简介
其实在map 和 set 的底层实现当中有差不多一半的 结构是使用 二叉搜索树来实现,关于二叉搜索树可以看下面这个篇博客:
C++ - 搜索二叉树_chihiro1122的博客-CSDN博客
而 set 是 key 模型,他是直接按照 key 值大小来有规律的在 二叉搜索树当中存储。
而 map 是 key - value 模型,在 上述博客中的 搜索二叉树的运用当中对 key - value 这个模型进行了举例说明。
map 是一个非常好用的 数据结构,我们知道 二叉搜索树 在查找数据当中所带来的极高效率,然而我们在平常使用的时候,不会去手搓一个 二叉搜索树。用现成的 map 和 set 就行了。
set
set 是 key 模型,它在存储一些比如 只有 int 类型的数的时候,为未来带来非常快速的查找。
在了解 二叉搜索树 是如何实现之后,我们就应该明白 set 的一些特性:自动排序,去重。
set 当中在打印的时候,比如使用它的迭代器来打印,他是按照树的中序来打印的,所以,打印出来的结果是有序的。而且二叉搜索树当中的值只有一个,不会重复,就算你在构建树或者在后续插入结点的时候,造成了重复的值,这些值也会被set 进行去重:
set<int> s;s.insert(5);s.insert(5);s.insert(5);s.insert(3);s.insert(8);s.insert(1);s.insert(10);std::set<int>::iterator it = s.begin();for (auto e : s){cout << e << endl;}return 0;
输出:
1
3
5
8
10发现,尾差的结点当中是无序的,而且有重复值,但是输出都 是有序而且去重了的。
注意:在 set 当中重写了 Find()函数,但是库当中也有find()函数,两者虽然都能够达到查找的目的,但是两个 find()函数的查找逻辑是完全不一样的:
set<int> s;s.insert(5);s.insert(5);s.insert(5);s.insert(3);s.insert(8);s.insert(1);s.insert(10);std::set<int>::iterator it = s.find(5); // set 当中的 find()函数auto it1 = find(s.begin(), s.end(), 5);if(it != s.end())cout << "set::find() :" << * it << endl;cout << "std::find() :" << * it1 << endl;return 0;输出:
set::find() :5
std::find() :5在 set 当中的find()函数,是按照 二叉搜索树当中 查找的逻辑来查找的,按照给定的 key 值,比如 当前结点的值比key大,走左子树,反之;
而在 库当中的 find()函数是直接暴力查找,要遍历整颗树。
因为 set 的find()函数如果找到结点返回的是该结点的迭代器,如果没有找到 返回的是 end()位置迭代器。
set 当中的一些函数介绍
set 当中有一些 自己实现的,好用的一些函数,以下我们简单介绍一些:
key_comp 和 value_comp

是 获取到 key 和 value 的仿函数,获取到仿函数对象。
count()函数
count()函数判断给值在树当中出现多少次,因为是搜索二叉树,只会出现一次,所以当 count()函数找到了,就会返回1,找不到就返回0:

而且count()函数是被 const 修饰的,也就是说该函数的 this指针是不能进行修改的,count()函数不能用于修改 二叉搜索树。
其中的value_type 和 value_key 是一样的,都是 key,也就是模版参数类型。只不过在库当中经常模版参数 T ,typedef 一下,命名为 类似 value_type 这样的参数。
if (s.find(5) != s.end())cout << "找到了" << endl;if (s.count(5))cout << "找到了" << endl;由上述例子可以发现,count()再日常使用方式,比find()函数使用还要方便一些,而且 count()函数的效率和 find()函数的效率都是一样的,因为都是使用二叉搜索树的查找方式来寻找的。
那么count()函数和 find()函数差不多,那么为什么要多设计一个 count()函数出来呢?
请看下述的 multiset 容器。
lower_bound 和 upper_bound



这两个函数是用于取出迭代器区间的。
有时候我们可能会有一些需求,比如要去除某迭代器区间的值,然后删除;或者在 insert()插入函数当中,有重载有 用 迭代器区间来插入值的 函数:

