大家好,我是蓝胖子,前段时间线上elasticsearch集群遇到多次wildcard产生的性能问题, elasticsearch wildcard 一直是容易引发elasticsearch 容易宕机的一个风险点, 但究竟它为何消耗cpu呢?又该如何理解elasticsearch profile api的返回结果呢?在探索了部分源码后,我将在这篇文章一一揭晓答案。
学完这篇文章,你可以学到如下内容:

首先,我们来看下elasticsearch的查询过程,elasticsearch 底层是使用lucece来实现数据的存储与搜索,你可以简单的理解为elasticsearch 为lucece提供了分布式存储的能力,lucece只能单机存储。
所以,理解elasticsearch查询过程分为两部分,第一是elasticsearch 如何使用lucece进行查询,第二是lucece本身是如何进行查询的。
elasticsearch查询流程
elasticsearch 的查询简单来说可以分为两部分,第一步称为query通过调用lucece查询的api获取符合条件的文档id,第二步称为fetch阶段,再通过文档id,向lucece获取原文档内容。所以宏观上看对于elasticsearch 的慢查询,要么是query阶段慢,要么是fetch阶段慢。
lucece 查询流程
对于fetch阶段没有多的可讲,即用文档id在lucece正排索引中获取原文档内容。我们着重分析下query阶段,即lucece是如何进行文档id搜索的。
在使用lucece 搜索时,通常是构造一个lucece的indexsearcher 对象,通过调用indexsearcher对象的search方法实现搜索,代码如下:
Query query = new WildcardQuery(new Term("body", "m*tal*"));
ScoreDoc[] result = searcher.search(query, 1000).scoreDocs;
socreDoc是封装了文档id和搜索得分的类型,代码如下,
public class ScoreDoc { /** The score of this document for the query. */ public float score; /** * A hit document's number. * * @see StoredFields#document(int) */ public int doc; /** Only set by {@link TopDocs#merge} */ public int shardIndex;
而整个search的流程可以总结为以下几个阶段,
1,重写(rewrite)query 类型。
2, 创建weight对象。
3,创建bulksocre对象。
4, 调用bulkscore.score方法,进行文档算分。
为了对下面分析的阶段更加深刻,我将search 方法代码粘贴到这下面,
public <C extends Collector, T> T search(Query query, CollectorManager<C, T> collectorManager) throws IOException { final C firstCollector = collectorManager.newCollector(); query = rewrite(query, firstCollector.scoreMode().needsScores()); final Weight weight = createWeight(query, firstCollector.scoreMode(), 1); return search(weight, collectorManager, firstCollector);
}
接着,我们依次来看下这几个阶段。
rewrite query
lucece中每个查询类型都继承自org.apache.lucene.search.Query 这个抽象类,在每个查询各自的实现中可以覆盖其中的rewrite方法,来将原本的复杂查询转换为更底层的查询类型。比如wildcard query 查询类型会被rewrite 修改为MultiTermQueryConstantScoreWrapper,MultiTermQueryConstantScoreBlendedWrapper或其他查询类型,具体取决于elasticsearch 执行wildcard查询时指定的rewrite类型。
在lucece执行search方法内部执行rewrite时实际就是在调用查询类型Query的rewrite方法。
createWeight
接着lucece的search方法会调用createWeight方法产生一个weight对象,createWeight 本质上也是对Query类型的createWeight方法的调用,weight对象的作用是计算查询的权重以及构建打分score对象。
elasticsearch 会为每个查询匹配的文档进行打分,分数越高的文档就会排在前面,打分时也会考虑查询条件的权重,权重越高,分数越高。
计分阶段
像前面提到的search 方法源码那样, 接着又会调用一个重载的search方法来进行search阶段的最后的步骤
return search(weight, collectorManager, firstCollector);
在这个search方法里,lucece会判断会不会对索引的多个段segment采用多线程方式搜索。
lucece的每个段segment是可以单独被搜索的,多线程搜索的结果最后会由collecotor对象通过reduce方法进行合并。这里就不展开了,我们着重关注下,lucece是如何对每个段进行搜索的。
第一步则是由前面的weight 对象通过bulkScorer 获得一个bulkScore对象。
BulkScorer scorer = weight.bulkScorer(ctx);
bulkScore 对象顾名思义,批量打分,这个对象将会对筛选出来的文档进行批量打分。
所以紧接着第二部便是调用bulkScore的score方法进行批量打分,
scorer.score(leafCollector, ctx.reader().getLiveDocs());
批量打分的结果会被leafCollector 收集起来。
lucece 查询过程时是在哪个阶段查询匹配文档的?
