🎈🎈🎈YOLO 系列教程 总目录
YOLOV1整体解读
YOLOV2整体解读
YOLOV3提出论文:《Yolov3: An incremental improvement》
1、YOLOV3改进
这张图讲道理真的过分了!!!我不是针对谁,在座的各位都是**
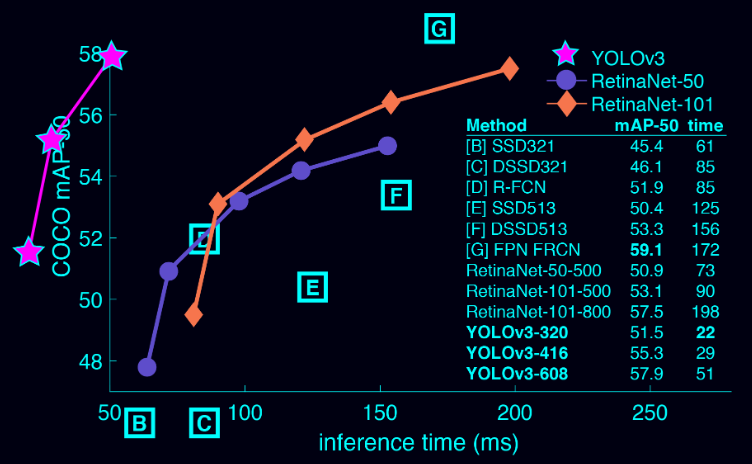
故意将yolov3画到了第二象限
- 终于到V3了,最大的改进就是网络结构,使其更适合小目标检测
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 先验框更丰富了,3种scale,每种3个规格,一共9种
- softmax改进,预测多标签任务
- yolo的思想就是一步预测,速度快,但是一直被质疑效果不好,这次改进了网络结构更加适合小目标检测
- yolo主要用的还是cnn,改进的地方还是在cnn上
- v1 2个框,v2做了一个聚类有5个框,v3 9个框
- 一个物体可能有多标签,比如哈士奇既是狗可别也是哈士奇类别
2、多scale方法与特征融合
- 为了能检测到不同大小的物体,设计了3个scale
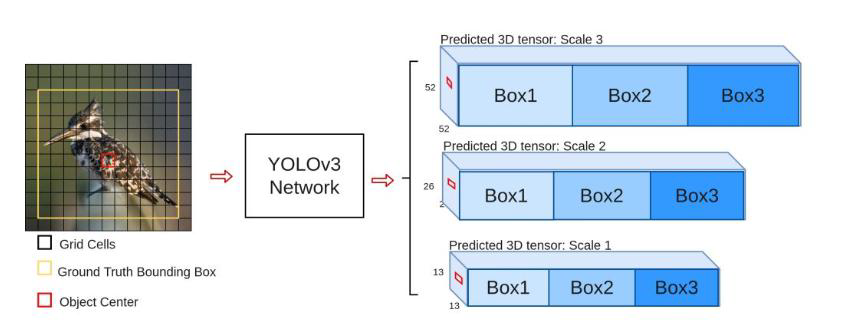
在v2版本中,将不同尺度的特征融合到了一起来满足多尺寸的物体检测,实际上效果并不好,v3版本中,将物体分为了三个尺寸(13,13)、(26,26)、(52,52),代表大、中、小三种尺寸的物体取预测。
(13,13),对应大物体,3个较大的候选框
(26,26),对应中等物体,3个略小的候选框
(52,52),对应小物体,3个较小的候选框
在yolov2中为了应对对小目标检测效果不好的情况,将最后一层卷积的特征图和倒数第二层做了融合,去预测。
在yolov3版本的做法是:
- 最后一层卷积的特征图尺寸是(13,13),记为结果A
