基本数据类型简介
位、字节和内存寻址
最小的内存单位是二进制数字(也称为位),它可以保存 0 或 1 的值。你在现代计算机体系结构中,每个位都没有自己唯一的内存地址。这是因为内存地址的数量有限,并且很少需要逐位访问数据。相反,每个内存地址保存 1 个字节的数据。字节是作为单元操作的一组位。现代标准是字节由 8 个连续位组成。

数据类型
因为计算机上的所有数据都只是一个位序列,所以我们使用数据类型(通常简称为“类型”)来告诉编译器如何以某种有意义的方式解释内存的内容。您已经看到了数据类型的一个示例:整数。当我们将变量声明为整数时,我们告诉编译器“该变量使用的内存片段将被解释为整数值”。
当您为对象赋值时,编译器和 CPU 负责将您的值编码为该数据类型的相应位序列,然后将其存储在内存中(请记住:内存只能存储位)。例如,如果为整数对象赋值 65,则该值将转换为位序列 0100 0001 ,并存储在分配给该对象的内存中。
相反,当计算对象以生成值时,该位序列将重构回原始值。这意味着 0100 0001 将其转换回值 65。
幸运的是,编译器和 CPU 在这里完成了所有艰苦的工作,因此您通常无需担心值如何转换为位序列并返回。您需要做的就是为对象选择最符合所需用途的数据类型。
基本数据类型
C++内置了对许多不同数据类型的支持。这些类型称为基本数据类型,但通常非正式地称为基本类型、基元类型或内置类型。
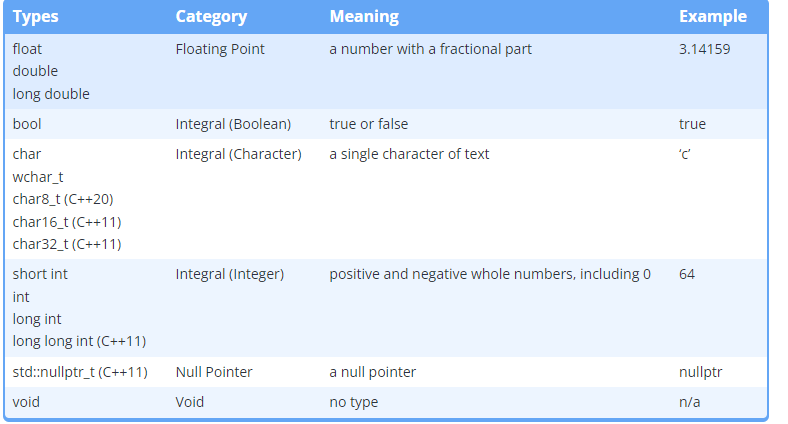
本章致力于详细探讨这些基本数据类型(std::nullptr_t 除外,我们将在讨论指针时讨论)。C++还支持许多其他更复杂的类型,称为复合类型。我们将在以后的章节中探讨化合物类型。
The _t suffix _t后缀
较新版本C++中定义的许多类型(例如 std::nullptr_t)都使用_t后缀。这个后缀的意思是“类型”,它是应用于现代类型的常用命名法。
如果您看到带有_t后缀的内容,则它可能是一种类型。但是许多类型没有_t后缀,因此无法始终如一地应用。
void
void意味着没有类型。不完整类型是已声明但尚未定义的类型。编译器知道此类类型的存在,但没有足够的信息来确定为该类型的对象分配多少内存。
无法实例化不完整的类型:
void value; // won't work, variables can't be defined with incomplete type void
空通常用于几种不同的上下文。
不返回值的函数
已弃用:不带参数的函数
void 关键字在C++中有第三个(更高级)用法: Void 指针
对象大小和运算符大小
现代机器上的内存通常组织成字节大小的单位,每个字节的内存都有一个唯一的地址。到目前为止,将内存视为一堆小隔间或邮箱,我们可以在其中放置和检索信息,将变量视为访问这些隔间孔或邮箱的名称,这很有用。
因为我们通常通过变量名(而不是直接通过内存地址)访问内存,所以编译器能够向我们隐藏给定对象使用多少字节的详细信息。当我们访问某个变量 x 时,编译器知道要检索多少字节的数据(基于变量 x 的类型),并且可以为我们处理该任务。
即便如此,有几个原因有助于了解对象使用多少内存。
首先,对象使用的内存越多,它可以容纳的信息就越多。因此,对象的大小限制了它可以存储的唯一值的数量
其次,计算机的可用内存量有限。每次我们定义一个对象时,只要该对象存在,就会使用该可用内存的一小部分。由于现代计算机具有大量内存,因此这种影响通常可以忽略不计。但是,对于需要大量对象或数据的程序(例如,渲染数百万个多边形的游戏),使用 1 字节和 8 字节对象之间的差异可能很大。
Key insight
编写可维护的代码,并且仅在实质性收益的时间和地点进行优化。
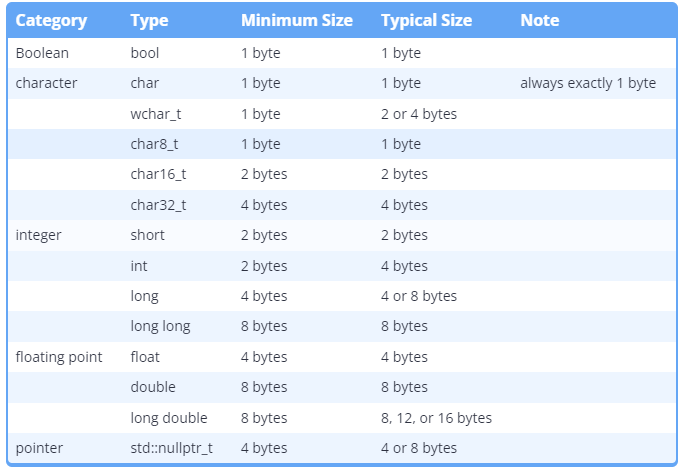
基本数据类型大小
显而易见的下一个问题是“不同数据类型的变量占用多少内存?也许令人惊讶的是,C++标准没有定义任何基本类型的确切大小。相反,它只定义了整型和 char 类型的最小大小(以位为单位),并将所有类型的实际大小留给实现定义!C++标准也不假定一个字节是 8 位。
在本教程系列中,我们将通过做出一些对于现代体系结构通常正确的合理假设来采用简化的观点:
- 一个字节是八位
- 内存是字节可寻址的,因此最小对象是一个字节
- 浮点数支持符合 IEEE-754 标准。
- 我们使用的是 32 位或 64 位架构。
运算符的大小
为了确定特定计算机上数据类型的大小,C++提供了一个名为 sizeof 的运算符。sizeof 运算符是一个一元运算符,它采用类型或变量,并以字节为单位返回其大小。
#include <iostream>
#include <iomanip> // for std::setw (which sets the width of the subsequent output)int main()
{std::cout << std::left; // left justify outputstd::cout << std::setw(16) << "bool:" << sizeof(bool) << " bytes\n";std::cout << std::setw(16) << "char:" << sizeof(char) << " bytes\n";std::cout << std::setw(16) << "wchar_t:" << sizeof(wchar_t) << " bytes\n";std::cout << std::setw(16) << "char16_t:" << sizeof(char16_t) << " bytes\n";std::cout << std::setw(16) << "char32_t:" << sizeof(char32_t) << " bytes\n";std::cout << std::setw(16) << "short:" << sizeof(short) << " bytes\n";std::cout << std::setw(16) << "int:" << sizeof(int) << " bytes\n";std::cout << std::setw(16) << "long:" << sizeof(long) << " bytes\n";std::cout << std::setw(16) << "long long:" << sizeof(long long) << " bytes\n";std::cout << std::setw(16) << "float:" << sizeof(float) << " bytes\n";std::cout << std::setw(16) << "double:" << sizeof(double) << " bytes\n";std::cout << std::setw(16) << "long double:" << sizeof(long double) << " bytes\n";return 0;
