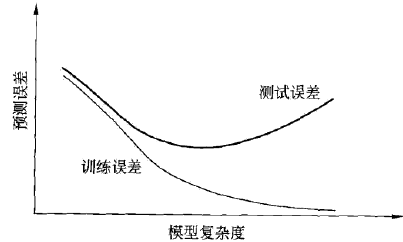
理想模型
逼近 “真”模型 { 参数个数相同 参数向量相近 \begin{cases}参数个数相同\\参数向量相近\end{cases} {参数个数相同参数向量相近
1.4.2 欠拟合
欠拟合:学习能力太弱,以致于训练数据的基本性质都没学到
在实际的机器学习中,欠拟合可以通过改进学习器的算法克服,但过拟合却无法避免
-
由于训练样本的数量有限,所以具备有限个参数的模型就足以将所有样本都纳入其中。
但模型的参数越多,与这个模型精确符合的数据也越少,将这样的模型运用到无穷的未知数据中,过拟合的出现便不可避免
1.4.3 过拟合
原因 :将噪音数据并入模型
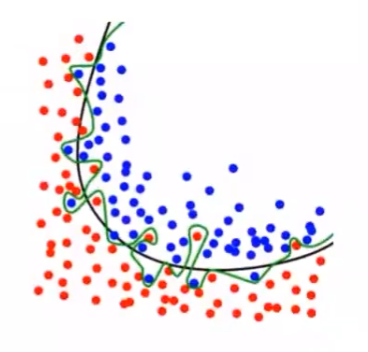
过拟合:对训练数据拟合程度越高,学习时模型会越复杂(包含的参数过多),从而导致训练误差较低但测试误差较高(失去泛化能力)
- 表现为错把训练数据的特征当做整体的特征
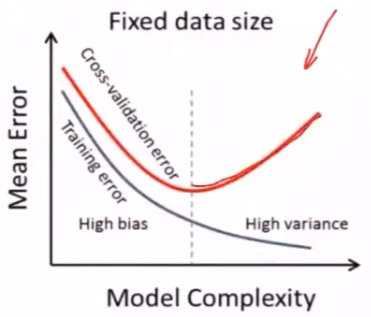
多项式复杂度代表模型复杂度与自由度,自由度过高会出现过拟合问题
避免过拟合
-
增大样本容量
-
集成学习:训练很多模型,对模型求均值
-
正则化:对模型复杂度加以惩罚
W = ∑ V ( f ( x i , t i ) ) + λ Ω ( f ) W=\sum V(f(x_i,t_i))+\lambda\Omega(f) W=∑V(f(xi,ti))+λΩ(f) -
交叉验证
正则化
控制模型参数范围,使一些参数趋于0或等于0
结构风险最小化策略的实现
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( X i ) ) + λ J ( f ) \min\limits_{f\in \mathcal{F}}\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i))+\lambda J(f) f∈FminN1i=1∑NL(yi,f(Xi))+λJ(f)
正则化项
-
L 2 L_2 L2 范数尽可能趋于0
L ( ω ) = 1 N ∑ i = 1 N L ( y i , f ^ ( X i ) ) + J ( f ) = 1 N ∑ i = 1 N ( f ^ ( X i ) − y i ) 2 + λ 2 ∥ ω ∥ 2 2 ∥ ω ∥ 2 = ω 1 2 + ω 2 2 + ⋯ + ω m 2 , 限制条件 ∑ ω 2 ≤ m \begin{aligned} L(\omega)&=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,\hat{f}(X_i))+J(f)\\ &=\frac{1}{N}\sum\limits_{i=1}^N\left(\hat{f}(X_i)-y_i\right)^2+\frac{\lambda}{2}\Vert \omega\Vert^2_2\\ &\Vert \omega\Vert_2=\sqrt{\omega_1^2+\omega_2^2+\cdots+\omega_m^2},限制条件 \sum\omega^2\le m \end{aligned} L(ω)=N1i=1∑NL(yi,f^(Xi))+J(f)=N1i=1∑N(f^(Xi)−yi)2+2λ∥ω∥22∥ω∥2=ω12+ω22+⋯+ωm2,限制条件∑ω2≤m -
L 1 L_1 L1 范数——使参数稀疏化
