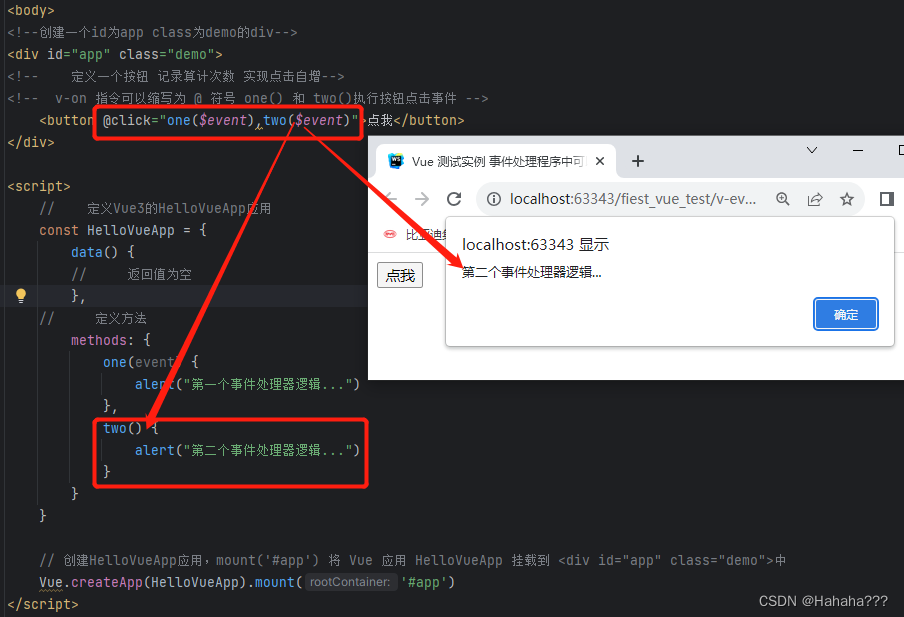
一、样例理解
import pandas as pd
import numpy as np# 创建测试数据
feature_names = ['col1 ', 'col2', 'col3', 'col4', 'col5', 'col6']
values = np.random.randint(20, size=(10,6))dataset = pd.DataFrame(data = values, columns = feature_names)print("转换前的数据为\n",dataset)
print(dataset.dtypes)print("======================================================")# 获取dataframe格式数据的特征名称
feature_names = list(dataset)
print("特征名称为\n",feature_names)# 将特征值转为分类数据
for col in feature_names:dataset[col] = dataset[col].astype('category',copy=False)print("转换后的数据为\n",dataset)
print(dataset.dtypes)

二、dataframe格式数据样例说明
import pandas as pd
import numpy as np
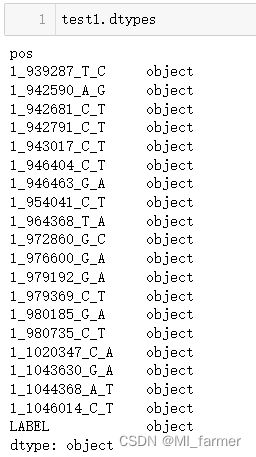
test1 = pd.read_csv('./test.csv',encoding='utf-8',index_col=0)
test1
# 获取特征名称
features = [x for x in test3.columns if x not in ['pos','LABEL']]#将特征数据类型转换为分类数据
for col in features:test2[col] = test2[col].astype('category',copy=False)