}
sizeof 不包括对象使用的动态分配内存。
基本数据类型性能
在现代机器上,基本数据类型的对象速度很快,因此使用或复制这些类型的性能通常不是问题。您可能会认为使用较少内存的类型比使用更多内存的类型更快。这并不总是正确的。CPU 通常经过优化以处理特定大小(例如 32 位)的数据,并且与该大小匹配的类型可以更快地处理。在这样的机器上,32 位 int 可能比 16 位短字符或 8 位字符快。
有符号整数
各种整数类型之间的主要区别在于它们具有不同的大小 - 较大的整数可以容纳更大的数字。
有符号整数
C++中的整数是有符号的,这意味着数字的符号存储为数字的一部分。因此,有符号整数可以同时保存正数和负数(和 0)。
定义有符号整数
以下是定义四种有符号整数类型的首选方法:
short s; // prefer "short" instead of "short int"
int i;
long l; // prefer "long" instead of "long int"
long long ll; // prefer "long long" instead of "long long int"
整数类型还可以采用可选的有符号关键字,按照惯例,该关键字通常放在类型名称之前:
signed short ss;
signed int si;
signed long sl;
signed long long sll;
有符号整数范围
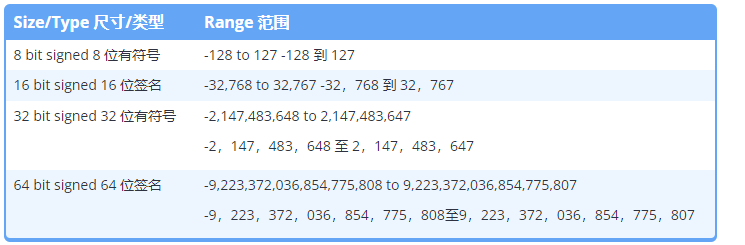
具有 n 位的变量可以容纳 2 个 n 可能的值。但是哪些具体值呢?我们调用数据类型可以保存其范围的特定值集。整数变量的范围由两个因素决定:它的大小(以位为单位)以及它是否是有符号的。
根据定义,8 位有符号整数的范围为 -128 到 127。这意味着有符号整数可以安全地存储 -128 和 127(含)之间的任何整数值.2 8 是 256,7 位用于保存数字的大小,1 位用于保存符号。
整数溢出
整数溢出(通常简称为溢出)发生在我们尝试存储类型范围之外的值时。从本质上讲,我们尝试存储的数字需要比对象可用的更多的位来表示。在这种情况下,数据会丢失,因为对象没有足够的内存来存储所有内容。对于有符号整数,丢失的位没有明确定义,因此有符号整数溢出会导致未定义的行为。通常,溢出会导致信息丢失,这几乎是不可取的。
如果怀疑某个对象可能需要存储超出其范围的值,请使用范围更大的类型!
整数除法
当对两个整数进行除法(称为整数除法)时,C++总是产生整数结果。由于整数不能容纳小数值,因此任何小数部分都会被简单地删除(不四舍五入!
无符号整数,以及为什么要避免它们
定义无符号整数
unsigned short us;
unsigned int ui;
unsigned long ul;
unsigned long long ull;
无符号整数范围
1 字节无符号整数的范围为 0 到 255。
无符号整数溢出
如果无符号值超出范围,则将其除以大于该类型最大数的 1,并仅保留余数。
这个数字 280 太大,不适合我们的 0 到 255 的 1 字节范围。大于 1 的类型的最大数字是 256。因此,我们将 280 除以 256,得到 1 个余数 24。24 是存储的内容。
任何大于类型可表示的最大数字的数字都只是“环绕”(有时称为“模包装”)。 255 在 1 字节整数的范围内,所以 255 很好。 256 但是,超出了范围,因此它环绕到值 0 。 257 环绕到值 1 。 280 环绕到值 24 。
也可以绕另一个方向。0 可以用 2 字节无符号整数表示,所以这很好。-1 不可表示,因此它环绕到范围的顶部,产生值 65535。-2 环绕到 65534。等等
#include <iostream>int main()
{unsigned short x{ 0 }; // smallest 2-byte unsigned value possiblestd::cout << "x was: " << x << '\n';x = -1; // -1 is out of our range, so we get modulo wrap-aroundstd::cout << "x is now: " << x << '\n';x = -2; // -2 is out of our range, so we get modulo wrap-aroundstd::cout << "x is now: " << x << '\n';return 0;
}
关于无符号数字的争议
许多开发人员(以及一些大型开发公司,如Google)认为开发人员通常应避免使用无符号整数。
这主要是因为两种可能导致问题的行为。
意外溢出范围的顶部或底部需要一些工作.
可能会导致意外行为。在C++中,如果数学运算(例如算术或比较)有一个有符号整数和一个无符号整数,则有符号整数通常会转换为无符号整数。因此,结果将是无符号
best practice:
避免混合使用有符号和无符号数字。
那么什么时候应该使用无符号数字呢?
首先,在处理位操作时,首选无符号数字(在O章中介绍 - 这是一个大写的“o”,而不是“0”)。当需要明确定义的环绕行为时,它们也很有用(在某些算法中很有用,如加密和随机数生成)。
其次,在某些情况下,使用无符号数字仍然是不可避免的,主要是那些与数组索引有关的数字。我们将在数组和数组索引课程中对此进行更多讨论。
NaN and Inf NaN 和 Inf
浮点数有两种特殊类别。第一个是Inf,它代表无穷大。Inf 可以是正数或负数。第二个是NaN,代表“不是一个数字”。有几种不同类型的 NaN(我们不会在这里讨论)。仅当编译器对浮点数使用特定格式 (IEEE 754) 时,NaN 和 Inf 才可用。如果使用其他格式,则以下代码将生成未定义的行为。
固定宽度的整数和size_t
为什么整数变量的大小不是固定的?
简短的回答是,这可以追溯到C,当时计算机速度很慢,性能是最重要的问题。
这不是很糟糕吗?
