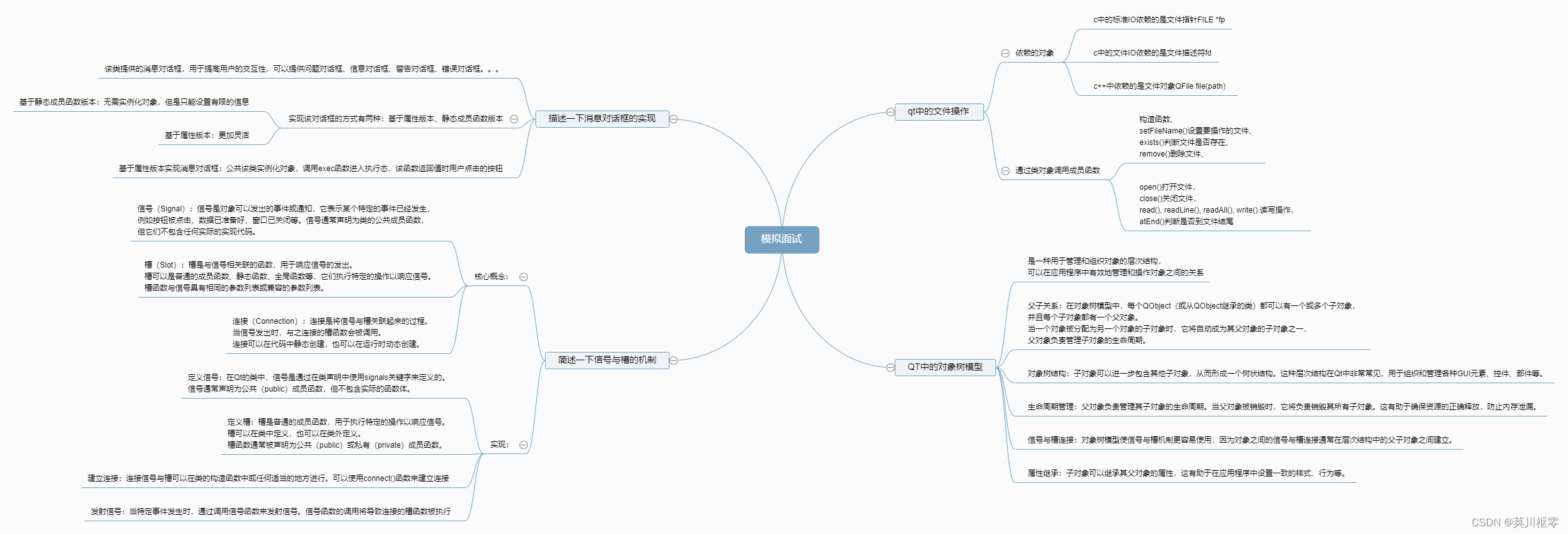
1. 不同存储引擎的索引结构
MySQL5.5版本之前默认采用的是MyISAM引擎,5.5之后默认采用的是Innodb引擎。
1.1. MyISAM存储引擎
MYD文件:数据文件,所有的数据保存在这个文件中。MYI文件 :索引文件。
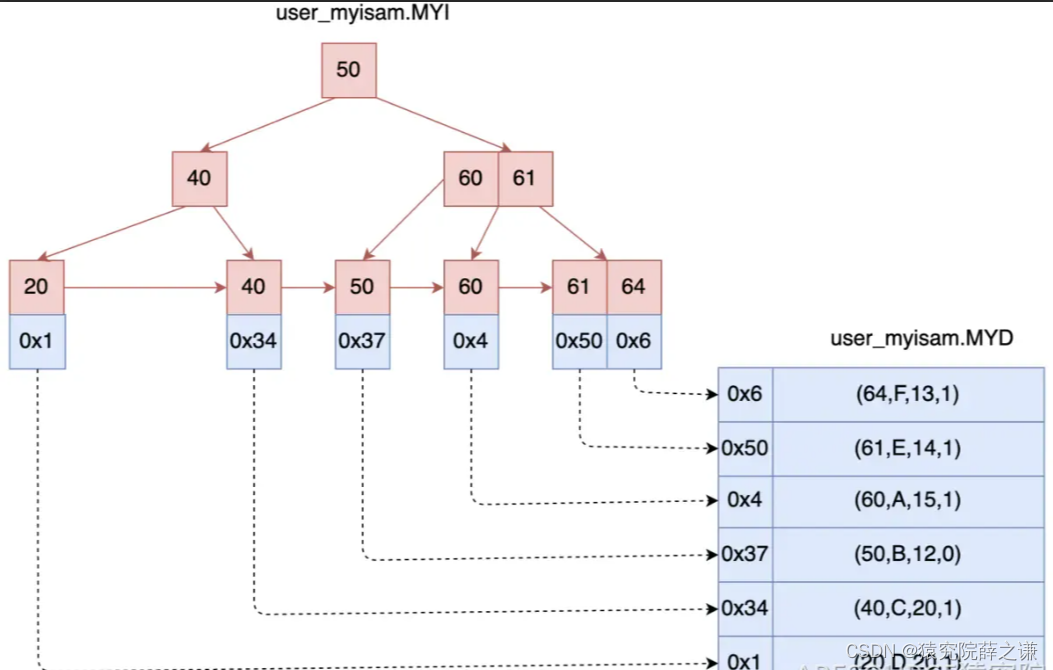
- 如果要查询
id = 40的数据: - 先根据
MyISAM索引文件(user_myisam.MYI)去找id = 40的节点,通过这个节点的数据区拿到真正保存数据的磁盘地址,再通过这个地址从MYD数据文件(user_myisam.MYD)中加载对应的记录。
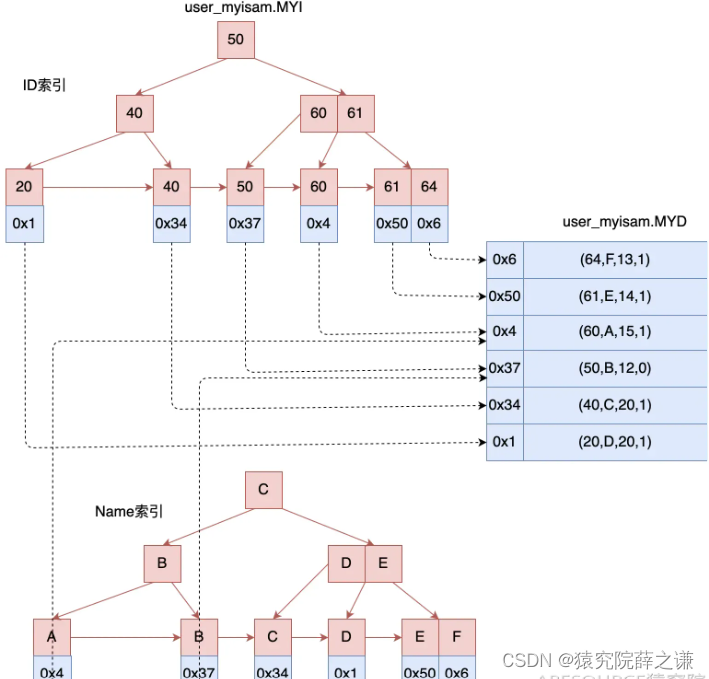
