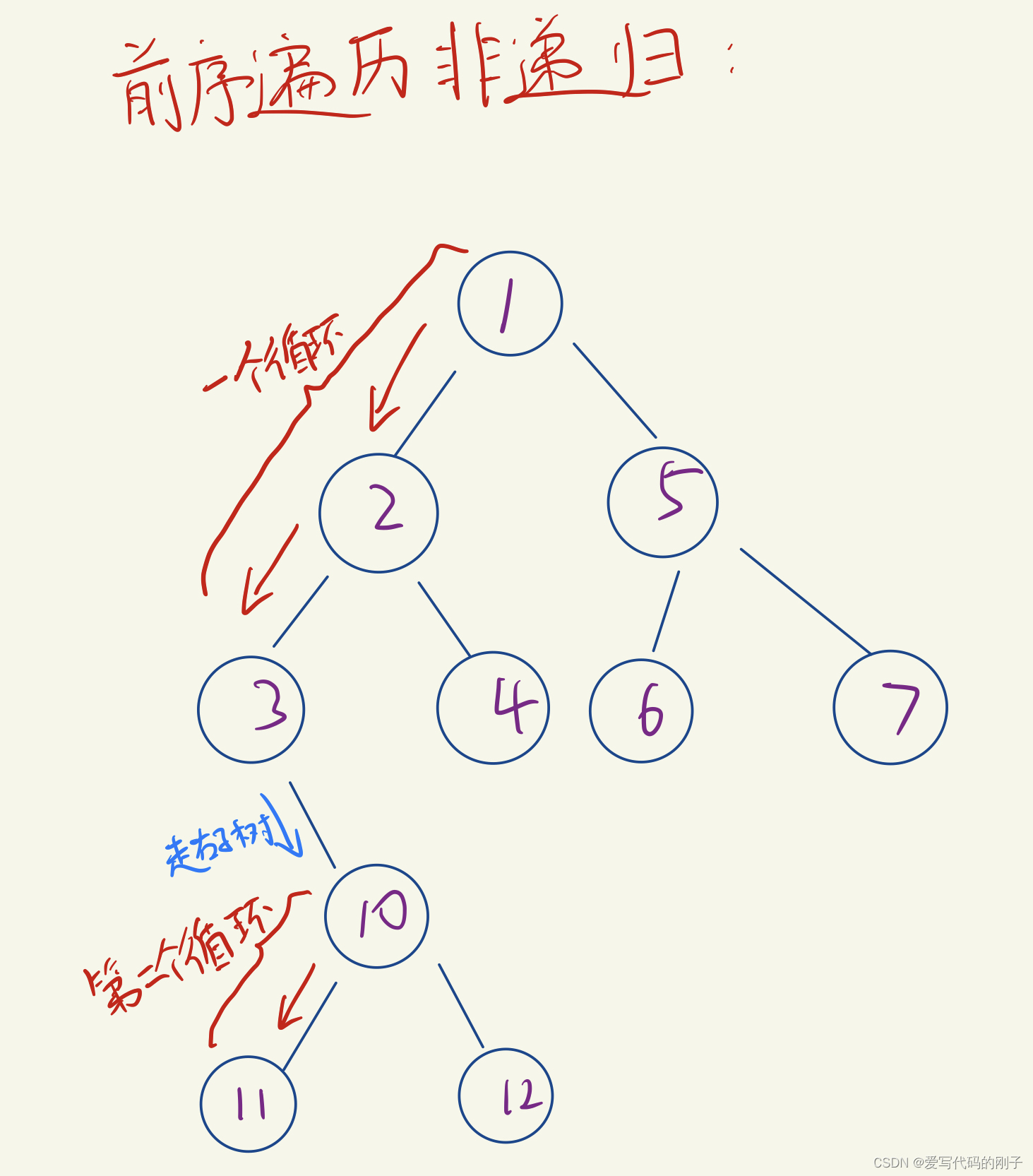
目录
1. 导读
2. ConcurrentHashMap 成员变量解读
3. ConcurrentHashMap 初始化
3.1 ConcurrentHashMap 无参构造源码解读
3.2 ConcurrentHashMap 带参构造源码解读
3.3 tableSizeFor 方法作用解读
3.4 ConcurrenthashMap初始化总结
4. ConcurrentHashMap 添加元素方法解读
4.1 put 源码解读
4.2 putVal 方法解读
3.3 initTable 初始化方法解读
4.4 put 添加元素方法总结概括
5. ConcurrentHashMap 树化操作何时进行?
6. ConcurrentHashMap 数组长度维护解读
7. ConcurrentHashMap 键和值能否为空?
1. 导读
我们都知道,HashMap 是我们在面试过程中经常被问到的一个点,而与 HashMap 并存的一个,就是 ConcurrentHashMap,它与HashMap最大的区别就是能在多线程的情况下保证线程安全,下面就从源码角度深入探究一下 ConcurrentHashMap 底层到底是什么样的,又是如何实现线程安全的。本贴难度会稍微高一些,建议各位在学习ConcurrentHashMap 源码之前,可以先学会看懂 HashMap 的底层源码逻辑,再来学习 ConcurrentHashMap ,这样会轻松非常多,因为它们两个本就差不多,主要是 ConcurrentHashMap 主要是能保证线程安全,在这里我会说的尽可能详细,代码的注释也都会标注清楚。
还有一篇文章讲的是 HashMap 的源码,各位同学有兴趣可以结合观看
HashMap 底层源码深度解读_程序猿ZhangSir的博客-CSDN博客![]() https://blog.csdn.net/m0_70325779/article/details/132015542?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_70325779/article/details/132015542?spm=1001.2014.3001.5501
2. ConcurrentHashMap 成员变量解读
在解读源码之前,有很多关键的变量需要各位记住,这些都是 ConcurrentHashMap 源码类中的一些重要属性,我已经列出来了,各位同学可以结合自己电脑上的IDEA源码结合观看,注释如下
// 这里1左移30位,表示 数组最大容量MAXIMUM_CAPACITY 为 2^30 即2的30次方,