按照现代标准,是的。作为一名程序员,不得不处理范围不确定的类型有点荒谬。
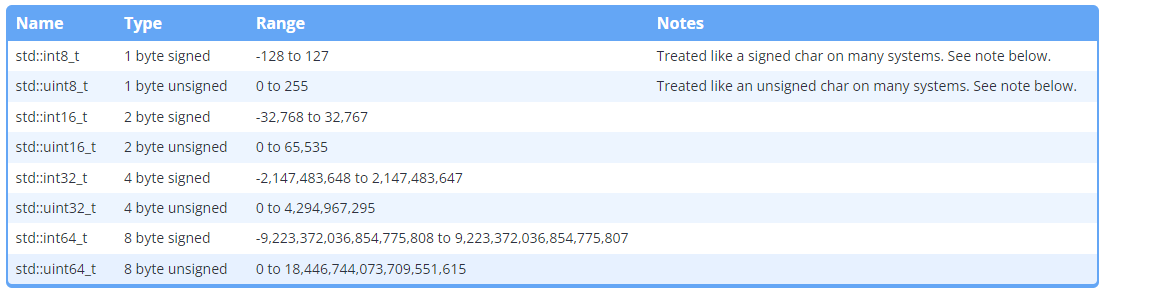
固定宽度整数
为了解决上述问题,C99 定义了一组固定宽度的整数(在 stdint.h 标头中),这些整数在任何体系结构上都保证大小相同。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::int16_t i{5};std::cout << i << '\n';return 0;
}
固定宽度的整数有两个缺点,通常会引发。
首先,不保证在所有体系结构上定义固定宽度的整数。它们仅存在于存在与其宽度匹配的基本类型并遵循某种二进制表示的系统上。程序将无法在不支持程序正在使用的固定宽度整数的任何此类体系结构上进行编译。但是,鉴于大多数现代体系结构都标准化了 8/16/32/64 位变量,这不太可能成为问题,除非您的程序需要移植到一些外来的大型机或嵌入式体系结构。
其次,如果使用固定宽度的整数,则在某些体系结构上,它可能比更宽的类型慢。例如,如果您需要一个保证为 32 位的整数,您可能会决定使用 std::int32_t ,但您的 CPU 实际上在处理 64 位整数时可能更快。但是,仅仅因为您的 CPU 可以更快地处理给定类型并不意味着您的程序整体会更快 - 现代程序通常受到内存使用而不是 CPU 的限制,并且较大的内存占用可能会比更快的 CPU 处理加速它更慢您的程序。
快速整数和最小整数
为了帮助解决上述缺点,C++还定义了两组保证定义的备用整数集。
快速类型(std::int_fast#_t 和 std::uint_fast#_t)提供宽度至少为 # 位的最快有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::int_fast32_t 将为您提供至少为 32 位的最快有符号整数类型。最快,我们指的是 CPU 可以最快处理的积分类型
最小类型(std::int_least#_t 和 std::uint_least#_t)提供宽度至少为 # 位的最小有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::uint_least32_t 将为您提供至少为 32 位的最小无符号整数类型。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::cout << "least 8: " << sizeof(std::int_least8_t) * 8 << " bits\n";std::cout << "least 16: " << sizeof(std::int_least16_t) * 8 << " bits\n";std::cout << "least 32: " << sizeof(std::int_least32_t) * 8 << " bits\n";std::cout << '\n';std::cout << "fast 8: " << sizeof(std::int_fast8_t) * 8 << " bits\n";std::cout << "fast 16: " << sizeof(std::int_fast16_t) * 8 << " bits\n";std::cout << "fast 32: " << sizeof(std::int_fast32_t) * 8 << " bits\n";return 0;
}
然而,这些快速和最小整数有其自身的缺点:首先,没有多少程序员真正使用它们,缺乏熟悉会导致错误。其次,快速类型会导致内存浪费,因为它们的实际大小可能大于其名称所指示的大小。最严重的是,由于快速/最小整数的大小可能会有所不同,因此程序可能会在解析为不同大小的体系结构上表现出不同的行为。例如:
std::int8_t 和 std::uint8_t 的行为可能像字符而不是整数
由于 C++ 规范中的疏忽,大多数编译器分别定义和处理 std::int8_t 和 std::uint8_t(以及相应的快速和最小固定宽度类型)与有符号字符和无符号字符类型相同。这意味着这些 8 位类型的行为可能(也可能不)与其他固定宽度类型不同,这可能会导致错误。此行为与系统相关,因此在一个体系结构上正常运行的程序可能无法在另一个体系结构上正确编译或运行。
存储整数值时,通常最好避免使用 std::int8_t 和 std::uint8_t(以及相关的快速和最小类型),改用 std::int16_t 或 std::uint16_t。
整型的最佳实践
整型的最佳实践
我们的立场是,正确比快速更好,编译时失败比运行时更好。因此,如果您需要具有固定大小的整型,我们建议避免使用快速/最小类型,而使用固定宽度类型。如果您后来发现需要支持固定宽度类型无法编译的平台,那么您可以在此时决定如何迁移程序(并进行彻底测试)
什么是std::size_t?
很简单,对吧?我们可以推断运算符 sizeof 返回一个整数值 - 但是该返回值是什么整数类型?一个整数?短?答案是 sizeof(以及许多返回大小或长度值的函数)返回 type std::size_t 的值。std::size_t 定义为无符号整型,通常用于表示对象的大小或长度
#include <cstddef> // for std::size_t
#include <iostream>int main()
{std::cout << sizeof(std::size_t) << '\n';return 0;
}
就像整数的大小可以根据系统而变化一样, std::size_t 大小也会有所不同。 std::size_t 保证无符号且至少为 16 位,但在大多数系统上将等效于应用程序的地址宽度。也就是说,对于 32 位应用程序,通常是 32 位无符号整数,对于 64 位应用程序, std::size_t std::size_t 通常是 64 位无符号整数。
一些编译器将最大的可创建对象限制为最大值 std::size_t 的一半(可以在此处找到对此的良好解释).实际上,最大的可创建对象可能小于此数量(可能明显小于此数量),具体取决于计算机可用于分配的连续内存量。
科学记数法简介
科学计数法是一种很长数字的有限简写,了解科学计数法帮助你了解浮点数工作原理,以及科学计数法的界限。
科学记数法中的数字采用以下形式:有效数 x 10 exponent 。例如,在科学记数法中 1.2 x 10⁴ , 1.2 是有效数, 4 是指数。由于 10⁴ 的计算结果为 10,000,因此 1.2 x 10⁴ 的计算结果为 12,000。
科学记数法还有一个额外的好处,即只需比较指数,就可以更轻松地比较两个非常大或非常小的数字的大小。
由于很难在C++中键入或显示指数,因此我们使用字母“e”(有时使用“E”)来表示等式的“乘以 10 的幂”部分。例如, 将写为 , 1.2 x 10⁴ 写成1.2e4,并将 5.9736 x 10²⁴ 写为 5.9736e24 `` 。
在标准科学记数法中,我们更喜欢保留小数点后的任何尾随零,因为这些数字传递了有关数字精度的有用信息。
浮点数
整数非常适合计算整数,但有时我们需要存储非常大的数字,或者带有分数分量的数字。浮点类型变量是可以保存带有分数分量的数字的变量,例如 4320.0、-3.33 或 0.01226。名称浮点的浮点部分是指小数点可以“浮点”的事实;也就是说,它可以支持小数点前后的可变位数。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::int16_t i{5};std::cout << i << '\n';return 0;
}
固定宽度的整数有两个缺点,通常会引发。
首先,不保证在所有体系结构上定义固定宽度的整数。它们仅存在于存在与其宽度匹配的基本类型并遵循某种二进制表示的系统上。程序将无法在不支持程序正在使用的固定宽度整数的任何此类体系结构上进行编译。但是,鉴于大多数现代体系结构都标准化了 8/16/32/64 位变量,这不太可能成为问题,除非您的程序需要移植到一些外来的大型机或嵌入式体系结构。
其次,如果使用固定宽度的整数,则在某些体系结构上,它可能比更宽的类型慢。例如,如果您需要一个保证为 32 位的整数,您可能会决定使用 std::int32_t ,但您的 CPU 实际上在处理 64 位整数时可能更快。但是,仅仅因为您的 CPU 可以更快地处理给定类型并不意味着您的程序整体会更快 - 现代程序通常受到内存使用而不是 CPU 的限制,并且较大的内存占用可能会比更快的 CPU 处理加速它更慢您的程序。
快速整数和最小整数
为了帮助解决上述缺点,C++还定义了两组保证定义的备用整数集。
快速类型(std::int_fast#_t 和 std::uint_fast#_t)提供宽度至少为 # 位的最快有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::int_fast32_t 将为您提供至少为 32 位的最快有符号整数类型。最快,我们指的是 CPU 可以最快处理的积分类型
最小类型(std::int_least#_t 和 std::uint_least#_t)提供宽度至少为 # 位的最小有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::uint_least32_t 将为您提供至少为 32 位的最小无符号整数类型。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::cout << "least 8: " << sizeof(std::int_least8_t) * 8 << " bits\n";std::cout << "least 16: " << sizeof(std::int_least16_t) * 8 << " bits\n";std::cout << "least 32: " << sizeof(std::int_least32_t) * 8 << " bits\n";std::cout << '\n';std::cout << "fast 8: " << sizeof(std::int_fast8_t) * 8 << " bits\n";std::cout << "fast 16: " << sizeof(std::int_fast16_t) * 8 << " bits\n";std::cout << "fast 32: " << sizeof(std::int_fast32_t) * 8 << " bits\n";return 0;
}
然而,这些快速和最小整数有其自身的缺点:首先,没有多少程序员真正使用它们,缺乏熟悉会导致错误。其次,快速类型会导致内存浪费,因为它们的实际大小可能大于其名称所指示的大小。最严重的是,由于快速/最小整数的大小可能会有所不同,因此程序可能会在解析为不同大小的体系结构上表现出不同的行为。例如:
std::int8_t 和 std::uint8_t 的行为可能像字符而不是整数
由于 C++ 规范中的疏忽,大多数编译器分别定义和处理 std::int8_t 和 std::uint8_t(以及相应的快速和最小固定宽度类型)与有符号字符和无符号字符类型相同。这意味着这些 8 位类型的行为可能(也可能不)与其他固定宽度类型不同,这可能会导致错误。此行为与系统相关,因此在一个体系结构上正常运行的程序可能无法在另一个体系结构上正确编译或运行。
存储整数值时,通常最好避免使用 std::int8_t 和 std::uint8_t(以及相关的快速和最小类型),改用 std::int16_t 或 std::uint16_t。
整型的最佳实践
整型的最佳实践
我们的立场是,正确比快速更好,编译时失败比运行时更好。因此,如果您需要具有固定大小的整型,我们建议避免使用快速/最小类型,而使用固定宽度类型。如果您后来发现需要支持固定宽度类型无法编译的平台,那么您可以在此时决定如何迁移程序(并进行彻底测试)
什么是std::size_t?