在官方文档当中给出了下面这个例子:
std::set<int> myset;std::set<int>::iterator itlow,itup;for (int i=1; i<10; i++) myset.insert(i*10); // 10 20 30 40 50 60 70 80 90itlow=myset.lower_bound (30); // ^itup=myset.upper_bound (60); // ^myset.erase(itlow,itup); // 10 20 70 80 90std::cout << "myset contains:";for (std::set<int>::iterator it=myset.begin(); it!=myset.end(); ++it)std::cout << ' ' << *it;std::cout << '\n';这个例子就是删除某一段迭代器区间当中的所以值。
我们发现 erase()函数函数也是重载了 迭代器区间 参数的函数。
用 lower_bound ()函数取出 左迭代器区间;用 upper_bound()函数取出 右迭代器区间;
再把取出的迭代器,传入到 erase()函数当中就返程了删除操作。
注意,在STL当中的区间一般都是 左闭右开 的,但是上述程序的输出结果是:
10 20 70 80 90
其实这里的erase()函数其实也是 左闭右开,这里把 60 也删掉了是因为,upper_bound (60)在实际当中 返回的是 删除的右区间的数要稍微比 60 大一点,才会把 60 给删掉;但 erase()的本质上还是左闭右开区间的删除。
equal_range()函数

equal_range () 函数也是可以取出迭代器区间的,但是这个函数的返回值返回的是一个 pair 对象,(关于 pair 类会在 map 当中说明)。只不过 equal_range()函数返回的迭代器区间只有一个值,并不想之前的一样可以有多个值。
如果 equal_range() 没有找到 值,返回的是比 找到的值稍大一点的区间,但是这个区间也是一个不存在的区间;假如你传入 6,那么他可能返回的区间是 [7,7) ,这个区间相当于是一个不存在的区间;如果传入的值已经大于 二叉搜索树当中最大的值了,返回的 是 end()。
在官方文档中的 例子 是这样写的:
std::set<int> myset;for (int i=1; i<=5; i++) myset.insert(i*10); // myset: 10 20 30 40 50std::pair<std::set<int>::const_iterator,std::set<int>::const_iterator> ret;ret = myset.equal_range(30);auto it1 = ret.first;auto it2 = ret.second;std::cout << "the lower bound points to: " << *it1 << '\n';std::cout << "the upper bound points to: " << *it2 << '\n';像上述例子,我们也取出了 it1 和 it2 两个迭代器左右区间。
上述的 pair 当中 second 也返回的是 比 右区间要稍微大一点的值。
multiset,另一种 set
除了set 本身,还有一个 set 叫做 multiset;
set 是 排序加去重;multiset 只是 排序。

multiset 在功能上 和 set 是基本完全一样的,使用也是和 set 没多大区别。
例子:
multiset<int> s;s.insert(5);s.insert(5);s.insert(5);s.insert(3);s.insert(8);s.insert(1);s.insert(10);for (auto e : s){cout << e << " ";}输出:
1 3 5 5 5 8 10multiset支持 相同的值继续插入,相同的值插入在左右两边都可以。
那 对应 的在 set 当中意义不大的函数 ,比如 count()函数在 multiset当中就有意义了。
那么如果我能使用 find()函数查找 上述例子当中的 5 ,find()函数会返回哪一个 5呢?
不一定是 第一个 5 ,或者说是 第一个插入的 5,因为 multiset 当中为了 防止 出现 极端情况,就会旋转子树。其实 find()函数返回的是 中序当中的第一个 5。
map
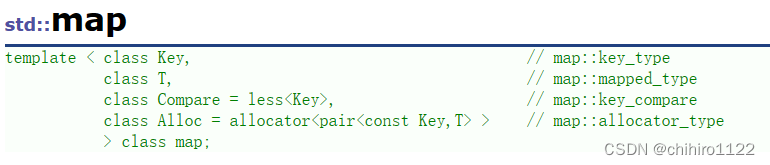
map在定义的时候和 set 的区别就是,map 的 定义需要两个参数,一个是 用于排列的 key,另一个是 key 对应的 value值。
由上述声明当中也可以发现,Compare 比较器 是 Key。是按照 key 值 来排序的。
而,在 map 当中的 value_type 不一样了,不在是 模版参数当中的 T:

他是 一个 pair 类模板。而且 pair 其中的 key 还是一个 const 的 key,也就是 不允许修改了。而 value 是可以修改的。
其实在 set 当中也是不允许修改 其中结点的值的,实现也简单,set 当中的 迭代器 和 const 迭代器,都是 const 迭代器。也就是说set 当中只有 const 迭代器:

所以在 map 当中使用 insert()函数来插入结点的时候,就不能直接传入 两个参数来插入了。
必须传入一个 pair 对象,因为 insert()函数的当中的参数类型是 value_type ,是 pair 的typedef:
map<string, string> dict;pair<string, string> p("你好","hello");dict.insert(p); // 方式1 dict.insert(pair<string, string>("再见", "byebye")); // 方式2dict.insert({ "string", "字符串" }); // 方式3在 map 当中,支持 key 不相同但 value 相同;不支持 key 相同,value 不相同;
其实就是 key值不能相同,相同会进行去重,但value 是可以相同的。
key 相同,不插入,不覆盖;插入过程当中只比较 key。
虽然在 map 当中模版可以支持任意类型,但是因为 map 的底层是用二叉搜索树来实现的,避免不了要比较大小,所以,key 的类型必须是有 比较大小功能的 类型。如果有一种需求,想使用一种没有比较大小的作为 key,那么可以用仿函数来实现。在 map 的模版参数当中给出了 Compare = less<Key>。默认是 Key ,我们可以自己写一个仿函数来 构建 这个类型的比较函数。
 关于如何仿函数运用的文章:C++ - 优先级队列(priority_queue)的介绍和模拟实现 - 反向迭代器的适配器实现 - 仿函数_c++ priority_queue迭代器_chihiro1122的博客-CSDN博客
关于如何仿函数运用的文章:C++ - 优先级队列(priority_queue)的介绍和模拟实现 - 反向迭代器的适配器实现 - 仿函数_c++ priority_queue迭代器_chihiro1122的博客-CSDN博客
多参数的隐式类型转换
dict.insert({ "string", "字符串" }); 这种写法是最简便的,看上去有点怪,其实这发生了隐式类型的转换。我们知道,单参数的构造函数支持隐式类型的转换,可以看下面这边博客当中,对隐式类型转换的介绍:C++ 构造函数-2_chihiro1122的博客-CSDN博客
其实多参数的隐式类型转换也是可以的,只需要把 隐式转换的 变量或者常量用 "{}"括起来,用 ","分隔就行:
class A
{
public:A(int a, int b){_a = a;_b = b;}
private:int _a;int _b;
};int main()
{A Aaa = { 1 , 2 };return 0;
}其实下述三者的本质都是隐式类型的转换,只不过参数个数不同。
string str = "hello";A Aaa = { 1 , 2 };pair<string, string> p = { "string" , "字符串" };隐式类型转换,本质上需要调用两个函数,一个是构造函数,一个是拷贝构造函数;构造函数利用 参数 构造临时对象,而拷贝构造函数 把 临时对象拷贝到 我们要创建的对象的当中。
但实际上,编译器不会这样做,他觉得只构建一个对象,却要调用两个构造函数,很麻烦,所以通常情况下,编译器会对这里进行优化,比如上述例子,会直接使用 "hello" 等等的参数作为构造函数的参数,直接构造出 对象。
如果构建的对象加了 引用类型,比如:
const pair<string, string> p& = { "string" , "字符串" };当构建的是对象引用的时候,优化就没有了;
但是单独加 & 是不行的,会报错,需要加 const 修饰才行。因为 此时 对象引用 引用的是 隐式类型转换,构造的临时对象,临时对象具有常性,需要加 const 修饰。
make_pair()
上述在使用 insert()函数的时候,我们还有单独构建出一个 pair 对象出来,非常的麻烦。
所以在 C++ 当中提供给了一个函数:make_pair()。
它的实现大概是这样的:

dict.insert(make_pair("string", "字符串"));这是 C++ 98 经常使用的方式,在 C++ 11 是不支持隐式类型转换。
使用 make_pair() 函数看似多调用一个函数去构造,其实在效率上没有多大的损失,和隐式类型转换方式构建差不多,因为 make_pair()函数代码少,会被定义成内联函数,内联函数就基本没有消耗了。
operator[] 函数
之前说过,插入一个 key 值在树当中已经存在的结点,不插入,不覆盖;
如果想要覆盖 value 值的话,就要使用 operator[] 函数 。
如下面这个例子:
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& e : arr){auto it = countMap.find(e);if (countMap.end() == it){countMap.insert(make_pair(e, 1)); // 没有找到,插入新的水果}else{it->second++;}}map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){cout << (*it).first << ":";cout << (*it).second << endl;it++;}输出:
苹果:6
西瓜:3
香蕉:2还可以这样写:
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& e : arr){countMap[e]++;}map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){cout << (*it).first << ":";cout << (*it).second << endl;it++;} 输出:
苹果:6
西瓜:3
香蕉:2这里就巧妙的用到 operator[] ()函数。
operator[]()函数的使用:

返回值 mapped_type& 是 模版参数的第二个位置,也就是 value。参数传入是 key_type 是key。
也就是传入 key ,返回 value。
到这里,就可以理解 为什么 countMap[e]++; 这句代码可以 ++ value。
关键是 开始的时候 countMap 当中是什么都没有的,第一次是如何处理的?
文档当中是这样说的:
A call to this function is equivalent to:(*((this->insert(make_pair(k,mapped_type()))).first)).second也就是相当于是在返回值 处调用这个:
mapped_type& operator[] (const key_type& k);
{// `````````````````````````return (*((this->insert(make_pair(k,mapped_type()))).first)).second;
} 简单来看就是使用 insert()函数来实现的,所以我们还要探究一下 insert()函数:
上述insert()函数的返回值是:
pair<iterator,bool>
![]()
发现,pair当中的模版参数有一个 是迭代器,官方文档当中,对于insert()的这个返回值是这样描述的:

总结,两种情况:
- 如果插入的结点(插入的key值)在树当中已经存在,返回pair<树里面key值结点的iterator,false>
- 如果插入的结点(插入的key值)在树当中不存在,返回pair<新插入的key值结点的iterator,true>
由上述发现,insert()函数不止有插入的价值,还有查找的价值,有没有找到在 返回值的模版参数当中的 bool 值类型当中就可以知道。
把他简化一下,上述的代码如下所示:
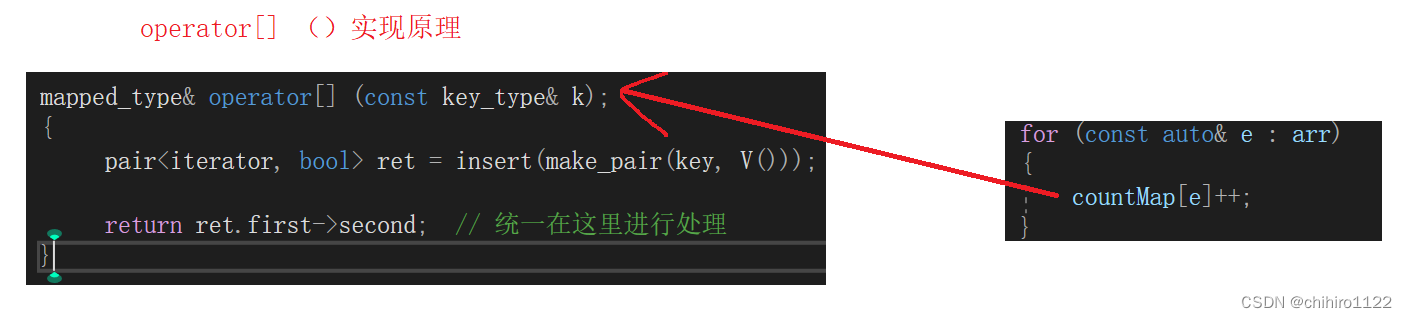
mapped_type& operator[] (const key_type& k);
{pair<iterator, bool> ret = insert(make_pair(key, V())); // 这不管 树当中有没有 这个key, //都不会去修改 value的值return ret.first->second; // 统一在这里进行处理
}operator[] ()函数实现原理细节解析:
- 上述V() 是 value的匿名对象,我们期望在这里调用 value的构造函数,在 value 的第地方我们不建议直接写 0 ,写 0 就写死了,写 value的构造函数比较好。
- 匿名对象调用的是 默认构造。所以,如果不给 value 的值,默认给的是 value 默认构造的缺省值。
- 而且,insert()函数有一个特性,他是不管 value的,不管 树中的key 和 当前插入的 key 想不想等,都不会去覆盖。
- 所以,因为这个函数的返回值是 value 的引用,我们直接返回 insert()函数返回的 pair对象,其中就有 first(iterator)和 second(bool)。
- 我们从 迭代器 first(iterator) 当中取出 其中的 second(value),使用引用返回 (value&)的话就可以直接对外部的访问的结点的 value 值进行修改。
现在我们来看,之前那一句代码究竟是如何实现的,实现的过程是什么:
countMap[e]++; 这一行代码,无非就两种情况:
- 第一种情况是,当前 e 从 arr 数组当中取到水果 在树 当中没有出现,那么此时的insert()就会构建出一个 int 的匿名对象,而 int 的匿名对象 默认构造函数的缺省参数就是 0 。然后 insert()函数插入这个水果,然后 insert()函数返回 当前 插入的这个结点的 迭代器 给到 pair 对象当中的 first成员,把 false 给到 second 成员。最后返回 一个 pair 类的对象 ret。
- 然后,返回的 是 ret 对象 first成员 当中存储的迭代器的 second成员,注意,此处的 second成员是迭代器指针指向的 pair 对象(当前插入的结点) 当中的 second 成员,它存储的是 当前结点的 value。
- 把 这个 second 也就是这个结点的 value值,作为 value& 返回,那么在外部对这个引用进行 ++ ,相当于就是对这个 value 进行 ++。
- 第二种情况是,当前 e 从 arr 数组当中取出的水果 是 树当中出现过的,insert()函数只看 key 相同,就会插入失败,失败同样会返回 从 arr 取出的水果在树当中的位置用迭代器表示如上述情况一样返回以 一个 pair 对象返回。