// 这个容量与 HashMap 的最大容量是一样的
private static final int MAXIMUM_CAPACITY = 1 << 30;// DEFAULT_CAPACITY = 16 表示的就是默认的数组初始容量为16
// 默认初始容量与HashMap的默认初始容量一样,都为16
private static final int DEFAULT_CAPACITY = 16;// 这里LOAD_FACTOR 指加载因子为0.75,即当数组中加入的数据超过了当前容量的0.75倍时,
// 要进行数组的扩容,这一点与 HashMap 是一样的,加在因子都是0.75
private static final float LOAD_FACTOR = 0.75f;// table 就是我们 ConcurrentHashMap 底层真正存贮数据的那个数组,名为table
// HashMap 底层的数组名字也叫 table,这个倒是无关大雅
transient volatile Node<K,V>[] table;// 这个变量代表了数组的阈值长度64
static final int MIN_TREEIFY_CAPACITY = 64;// 这个变量代表了链表的长度阈值8,与上面的64紧密配合
// 当链表的长度大于8且数组的长度大于64,就会把链表树化,提高查找效率
// 这个转换成树的时机与HashMap 一样,都是数组长度大于等于64并且链表长度大于等于8时
// 链表转换成红黑树结构
static final int TREEIFY_THRESHOLD = 8;
sizeCtl 属性解读
想要读懂 ConcurrentHashMap 的源码,sizeCtl这个变量非常关键,所以我把它单独拿出来,在源码的很多方法中都会发现它的身影,一定一定一定要记住,这里我大致总结了 sizeCtl 的几种情况
(1)sizeCtl 为0,代表数组未初始化,且数组的初始容量为16;
(2)sizeCtl 为正数,如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么记录的是数则的扩容阈值;
(3)sizeCtl 为 -1,表示数组正在进行初始化;
(4)sizeCtl 小于0,并且不是 -1,表示数组正在扩容,-(1+n),表示此时有n个线程正在共同完成数组的扩容操作。
3. ConcurrentHashMap 初始化
我们知道,在初始化对象的时候,可以采用无参构造创建对象,ConcurrentHashMap 也一样,可以使用空参构造不设置初始容量,也可以使用带参构造设置初始容量。
3.1 ConcurrentHashMap 无参构造源码解读
