摘要
本文主要对大模型WizardLM的基本信息进行了简单介绍,展示了WizardLM取得的优秀性能,分析了论文的核心——指令进化方法。
论文概述
基本信息
- 英文标题:WizardLM: Empowering Large Language Models to Follow Complex Instructions
- 中文标题:WizardLM:授权大型语言模型遵循复杂的指令
- 发表时间:2023年4月-arxiv
- 作者单位:北京大学 & 微软
- 论文链接:https://arxiv.org/abs/2304.12244
- 代码链接:GitHub - nlpxucan/WizardLM: Family of instruction-following LLMs powered by Evol-Instruct: WizardLM, WizardCoder and WizardMath

摘要
- 论文展示了使用LLM而不是人工来创建具有不同复杂程度的大量指令数据的途径。
- 从一组初始指令开始,通过进化指令逐步将它们重写为更复杂的指令。然后,将生成的所有指令数据进行混合来微调LLaMA。
- 论文将生成的模型称为WizardLM。
- 在复杂平衡测试平台和Vicuna测试集上的人类评估表明,来自evolution - instruct的指令优于人类创造的指令。
- 通过分析高复杂性部分的人工评估结果,论文证明了WizardLM模型的输出比OpenAI,ChatGPT的输出更受欢迎。在GPT-4自动评估中,WizardLM在29项技能中的17项达到了ChatGPT 90%以上的能力
WizardLM模型性能优越,可以作为text2sql的基座模型,github上有个DB-GPT-Hub项目开源了大模型微调text2sql的pipline,模型支持也有WizardLM模型(这是DB-GPT项目的子项目),其中提供了数据集下载-数据集预处理-模型下载-模型微调-模型权重合并-模型预测-模型评估,如果没有GPU可以使用AutoDL平台按需使用。
