前言:本文介绍近5年来生成式跨模态隐写领域的相关工作。
相关阅读:生成式文本隐写发展综述
不同于文本隐写,跨模态隐写需要考虑不同模态间的相关性,常见的跨模态场景有:Image-to-Text(如图像描述), Text-to-Speech(如语音助手), Text-to-Image(如按文作画)等。下面对基于深度学习的生成式跨模态隐写相关工作进行介绍。
[1]- 基于图像描述的文本信息隐藏 (北京邮电大学学报,2018) BUPT, Xue et al.

- 主要思想:采用CNN+LSTM框架,通过对基于Beam Search 的搜索方法进行改动。首先在密文首部加入16bit信息表示密文长度,然后根据不同的接收方共享场景分别设计了
- 基于句子的隐藏算法(SSH):使用 Beam Search,在所有单词生成完毕之后,通过对 2 n 2^{n} 2n个候选句等长编码,在最终句的选取过程中嵌入秘密信息;
- 基于单词的隐藏算法(WWH):Beam 长度为1时,Beam Search 退化为贪婪搜索。在每个时间步生成单词时,固定候选词集为2,密文为1则选择较大概率的词,密文为2则选择较小概率的词。
- 基于散列函数的隐藏算法(HH):通过下述公式将每个单词对应1bit的秘密信息,这种方法根据文本即可提取秘密信息。
v ( w , k e y ) = ( m d 5 ( w + k e y ) ) m o d 2 v(w,key) = (md5(w+key)) mod 2 v(w,key)=(md5(w+key))mod2
- 数据集:Flicker8k
- 评价指标:嵌入容量:
bpw;语义相关性:BLEU-N
[2]- Rits: real-time interactive text steganography based on automatic dialogue model (ICCCS, 2018) Tshinghua University, Yang et al.

这篇文章虽然不是跨模态的文章,但它指出生成的隐写文本应具备认知不可感知性,即:其语义应与上下文的语义相关,这一观点在跨模态文本隐写领域同样适用。
- 主要思想:针对对话场景,使用RNN+强化学习,使用基于完全二叉树的定长编码嵌入秘密信息。
- 数据集:对话数据集 negotiator
- 评价指标:效率:
time
[3]- Steganographic visual story with mutual-perceived joint attention (EURASIP, 2021) Shanghai University, Guo et al.

- 主要思想:本文提出概率分布方差在一定范围之内才能保证认知不可感知性,设计了一种自适应候选词集的信息嵌入和提取方法。
- 数据集:VIST
- 评价指标:视觉不可感知性:
Perplexity;认知不可感知性:BLEU&METEOR
[4]- ICStega: Image Captioning-based Semantically Controllable Linguistic Steganography (SPL, 2023) USTC, Wang et al.
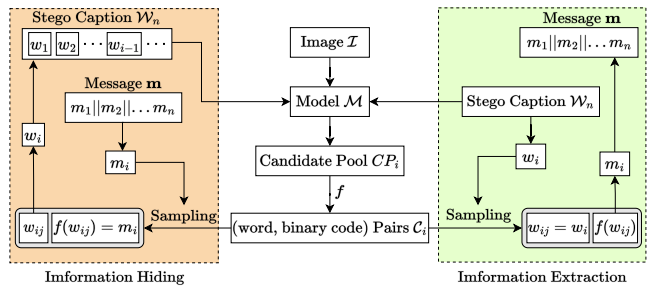
- 主要思想:本文主要提出一个基于语义控制的候选词集构建方法
- 数据集: MS COCO
- 评价指标:嵌入量:
bpw;视觉不可感知性:Perplexity;安全性:抗隐写分析能力 TS-FCN;认知不可感知性:BLEU&METEOR;多样性:LSA&Self-CIDEr
[5]- Cross-Modal Text Steganography Against Synonym Substitution-Based Text Attack (SPL, 2023) Fudan University, Peng et al.

- 主要思想:抗同义词替换攻击,有损隐写,使用DNN编码秘密信息,在解码网络中解锁。
- 数据集:MS COCO
- 评价指标:统计不可感知性:
KL散度;抗隐写分析能力:LS-CNN&R-BIC&SeSy&BERT-FT - 开源代码:https://github.com/hunanpolly/Cross-Modal-Steganography
[6]- Cover Reproducible Steganography via Deep Generative Models (TDSC, 2022) USTC, Chen et al.

- 应用场景:Text-to-Speech;Text-to-Image
[7]- Distribution-Preserving Steganography Based on Text-to-Speech Generative Models (TDSC, 2022) USTC, Chen et al.

- 应用场景:Text-to-Speech




![[unity]三角形顶点顺序](https://img-blog.csdnimg.cn/00190330434348ff9d9cb5d6c7ca87a0.gif)