很简单,对吧?我们可以推断运算符 sizeof 返回一个整数值 - 但是该返回值是什么整数类型?一个整数?短?答案是 sizeof(以及许多返回大小或长度值的函数)返回 type std::size_t 的值。std::size_t 定义为无符号整型,通常用于表示对象的大小或长度
#include <cstddef> // for std::size_t
#include <iostream>int main()
{std::cout << sizeof(std::size_t) << '\n';return 0;
}
就像整数的大小可以根据系统而变化一样, std::size_t 大小也会有所不同。 std::size_t 保证无符号且至少为 16 位,但在大多数系统上将等效于应用程序的地址宽度。也就是说,对于 32 位应用程序,通常是 32 位无符号整数,对于 64 位应用程序, std::size_t std::size_t 通常是 64 位无符号整数。
一些编译器将最大的可创建对象限制为最大值 std::size_t 的一半(可以在此处找到对此的良好解释).实际上,最大的可创建对象可能小于此数量(可能明显小于此数量),具体取决于计算机可用于分配的连续内存量。
科学记数法简介
科学计数法是一种很长数字的有限简写,了解科学计数法帮助你了解浮点数工作原理,以及科学计数法的界限。
科学记数法中的数字采用以下形式:有效数 x 10 exponent 。例如,在科学记数法中 1.2 x 10⁴ , 1.2 是有效数, 4 是指数。由于 10⁴ 的计算结果为 10,000,因此 1.2 x 10⁴ 的计算结果为 12,000。
科学记数法还有一个额外的好处,即只需比较指数,就可以更轻松地比较两个非常大或非常小的数字的大小。
由于很难在C++中键入或显示指数,因此我们使用字母“e”(有时使用“E”)来表示等式的“乘以 10 的幂”部分。例如, 将写为 , 1.2 x 10⁴ 写成1.2e4,并将 5.9736 x 10²⁴ 写为 5.9736e24 `` 。
在标准科学记数法中,我们更喜欢保留小数点后的任何尾随零,因为这些数字传递了有关数字精度的有用信息。
浮点数
整数非常适合计算整数,但有时我们需要存储非常大的数字,或者带有分数分量的数字。浮点类型变量是可以保存带有分数分量的数字的变量,例如 4320.0、-3.33 或 0.01226。名称浮点的浮点部分是指小数点可以“浮点”的事实;也就是说,它可以支持小数点前后的可变位数。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::int16_t i{5};std::cout << i << '\n';return 0;
}
固定宽度的整数有两个缺点,通常会引发。
首先,不保证在所有体系结构上定义固定宽度的整数。它们仅存在于存在与其宽度匹配的基本类型并遵循某种二进制表示的系统上。程序将无法在不支持程序正在使用的固定宽度整数的任何此类体系结构上进行编译。但是,鉴于大多数现代体系结构都标准化了 8/16/32/64 位变量,这不太可能成为问题,除非您的程序需要移植到一些外来的大型机或嵌入式体系结构。
其次,如果使用固定宽度的整数,则在某些体系结构上,它可能比更宽的类型慢。例如,如果您需要一个保证为 32 位的整数,您可能会决定使用 std::int32_t ,但您的 CPU 实际上在处理 64 位整数时可能更快。但是,仅仅因为您的 CPU 可以更快地处理给定类型并不意味着您的程序整体会更快 - 现代程序通常受到内存使用而不是 CPU 的限制,并且较大的内存占用可能会比更快的 CPU 处理加速它更慢您的程序。
快速整数和最小整数
为了帮助解决上述缺点,C++还定义了两组保证定义的备用整数集。
快速类型(std::int_fast#_t 和 std::uint_fast#_t)提供宽度至少为 # 位的最快有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::int_fast32_t 将为您提供至少为 32 位的最快有符号整数类型。最快,我们指的是 CPU 可以最快处理的积分类型
最小类型(std::int_least#_t 和 std::uint_least#_t)提供宽度至少为 # 位的最小有符号/无符号整数类型(其中 # = 8、16、32 或 64)。例如,std::uint_least32_t 将为您提供至少为 32 位的最小无符号整数类型。
#include <cstdint> // for fixed-width integers
#include <iostream>int main()
{std::cout << "least 8: " << sizeof(std::int_least8_t) * 8 << " bits\n";std::cout << "least 16: " << sizeof(std::int_least16_t) * 8 << " bits\n";std::cout << "least 32: " << sizeof(std::int_least32_t) * 8 << " bits\n";std::cout << '\n';std::cout << "fast 8: " << sizeof(std::int_fast8_t) * 8 << " bits\n";std::cout << "fast 16: " << sizeof(std::int_fast16_t) * 8 << " bits\n";std::cout << "fast 32: " << sizeof(std::int_fast32_t) * 8 << " bits\n";return 0;
}
然而,这些快速和最小整数有其自身的缺点:首先,没有多少程序员真正使用它们,缺乏熟悉会导致错误。其次,快速类型会导致内存浪费,因为它们的实际大小可能大于其名称所指示的大小。最严重的是,由于快速/最小整数的大小可能会有所不同,因此程序可能会在解析为不同大小的体系结构上表现出不同的行为。例如:
std::int8_t 和 std::uint8_t 的行为可能像字符而不是整数
由于 C++ 规范中的疏忽,大多数编译器分别定义和处理 std::int8_t 和 std::uint8_t(以及相应的快速和最小固定宽度类型)与有符号字符和无符号字符类型相同。这意味着这些 8 位类型的行为可能(也可能不)与其他固定宽度类型不同,这可能会导致错误。此行为与系统相关,因此在一个体系结构上正常运行的程序可能无法在另一个体系结构上正确编译或运行。
存储整数值时,通常最好避免使用 std::int8_t 和 std::uint8_t(以及相关的快速和最小类型),改用 std::int16_t 或 std::uint16_t。
整型的最佳实践
整型的最佳实践
我们的立场是,正确比快速更好,编译时失败比运行时更好。因此,如果您需要具有固定大小的整型,我们建议避免使用快速/最小类型,而使用固定宽度类型。如果您后来发现需要支持固定宽度类型无法编译的平台,那么您可以在此时决定如何迁移程序(并进行彻底测试)
什么是std::size_t?