- 倒数第二层卷积的特征图尺寸是(26,26),将结果A进行上采样至(26,26),融合在一起得到结果B
- 倒数第三层卷积的特征图尺寸是(52,52),将结果B进行上采样至(52,52),融合在一起得到结果C
- 结果A负责预测大物体,结果B负责预测中物体,结果C负责预测小物体
3、残差连接-为了更好的特征
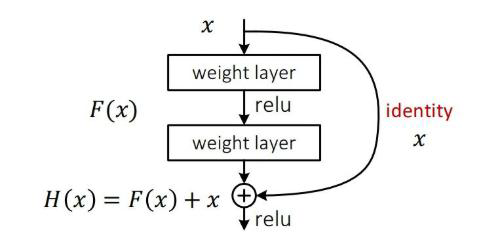
- 从今天的角度来看,基本所有网络架构都用上了残差连接的方法
- V3中也用了resnet的思想,堆叠更多的层来进行特征提取
当年2016年resnet让深度学习真正变得深了起来,因为很多网络在堆叠到一定程度后,效果不仅没有上升反而下降,加上resnet的残差连接的思想,保证了堆叠不会出现效果下降的情况
4、网络架构
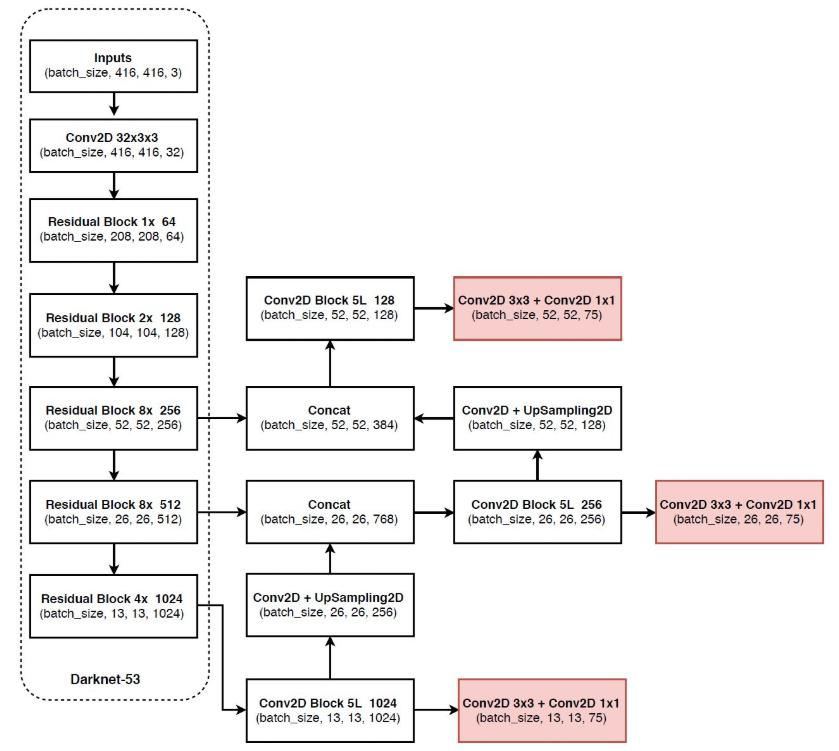
- 没有池化和全连接层,全部卷积
- 下采样通过stride为2实现
- 3种scale,更多先验框
- 基本上当下经典做法全融入了
- 在v2版本中去掉了所有的全连接层,在v3版本中所有的池化层也全部去掉了
- 下采样通过卷积步长为2来实现
- 红色部分从上到下依次对应小目标、中目标、大目标
整体就是利用残差网络得到三种不同输出的特征图,这三种不同特征图将之前的信息也融入进来
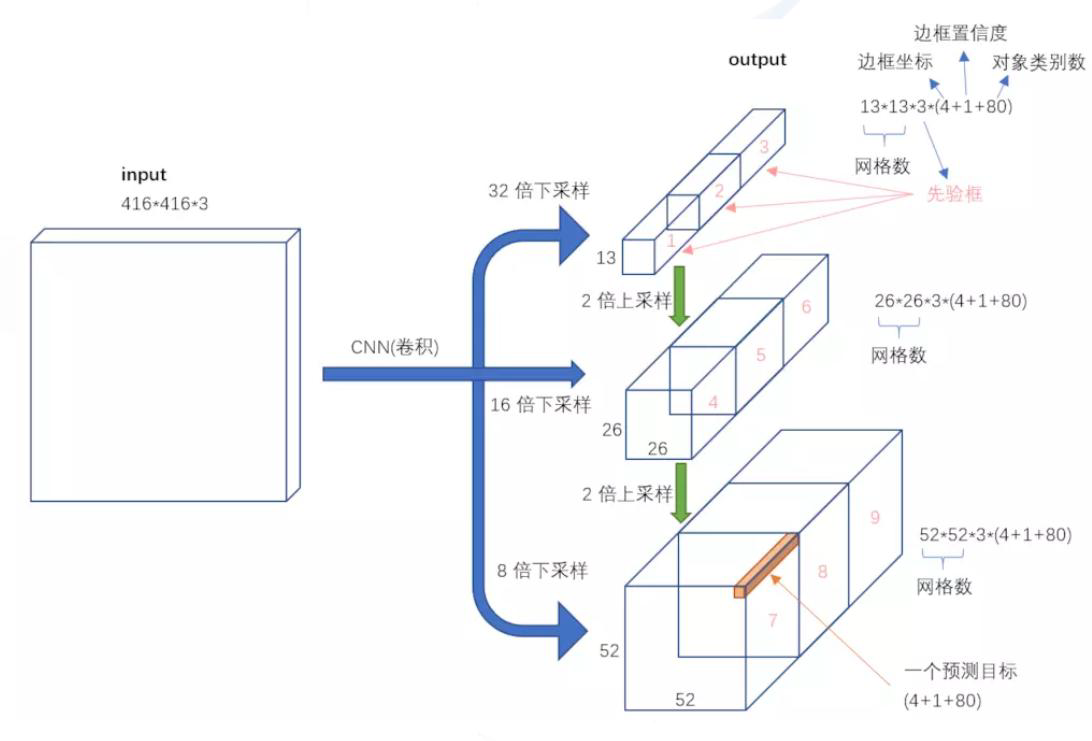
85的意思就是80+4+1,4是先验框的x、y、w、h,1是confidence判断是前景还是背景,80就是80个类别,这是自己定义的。
5、先验框改进设计

- YOLO-V2中选了5个,这回更多了,一共有9种
- 13*13特征图上:(116x90),(156x198),(373x326)
- 26*26特征图上:(30x61),(62x45),(59x119)