L ( ω ) = 1 N ∑ i = 1 N L ( y i , f ^ ( X i ) ) + J ( f ) = 1 N ∑ i = 1 N ( f ^ ( X i ) − y i ) 2 + λ ∥ ω ∥ 1 ∥ ω ∥ 1 = ∣ ω 1 ∣ ∣ ω 2 ∣ + ⋯ + ∣ ω m ∣ \begin{aligned} L(\omega)&=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,\hat{f}(X_i))+J(f)\\ &=\frac{1}{N}\sum\limits_{i=1}^N\left(\hat{f}(X_i)-y_i\right)^2+\lambda\Vert \omega\Vert_1\\ &\Vert \omega\Vert_1=\vert\omega_1\vert\vert\omega_2\vert+\cdots+\vert \omega_m\vert \end{aligned} L(ω)=N1i=1∑NL(yi,f^(Xi))+J(f)=N1i=1∑N(f^(Xi)−yi)2+λ∥ω∥1∥ω∥1=∣ω1∣∣ω2∣+⋯+∣ωm∣
经验风险较小的模型,正则化项会比较大
- 用于选择经验风险与模型复杂度同时小的模型
奥卡姆剃刀
在所有可能解释数据的模型中,模型越简单越好
-
对于贝叶斯估计,先验概率为正则项。
复杂模型,先验概率小
简单模型,先验概率大
正则化为什么防止过拟合
R s r m ( ω ) = 1 N ∑ i = 1 N L ( y i , f ^ ( X i ) ) + λ J ( ω ) { L 1 : ∥ ω ∥ 1 = ∑ i = 1 m ∣ ω i ∣ L 2 : ∥ ω ∥ 2 = ∑ i = 1 m ω i 2 R_{srm}(\omega)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,\hat{f}(X_i))+\lambda J(\omega)\begin{cases} L_1:\Vert \omega\Vert_1=\sum\limits_{i=1}^m\vert \omega_i\vert\\ L_2:\Vert \omega\Vert_2=\sqrt{\sum\limits_{i=1}^m\omega_i^2} \end{cases} Rsrm(ω)=N1i=1∑NL(yi,f^(Xi))+λJ(ω)⎩ ⎨ ⎧L1:∥ω∥1=i=1∑m∣ωi∣L2:∥ω∥2=i=1∑mωi2
对于平方损失函数, L ( ω ) = 1 N ∑ i = 1 N [ y i − f ^ ( X i ) ] 2 + λ ∥ ω ∥ 2 2 L(\omega)=\frac{1}{N}\sum\limits_{i=1}^N\left[y_i-\hat{f}(X_i)\right]^2+\lambda\Vert \omega\Vert_2^2 L(ω)=N1i=1∑N[yi−f^(Xi)]2+λ∥ω∥22
正则化项可看做拉格朗日算子,该函数极值点为令 { ∂ L ∂ ω i = 0 ∂ L ∂ λ = 0 \begin{cases}\frac{\partial L}{\partial \omega_i}=0\\\frac{\partial L}{\partial\lambda}=0\end{cases} {∂ωi∂L=0∂λ∂L=0 的点
也可以对参数和进行约束
{ min R e m p = 1 N ∑ i = 1 N [ y i − f ^ ( X i ) ] 2 s . t . ∥ ω ∥ 2 2 ≤ m \begin{cases} \min R_{emp}=\frac{1}{N}\sum\limits_{i=1}^N\left[y_i-\hat{f}(X_i)\right]^2\\ s.t. \Vert \omega\Vert_2^2\le m \end{cases} ⎩ ⎨ ⎧minRemp=N1i=1∑N[yi−f^(Xi)]2s.t.∥ω∥22≤m