很简单,对吧?我们可以推断运算符 sizeof 返回一个整数值 - 但是该返回值是什么整数类型?一个整数?短?答案是 sizeof(以及许多返回大小或长度值的函数)返回 type std::size_t 的值。std::size_t 定义为无符号整型,通常用于表示对象的大小或长度
#include <cstddef> // for std::size_t
#include <iostream>int main()
{std::cout << sizeof(std::size_t) << '\n';return 0;
}
就像整数的大小可以根据系统而变化一样, std::size_t 大小也会有所不同。 std::size_t 保证无符号且至少为 16 位,但在大多数系统上将等效于应用程序的地址宽度。也就是说,对于 32 位应用程序,通常是 32 位无符号整数,对于 64 位应用程序, std::size_t std::size_t 通常是 64 位无符号整数。
一些编译器将最大的可创建对象限制为最大值 std::size_t 的一半(可以在此处找到对此的良好解释).实际上,最大的可创建对象可能小于此数量(可能明显小于此数量),具体取决于计算机可用于分配的连续内存量。
科学记数法简介
科学计数法是一种很长数字的有限简写,了解科学计数法帮助你了解浮点数工作原理,以及科学计数法的界限。
科学记数法中的数字采用以下形式:有效数 x 10 exponent 。例如,在科学记数法中 1.2 x 10⁴ , 1.2 是有效数, 4 是指数。由于 10⁴ 的计算结果为 10,000,因此 1.2 x 10⁴ 的计算结果为 12,000。
科学记数法还有一个额外的好处,即只需比较指数,就可以更轻松地比较两个非常大或非常小的数字的大小。
由于很难在C++中键入或显示指数,因此我们使用字母“e”(有时使用“E”)来表示等式的“乘以 10 的幂”部分。例如, 将写为 , 1.2 x 10⁴ 写成1.2e4,并将 5.9736 x 10²⁴ 写为 5.9736e24 `` 。
在标准科学记数法中,我们更喜欢保留小数点后的任何尾随零,因为这些数字传递了有关数字精度的有用信息。
布尔值
布尔变量
布尔变量是只能有两个可能值的变量:true 和 false。
bool b;
整数到布尔值的转换
不能使用统一初始化来初始化具有整数的布尔值,整数 0 将转换为 false,任何其他整数将转换为 true。
#include <iostream>int main()
{bool b{ 4 }; // error: narrowing conversions disallowedstd::cout << b << '\n';return 0;
}
输入布尔值
#include <iostream>int main()
{bool b{}; // default initialize to falsestd::cout << "Enter a boolean value: ";std::cin >> b;std::cout << "You entered: " << b << '\n';return 0;
}
Enter a Boolean value: true
You entered: 0
事实证明,std::cin 只接受布尔变量的两个输入:0 和 1(不为真或假)。任何其他输入都会导致 std::cin 静默失败。
if 语句简介
if (condition) true_statement;
使用 if 语句的示例程序
#include <iostream>int main()
{std::cout << "Enter an integer: ";int x {};std::cin >> x;if (x == 0)std::cout << "The value is zero\n";return 0;
}
If-else
#include <iostream>int main()
{std::cout << "Enter an integer: ";int x {};std::cin >> x;if (x == 0)std::cout << "The value is zero\n";elsestd::cout << "The value is non-zero\n";return 0;
}
链接 if 语句
#include <iostream>int main()
{std::cout << "Enter an integer: ";int x {};std::cin >> x;if (x > 0)std::cout << "The value is positive\n";else if (x < 0)std::cout << "The value is negative\n";elsestd::cout << "The value is zero\n";return 0;
}
链接 if 语句
有时我们想按顺序检查几件事是真的还是假的。我们可以通过将 if 语句(或 if-else)链接到先前的 if-else 来做到这一点,如下所示:
#include <iostream>int main()
{std::cout << "Enter an integer: ";int x {};std::cin >> x;if (x > 0)std::cout << "The value is positive\n";else if (x < 0)std::cout << "The value is negative\n";elsestd::cout << "The value is zero\n";return 0;
}
布尔返回值和 if 语句
#include <iostream>// returns true if x and y are equal, false otherwise
bool isEqual(int x, int y)
{return (x == y); // operator== returns true if x equals y, and false otherwise
}int main()
{std::cout << "Enter an integer: ";int x {};std::cin >> x;std::cout << "Enter another integer: ";int y {};std::cin >> y;std::cout << std::boolalpha; // print bools as true or falsestd::cout << x << " and " << y << " are equal? ";std::cout << isEqual(x, y); // will return true or falsestd::cout << '\n';return 0;
}
非布尔条件
在这种情况下,条件表达式将转换为布尔值:非零值将转换为布尔值 true,零值将转换为布尔值 false。
Chars
char 数据类型旨在保存单个 character .字符可以是单个字母、数字、符号或空格。
char 数据类型是整型类型,这意味着基础值存储为整数。与布尔值 0 被解释为和非零被解释为 false true 类似,变量存储 char 的整数被理解为 ASCII character
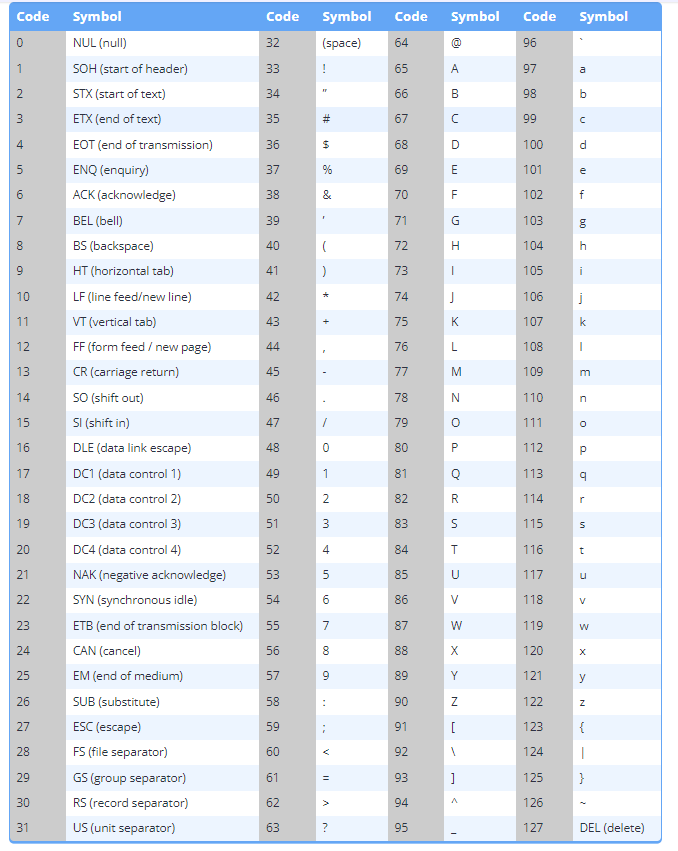
代码 0-31 称为不可打印字符,它们主要用于格式化和控制打印机。其中大多数现在已经过时了。如果您尝试打印这些字符,结果取决于您的操作系统(您可能会得到一些类似表情符号的字符)。
代码 32-127 称为可打印字符,它们表示大多数计算机用于显示基本英语文本的字母、数字字符和标点符号。
初始化字符
char ch2{ 'a' }; // initialize with code point for 'a' (stored as integer 97) (preferred)
打印字符
使用 std::cout 打印字符时,std::cout 将 char 变量输出为 ASCII 字符
输入字符
#include <iostream>int main()
{std::cout << "Input a keyboard character: ";char ch{};std::cin >> ch;std::cout << "You entered: " << ch << '\n';return 0;
}
Input a keyboard character: q
You entered: q
请注意,std::cin 将允许您输入多个字符。但是,变量 ch 只能容纳 1 个字符。因此,只有第一个输入字符被提取到变量 ch 中。其余的用户输入保留在 std::cin 使用的输入缓冲区中,可以通过后续调用 std::cin 来提取。
字符大小、范围和默认符号
字符由 C++ 定义为大小始终为 1 个字节。
如果使用 char 来保存小整数(除非显式优化空间,否则不应执行此操作),则应始终指定它是有符号的还是无符号的。有符号字符可以包含 -128 到 127 之间的数字。无符号字符可以包含 0 到 255 之间的数字。
转义序列
C++中有一些字符具有特殊含义。这些字符称为转义序列。转义序列以“\”(反斜杠)字符开头,然后是后面的字母或数字。\n \t ’ 打印单引号 \“ 打印双引号 \ 打印反斜杠
将符号放在单引号和双引号中有什么区别?