- DB-GPT项目:目前已有6.4k star,可以关注一波,目前该项目最新版本——DB-GPT V0.3.7 发布,支持用自然语言分析和查询Excel表格数据
- DB-GPT_Hub项目:目前有200多star,专注于text2sql大模型微调领域,大家也可以去贡献代码,比如模型支持里面也有WizardLM。
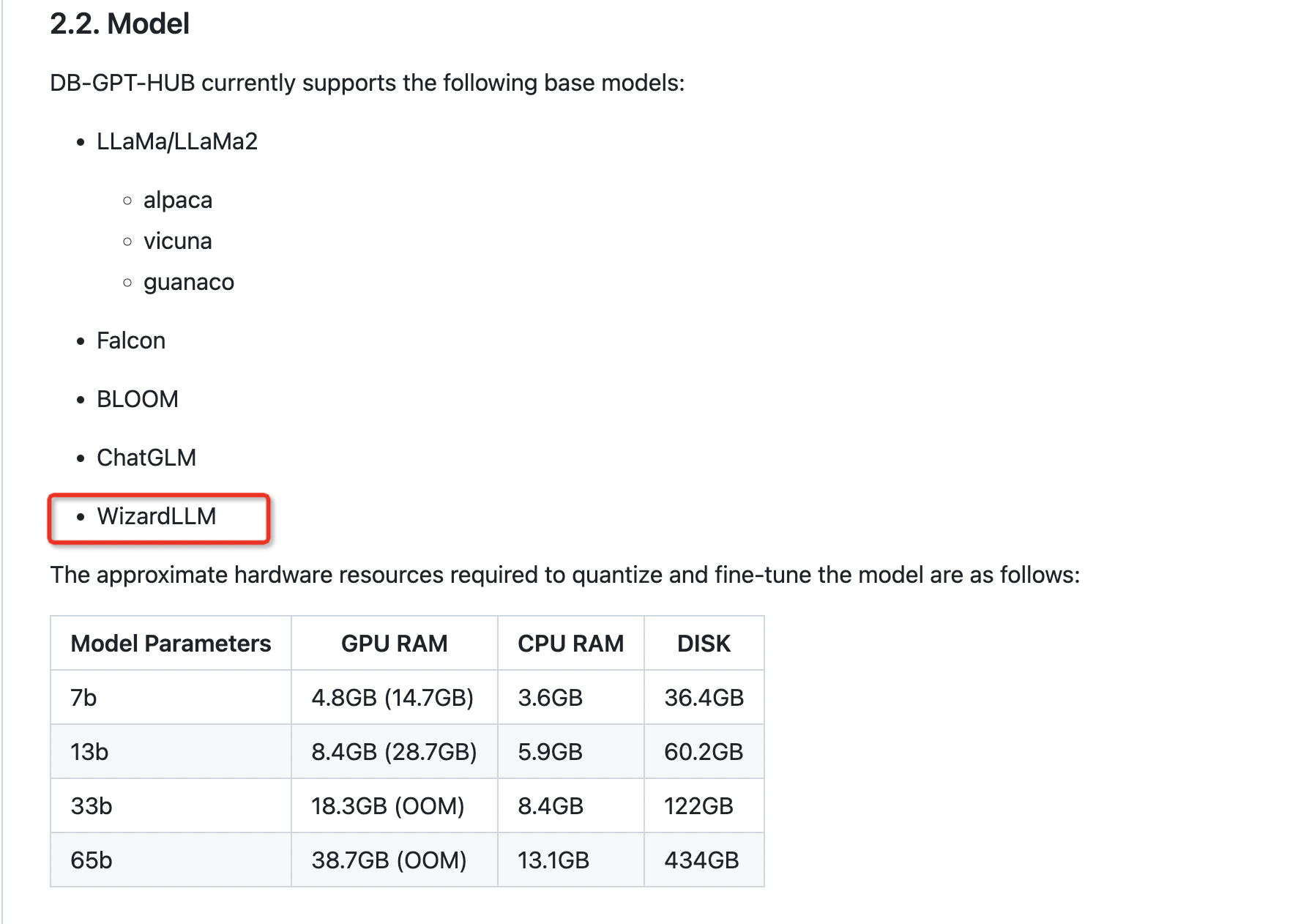
WizardLM模型的思想值得借鉴,后面还有模型Code Llama更加出色,后面再介绍。
结果
收集测试集
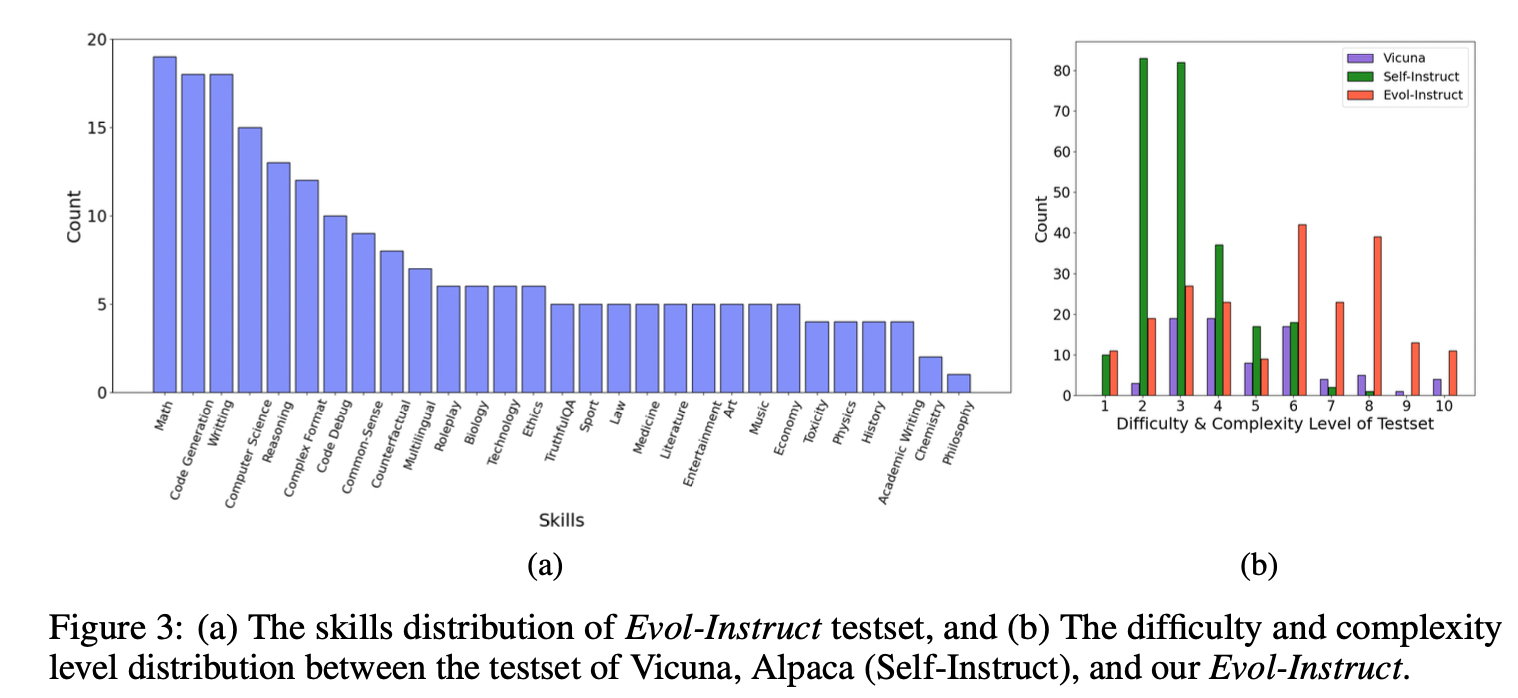
- 网上收集的指令测试集:总共218个例子,分成了29项类别,比如有数学math、代码生成、写作等等。
- 图3a说明了测试集中实例和技能的分布。测试集由218个实例组成,每个实例都是针对特定技能的指令。
- 图3b比较了和Vicuna小羊驼、Alpaca羊驼
人工打分评估