KKT条件:
{ m i n f ( x ) s . t . { g j ( x ) ≤ 0 , j = 1 , ⋯ , m h k ( x ) = 0 , k = 1 , ⋯ , l \begin{cases} min f(x)\\ s.t. \begin{cases} g_j(x)\le 0,j=1,\cdots,m\\ h_k(x)=0,k=1,\cdots,l \end{cases} \end{cases} ⎩ ⎨ ⎧minf(x)s.t.{gj(x)≤0,j=1,⋯,mhk(x)=0,k=1,⋯,l
构造拉格朗日函数 L ( X ; μ ; λ ) = f ( X ) + ∑ j = 1 m μ j g j ( X ) + ∑ k = 1 l λ k h k ( X ) L(X;\mu;\lambda)=f(X)+\sum\limits_{j=1}^m\mu_jg_j(X)+\sum\limits_{k=1}^l \lambda_k h_k(X) L(X;μ;λ)=f(X)+j=1∑mμjgj(X)+k=1∑lλkhk(X)
令
{ ∂ L ∂ X i = 0 h k ( X ) = 0 , k = 1 , ⋯ , l ∂ L ∂ λ k = 0 ∑ μ j g j ≤ 0 , j = 1 , ⋯ , m μ j ≥ 0 \begin{cases} \frac{\partial L}{\partial X_i}=0\\\\ h_k(X)=0,k=1,\cdots,l\\\\ \frac{\partial L}{\partial \lambda_k}=0\\\\ \sum\mu_jg_j\le 0,j=1,\cdots,m\\\\ \mu_j\ge 0 \end{cases} ⎩ ⎨ ⎧∂Xi∂L=0hk(X)=0,k=1,⋯,l∂λk∂L=0∑μjgj≤0,j=1,⋯,mμj≥0
L ( ω ) = 1 N ∑ i = 1 N [ f ^ ( X i ) − y i ] 2 + λ ( ∥ ω ∥ 2 2 − m ) L(\omega)=\frac{1}{N}\sum\limits_{i=1}^N\left[\hat{f}(X_i)-y_i\right]^2+\lambda(\Vert \omega\Vert_2^2-m) L(ω)=N1i=1∑N[f^(Xi)−yi]2+λ(∥ω∥22−m)
代入 K K T 条件有 { ∂ L ( ω ) ∂ ω i = 0 ∂ L ∂ λ = 0 代入KKT条件有\\ \begin{cases} \frac{\partial L(\omega)}{\partial \omega_i}=0\\ \frac{\partial L}{\partial\lambda}=0 \end{cases} 代入KKT条件有{∂ωi∂L(ω)=0∂λ∂L=0
由此可知,带正则化项与带约束项是一致的
1.4.4 泛化能力
模型对位置数据的预测能力
由于测试数据集是有限的,依赖测试误差的评价结果不可靠
泛化误差:风险函数(期望损失)最小化
R e x p ( f ^ ) = E P [ L ( y , f ^ ( X ) ) ] = ∫ X Y L ( y , f ^ ( X ) ) ⋅ P ( X , Y ) d x d y R_{exp}(\hat{f})=E_P[L(y,\hat{f}(X))]=\int_{\mathcal{XY}}L(y,\hat{f}(X))\cdot P(X,Y)dxdy Rexp(f^)=EP[L(y,f^(X))]=∫XYL(y,f^(X))⋅P(X,Y)dxdy
