1.VGG
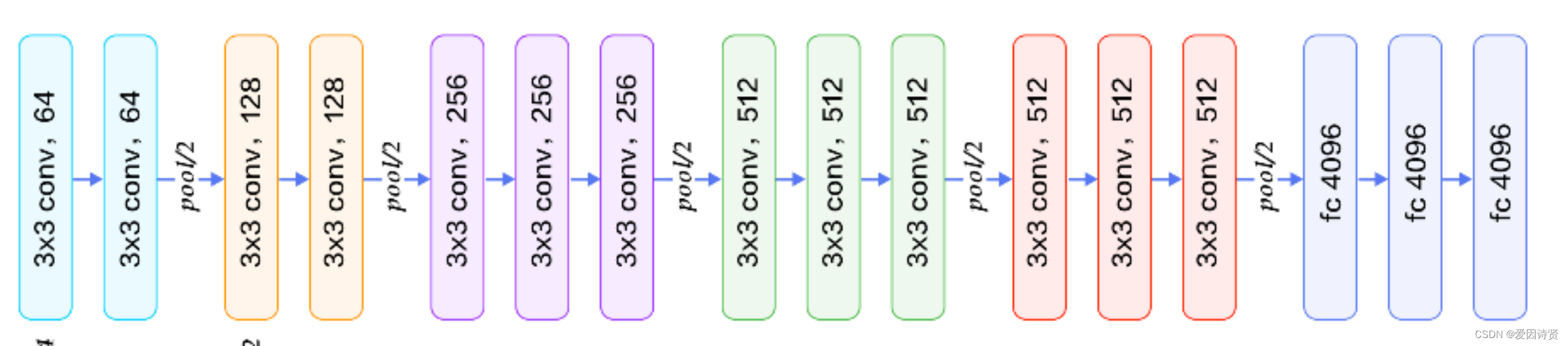
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,VGG的输入被设置为大小为224x244的RGB图像。为训练集图像上的所有图像计算平均RGB值,然后将该图像作为输入输入到VGG卷积网络。使用3x3或1x1滤波器,并且卷积步骤是固定的。有3个VGG全连接层,根据卷积层+全连接层的总数,可以从VGG11到VGG19变化。最小VGG11具有8个卷积层和3个完全连接层。最大VGG19具有16个卷积层+3个完全连接的层。此外,VGG网络后面没有每个卷积层后面的池化层,也没有分布在不同卷积层下的总共5个池化层。
结构图如下:
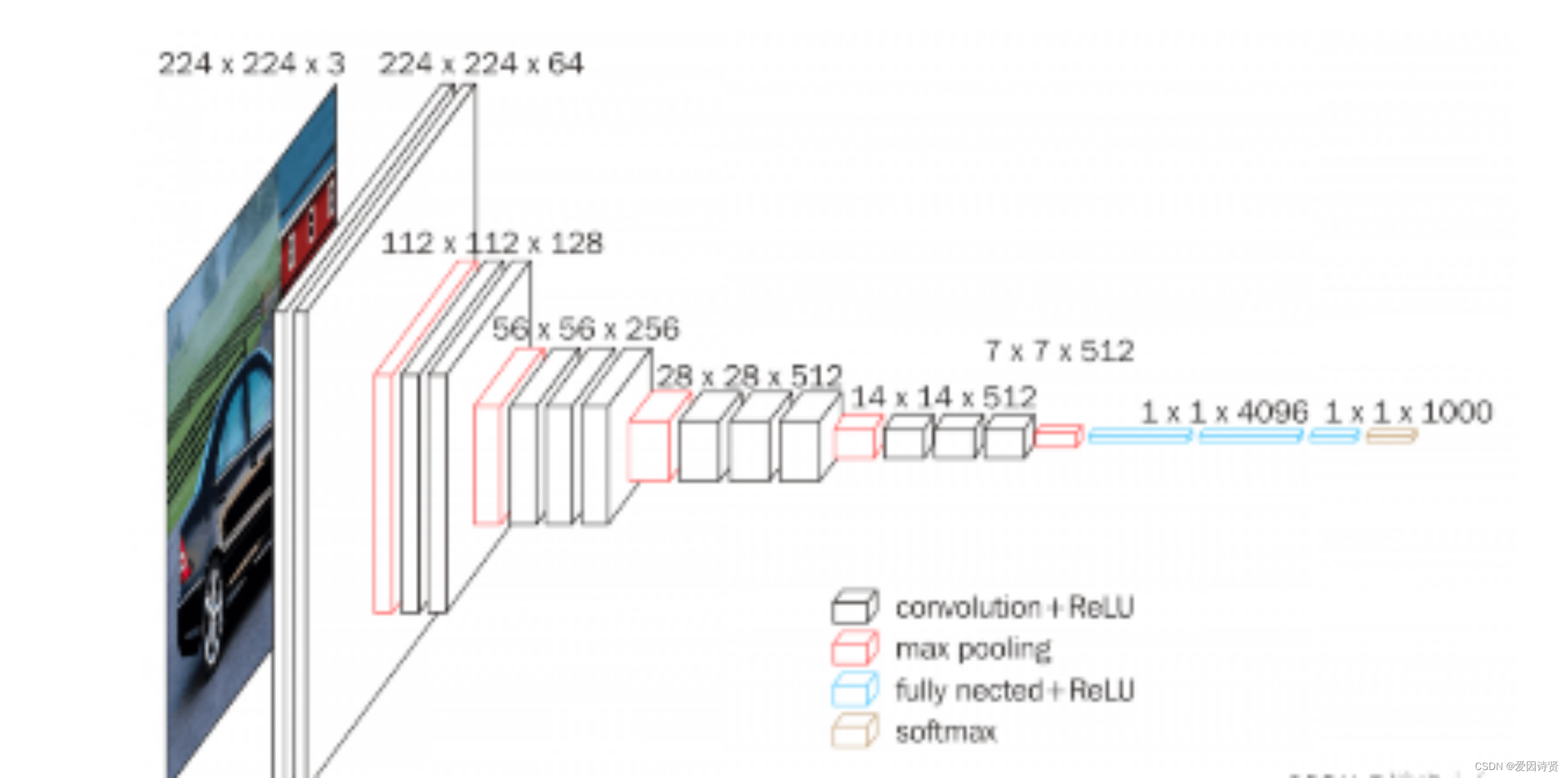
架构图
2.Unet模型:
Unet是一个优秀的语义分割模型,其主要执行过程与其它语义分割模型类似。与CNN不同的之处在于CNN是图像级的分类,而unet是像素级的分类,其输出的是每个像素点的类别
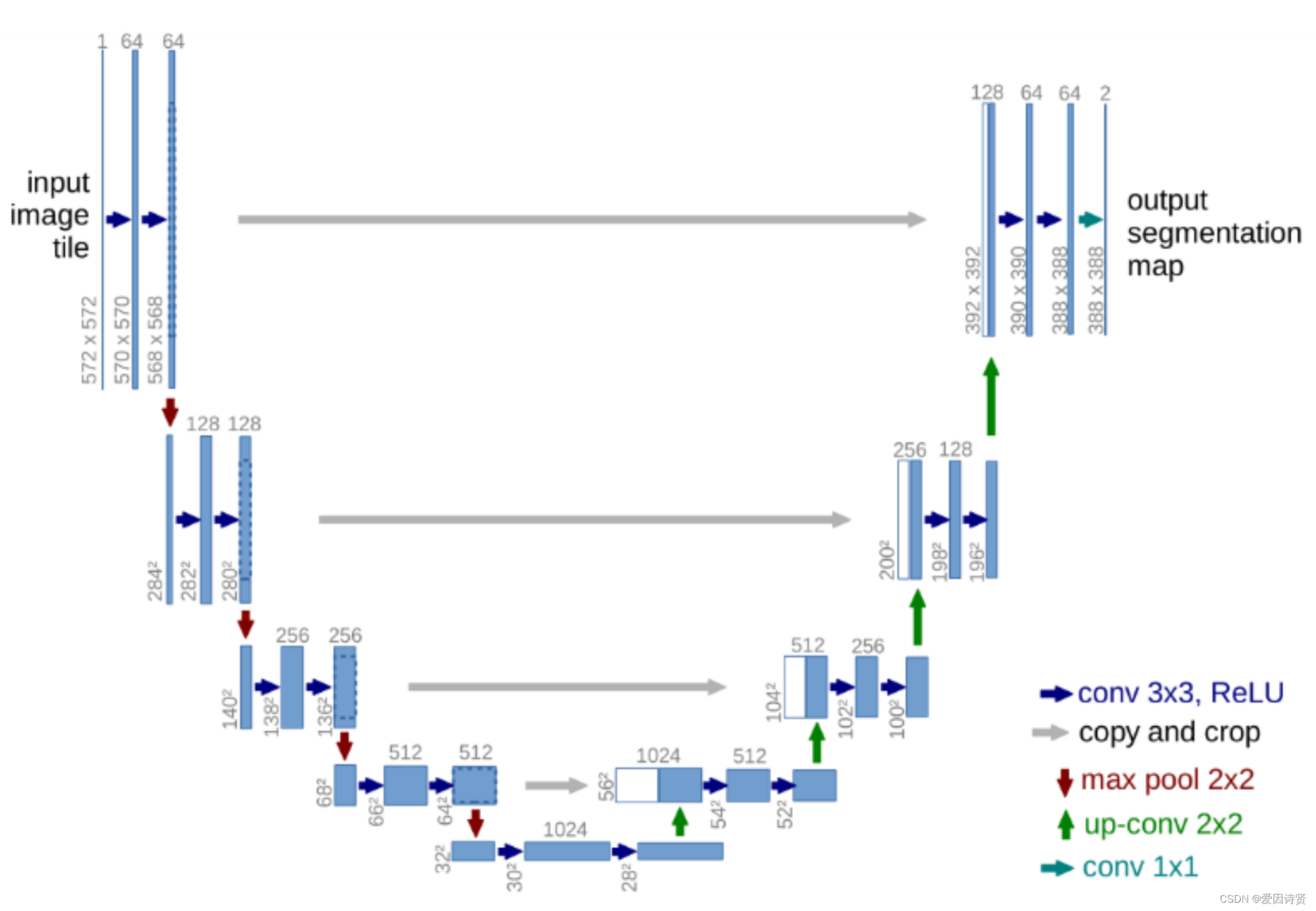
主要代码如下:
def get_vgg_encoder(input_height=224, input_width=224, channels=3):if channel == 'channels_first':img_input = Input(shape=(channels, input_height, input_width))elif channel == 'channels_last':img_input = Input(shape=(input_height, input_width, channels))x = Conv2D(64, (3, 3), activation='relu', padding='same',name='block1_conv1', data_format=channel)(img_input)x = Conv2D(64, (3, 3), activation='relu', padding='same',name='block1_conv2', data_format=channel)(x)x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool',data_format=channel)(x)f1 = x# Block 2x = Conv2D(128, (3, 3), activation='relu', padding='same',name='block2_conv1', data_format=channel)(x)x = Conv2D(128, (3, 