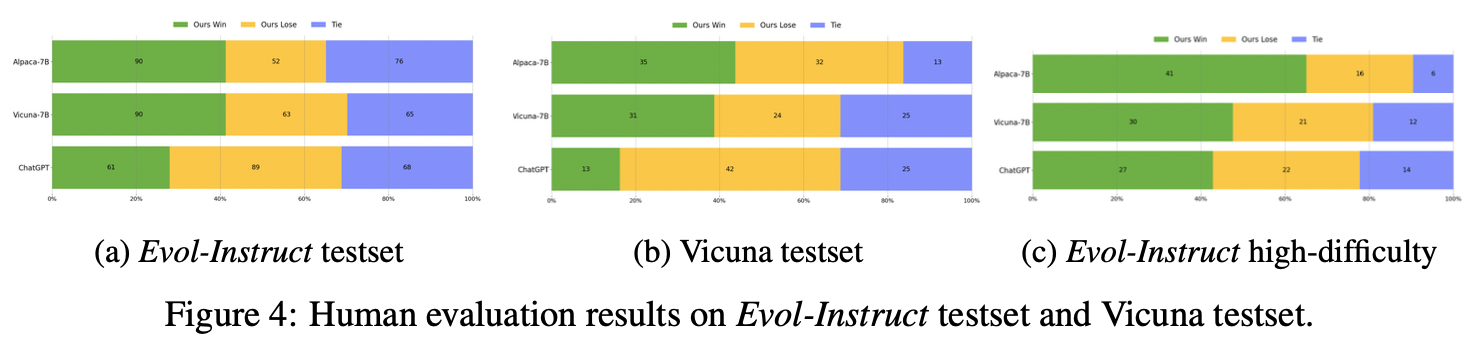
为了评估WizardLM,在evolution - directive测试集上进行了人类评估。我们在WizardLM和基线之间进行盲两两比较。具体来说,招募了10名受过良好教育的注释员。对于每个注释者,提供了来自Alpaca、Vicuna-7b、WizardLM和ChatGPT的四个响应,这些响应被随机打乱以隐藏其来源。然后评注者根据附录h中的标准判断哪一个回答更好,然后他们应该将四个回答从1到5进行排序(1表示最好),并允许同等分数的可比较实例。
- 比如图4a中Evol-Instruct testset数据集上,跟ChatGPT相比,WizardLM赢了61次,ChatGPT赢了89次,平局68次。(总共218)
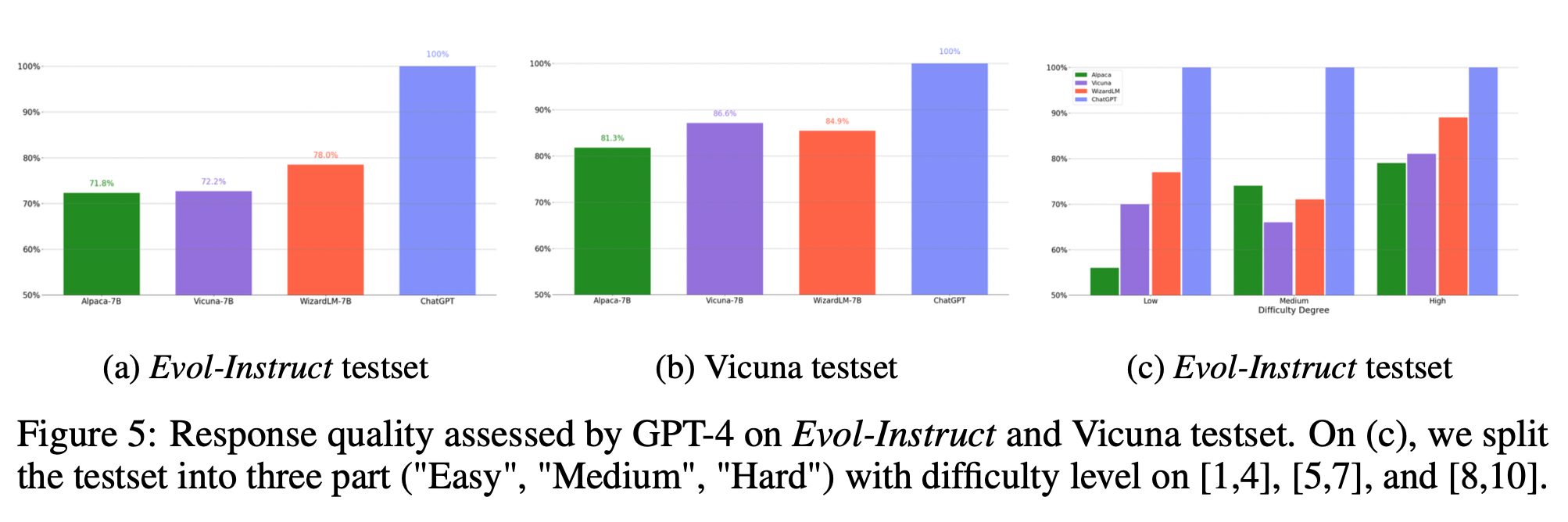
GPT4自动评估