由于 { 数据量少,无法用于对全部数据测试 X , Y 联合分布位置 \begin{cases}数据量少,无法用于对全部数据测试\\X,Y联合分布位置\end{cases} {数据量少,无法用于对全部数据测试X,Y联合分布位置 ,无法计算期望损失
比较 泛化误差上界 ,上界小的模型比较好
- 样本容量越多,泛化上界 → 0 \rightarrow 0 →0
- 假设空间容量越多,泛化误差上界越大
泛化误差上界
f f f 的期望风险, R ( f ) = E [ L ( y , f ( X ) ) ] R(f)=E[L(y,f(X))] R(f)=E[L(y,f(X))]
经验风险, R ^ ( f ) = 1 N ∑ i = 1 N L ( y i , f ( X i ) ) \hat{R}(f)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i)) R^(f)=N1i=1∑NL(yi,f(Xi))
经验风险最小化策略, f N = a r g min f ∈ F R ^ ( f ) = a r g min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( X i ) ) f_N=arg \min\limits_{f\in \mathcal{F}} \hat{R}(f)=arg \min\limits_{f\in \mathcal{F}}\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i)) fN=argf∈FminR^(f)=argf∈FminN1i=1∑NL(yi,f(Xi))
对于 f N f_N fN 的泛化能力
R ( f ) ≤ R ^ ( f ) + ε ( d ; N ; σ ) = 1 N ∑ i = 1 N L ( y i , f ( X i ) ) + 1 2 N ( log d + log 1 σ ) R(f)\le \hat{R}(f)+\varepsilon(d;N;\sigma)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i,f(X_i))+\sqrt{\frac{1}{2N}(\log d+\log\frac{1}{\sigma})} R(f)≤R^(f)+ε(d;N;σ)=N1i=1∑NL(yi,f(Xi))+2N1(logd+logσ1)
-
对于任一 f ∈ F f\in \mathcal{F} f∈F ,以 1 − σ 1-\sigma 1−σ 概率上式成立, σ ∈ ( 0 , 1 ) \sigma\in (0,1) σ∈(0,1)
-
d d d 为 ∣ F ∣ , F = { f 1 , f 2 , ⋯ , f d } \vert\mathcal{F}\vert,\mathcal{F}=\{f_1,f_2,\cdots,f_d\} ∣F∣,F={f1,f2,⋯,fd}
由泛化上界可知,
{ N ↑ ,泛化误差越小 d ↓ ,模型假设空间越少,泛化误差越小 σ ↑ ,对模型的确信度 ( 1 − σ ) 越小,泛化误差越小 \begin{cases} N\uparrow,泛化误差越小\\ d\downarrow,模型假设空间越少,泛化误差越小\\ \sigma\uparrow,对模型的确信度(1-\sigma)越小,泛化误差越小 \end{cases} ⎩ ⎨ ⎧N↑,泛化误差越小d↓,模型假设空间越少,泛化误差越小σ↑,对模型的确信度(1−σ)越小,泛化误差越小
样本多,备选模型少,小范围使用,不信任普适性,则泛化误差小
交叉验证
D = { 训练集:训练模型 验证集:模型选择 测试集:模型评估 D=\begin{cases} 训练集:训练模型\\ 验证集:模型选择\\ 测试集:模型评估 \end{cases} D=⎩ ⎨ ⎧训练集:训练模型验证集:模型选择测试集:模型评估