在了解了lucece的整体查询过程后,你可能还对lucece是在哪个阶段进行文档筛选的感到疑惑,所以我准备单独讲下这部分。
要了解这部分主要就是要了解weight.bulkScorer和scorer.score的细节,因为查询逻辑就封装在里面。
weight.bulkScorer 创建了BulkScore,bulkScore由scorer,DocIdSetIterator,TwoPhaseIterator 3个对象构成。
scorer 对象是由weight创建的,封装了打分的规则。
DocIdSetIterator ,TwoPhaseIterator用于遍历匹配的文档,它们是scorer对象的两个属性,在遍历匹配文档时,一般它们只有一个有值。
无论是DocIdSetIterator 还是TwoPhaseIterator ,它们都拥有共同的方法迭代文档的方法,next() 用于遍历到下一个文档,advance方法用于跳过某些文档,match()方法则是专门在TwoPhaseIterator 进行二次匹配判断时用到的。
TwoPhaseIterator特别用于说明此次遍历是二次遍历,比如PhraseQuery 类型的查询,lucece 是先将满足所有给定查询的term对应的文档筛选出来,然后再进行二次遍历看文档的term相对位置是不是满足查询条件的短语位置。
所以针对 lucece 查询过程时是在哪个阶段查询匹配文档的?这个问题,要区分不同的查询类型。由于我仅仅看了部分查询源码,这里直接说下phraseQuery 类型和wildcardQuery 类型查询文档各自在什么阶段。
phraseQuery
在createWeight方法调用时,此时会进行第一次查询,通过给定的phrase短语拆分成term后,找出包含所有term的文档集合。
然后在scorer.score 方法内,会对文档集合进行二次遍历得到最终符合条件的文档集合。