- 如图5a和5b所示,WizardLM-78.0%在evolo-instruct测试集上的性能明显优于Alpaca-7B-71.8%和Vicuna-7B-72.2%(分别优于Alpaca-7B和Vicuna-7B的性能6.2%和5.8%)
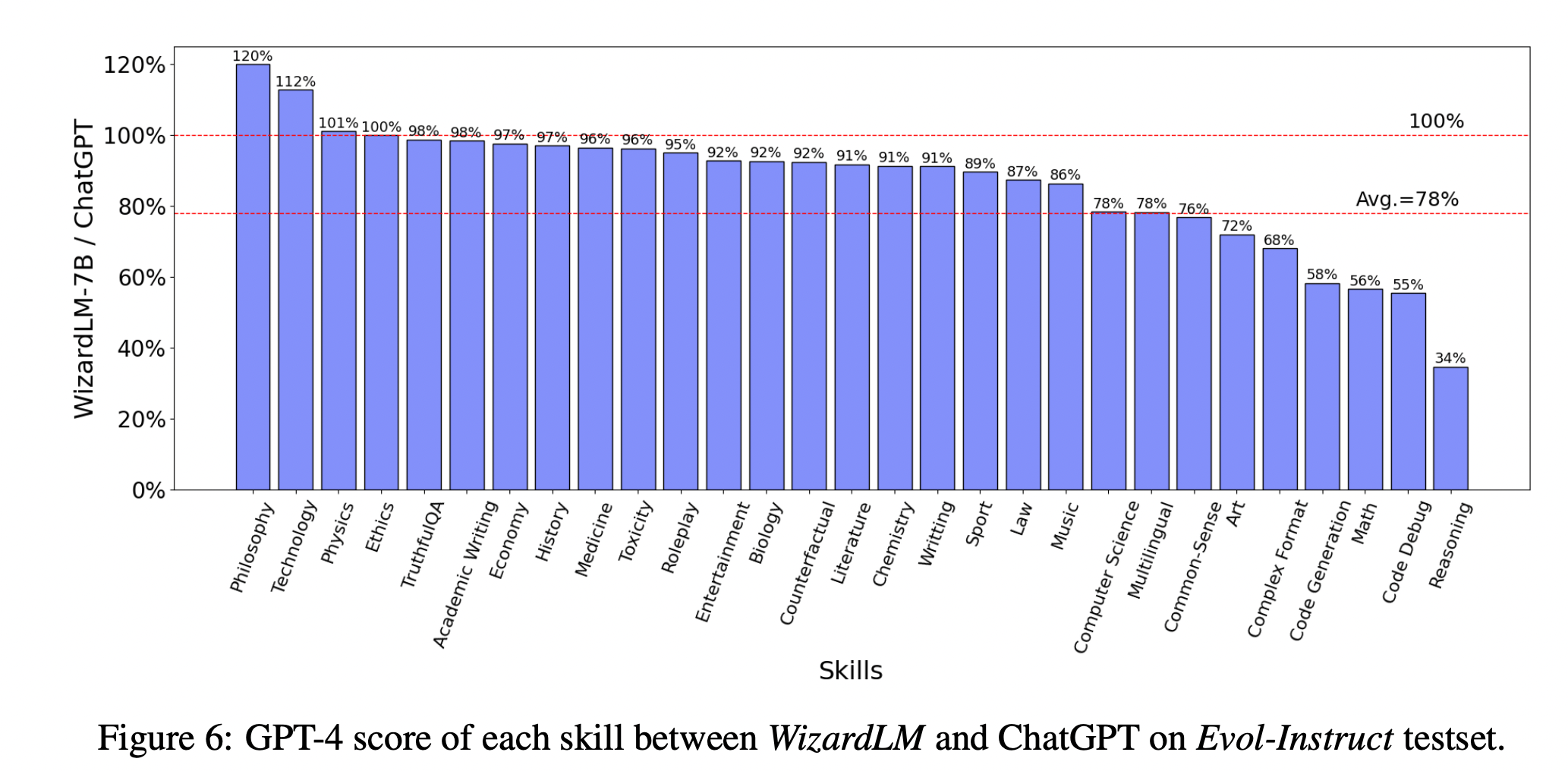
- 图6比较了WizardLM和ChatGPT在evolution - directive测试集上的技能水平。结果表明,WizardLM的平均性能达到了ChatGPT的78%,17项技能的容量几乎超过了90%。然而,WizardLM在代码、数学和推理场景方面遇到了困难,显示出与ChatGPT的明显差距。(所以后面有WizardCoder)
结论
本文提出了一种进化算法——evolution-directive,用于生成多种复杂的LLM指令数据。论文证明提出的方法提高了LLM的性能,WizardLM,在高复杂性任务上取得了最先进的结果,在其他指标上取得了具有竞争力的结果。