验证集和测试集不用于训练模型
调参(是否过拟合)——评估泛化能力
- 对模型框架定义
- 学习率
交叉验证思想在于重复利用有限的训练样本,通过将数据切分成若干子集,让不同的子集分别组成训练集与测试集,并在此基础上反复进行训练、测试和模型选择,达到最优效果。
交叉验证 适用于 { 数据量少 训练数据可重复使用 \begin{cases}数据量少\\训练数据可重复使用\end{cases} {数据量少训练数据可重复使用
-
简单交叉验证
训练+测试随机划分
-
k折交叉验证
将数据集分为 k k k 个大小相等,互不相交的子集,用 k − 1 k-1 k−1 个子集作为训练集,1个用作测试集,进行 k k k 轮训练,保证每份数据集都被用作测试集,选出 k k k 次评测中平均测试误差最小的模型
留一交叉验证 :一份一个样本
- 折数=样本数
1.4.5 参数取值
参数的取值是影响模型性能的重要因素,同样的学习算法在不同的参数配置下,得到的模型性能会有显著差异
假设一个神经网络有1000个参数,每个参数有10种取值可能,对于每一组训练/测试集就有 100 0 10 1000^{10} 100010 个模型需要考察,因此在调参过程中,主要的问题就是性能与效率的折衷
1.4.6 维数诅咒
在高维空间中,同样规模的数据集会变得很稀疏
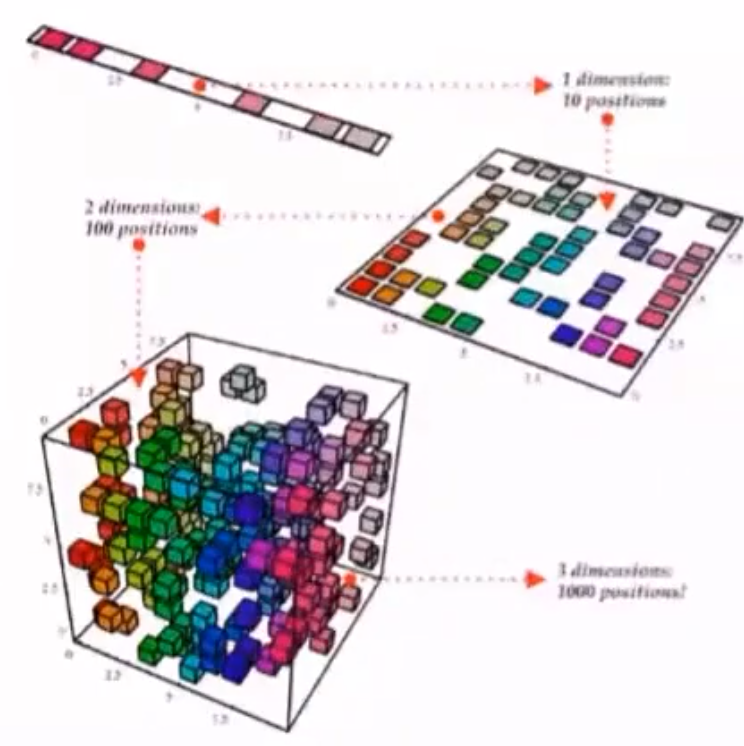
在高维空间,达到与低维空间相同的数据密度需要更大的数据量
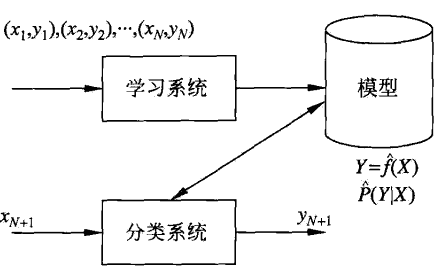
1.5 监督学习
监督学习假定训练数据满足独立同分布,并根据训练数据学习出一个由输入到输出的映射模型
- 所有可能的映射模型共同构成了假设空间
监督学习的任务是在假设空间中根据特定的误差准则找到最优的模型,形式为 { 决策函数 Y = f ( X ) 条件概率分布 P ( Y ∣ X ) \begin{cases}决策函数Y=f(X)\\条件概率分布P(Y\vert X)\end{cases} {决策函数Y=f(X)条件概率分布P(Y∣X)
1.5.1 学习方法
生成方法
关注 X,Y的真实状态,强调数据本身(掌握所有语言再判断)
首先学习X,Y的联合概率分布 P ( X , Y ) P(X,Y) P(X,Y) ,再求出条件概率分布 P ( Y ∣ X ) P(Y\vert X) P(Y∣X)
- 反映同类数据的相似度
- 学习的收敛速度快:当样本容量增加,学到的模型更快,收敛于真实模型
- 当存在隐变量时,用生成方法
判别方法
关注给定输入X,有什么样的输出Y,强调数据边界(语言关键词)
直接学习决策函数 Y = f ( X ) Y=f(X) Y=f(X) 或条件概率 P ( Y ∣ X ) P(Y\vert X) P(Y∣X)
- 反映数据的差异
- 学习难度小,准确率高
- 对数据进行抽象,定义特征并使用特征简化学习问题
- 具有更高的准确率和更简单的使用方式
1.5.2 模型
生成模型
由生成方法学习到的模型为生成模型,遍历所有结果,取概率最大的为结果
- 朴素贝叶斯
判别模型
由判别方法生成的模型为判别模型,直接得到结果
- 感知机
- K近邻
- 逻辑斯蒂回归
- 最大熵模型
- SVM
1.5.3 监督学习应用
分类问题
输出为有限个离散值
二分类问题
T:预测正确,P:预测为正类
F:预测错误,N:预测为负类
预测正误 预测结果 备注 T P 将正类归为正类 T N 将负类归为负类 F P 将负类归为正类 F N 将正类归为负类 \begin{array}{c|c|l} 预测正误&预测结果&备注\\ \hline T&P&将正类归为正类\\ T&N&将负类归为负类\\ F&P&将负类归为正类\\ F&N&将正类归为负类 \end{array} 预测正误TTFF预测结果PNPN备注将正类归为正类将负类归为负类将负类归为正类将正类归为负类