wildcardQuery
由于wildcardQuery会被重写,这里我用默认的重写类MultiTermQueryConstantScoreWrapper举例,它会在weight.bulkScorer 调用时遍历 查询字段所有的term,传入提前创建好的有限状态机(有限状态机是在构建wildcardQuery对象时创建的)进行匹配,如果匹配成功,则说明文档符和查询条件。最后将文档id集合构建成一个DocIdSetIterator对象作为scorer对象的属性用于后续的遍历。
所以在scorer.score方法里遍历的对象就是在weight.bulkScorer 方法里创建的DocIdSetIterator对象。
关于wildcardQuery 有限状态机的原理将不会在这节展开,但是你需要知道的是lucece中最终是将用户输入的模式匹配字符串构建成了DFA(确定性有限状态机),它的时间复杂度是O(2^n),n输入的字符串长度,所以这也是为什么模式匹配字符串越长,wildcardQuery消耗时间越长的原因之一,且构建过程十分消耗cpu资源。
其次,构建的状态机需要和索引中该字段的所有的term去进行比较匹配,这在term数量比较大时也会出现wildCardQuery缓慢的情况。
elasticsearch profile api
profile api 实现原理
elasticsearch 提供了profile 参数配置可以在查询的时候设置为true来得到查询的分析结果,也可以在kibana的dev tools 界面直接使用profile功能。
而profile api能够实现的原理则是通过装饰器模式,通过包装lucece原有的的weight,scorer,searchindexer类型,然后在前面提到的创建scorer方法,DocIdSetIterator的advance,next,TwoPhaseIterator的match方法前后加上埋点信息统计耗时时间。
