-
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
-
增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。
-
Web页面按存在方式可以分为表层网页(surface Web)和深层网页(deep Web,也称invisible Web pages或hidden Web)。
-
表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的Web页面。
-
深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
01 聚焦爬虫技术
聚焦网络爬虫(focused crawler)也就是主题网络爬虫。聚焦爬虫技术增加了链接评价和内容评价模块,其爬行策略实现要点就是评价页面内容以及链接的重要性。
基于链接评价的爬行策略,主要是以Web页面作为半结构化文档,其中拥有很多结构信息可用于评价链接重要性。还有一个是利用Web结构来评价链接价值的方法,也就是HITS法,其通过计算每个访问页面的Authority权重和Hub权重来决定链接访问顺序。
而基于内容评价的爬行策略,主要是将与文本相似的计算法加以应用,提出Fish-Search算法,把用户输入查询词当作主题,在算法的进一步改进下,通过Shark-Search算法就能利用空间向量模型来计算页面和主题相关度大小。
面向主题爬虫,面向需求爬虫:会针对某种特定的内容去爬取信息,而且会保证信息和需求尽可能相关。一个简单的聚焦爬虫使用方法的示例如下所示。
-
【例1】一个简单的爬取图片的聚焦爬虫
import urllib.request# 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包
import re# 正则用来规律爬取
keyname=""# 想要爬取的内容
key=urllib.request.quote(keyname)# 需要将你输入的keyname解码,从而让计算机读懂
for i in range(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search?q="+key+"&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180815&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(i*44)
# url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则
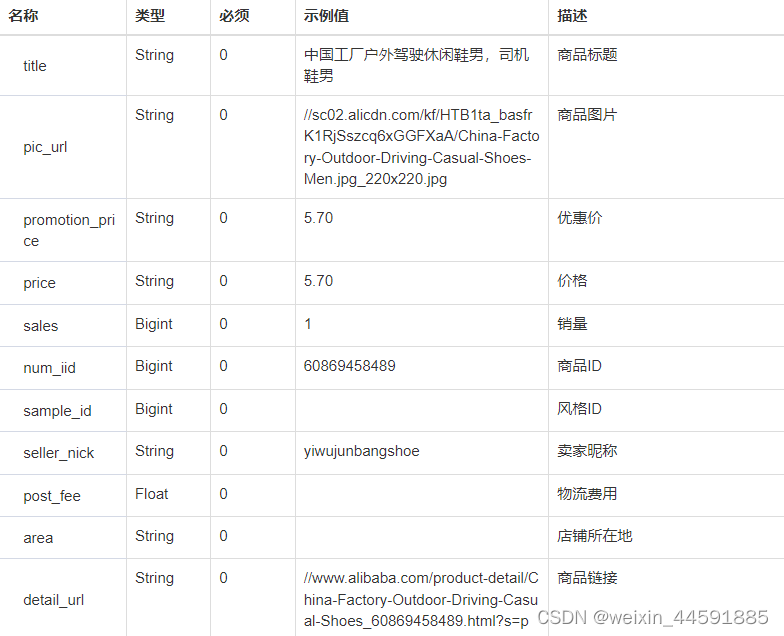
# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'
# pat使用正则表达式从网页爬取图片
# 将你爬取到的内容放在一个列表里面print(picturelist)# 可以不打印,也可以打印下来看看for j in range(0,len(picturelist)):picture=picturelist[j]pictureurl="http://"+picture# 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file)# 最后保存到文件夹
02 通用爬虫技术
通用爬虫技术(general purpose Web crawler)也就是全网爬虫。其实现过程如下。
-
第一,获取初始URL。初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
-
第二,根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,需要先爬取对应URL地址中的网页,接着将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,并且将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
-
第三,将新的URL放到URL队列中,在于第二步内获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
-
第四,从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
-
第五,满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫便会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。详情请参见图2-5中的右下子图。
通用爬虫技术的应用有着不同的爬取策略,其中的广度优先策略以及深度优先策略都是比较关键的,如深度优先策略的实施是依照深度从低到高的顺序来访问下一级网页链接。
关于通用爬虫使用方法的示例如下。
-
【例2】爬取京东商品信息
'''
爬取京东商品信息:请求url:https://www.jd.com/提取商品信息:1.商品详情页2.商品名称3.商品价格4.评价人数5.商品商家
'''
from selenium import webdriver # 引入selenium中的webdriver
from selenium.webdriver.common.keys import Keys
import timedef get_good(driver):try:# 通过JS控制滚轮滑动获取所有商品信息js_code = '''window.scrollTo(0,5000);'''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2)# 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item')n = 1for good in good_list:# 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector('.p-img a').get_attribute('href')# 商品名称good_name = good.find_element_by_css_selector('.p-name em').text.replace("\n", "--")# 商品价格good_price = good.find_element_by_class_name('p-price').text.replace("\n", ":")# 评价人数good_commit = good.find_element_by_class_name('p-commit').text.replace("\n", " ")good_content = f'''商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}\n'''print(good_content)with