当 F P FP FP 减小, F N FN FN 会增大
指标
准确率 = ∣ 预测正确的 ∣ ∣ 总 ∣ = T P + T N ∣ 总 ∣ 错误率 = ∣ 预测错误的 ∣ ∣ 总 ∣ = F P + F N ∣ 总 ∣ 精确率 P = 预测对的正类 ∣ 预测为正类 ∣ = T P T P + F P ——推荐,少而精准 召回率 R = ∣ 预测对的正类 ∣ ∣ 真正的正类 ∣ = T P T P + F N ——预测癌症,宁可错杀 准确率=\frac{\vert 预测正确的\vert}{\vert 总\vert}=\frac{TP+TN}{\vert 总\vert}\\ 错误率=\frac{\vert 预测错误的\vert}{\vert 总\vert}=\frac{FP+FN}{\vert 总\vert}\\ 精确率P=\frac{预测对的正类}{\vert 预测为正类\vert}=\frac{TP}{TP+FP}——推荐,少而精准\\ 召回率R=\frac{\vert预测对的正类\vert}{\vert 真正的正类\vert}=\frac{TP}{TP+FN}——预测癌症,宁可错杀 准确率=∣总∣∣预测正确的∣=∣总∣TP+TN错误率=∣总∣∣预测错误的∣=∣总∣FP+FN精确率P=∣预测为正类∣预测对的正类=TP+FPTP——推荐,少而精准召回率R=∣真正的正类∣∣预测对的正类∣=TP+FNTP——预测癌症,宁可错杀
精确率(查准率)与召回率(查全率)是相互矛盾的,在不同模型中要是用不同评价指标
- P P P 越大,则 R R R 越小
调和均值
2 F 1 = 1 P + 1 R = T P + F P T P + T P + F N T P = 2 T P + F N + F P T P F 1 = T P 2 T P + F N + F P \frac{2}{F_1}=\frac{1}{P}+\frac{1}{R}=\frac{TP+FP}{TP}+\frac{TP+FN}{TP}=\frac{2TP+FN+FP}{TP}\\ F_1=\frac{TP}{2TP+FN+FP} F12=P1+R1=TPTP+FP+TPTP+FN=TP2TP+FN+FPF1=2TP+FN+FPTP
标注问题
分类问题 → 推广 标注问题 → 简单形式 结构预测 分类问题\xrightarrow{推广}标注问题\xrightarrow{简单形式}结构预测 分类问题推广标注问题简单形式结构预测
输入:观测序列
- X i = ( x i ( 1 ) , x i ( 2 ) , ⋯ , x i ( n ) ) X_i=(x_i^{(1)},x_i^{(2)},\cdots,x_i^{(n)}) Xi=(xi(1),xi(2),⋯,xi(n)) 表示一个样本在不同阶段的取值
输出:标记序列/状态序列
- y i = ( y i ( 1 ) , y i ( 2 ) , ⋯ , y i ( n ) ) y_i=(y_i^{(1)},y_i^{(2)},\cdots,y_i^{(n)}) yi=(yi(1),yi(2),⋯,yi(n)) 表示输出在不同阶段的值
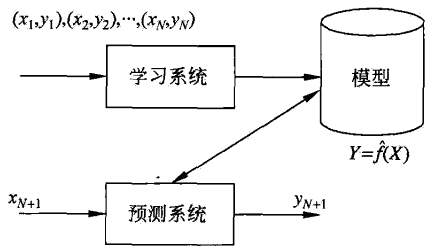
回归问题
用于预测输入变量和输出变量的关系,输入与输出之间的映射函数 ⟺ \iff ⟺ 函数拟合
学习+预测
变量个数—— n n n 大小
特征数量 { 一元回归——一个特征维度 多元回归——多个特征维度 \begin{cases}一元回归——一个特征维度\\多元回归——多个特征维度\end{cases} {一元回归——一个特征维度多元回归——多个特征维度