单字符总是放在单引号中(例如、 ‘a’ 、 ‘+’ ‘5’ )。一个字符只能代表一个符号(例如字母a,加号,数字5)。
双引号之间的文本(例如“Hello, world!”)被视为由多个字符组成的字符串。我们在课 4.15 – 文字中讨论字符串。
其他字符类型(wchar_t、char16_t 和char32_t)呢?
在几乎所有情况下都应避免wchar_t。它的大小是实现定义的,并且不可靠。它在很大程度上已被弃用。
类型转换和static_cast简介
隐式类型转换
编译器在没有我们明确询问的情况下代表我们进行类型转换时,我们称之为隐式类型转换。
类型转换生成新值
即使称为转换,类型转换实际上也不会更改要转换的值的值或类型。相反,要转换的值将用作输入,并且转换将生成目标类型的新值。
隐式类型转换警告
由于将浮点值转换为整数值会导致删除任何分数
通过static_cast运算符进行显式类型转换简介
static_cast<new_type>(expression)
#include <iostream>void print(int x)
{std::cout << x << '\n';
}int main()
{print( static_cast<int>(5.5) ); // explicitly convert double value 5.5 to an intreturn 0;
}
由于我们现在显式请求将双精度值转换为 int 值 5.5 ,因此编译器不会在编译时生成有关数据丢失的警告(这意味着我们可以启用“将警告视为错误”)。
使用 static_cast 将字符转换为 int
#include <iostream>int main()
{char ch{ 97 }; // 97 is ASCII code for 'a'std::cout << ch << '\n';return 0;
}
将无符号数字转换为有符号数字
要将无符号数字转换为有符号数字,还可以使用以下 static_cast 运算符:
#include <iostream>int main()
{unsigned int u { 5 };int s { static_cast<int>(u) }; // return value of variable u as an intstd::cout << s << '\n';return 0;
}
运算符 static_cast 不执行任何范围检查,因此,如果将值强制转换为范围不包含该值的类型,则会导致未定义的行为。因此,如果 的值 unsigned int 大于签名 int 可以保存的最大值,则上述 from unsigned int to int 转换将产生不可预测的结果。
std::int8_t 和 std::uint8_t 的行为可能像字符而不是整数
常量变量和符号常量
必须初始化常量变量
常量变量必须在定义时初始化,然后不能通过赋值更改该值:
int main()
{const double gravity; // error: const variables must be initializedgravity = 9.9; // error: const variables can not be changedreturn 0;
}
请注意,const 变量可以从其他变量(包括非 const 变量)初始化
命名常量变量
有许多不同的命名约定用于常量变量。从 C 转换的程序员通常更喜欢 const 变量的下划线大写名称(例如 EARTH_GRAVITY )。C++中更常见的是使用带有“k”前缀的间盖名称(例如 kEarthGravity )。
但是,由于 const 变量的行为类似于普通变量(除了它们不能被赋值),因此它们没有理由需要特殊的命名约定。出于这个原因,我们更喜欢使用与非常量变量相同的命名约定(例如 earthGravity )
常量函数参数
按值传递时不要使用 const 。
常量返回值
按值返回时不要使用 const
什么是符号常数?
符号常量是赋予常量值的名称。常量变量是一种类型的符号常量,因为变量具有名称(其标识符)和常量值
对于符号常量,首选常量变量而不是类似对象的宏
首先,由于宏由预处理器解析,因此宏的所有匹配项都将在编译之前替换为定义的值。如果你正在调试代码,你不会看到实际值(例如) 30 ——你只会看到符号常量的名称(例如)。 MAX_STUDENTS_PER_CLASS 由于这些 #defined 值不是变量,因此无法在调试器中添加监视以查看其值。如果你想知道解析为什么值 MAX_STUDENTS_PER_CLASS ,你必须找到的定义 MAX_STUDENTS_PER_CLASS (它可能在不同的文件中)。这会使程序更难调试。
其次,宏可能与普通代码存在命名冲突。例如:
第三,宏不遵循正常的范围规则,这意味着在极少数情况下,在程序的一部分中定义的宏可能会与在程序的另一部分中编写的代码发生冲突,而这些代码不应该与之交互
在整个多文件程序中使用常量变量
在许多应用程序中,需要在整个代码中使用给定的符号常量(而不仅仅是在一个位置)。这些可以包括不变的物理或数学常数(例如 pi 或阿伏伽德罗数),或特定于应用的“调整”值(例如摩擦或重力系数)。与其在每次需要它们时都重新定义它们,不如在中心位置声明它们一次,并在需要的地方使用它们。这样,如果您需要更改它们,只需在一个地方更改它们。
编译时常量、常量表达式和 constexpr
常量表达式
常量表达式是编译器可在编译时计算的表达式。要成为常量表达式,表达式中的所有值必须在编译时已知(并且调用的所有运算符和函数都必须支持编译时计算)。
当编译器遇到常量表达式时,它可以在编译时计算表达式,然后将常量表达式替换为计算结果。
key insight:
在编译时计算常量表达式会使我们的编译花费更长的时间(因为编译器必须做更多的工作),但这样的表达式只需要计算一次(而不是每次程序运行时)。生成的可执行文件速度更快,占用的内存更少。
关键字 constexpr
声明 const 变量时,编译器将隐式跟踪它是运行时常量还是编译时常量。在大多数情况下,除了优化目的之外,这无关紧要,但在某些情况下,C++需要一个常量表达式(我们将在稍后介绍这些主题时介绍这些情况)。并且只有编译时常量变量才能在常量表达式中使用。
由于编译时常量也允许更好的优化(并且几乎没有缺点),因此我们通常希望尽可能使用编译时常量。
使用 const 时,我们的变量可能最终成为编译时常量或运行时常量,具体取决于初始值设定项是否是编译时表达式。在某些情况下,很难判断 const 变量是编译时 const(在常量表达式中可用)还是运行时 const(在常量表达式中不可用)。
int x { 5 }; // not const at all
const int y { x }; // obviously a runtime const (since initializer is non-const)
const int z { 5 }; // obviously a compile-time const (since initializer is a constant expression)
const int w { getValue() }; // not obvious whether this is a runtime or compile-time const
幸运的是,我们可以寻求编译器的帮助,以确保我们在需要的地方获得编译时常量。为此,我们使用 constexpr 关键字而不是变量的声明 const 。constexpr(“常量表达式”的缩写)变量只能是编译时常量。如果 constexpr 变量的初始化值不是常量表达式,编译器将出错。
#include <iostream>int five()
{return 5;
}int main()
{constexpr double gravity { 9.8 }; // ok: 9.8 is a constant expressionconstexpr int sum { 4 + 5 }; // ok: 4 + 5 is a constant expressionconstexpr int something { sum }; // ok: sum is a constant expressionstd::cout << "Enter your age: ";int age{};std::cin >> age;constexpr int myAge { age }; // compile error: age is not a constant expressionconstexpr int f { five() }; // compile error: return value of five() is not a constant expressionreturn 0;
}
Best practice:
任何在初始化后不可修改且其初始值设定项在编译时已知且应声明为 constexpr .