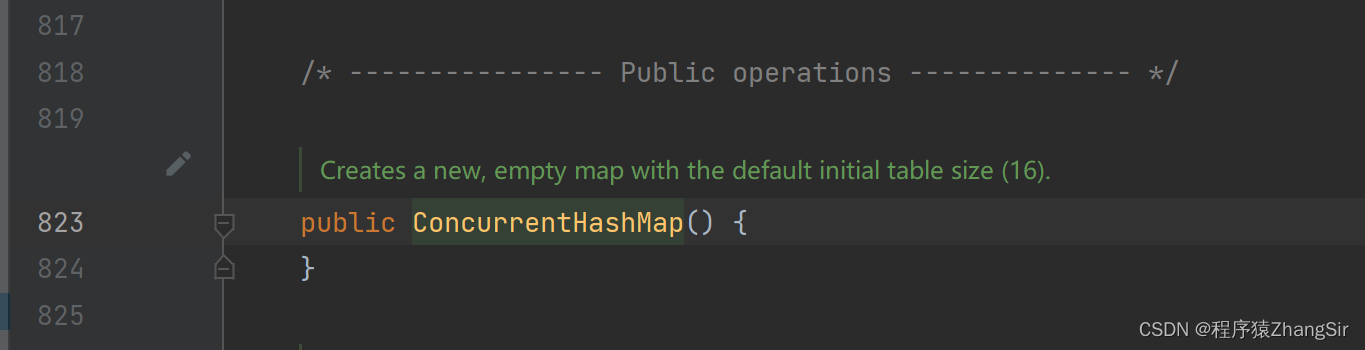
从无参构造源码也可以看出,在 ConcurrentHashMap 无参构造方法中,它没有做任何的动作;也就是说,采用无参构造创建 ConcurrentHashMap 时,底层并没有创建数组对象。(这里补充一点,创建数组对象的动作是在后续进行 put 操作添加元素时创建的,后面会说到)。
初始化源码上方有一句话,翻译过来就是"创建一个新数组,数组默认长度为16",也对应了上面我说到的,默认初始容量为16。
3.2 ConcurrentHashMap 带参构造源码解读
如下为 ConcurrentHashMap 的有参构造方法,设置一个初始容量
// 这里 initialCapacity 就是我们传入的初始容量
public ConcurrentHashMap(int initialCapacity) {
// 先做了一步判断,判断传入的初始值是否小于0,if (initialCapacity < 0)
// 若小于0抛出异常throw new IllegalArgumentException();
// 代码走到这里,说明初始容量大于等于0,三元运算符做进一步逻辑运算
// (initialCapacity >= (MAXIMUM_CAPACITY >>> 1))
// 三元运算是在判断我们传入的初始容量是否大于等于最大容量的一半,
// 若大于最大容量的一半,则初始化容量为最大容量;
// 若不大于一半,执行tableSizeFor方法计算出初始容量int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?MAXIMUM_CAPACITY :
// 运行下面这一行说明初始容量小于最大容量的一半,通过 tableSizeFor 方法计算出初始容量tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
// 将计算出来的结果赋值给 sizeCtl,这个sizeCtl 需要记住,后面还会提到this.sizeCtl = cap;}3.3 tableSizeFor 方法作用解读
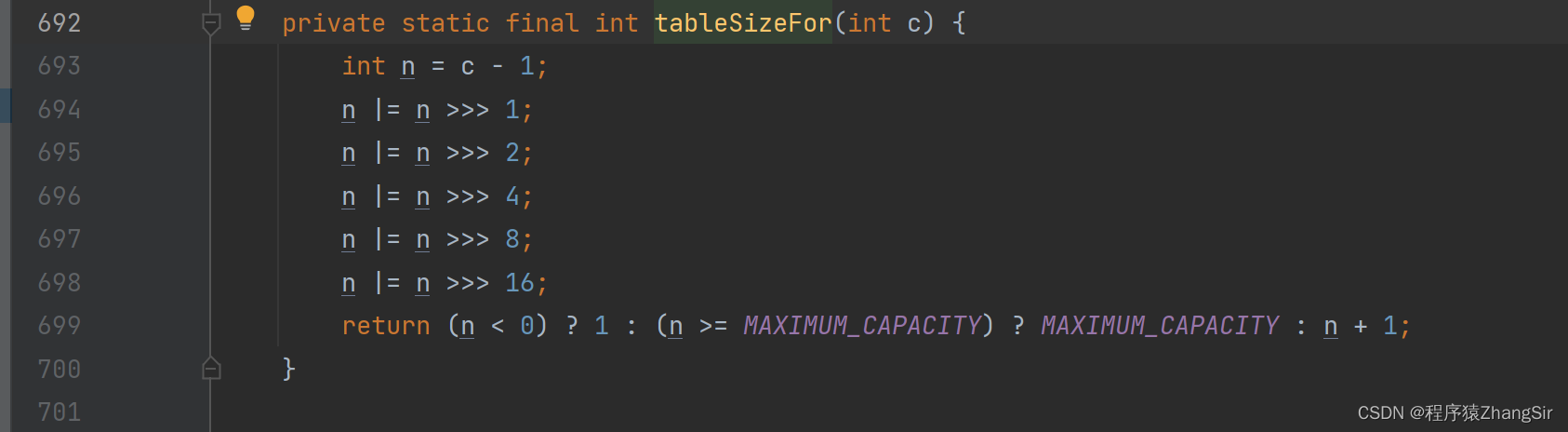
这个方法可能大家看不太懂,我就这么说吧,这个方法的目的是返回一个 2的整数次幂的数。如2^4 = 16,2^5 = 32,2^6 = 64。
结合上述扩容方法和 tableSizeFor 方法,我们可以知道,当我们传入一个初始值的时候,实际计算出的结果是 (传入的值+传入值的一半+1)的结果向上取整并且必须是2的整数次幂,说到这里,各位应该明白了吧.
