⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬
这次来给大家分享一下小红书笔记的爬取方式,希望对大家有帮助!
一、找到目标数据:
小红书笔记的内容和互动数据(点赞数、收藏数、评论数)如下:
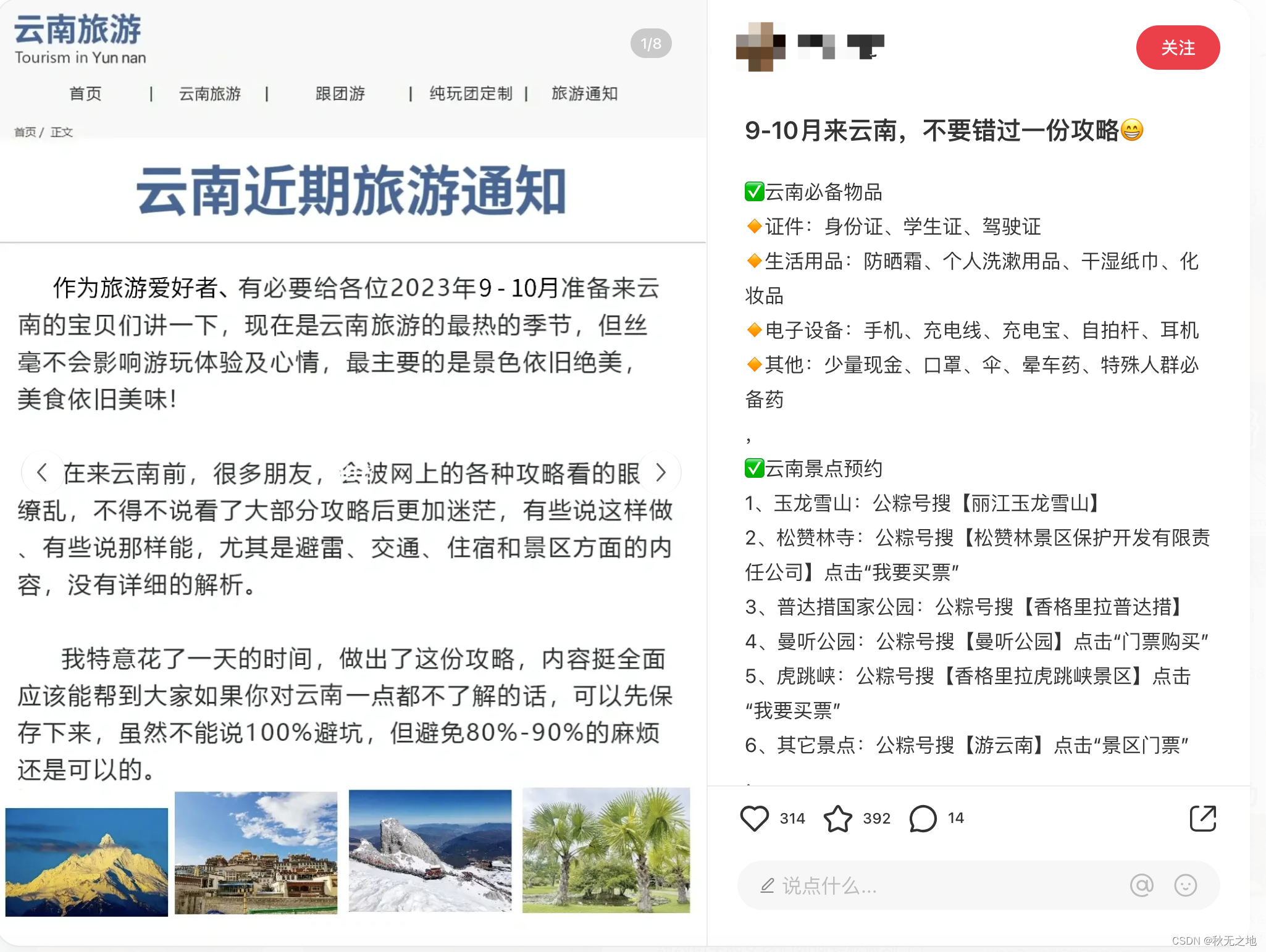
二、找到数据所在接口或页面:
通过f12,搜索笔记ID,找到对应的接口,然后在接口返回信息体中,搜索点赞数,发现找到对应的数据,说明这个接口或页面就是我们的目标
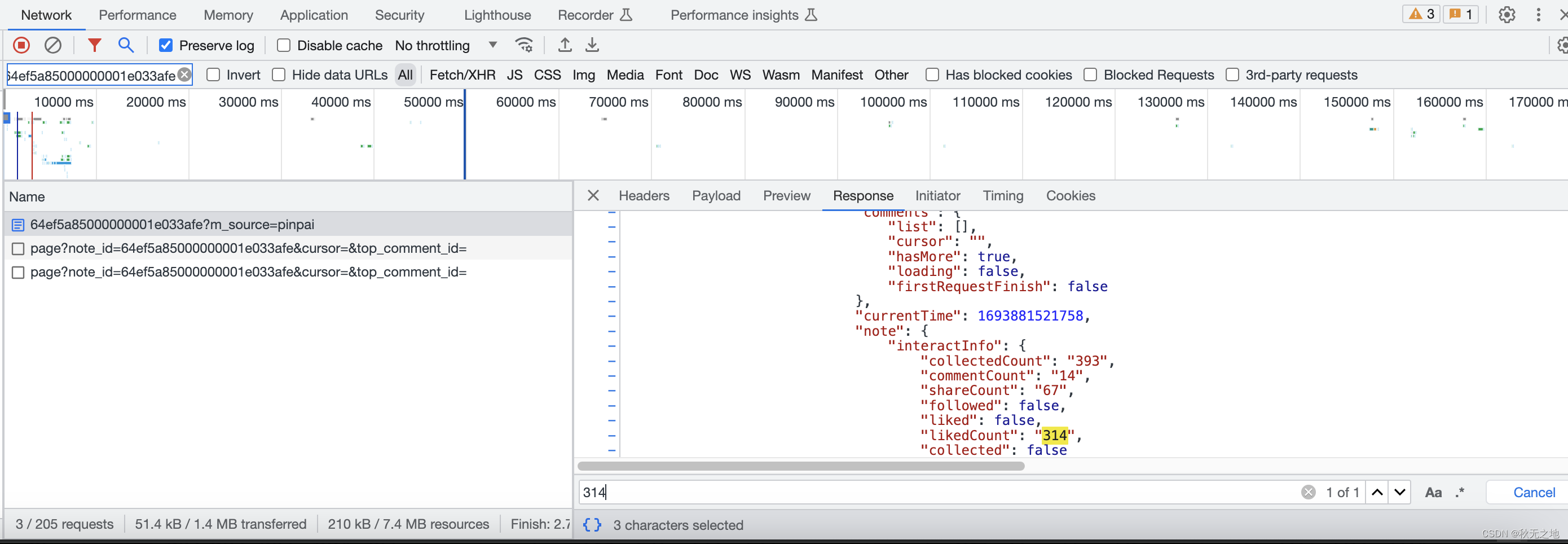
三、检查接口或页面的请求参数:
通过检查接口的请求参数,判断是否有加密参数、混淆参数等,下图可以看到,除了一个cookie参数以外,其他参数都是不变的

四、获取登录cookie:
一般获取登录cookie,方式有2种,第一种是接口请求,另一种是模拟登录,相对而言,第二种简单点。具体操作,请查下我另一个的一篇文章。
五、返回数据抽取目标数据:
目标数据是存放在这个字典中,可以使用正则匹配,匹配结果就能通过字典读取了。

# 正则匹配
note_result = re.findall(r'__INITIAL_STATE__=(.*?)</script>', note_res)[0].replace("undefined",'null')###用户描述###
# 笔记标题
note_info_dict['title'] = note_dict['title']
# 笔记数据
interactions = note_dict['interactInfo']
# 点赞数
note_info_dict['liked_count'] = int(interactions['likedCount'])
# 收藏数
note_info_dict['collected_count'] = int(interactions['collectedCount'])
# 评论数
note_info_dict['comments_count'] = int(interactions['commentCount'])
# 分享数
note_info_dict['share_num'] = int(interactions['shareCount'])以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://my.csdn.net/weixin_42108731