初始化后不应修改且其初始值设定项在编译时未知的任何变量都应声明为 const 。
常量和常量函数参数
普通函数调用在运行时计算,提供的参数用于初始化函数的参数。这意味着 const 函数参数被视为运行时常量,即使提供的参数是编译时常量也是如此。
由于 constexpr 对象必须使用编译时常量(而不是运行时常量)进行初始化,因此不能将函数参数声明为 constexpr 。
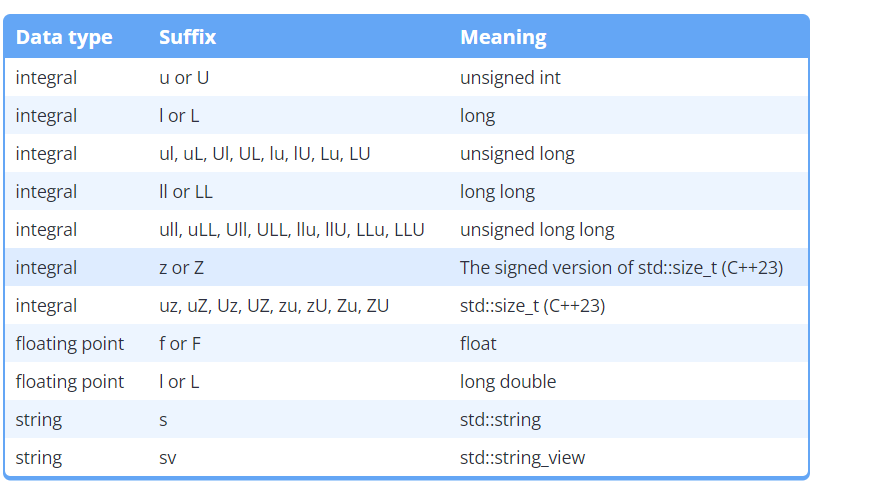
字变量
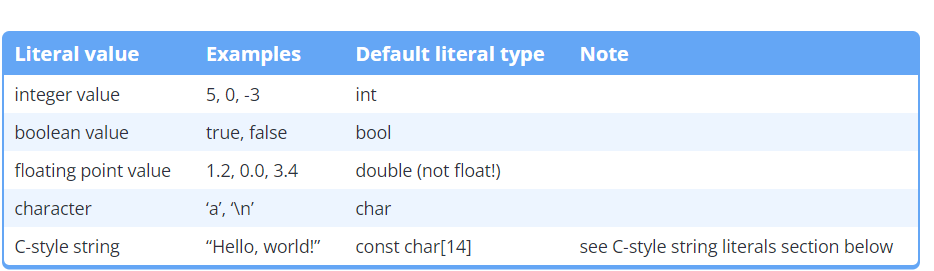
前缀
幻数
幻数是一个字面(通常是数字),含义不明确或以后可能需要更改。
constexpr int maxStudentsPerSchool{ numClassrooms * 30 };
setMax(30);
要避免在代码中使用幻数
数字系统(十进制、二进制、十六进制和八进制)
十进制和二进制是数字系统的两个例子,它是用于表示数字的符号(例如数字)集合的花哨名称。C++有 4 种主要的数字系统。按流行程度排序,它们是:十进制(以 10 为基数)、二进制(以 2 为基数)、十六进制(以 16 为基数)和八进制(以 8 为基数)。
要使用八进制文本,请在文本前面加上 0(零)。八进制几乎从未使用过,我们建议您避免使用。
要使用十六进制文本,请在文本前面加上 0x。
在 C++14 中,我们可以通过使用 0b 前缀来使用二进制文字
默认情况下,C++以十进制输出值。但是,您可以通过使用 std::dec 、 std::oct 和 std::hex I/O 操纵器更改输出格式
#include <iostream>int main()
{int x { 12 };std::cout << x << '\n'; // decimal (by default)std::cout << std::hex << x << '\n'; // hexadecimalstd::cout << x << '\n'; // now hexadecimalstd::cout << std::oct << x << '\n'; // octalstd::cout << std::dec << x << '\n'; // return to decimalstd::cout << x << '\n'; // decimalreturn 0;
}
字符串简介
在 C++ 中处理字符串和字符串对象的最简单方法是通过 std::string 位于标头中的类型。
请注意,字符串也可以由数字字符组成:
std::string myID{ "45" }; // "45" is not the same as integer 45!
在字符串形式中,数字被视为文本,而不是数字,因此它们不能作为数字进行操作(例如,你不能将它们相乘)。C++不会自动将字符串转换为整数或浮点值,反之亦然(尽管有一些方法可以做到这一点,我们将在以后的课程中介绍)。
事实证明,当用于 operator>> 从 std::cin 中提取 operator>> 字符串时,仅返回它遇到的第一个空格的字符。任何其他字符都留在里面 std::cin ,等待下一次提取。
用于 std::getline() 输入文本
#include <iostream>
#include <string> // For std::string and std::getlineint main()
{std::cout << "Enter your full name: ";std::string name{};std::getline(std::cin >> std::ws, name); // read a full line of text into namestd::cout << "Enter your favorite color: ";std::string color{};std::getline(std::cin >> std::ws, color); // read a full line of text into colorstd::cout << "Your name is " << name << " and your favorite color is " << color << '\n';return 0;
}
到底是什么 std::ws ?