如果我们时传入的是32,那么计算出的初始容量就是 32 + 16 + 1 = 49,49不是2的整数次幂,向上取整最小为 64,所以初始容量为64而不是我们传入的32;
如果我们传入的是16,那么计算出的结果就是 16 + 8 + 1 = 25,25不是2的整数次幂,向上取整在最小为32,所以计算出的初始容量为32而不是我们传入的16;
3.4 ConcurrenthashMap初始化总结
总结上面的初始化源码分析,我们可以得到以下结论。
(1)ConcurrentHahMap 采用无参构造在底层什么都没有做,真正创建数组是在 put 第一个元素扩容的时候才创建数组的。
(2)ConcurrentHashMap 带参构造中如果我们传入的初始容量大于等于最大容量的一半,则实际集合容量会使用最大容量 2^30 ;如果传入的初始容量小于集合最大长度的一半,则实际计算出的容量是(传入的值 + 传入值的一半 + 1)的结果向上取整并且必须是2的整数次幂。例如传入32,是计算出的容量是64而不是32。
4. ConcurrentHashMap 添加元素方法解读
ConcurrenthashMap 添加元素需要调用 put 方法,下面我们就详细分析 put 方法的原理。
4.1 put 源码解读
ConcurrentHashMap 的put添加方法源码如下,这里 put 方法调用了一个 putVal 方法,没有做别的事情,下面跟进查看 putVal 方法源码
public V put(K key, V value) {return putVal(key, value, false);}4.2 putVal 方法解读
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 这里判断key和value是否有空值存在,若有则抛出异常if (key == null || value == null) throw new NullPointerException();
// 这里对 key 做了一系列哈希运算得到key的一个哈希值int hash = spread(key.hashCode());
// binCount 与后面数据长度的维护有关,这里暂时不用关心int binCount = 0;
// 这里的 for 循环是一个死循环,只要不进行break,会一直循环
// ConcurrentHashMap底层数组名字叫 table,然后将table赋值给对象tabfor (Node<K,V>[] tab = table;;) {
// 创建一个节点对象 f,定义 n,i,fh 三个变量Node<K,V> f; int n, i, fh;
// 这里对tab做判空操作或长度为0的判断,if (tab == null || (n = tab.length) == 0)