- 那么,此时就没有对这个水果进行插入,但是到了返回值的时候,还是会像上述情况一样取出 ret 的 first 当中的 second,此处(second)存储的是 这个结点(水果)出现的次数,这个 second 同样以 引用的形式返回,在函数外 进行 ++ , 影响到 函数内部的 second。
operator[] ()函数是 map 这个容器设计最 巧妙之处,他的功能不止在于上面,这个函数的返回值是 value& ,因为不是那 const 修饰的,我们可以用这个 value& 做很多事情。可读,可修改,可查找,可以插入新的结点:
map<string, string> m;m.insert(make_pair("你好", "hello"));m["你好"] = "byebye";cout << m["你好"] << endl; // byebye还有一种是 插入 加 修改:
// set 这个 key 在 树当中是没有的
// 先 调用 inset()进行插入
// 然后在 利用返回值 value& 进行修改m["set"] = "集合";pair类模板介绍
库当中的 pair 类模板大概是这样定义的:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};在 pair 当中有两个核心成员:first 和 second。由 T1 和 T2 来控制模版当中的参数。
官方库当中之所以要使用 pair 这个结构来存储 key - value 值,而不是直接用 key 和 value 的变量来存储,是因为在迭代器的实现当中,需要实现 operator*()这个 重载运算符函数,这个函数当中是需要返回 key 和 value的,而在 map 当中有 key 和 value 两个成员,如果用单独 变量来存储的话,两个单独的变量不好返回,只要把他们作为一个结构来返回。
在 pair 库当中是没有实现 << 和 >>(流提取和流插入),在使用迭代器来进行打印的时候,迭代器取出来的是 一个 pair 对象,我们要想打印出 key 和 value 值,就要访问对象当中的 first 和 second 成员:
map<string, string> dict;pair<string, string> p("你好","hello");dict.insert(p); // 方式1 dict.insert(pair<string, string>("再见", "byebye"));dict.insert(make_pair("string", "字符串"));dict.insert({ "string", "字符串" });map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << (*it).first << " ";cout << (*it).second << " " << endl;it++;}输出:
string 字符串
你好 hello
再见 byebye或者用 "->" :
cout << it->first << " ";cout << it->second << " " << endl;这个指针的解引用操作符,上述应该是 it->->first 这样使用,但是编译器优化了,看上去就像直接使用 "->" 一样。
这里使用的 "->" 其实是 operator-> ()这个函数实现的:

operator-> ()这个函数返回的是一个 指针,前面一个 "->" 是重载函数名,后一个 "->" 是函数返回的指针的解引用。
pair 当中的 first成员,也就是 map 当中的 key 值是不能修改的;而 second 成员,也就是 map 当中的 value 值是可以修改的。
multimap,另一种 map
multimap和 multiset 是类似的,也是支持排序,不支持去重。
multimap 和 map 之间不同点不止去不去重,在 multimap 当中没有实现 operator[]()函数。
至于原因我们也很容易想到,可能一个key 对应 多个 value,所以没有办法提供 operator[]()函数。
而 ,multimap 当中的 insert()函数的返回值 只是 iterator了,不再是 pair<iterator,bool> 这样的类型。因为 在 multimap 当中永远插入成功。
![]()

![[学习笔记]CS224W(图机器学习) 2022/2023年冬学习笔记](https://img-blog.csdnimg.cn/d375060fcb374436b326abe8f1898e06.png)