std::ws 输入操纵器告诉 std::cin 在提取之前忽略任何前导空格。前导空格是出现在字符串开头的任何空格字符(空格、制表符、换行符)。
std::string 的长度
#include <iostream>
#include <string>int main()
{std::string name{ "Alex" };std::cout << name << " has " << name.length() << " characters\n";return 0;
}
该 length() 函数不是普通的独立函数 - 它是一种特殊类型的函数,嵌套在称为成员函数中 std::string 。因为成员函数是在 length() 内部 std::string 声明的,所以它有时被写 std::string::length() 成在文档中。在 C++20 中,您还可以使用该 std::ssize() 函数获取 a std::string 的长度作为有符号整数值
#include <iostream>
#include <string>int main()
{std::string name{ "Alex" };std::cout << name << " has " << std::ssize(name) << " characters\n";return 0;
}
std::string 初始化和复制可能很昂贵
每当初始化 时 std::string ,都会创建用于初始化它的字符串的副本。每当 a std::string 按值传递给 std::string 参数时,就会创建另一个副本。复制字符串的成本很高,应尽可能避免。
Literals for std::string
我们可以通过在双引号字符串文字后使用后 s 缀来创建带有类型的 std::string 字符串文字。
using namespace std::string_literals; // easy access to the s suffix
Constexpr strings Constexpr
如果尝试定义 constexpr std::string ,编译器可能会生成错误,发生这种情况是因为 constexpr std::string 在 C++17 或更早版本中根本不支持,并且在 C++20/23 中仅适用于非常有限的情况。
std::string_view简介
为了解决初始化(或复制)成本高昂的问题 std::string ,引入了 std::string_view C++17(位于标头中)。 std::string_view 提供对现有字符串(C 样式字符串、A std::string 或其他 std::string_view 字符串)的只读访问,而无需创建副本。只读意味着我们可以访问和使用正在查看的值,但我们不能修改它。
std::string_view 参数将接受许多不同类型的字符串参数
C 样式字符串和 a std::string 都将隐式转换为 std::string_view .因此, std::string_view 参数将接受 C 样式字符串、a std::string 或 std::string_view
std::string_view 不会隐式转换为 std::string
因为复制其初始值设定项(这很昂贵)。 但是,如果需要,我们有两种选择:
1.显式创建带有 std::string_view 初始值设定项的 ( std::string 这是允许的,因为很少会无意中这样做)
2.将现有 std::string_view 转换为 std::string 使用 static_cast
更改 std::string_view 正在查看的内容
#include <iostream>
#include <string>
#include <string_view>int main()
{std::string name { "Alex" };std::string_view sv { name }; // sv is now viewing namestd::cout << sv << '\n'; // prints Alexsv = "John"; // sv is now viewing "John" (does not change name)std::cout << sv << '\n'; // prints Johnstd::cout << name << '\n'; // prints Alexreturn 0;
}
std::string_view 文字
可以通过在双引号字符串文字后使用后 sv 缀来创建带有类型的 std::string_view 字符串文字。
constexpr std::string_view
std::string_view 完全 std::string 支持 constexpr
#include <iostream>
#include <string_view>int main()
{constexpr std::string_view s{ "Hello, world!" }; // s is a string symbolic constantstd::cout << s << '\n'; // s will be replaced with "Hello, world!" at compile-timereturn 0;
}
std::string_view
您可能想知道为什么要 std::string 制作其初始值设定项的昂贵副本。实例化对象时,将为该对象分配内存,以存储它在其整个生存期内需要使用的任何数据。此内存是为对象保留的,并保证只要对象存在,就会存在。这是一个安全的空间。 std::string (和大多数其他对象)将它们给定的初始化值复制到此内存中,以便它们可以具有自己的独立值以供以后访问和操作。复制初始化值后,对象不再以任何方式依赖于初始值设定项。
请务必注意,a std::string_view 在其生存期内始终依赖于初始值设定项。如果在视图仍在使用时修改或销毁正在查看的字符串,则会导致意外或未定义的行为。
std::string_view 最好用作只读函数参数
使用 std::string_view 不当
#include <iostream>
#include <string>
#include <string_view>int main()
{std::string_view sv{};{ // create a nested blockstd::string s{ "Hello, world!" }; // create a std::string local to this nested blocksv = s; // sv is now viewing s} // s is destroyed here, so sv is now viewing an invalid stringstd::cout << sv << '\n'; // undefined behaviorreturn 0;
}
关于何时使用与 std::string_view 何时使用的 std::string 快速指南
在以下情况下使用 std::string 变量:
-
您需要一个可以修改的字符串。
-
您需要存储用户输入的文本。
-
您需要存储返回 . std::string
在以下情况下使用 std::string_view 变量:
-
您需要对已在其他地方存在的部分或全部字符串进行只读访问,并且在使用完成之前 std::string_view 不会被修改或销毁。
-
您需要 C 样式字符串的符号常量。
-
需要继续查看返回 C 样式字符串或非悬空字符串的函数的返回值 std::string_view 。
在以下情况下使用 std::string 函数参数:
- 该函数需要修改作为参数传入的字符串,而不会影响调用方。这种情况很少见。
- 您正在使用早于 C++17 的语言标准。
- 您符合第 9.5 课 - 通过右值引用传递中涵盖的情况的标准。
在以下情况下使用 std::string_view 函数参数:
该函数需要一个只读字符串。
总结
内存的最小单位是二进制数字,也称为位。可以直接寻址的最小内存单位是一个字节。现代标准是字节等于 8 位。
数据类型告诉编译器如何以某种有意义的方式解释内存的内容。
void 用于指示无类型。它主要用于指示函数不返回值。
不同的类型占用不同的内存量,使用的内存量可能因计算机而异。
sizeof 运算符可用于返回类型的大小(以字节为单位)。
有符号整数用于保存正整数和负整数,包括 0。特定数据类型可以保存的值集称为其范围。使用整数时,请注意溢出和整数除法问题。
无符号整数仅包含正数(和 0),通常应避免使用,除非您正在进行位级操作。
固定宽度整数是具有保证大小的整数,但它们可能并非存在于所有体系结构上。快速整数和最小整数是至少具有一定大小的最快和最小整数。std::int8_t 和 std::uint8_t 通常应该避免,因为它们的行为往往像字符而不是整数。
size_t 是一种无符号整数类型,用于表示对象的大小或长度。
科学记数法是书写冗长数字的速记方法。C++支持科学记数法和浮点数。有效数中的数字(e 之前的部分)称为有效数字。
点数是一组旨在保存实数的类型(包括具有分数分量的类型)。数字的精度定义了它可以在不丢失信息的情况下表示多少位有效数字。当在无法保持那么高的精度的浮点数中存储太多有效数字时,可能会发生舍入错误。舍入误差一直发生,即使是简单的数字,如 0.1。因此,您不应直接比较浮点数。
布尔类型用于存储真值或假值。
if 语句允许我们在某个条件为真时执行一行或多行代码。if 语句的条件表达式被解释为布尔值。
Char 用于存储解释为 ASCII 字符的值。使用字符时,请注意不要混淆 ASCII 代码值和数字。将字符打印为整数值需要使用static_cast。
尖括号通常用于C++来表示需要可参数化类型的内容。这与static_cast一起使用,以确定参数应该转换为哪种数据类型(例如, static_cast(x) 将x转换为int)。
常量是不能更改的值。C++支持两种类型的常量:常量变量和文本。其值无法更改的变量称为常量变量。const 关键字用于使变量常量。
常量表达式是可以在编译时计算的表达式。编译时常量是其值在编译时已知的常量。运行时常量是其初始化值在运行时之前未知的常量。constexpr 变量必须是编译时常量。
文本是直接插入到代码中的值。文本具有类型,文本后缀可用于从默认类型更改文本的类型。
幻数是一个字面(通常是数字),含义不明确或以后可能需要更改。不要在代码中使用幻数。请改用符号常量。
在日常生活中,我们使用十进制数进行计数,十进制数有 10 位数字。计算机使用二进制,只有 2 位数字。C++还支持八进制(以 8 为基数)和十六进制(以 16 为基数)。这些都是数字系统的示例,数字系统是用于表示数字的符号(数字)的集合。
字符串是用于表示文本(如名称、单词和句子)的连续字符的集合。字符串文本始终放在双引号之间。C++中的字符串文本是 C 样式的字符串,它们具有难以使用的奇怪类型。
std::string_view 提供对现有字符串(C 样式字符串文本、std::string 或 char 数组)的只读访问,而无需创建副本。正在查看已销毁的字符串的 有时 std::string_view 称为悬空视图。修改 a std::string 时,所有 std::string 视图都将失效,这意味着这些视图现在无效。使用无效的视图(而不是重新验证它)将产生未定义的行为。