// 如果为空或者长度为0,进行数组初始化,执行 initTable 方法
// 下面4.3 单独会说到 initTable 初始化方法tab = initTable();
// 执行到这里,说明数组不为空,计算待加入的元素应该存放的位置是否为空,else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 进到 if 里面,说明要添加的位置为空,但为了避免线程添加冲突
// 使用 CAS自旋操作,因为有可能别的线程也正在此处添加元素,
// 要保证线程的安全性,不能冲突,如果有两个线程,只有一个会添加成功,另一个会添加失败
// 另一个线程添加失败,就会重新执行判断,此时此处不为空,就会向下执行判断if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
// 其中一个线程添加成功,break退出循环,完成添加操作break; // no lock when adding to empty bin}
// 这里做判断,如果为 true,说明数组正在进行扩容,然后协助其他线程完成扩容操作else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);
// 如果上面都不是,说明数组既没有扩容,也不是空数组,而且要插入的位置已经有元素
// 就遍历链表中的每个节点或者树中的每个节点else {V oldVal = null;
// 此处锁的是链表的的节点,或者是树的根节点,锁粒度小,提高了并发能力synchronized (f) {
// 这里需要再次做一下判断,
//多线程情况下,可能其他线程添加完数据后可能会恰好链表转化成了树,或者红黑树根节点发生了旋转
// 因此要多做一步判断很有必要if (tabAt(tab, i) == f) {if (fh >= 0) {
// 这里的binCount记录的是链表的长度,若链表长度大于8可能会链表转化为树binCount = 1;
// 从这里开始,遍历链表,将链表中的每一个元素与待插入的元素做比较for (Node<K,V> e = f;; ++binCount) {K ek;
// 对链表中其他节点的key做是否相同的判断if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {
//若有相同则将老的元素进行替换,并赋值给 oldVal return返回oldVal = e.val;if (!onlyIfAbsent)e.val = value;
// break 退出循环,添加操作结束break;}Node<K,V> pred = e;
// 对当前节点的下一个节点做判空操作if ((e = e.next) == null) {