平方损失函数MSE(mean square error) : 1 2 [ f ^ ( X i ) − y i ] 2 \frac{1}{2}[\hat{f}(X_i)-y_i]^2 21[f^(Xi)−yi]2
- 最小二乘法求解LMS(least mean square)
- MSE最小化 ⟺ \iff ⟺ 极大似然估计
对于复杂的现实问题,很难用已有的函数进行拟合
神经网络逼近 f ( x ) f(x) f(x) ——预测问题
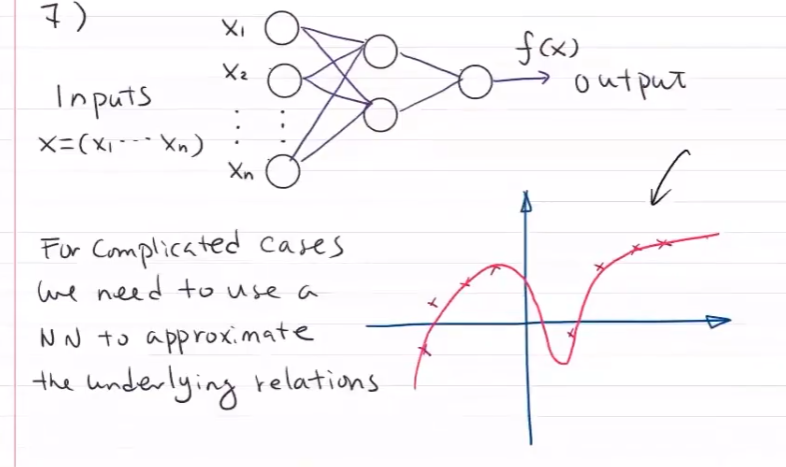
概率拟合 贝叶斯——分类问题
P ( 0 ∣ X ) > P ( 1 ∣ X ) P(0\vert X)>P(1\vert X) P(0∣X)>P(1∣X) 则分类为0
1.6 频率派与贝叶斯派
1.6.1 频率派
频率本身会随机波动,但随着重复实验的次数不断增加,特定事件出现的频率值会呈现出稳定性,逐渐趋近于某个常数
从事件发生的频率认识概率的方法称为 “频率学派”。概率被认为是一个独立可重复实验中,单个结果出现频率极限。
稳定的频率是统计规律性的体现 ,用其表征事件发生的可能性是一种合理的思路
频率学派依赖的是古典概型。由于古典概型只描述单个随机事件,并不能刻画两个随机事件之间的关系。所以引入的 条件概率 ,进一步得出 全概率公式 。
KaTeX parse error: Expected group after '_' at position 11: P(A)=\sum_̲\limits{i=1}^nP…
全概率公式代表了频率派解决问题的思路:先做出一些假设 P ( B i ) P(B_i) P(Bi) ,再在这些假设下讨论随机事件的概率 P ( A ∣ B i ) P(A\vert B_i) P(A∣Bi)
1.6.2 贝叶斯派
逆概率 :由全概率公式调整得来,即在事件结果 P ( A ) P(A) P(A) 确定的条件下,推断各种假设发生的可能性
通过贝叶斯公式,可以将后验概率 P ( D ∣ H ) P(D\vert H) P(D∣H) 转变为先验概率 P ( H ) P(H) P(H)
P ( H ∣ D ) = P ( D ∣ H ) P ( H ) P ( D ) P(H\vert D)=\frac{P(D\vert H)P(H)}{P(D)} P(H∣D)=P(D)P(D∣H)P(H)
- P ( H ) P(H) P(H) :先验概率,假设成立的概率
- P ( D ∣ H ) P(D\vert H) P(D∣H) :似然概率
- P ( H ∣ D ) P(H\vert D) P(H∣D) :后验概率,已知结果下情况下假设成立的概率
贝叶斯定理提供了解决问题的新思路:根据观测结果寻找最佳的理论解释
1.6.3 区别
频率学派 认为假设是客观存在且不会改变的,即存在固定的先验分布,需要通过 最大似然估计 确定概率分布的类型和参数,以此作为基础进行概率推演。
贝叶斯学派 认为固定的先验分布是不存在的,即参数本身是随机数。假设本身取决于结果,是不确定的、可以修正的。数据的作用就是对假设不断修正,通过 贝叶斯估计 使后验概率最大化 。
从 参数估计 角度也能体现两种思想的差距
由于实际任务中可供使用的训练数据有限,因而需要对概率分布的参数进行估计。
最大似然估计(最大似然概率 P ( D ∣ H ) P(D\vert H) P(D∣H))的思想是使训练数据出现的概率最大化,以此确定概率分布中的未知参数
贝叶斯方法(最大后验概率 P ( H ∣ D ) P(H\vert D) P(H∣D)):根据训练数据和已知的其他条件,使未知参数出现的可能性最大化,并选取最大概率对应的未知参数
- 还需要额外的信息 ——先验概率 P ( H ) P(H) P(H)