局限性(评估方法):本文承认我们的自动GPT-4和人工评估方法的局限性。这种方法对可扩展性和可靠性提出了挑战。此外,我们的测试集可能无法代表LLM可以应用或与其他方法进行比较的所有场景或领域。
更广泛的影响。evolo - instruct可以提高LLM在各个领域和应用中的性能和交互性,但它也可能产生不道德、有害或误导性的指令。因此,我们敦促未来对人工智能进化指令的研究,以解决伦理和社会影响。
核心思想
这个图看着还挺有意思的
很简约
图形化很不错
只不过作为模型核心结构会有点懵
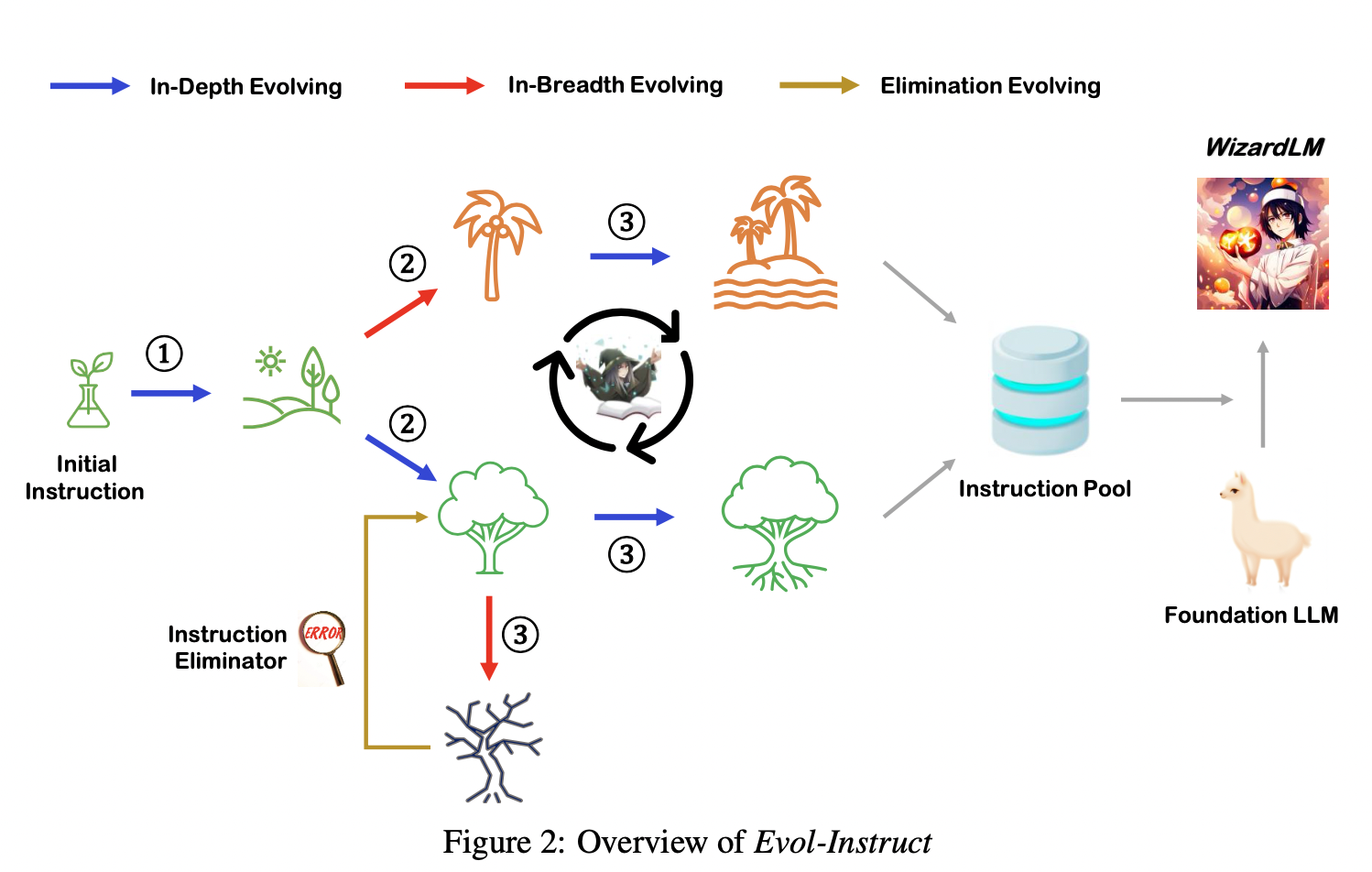
instruction data evolution指令数据演化
输入指令I1-instruction,通过LLM得到答复R1-response
输入指令I2-instruction,通过LLM得到答复R2-response
不断迭代
指令I1如何更新为指令2?
- 通过LLM instruction evolution prompt 指令进化提示词
instruction evolution prompt是什么?