// 满足下一个节点为空,则将新前节点插入在当前节点的下方pred.next = new Node<K,V>(hash, key,value, null);
// 插入操作完成,break 退出循环。break;}}}
// 若执行到这里,说明不在链表中,则遍历树,看看树中的每一个元素是否与待插入的元素相等
// 这个树的判断操作就比较复杂了,这里不详细说明,和链表相似,相同则替换,不同则插入
// 有想了解红黑树的插入规则的,可以点我首页往下寻找红黑树那一篇帖子else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}
// 这里的 binCount 就是数据插入完成之后的链表的长度
// 然后对数组中链表的长度做一个判断,先判断是否为0
// 不为0,则数值为插入后链表的长度,再判断是否大于等于8
// 如果满足链表的长度大于等于8,还要在 treeifyBin 方法中进一步判断数组的长度是否大于等于 64
// 如果满足数组长度大于等于64并且链表的长度大于等于8,链表会转化成红黑树,这里就不展开了if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);
// 这里的 oldVal 就是被替换掉的老的元素,听名字也能看出来
// 对 oldVal 做判空操作,如果为空,则表示数组中之前没有添加过当前元素
// 如果不为空,将这个老的被替换掉的元素的值返回if (oldVal != null)return oldVal;break;}}}
// 这里会对数组的长度做一个维护,保证多线程下数组长度的安全性,
// 下面第专门讲到,addCount(1L, binCount);return null;}3.3 initTable 初始化方法解读
ConcurrentHashMap 在调用 put 方法添加第一个元素的时候,底层就会去做初始化,在上面 putVal 放啊中也有做简单说明,初始化数组执行的就是下面这个方法,各位同学可以简单看一看该方法中的每一步,我都做了注释
private final Node<K,V>[] initTable() {
// 创建数组对象 tab,定义变量 sc;Node<K,V>[] tab; int sc;
// 对数组做判空操作,长度判断是否为0while ((tab = table) == null || tab.length == 0) {
// 这里将sizeCtl变量的值赋值给sc判断是否小于0,if ((sc = sizeCtl) < 0)
// 若小于0表明数组正在扩容或正在进行初始化,调用 Thread.yield 方法,
// 让线程释放CPU资源,一直得到一直释放,做自旋操作,直到其他的线程初始化完成Thread.yield(); // lost initialization race; just spin