如果有多个索引,在MyISAM存储引擎中,主键索引 和 普通索引(辅助索引)是同级别的,没有主次之分。
5.2. InnoDB存储引擎
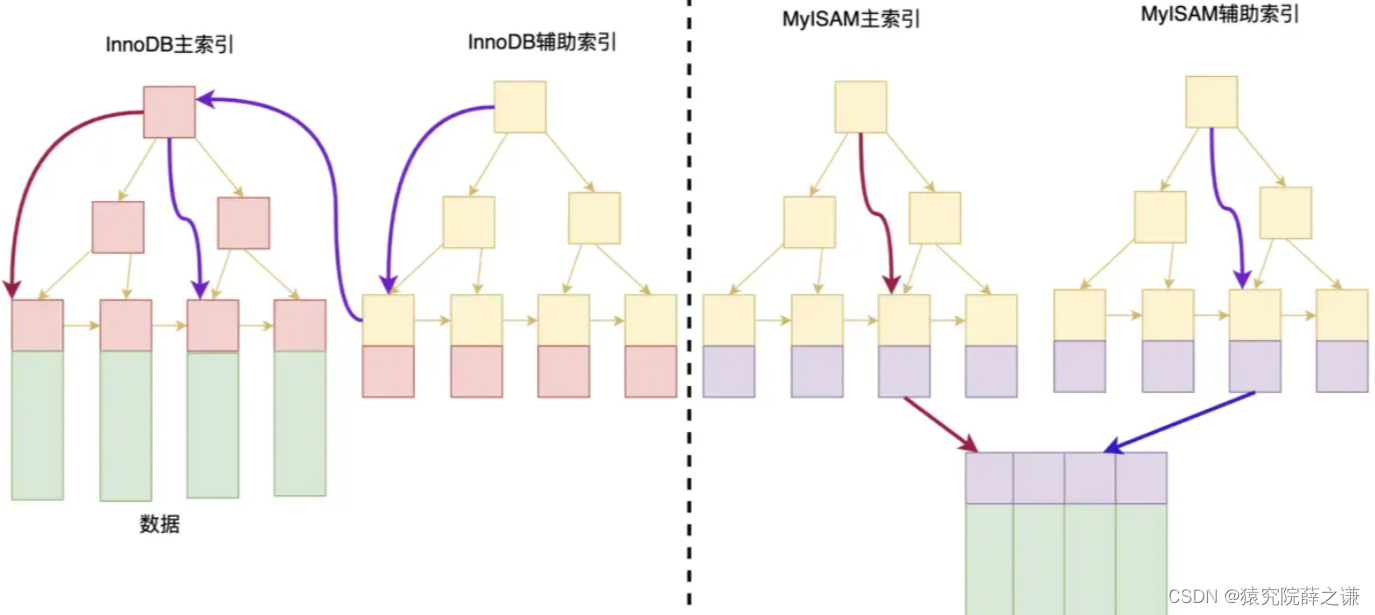
Innodb主键索引是一个聚集索引。
聚集索引的概念:数据库表行中数据的物理顺序和键值的逻辑顺序相同。所以,叶子节点的数据区保存的就是真实的数据,在通过索引进行检索的时候,命中叶子节点,就可以直接从叶子节点中取出行数据。
如果有多个索引,在Innodb存储引擎中,主键索引的叶子节点保存的是真正的数据。而辅助索引叶子节点的数据区保存的是主键索引关键字的值。
假如要查询name = C 的数据,其搜索过程如下:
- 先在辅助索引中通过
C查询最后找到主键id = 9. - 在主键索引中搜索
id=9的数据,最终在主键索引的叶子节点中获取到真正的数据。 - 所以通过辅助索引进行检索,需要检索两次索引。
5.3. B+Tree索引在Innodb 和 在MYISAM的区别
数据存储位置不同。
2.索引失效
索引可以提高查询的速度,但并不是使用带有索引的字段查询时,索引都会起作用。使用索引有几种特殊情况,在这些情况下,有可能使用带有索引的字段查询时,索引并没有起作用,下面重点介绍这几种特殊情况。
通过使用EXPLAIN语句,观察SQL执行计划,检查索引是否生效。
2.1.查询语句中使用LIKE关键字
-- 创建索引
CREATE INDEX index_zhongwenpianming ON north_american_box_office(zhongwenpianming);
-- 成功索引使用等号ref
EXPLAIN SELECT * FROM north_american_box_office
WHERE zhongwenpianming = '狮子王';