- 参考下方的指令进化器
Automatic Instruction Data Evolution自动指令数据演化
pipline 分成3个部分:
- 1)指令进化
- 2)响应生成
- 3)消除进化,即过滤无法进化的指令。
指令进化instruction evolution
作者发现LLM可以使用特定的提示使给定的指令变得更加复杂和困难。此外,它们可以生成同样复杂但完全不同的全新指令。
利用这一发现,我们可以迭代地进化一个初始指令数据集,提高难度水平,扩大其丰富性和多样性。
1.用给定的初始指令数据集D(0)初始化指令池。
2.在每个进化时期,从前一个时期升级的指令从池中取出。
3.然后利用指令进化器instruction evolver来进化每条获取到的指令,并利用指令消除器instruction eliminator来检查是否存在进化失败的指令。
- 成功进化的指令被添加到池中
- 不成功的指令被放回原处,希望在下一个进化时期成功升级它们。
指令进化器instruction evolver
指令进化器是一种LLM,它使用提示来进化指令,有两种类型:深度进化和广度进化。
深度进化
深度进化通过五种类型的提示来增强指令的复杂性和难度:
- 添加约束
- 使得深度化
- 使得具体化
- 增加推理步骤
- 使输入变得复杂化。
举例子:
- 这是添加约束add contraints:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please add one more constraints/requirements into #Given Prompt#
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
<Here is instruction.>
#Rewritten Prompt#:- 这是Deepening Prompt深化:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
If #Given Prompt# contains inquiries about certain issues, the depth and breadth of the inquiry can be increased. or
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
<Here is instruction.>
#Rewritten Prompt#:- 这是具体化Concretizing Pormpt:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please replace general concepts with more specific concepts. or
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
<Here is instruction.>
#Rewritten Prompt#:- Increased Reasoning Steps Prompt:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
If #Given Prompt# can be solved with just a few simple thinking processes, you can rewrite it to explicitly request multiple-step reasoning.
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
<Here is instruction.>
#Rewritten Prompt#:- 这是complicating input:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
You must add [XML data] format data as input data in [Rewritten Prompt]
#Given Prompt#:
<Here is Demonstration instruction 1.>
#Rewritten Prompt#:
<Here is Demonstration Example 1.>
... N -1 Examples ...
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
You must add [#Given Dataformat#] format data as input data, add [#Given Dataformat#] code as input code in [Rewritten Prompt]
Rewrite prompt must be a question style instruction
#Given Prompt#:
<Here is instruction.>
#Rewrite prompt must be a question style instruction Rewritten Prompt(MUST contain a specific JSON data as input#:广度进化
I want you act as a Prompt Creator.
Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt.
This new prompt should belong to the same domain as the #Given Prompt# but be even more rare.
The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#. The #Created Prompt# must be reasonable and must be understood and responded by humans.
‘#Given Prompt#’, ‘#Created Prompt#’, ‘given prompt’ and ‘created prompt’ are not allowed to appear in #Created Prompt#.
#Given Prompt#:
<Here is instruction.>
#Created Prompt#:生成response
- 使用与进化相同的LLM来为进化的指令生成相应的响应。生成提示符是" <Here is instruction.> "。
消除进化
有以下4种情况归类为失败:
- 指令进化失败;与原始指令相比,进化后的指令没有提供任何信息增益。我们使用ChatGPT进行此确定。
- 进化的指令使得LLM很难产生响应。我们发现,当生成的响应包含“sorry”并且长度相对较短(即少于80个单词)时,它通常表明LLM努力响应进化的指令。所以我们可以用这个规则来做判断。
- LLM生成的响应只包含标点和停止词。
- 进化指令显然从进化提示中复制了一些单词,如“给定提示”、“重写提示”、“#重写提示#”等。
baseline
- ChatGPT
-
- OpenAI
- AI bot
- 基于GPT-3.5 or GPT-4
- Alapaca
-
- 开源模型,基于LLaMA
- 斯坦福大学Standford University
- Vicuna
-
- 开源的chat bot
- 基于LLaMA
参考文献
WizardLM论文:https://arxiv.org/abs/2304.12244
DB-GPT项目:https://github.com/eosphoros-ai/DB-GPT/blob/main/README.zh.md
DB-GPT-Hub项目:GitHub - eosphoros-ai/DB-GPT-Hub: A repository that contains models, datasets, and fine-tuning techniques for DB-GPT, with the purpose of enhancing model performance, especially in Text-to-SQL.