// 做判断,判断 sc 和 sizeCtl是否是相等的,
// 如果相等,把 sizeCtl赋值为 -1,说明去进行初始化数组了else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {
// 再次对数组做判空操作,因为有可能之前有现成已经进行初始化,这里在此作判断,防止重复初始化if ((tab = table) == null || tab.length == 0) {
// 对sc做判断,sc如果大于0,取我们算出来的sc,如果不大于0,赋值默认初始容量int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")
// new 了一个新的数组,长度为刚才得到的nNode<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将 new 出来的数组nt赋值给 tab 再赋值给底层数组 tabletable = tab = nt;
// 加算出数组长度的0.75倍并赋值给sc,下次sc达到这个值,就会进行扩容sc = n - (n >>> 2);}} finally {
// 将计算出来的 sc 赋值给 sizeCtlsizeCtl = sc;}
// 退出循环break;}}
// 返回得到的数组 tabreturn tab;}
4.4 put 添加元素方法总结概括
通过上面的了解,我们大致可以知道 ConcurrentHashMap 在进行put操作添加元素时是什么样的一个过程,我大致总结了以下几点
(1)ConcurrentHashMap 在进行put 操作时,若数组采用无参构造创建,在 put 第一个元素时会先进行扩容,默认容量为16;
(2)ConcurrentHashMap 在进行 put 操作时,采用了 CAS自旋,循环,锁每个链表头节点数根节点的方式保证了添加元素时的线程安全性;
(3)添加元素时,ConcurrentHashMap 锁锁的是每个链表的头节点或者是树的根节点,它只是锁了当前的哈希桶,对其它元素添加到其他哈希桶的操作并没有任何影响,打个比方就是你要添加的数据位于哈希值为1的地方时,它只会锁住哈希值为1处的桶,不会锁住其他哈希值的桶位,它不像 HashTable 那样将整个数组锁起来,这样极大地提高了操作元素的效率;
(4)在添加元素完成之后,数组会去做一个判断,若数组的长度大于64并且链表的长度8时,会把链表进行树化,提高数据的查找效率,这一点与 HashMap 树化的操作类似;
(5)判断完是否需要树化的操作之后,还会判断添加的元素是否已经存在,如果存在会把原来的元素的Value值覆盖为新添加的元素的Value值,并返回被覆盖的Value值。
(5)做完上面的步骤之后,最后调用addCount 方法对数组的长度进行维护。