- 52*52特征图上:(10x13),(16x30),(33x23)
(116x90),(156x198),(373x326)对应大物体的先验框,用在13*13的特征图上,其他以此类推



6、softmax替代
- 物体检测任务中可能一个物体有多个标签
- logistic激活函数来完成,这样就能预测每一个类别是/不是
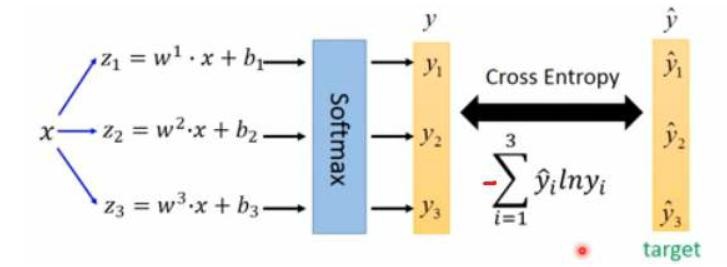
不管是在检测任务的标注数据集,还是在日常场景中,物体之间的相互覆盖都是不能避免的。因此一个锚点的感受野肯定会有包含两个甚至更多个不同物体的可能,在之前的方法中是选择和锚点IoU最大的Ground Truth作为匹配类别,用softmax作为激活函数。
YOLOv3多标签模型的提出,对于解决覆盖率高的图像的检测问题效果是十分显著的,YOLOv3的效果好很多,不仅检测的更精确,最重要的是被覆盖很多的物体也能很好的在YOLOv3中检测出来。
1、YOLOv3 使用的是logistic 分类器,而不是之前使用的softmax。
2、在YOLOv3 的训练中,便使用了Binary Cross Entropy ( BCE, 二元交叉熵) 来进行类别预测。
原因:
(1)softmax只适用于单目标多分类(甚至类别是互斥的假设),但目标检测任务中可能一个物体有多个标签。(属于多个类并且类别之间有相互关系),比如Person和Women。
(2)logistic激活函数来完成,这样就能预测每一个类别是or不是。
对于原始的输入,在给定的80个类别(假设是80),经过前面的网络提取后,最后的输出经过softmax,得到80个概率值,选取最高的那一个,就是预测结果,如果正确结果有两个(或者更多)
而用BCE来做呢?将所有的结果都进行二分类,即每一个类别都有两个概率值。