3), activation='relu', padding='same',name='block2_conv2', data_format=channel)(x)x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool',data_format=channel)(x)f2 = x# Block 3x = Conv2D(256, (3, 3), activation='relu', padding='same',name='block3_conv1', data_format=channel)(x)x = Conv2D(256, (3, 3), activation='relu', padding='same',name='block3_conv2', data_format=channel)(x)x = Conv2D(256, (3, 3), activation='relu', padding='same',name='block3_conv3', data_format=channel)(x)x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool',data_format=channel)(x)f3 = x# Block 4x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block4_conv1', data_format=channel)(x)x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block4_conv2', data_format=channel)(x)x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block4_conv3', data_format=channel)(x)x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool',data_format=channel)(x)f4 = x# Block 5x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block5_conv1', data_format=channel)(x)x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block5_conv2', data_format=channel)(x)x = Conv2D(512, (3, 3), activation='relu', padding='same',name='block5_conv3', data_format=channel)(x)x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool',data_format=channel)(x)f5 = xreturn img_input, [f1, f2, f3, f4, f5]def _unet(classes, encoder, l1_skip_conn=True, input_height=416,input_width=608, channels=3):img_input, levels = encoder(input_height=input_height, input_width=input_width, channels=channels)[f1, f2, f3, f4, f5] = levelso = f4o = (ZeroPadding2D((1, 1), data_format=channel))(o)o = (Conv2D(512, (3, 3), padding='valid' , activation='relu' , data_format=channel))(o)o = (BatchNormalization())(o)o = (UpSampling2D((2, 2), data_format=channel))(o)o = (concatenate([o, f3], axis=-1))o = (ZeroPadding2D((1, 1), data_format=channel))(o)o = (Conv2D(256, (3, 3), padding='valid', activation='relu' , data_format=channel))(o)o = (BatchNormalization())(o)o = (UpSampling2D((2, 2), data_format=channel))(o)o = (concatenate([o, f2], axis=-1))o = (ZeroPadding2D((1, 1), data_format=channel))(o)o = (Conv2D(128, (3, 3), padding='valid' , activation='relu' , data_format=channel))(o)o = (BatchNormalization())(o)o = (UpSampling2D((2, 2), data_format=channel))(o)if l1_skip_conn:o = (concatenate([o, f1], axis=-1))o = (ZeroPadding2D((1, 1), data_format=channel))(o)o = (Conv2D(64, (3, 3), padding='valid', activation='relu', data_format=channel, name="seg_feats"))(o)o = (BatchNormalization())(o)o = Conv2D(classes, (3, 3), padding='same',data_format=channel)(o)model = get_segmentation_model(img_input, o)return model