5. ConcurrentHashMap 树化操作何时进行?
在上面 putVal 方法中,犹如下一步判断,binCount 代表插入插入元素之后链表的长度,这里如果 binCount 大于等于8,就会执行 treeifyBin 方法
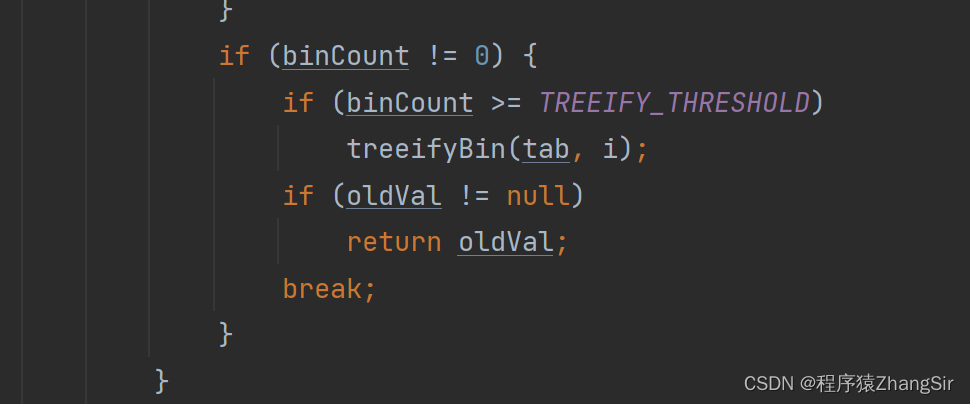
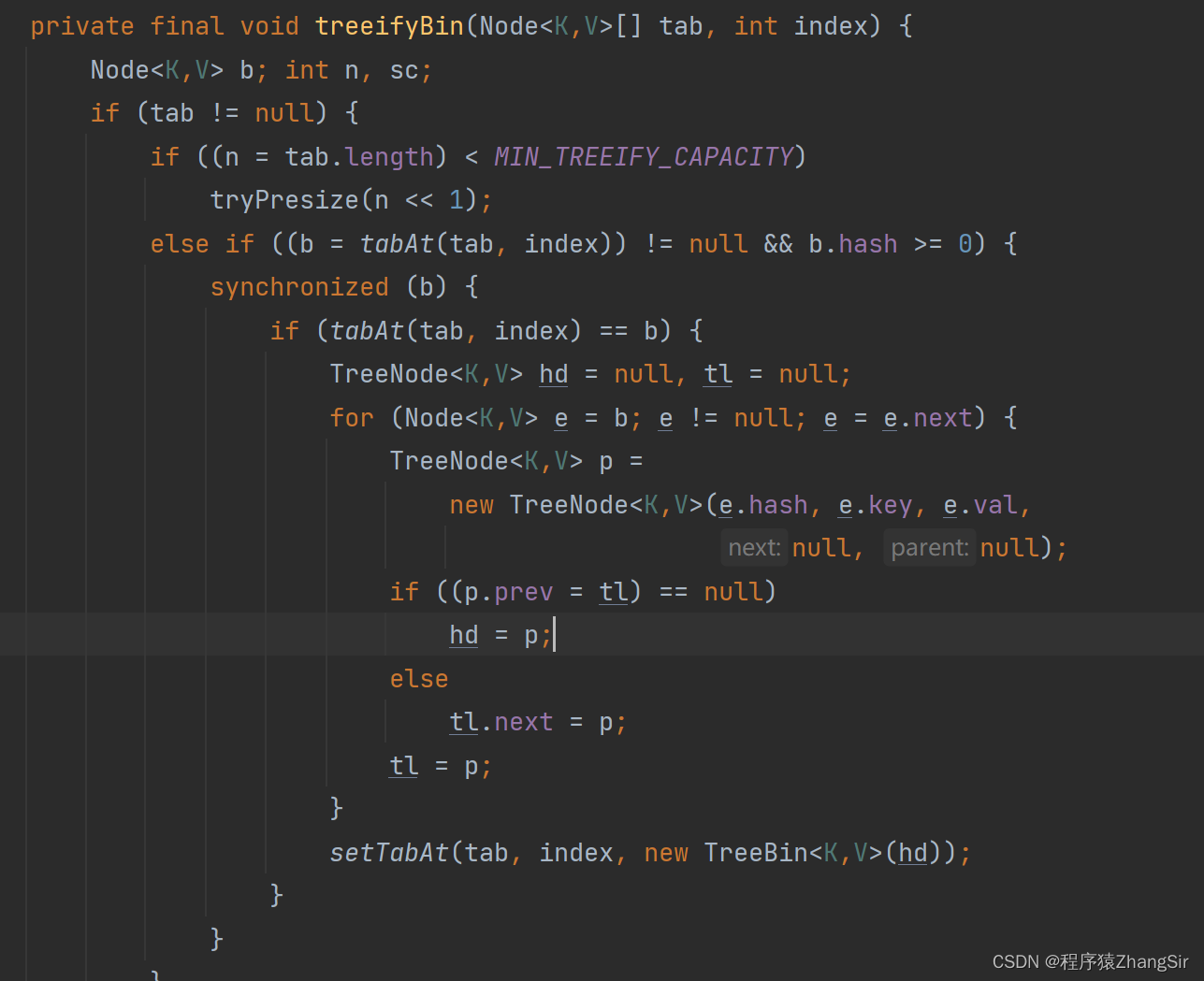
在下面 treeifyBin 方法中,记住一点即可。在链表长度大于等于8之后,还要满足数组的长度大于等于64,链表才会转化成红黑树。
6. ConcurrentHashMap 数组长度维护解读
刚才在分析 ConcurrentHashMap 的 put 操作的时候,可以看到,进行完 put 操作之后,会调用一个 addCount() 方法,这个方法就是对数组的长度做一个维护。
当多个线程同时来做插入操作时,数组长度的维护也会出现线程安全问题,我先来说一下原因,刚才上面提到了,再插入元素的时候。我们利用自旋+锁住链表头节点的方式保证线程安全。但是在添加完成数据之后,有可能不同的桶位同时添加完成要对数组长度做++操作,此时就会出现线程安全问题。
其实本身多个线程对数组长度做++的操作也可以同样利用自旋来完成,但是在多线程的情况下,采用自旋的方式效率仍然还是低一些,但是为了提高效率,它采用了另外一种做法;在 ConcurrentHashMap 内部,它还维护了另外一个普通数组,如下图所示的 CounterCell 数组,
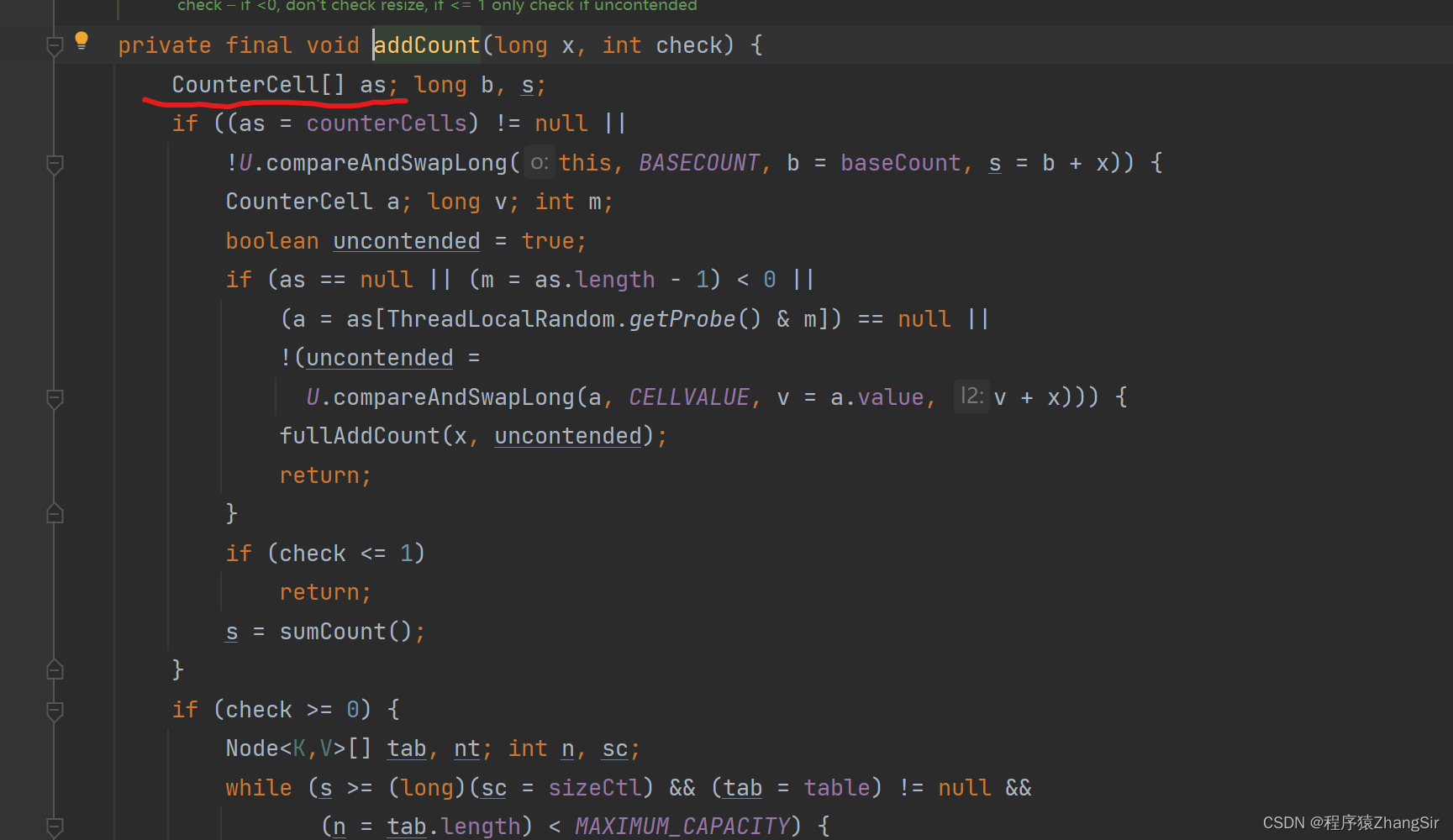
我给大家说一下这种做法的原理。
假设现在有三个线程都完成了数据添加操作,同时要对数组长度做++操作,那么肯定会线程冲突,利用CAS自旋三个线程会去竞争谁先去++操作。假设第一个线程先执行了++操作,那么第二个线程和第三个线程都会做另外一个操作。它们会先获取各自线程的随机值,然后通过特殊的计算方法的得出一个数值,该数值对应着上面的 CounterCell 数组的位置,完成计算步骤的出对应数值之后,第二个第三个线程就会分别去 CounterCell 数组中各自对应的做++操作,如果添加成功,就算完成数组长度的维护操作。如果有第三个线程和第二个线程需要在同一个位置的 value 做++操作,产生了冲突,此时才会再去采用自旋的方式让其中一个线程重新获取新的线程随机值,再重新计算该往数组中的哪个位置的 value 做++操作。
7. ConcurrentHashMap 键和值能否为空?
这算是一个小的细节面试题;
如下为 putVal 源码的一部分,在这里可以看到,在put 元素之前,它会先对 key 和 value 做非空判断,只要有一个是控制,就会爆出空指针异常,所以 ConcurrentHashMap 是不能存控制的。