查询结果分析
最后,我们着重来看下profile的返回结果,这里我用kibana的界面返回结果举例。
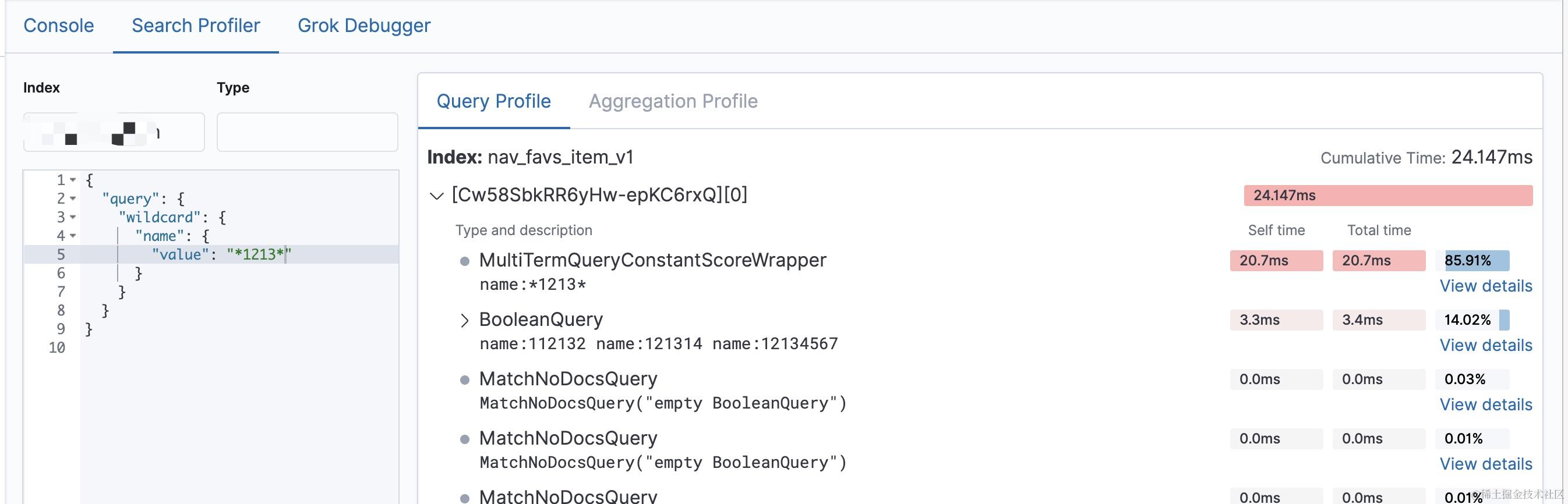
profile 返回的结果列出了被重写后的查询,每个查询耗时情况,而单个的查询各个阶段的耗时情况也被列举了出来。
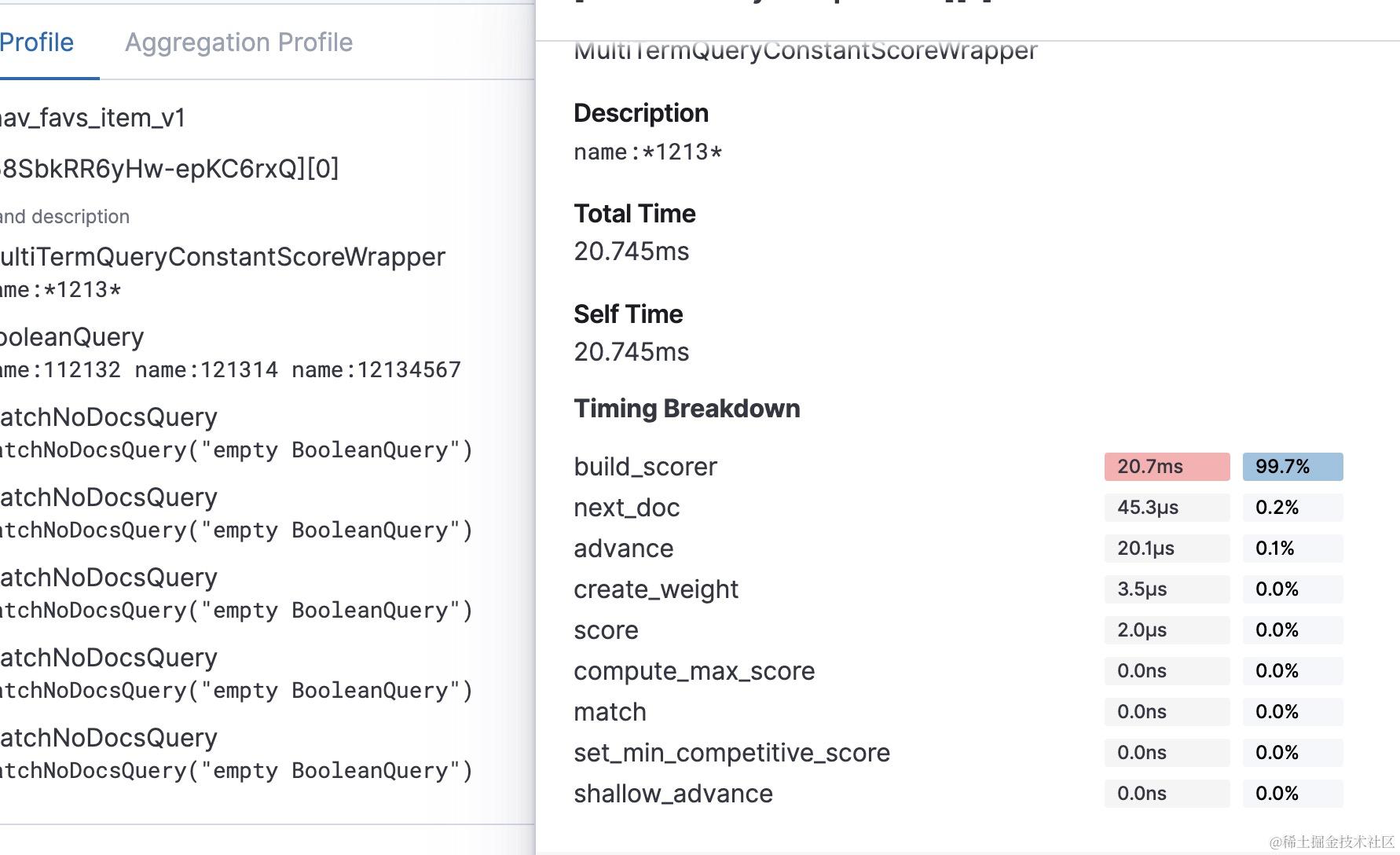
像wildCardQuery的查询主要耗时在build_scorer 阶段,正如前面提到的那样,wildCardQuey 查询在执行weight.bulkScorer 时会遍历查询字段所有的term 传入状态机进行匹配,这个过程是比较耗时的,生产上还是慎用,我们生产上3亿多的数据,用wildcard 查询一个匹配 *abc* 的字符串需要6,7s 。慢也是慢在build_scorer, 其次需要注意的是构建状态机的耗时没有出现在profile的返回结果里,当模式匹配字符串很长时,构建自动状态机也是很消耗cpu的,一般还是要限制模式匹配字符串的长度。
profile 结果中返回的其他阶段, 例如next_doc ,advance 则是在scorer.score 方法内部调用文档迭代器进行迭代时,调用的方法。
create_weight 是创建weight对象时需要调用的,像phraseQuery 在create_weight还进行了第一次文档查询,所以针对phraseQuery而言,可能整个过程中,最耗时的就是create_weight阶段。
score是对最后匹配的文档进行打分时需要调用的方法,match 则是二次匹配时需要调用的方法,其余3个方法耗时,compute_max_score,set_min_competive_score,shallow_advance 具体在什么场景下会被调用就没有深入研究了,等碰到耗时比较高的情况可以再去翻源码查看。