type查询类型ref表示使用索引查询,key使用的索引名称。
-- 占位符开头 索引失效all
EXPLAIN SELECT * FROM north_american_box_office
WHERE zhongwenpianming LIKE '%狮';

all表示使用全表查询,索引失效。
-- 内容开头 索引成功range
EXPLAIN SELECT * FROM north_american_box_office
WHERE zhongwenpianming LIKE '狮%';

2.2. 查询语句中使用多列索引
多列索引是在表的多个字段上创建一个索引,只有查询条件中使用了这些字段中的第一个字段,索引才会被使用。
示例:为north_american_box_office表中的shangyingtianshu字段和leijipiaofang字段添加多列索引index_tianshu_piaofang。
CREATE INDEX index_tianshu_piaofang ON north_american_box_office(shangyingtianshu, leijipiaofang);
-- 使用到第一字段 索引有效
EXPLAIN SELECT * FROM north_american_box_office
WHERE (shangyingtianshu BETWEEN 9 AND 13) AND leijipiaofang >=3000

-- 无第一字段内容 索引失效
EXPLAIN SELECT * FROM north_american_box_office
WHERE leijipiaofang >=3000

-- 内容过多 走全表查 索引失效
EXPLAIN SELECT * FROM north_american_box_office
WHERE shangyingtianshu >= 9 AND leijipiaofang >=3000

该索引失效的原因是MySQL在优化器阶段,发现全表扫描比走索引效率更高,因此就放弃使用索引。当MySQL发现通过索引扫描的行记录数超过全表的10%-30%时,优化器可能会放弃走索引,自动变成全表扫描。
类似的问题,在进行范围查询(比如>、< 、>=、<=、in等条件)时往往会出现上述情况。
2.3. 查询语句中使用OR关键字
查询语句只有 OR 关键字时,如果 OR 前后的两个条件的列都是索引,那么查询中将使用索引。如果 OR 前后有一个条件的列不是索引,那么查询中将不使用索引。
-- 索引失效
EXPLAIN SELECT * FROM north_american_box_office
WHERE zhongwenpianming LIKE '狮%' OR leijipiaofang BETWEEN 90 AND 100

虽然OR关键字前的第一个条件中的字段zhongwenpianming虽然存在索引,但是由于多列索引index_tianshu_piaofang并不包含leijipiaofang字段,导致OR关键字后面的条件不存在索引,所以导致整条SQL语句的索引失效。
2.4. 查询语句中使用函数
查询语句中使用函数时,会造成查询中将不使用索引。
EXPLAIN SELECT * FROM north_american_box_office
WHERE length(zhongwenpianming) = 9

3. 索引选择
3.1.列的离散性
离散性计算公式:count(distinct column_name):count(*),即:去重后的列值个数 VS 总个数。
离散度越高,选择性越好。因为离散度越高,通过索引最终确定的范围越小,最终扫描的行数也就越少,索引效率也就越高。
3.2. 为经常需要排序、分组和联合操作的字段建立
经常需要 ORDER BY、GROUP BY、DISTINCT 和 UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
3.3. 为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
3.4. 限制索引的数目
索引的数目不是“越多越好”。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。在修改表的内容时,索引必须进行更新,有时还可能需要重构。因此,索引越多,更新表的时间就越长。
注意避免冗余索引 ,冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。例如:(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。
3.5. 数据量小的表最好不要使用索引
由于数据较小,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
3.6. 尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和 BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
3.7. 删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。应该定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。

![Buuctf web [SUCTF 2019]EasySQL](https://img-blog.csdnimg.cn/03f6128705fe48cba20022e995026cb9.png)





![BUU [HCTF 2018]Hideandseek](https://img-blog.csdnimg.cn/img_convert/3e4aadda7ded3f0477807c06ab39d184.png)