open('jd.txt', 'a', encoding='utf-8') as f:f.write(good_content)next_tag = driver.find_element_by_class_name('pn-next')next_tag.click()time.sleep(2)# 递归调用函数get_good(driver)time.sleep(10)finally:driver.close()if __name__ == '__main__':good_name = input('请输入爬取商品信息:').strip()driver = webdriver.Chrome()driver.implicitly_wait(10)# 往京东主页发送请求driver.get('https://www.jd.com/')# 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key')input_tag.send_keys(good_name)input_tag.send_keys(Keys.ENTER)time.sleep(2)get_good(driver)03 增量爬虫技术
某些网站会定时在原有网页数据的基础上更新一批数据。例如某电影网站会实时更新一批最近热门的电影,小说网站会根据作者创作的进度实时更新最新的章节数据等。在遇到类似的场景时,我们便可以采用增量式爬虫。
增量爬虫技术(incremental Web crawler)就是通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新后的新数据。
关于如何进行增量式的爬取工作,以下给出三种检测重复数据的思路:
-
在发送请求之前判断这个URL是否曾爬取过;
-
在解析内容后判断这部分内容是否曾爬取过;
-
写入存储介质时判断内容是否已存在于介质中。
-
第一种思路适合不断有新页面出现的网站,比如小说的新章节、每天的实时新闻等;
-
第二种思路则适合页面内容会定时更新的网站;
-
第三种思路则相当于最后一道防线。这样做可以最大限度地达到去重的目的。
不难发现,实现增量爬取的核心是去重。目前存在两种去重方法。
-
第一,对爬取过程中产生的URL进行存储,存储在Redis的set中。当下次进行数据爬取时,首先在存储URL的set中对即将发起的请求所对应的URL进行判断,如果存在则不进行请求,否则才进行请求。
-
第二,对爬取到的网页内容进行唯一标识的制定(数据指纹),然后将该唯一标识存储至Redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,可以先判断该数据的唯一标识在Redis的set中是否存在,从而决定是否进行持久化存储。
关于增量爬虫的使用方法示例如下所示。
-
【例3】爬取4567tv网站中所有的电影详情数据
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from incrementPro.items import IncrementproItem
class MovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html']rules = (Rule(LinkExtractor(allow=r'/frim/index7-\d+\.html'), callback='parse_item', follow=True),)# 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379)def parse_item(self, response):li_list = response.xpath('//li[@class="p1 m1"]')for li in li_list:# 获取详情页的urldetail_url = 'http://www.4567tv.tv' + li.xpath('./a/@href').extract_first()# 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url)if ex == 1:print('该url没有被爬取过,可以进行数据的爬取')yield scrapy.Request(url=detail_url, callback=self.parst_detail)else:print('数据还没有更新,暂无新数据可爬取!')# 解析详情页中的电影名称和类型,进行持久化存储def parst_detail(self, response):item = IncrementproItem()item['name'] = response.xpath('//dt[@class="name"]/text()').extract_first()item['kind'] = response.xpath('//div[@class="ct-c"]/dl/dt[4]//text()').extract()item['kind'] = ''.join(item['kind'])yield it
管道文件:
from redis import Redis
class IncrementproPipeline(object):conn = Nonedef open_spider(self,spider):self.conn = Redis(host='127.0.0.1',port=6379)def process_item(self, item, spider):dic = {'name':item['name'],'kind':item['kind']}print(dic)self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6return item04 深层网络爬虫技术
在互联网中,网页按存在方式可以分为表层网页和深层网页两类。
所谓的表层网页,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层网页则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词后才能够获取到的页面,深层网络爬虫(deep Web crawler)最重要的部分即为表单填写部分。
在互联网中,深层网页的数量往往要比表层网页的数量多很多,故而,我们需要想办法爬取深层网页。
深层网络爬虫的基本构成:URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深层网络爬虫的表单填写有两种类型:
-
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写);
-
基于网页结构分析的表单填写(一般在领域知识有限的情况下使用,这种方式会根据网页结构进行分析,并自动地进行表单填写)。