一、概念
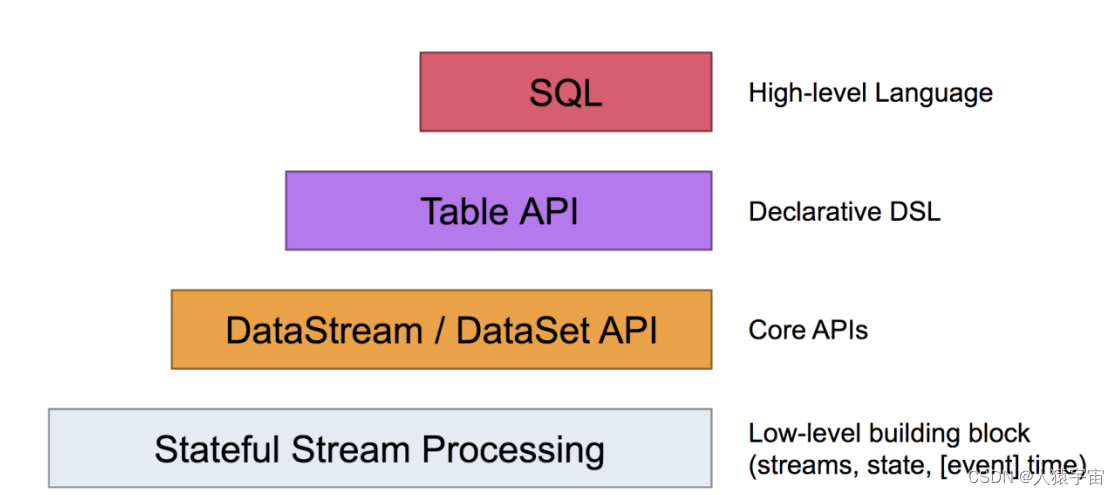
1.1 Apache Flink 两种关系型 API
Apache Flink 有两种关系型 API 来做流批统一处理:Table API 和 SQL。
Table API 是用于 Scala 和 Java 语言的查询API,它可以用一种非常直观的方式来组合使用选取、过滤、join 等关系型算子。
Flink SQL 是基于 Apache Calcite 来实现的标准 SQL。这两种 API 中的查询对于批(DataSet)和流(DataStream)的输入有相同的语义,也会产生同样的计算结果。
Table API 和 SQL 两种 API 是紧密集成的,以及 DataStream 和 DataSet API。你可以在这些 API 之间,以及一些基于这些 API 的库之间轻松的切换。比如,你可以先用 CEP 从 DataStream 中做模式匹配,然后用 Table API 来分析匹配的结果;或者你可以用 SQL 来扫描、过滤、聚合一个批式的表,然后再跑一个 Gelly 图算法 来处理已经预处理好的数据。
注意:Table API 和 SQL 现在还处于活跃开发阶段,还没有完全实现所有的特性。不是所有的 [Table API,SQL] 和 [流,批] 的组合都是支持的。
1.2 动态表(Dynamic Tables)
动态表是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。
动态表是随时间变化的,可以像查询静态批处理表一样查询它们。查询动态表将生成一个连续查询(Continuous Query)。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。
需要注意的是,连续查询的结果在语义上总是等价于以批处理模式在输入表快照上执行的相同查询的结果。
对动态表的一般处理过程: 流->动态表->连续查询处理->动态表->流
二、导入Flink Table API依赖
pom.xml 中添加
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress -->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.21</version>
</dependency>
三、表与DataStream的混合使用简单案例
package com.lyh.flink12;import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;//必须添加此类才能在表达式中运用$符号
import static org.apache.flink.table.api.Expressions.$;public class Table_Api_BasicUse {public static void main(String[] args) throws Exception {// 流运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//并行参数env.setParallelism(1);// 数据源DataStreamSource<WaterSensor> waterSensorStream =env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60));// 创建表的执行环境StreamTableEnvironment TableEnv = StreamTableEnvironment.create(env);// 创建表,将流转换成动态表. 表的字段名从pojo的属性名自动抽取Table table = TableEnv.fromDataStream(waterSensorStream);// 对动态表进行查询Table resultTable = table.where($("id").isEqual("sensor_1")).select($("id"),$("vc"));//把动态表转化为流DataStream<Row> dataStream = TableEnv.toAppendStream(resultTable,Row.class);dataStream.print();env.execute();}
}
四、表到流的转换
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
Append-only 流
仅通过 INSERT 操作修改的动态表可以通过输出插入的行转换为流。
Retract 流
retract 流包含两种类型的 message: add messages 和 retract messages 。通过将INSERT 操作编码为 add message、将 DELETE 操作编码为 retract message、将 UPDATE 操作编码为更新(先前)行的 retract message 和更新(新)行的 add message,将动态表转换为 retract 流。下图显示了将动态表转换为 retract 流的过程。
Upsert 流
upsert 流包含两种类型的 message: upsert messages 和delete messages。转换为 upsert 流的动态表需要(可能是组合的)唯一键。通过将 INSERT 和 UPDATE 操作编码为 upsert message,将 DELETE 操作编码为 delete message ,将具有唯一键的动态表转换为流。消费流的算子需要知道唯一键的属性,以便正确地应用 message。与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。
请注意,在将动态表转换为 DataStream 时,只支持 append 流和 retract 流。
五、通过Connector声明读入数据
前面是先得到流, 再转成动态表, 其实动态表也可以直接连接到数据
5.1 File source
// 创建表
//表的元数据信息
Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());
// 连接文件, 并创建一个临时表, 其实就是一个动态表
tableEnv.connect(new FileSystem().path("input/sensor.txt")).withFormat(new Csv().fieldDelimiter(',').lineDelimiter("\n")).withSchema(schema).createTemporaryTable("sensor");
// 做成表对象, 然后对动态表进行查询
Table sensorTable = tableEnv.from("sensor");
Table resultTable = sensorTable.groupBy($("id")).select($("id"), $("id").count().as("cnt"));
// 把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记
DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
resultStream.print();
5.2 Kafka Source
// 创建表
// 表的元数据信息
Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());
// 连接文件, 并创建一个临时表, 其实就是一个动态表
tableEnv.connect(new Kafka().version("universal").topic("sensor").startFromLatest().property("group.id", "bigdata").property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092")).withFormat(new Json()).withSchema(schema).createTemporaryTable("sensor");
//对动态表进行查询
Table sensorTable = tableEnv.from("sensor");
Table resultTable = sensorTable.groupBy($("id")).select($("id"), $("id").count().as("cnt"));
//把动态表转换成流. 如果涉及到数据的更新, 要用到撤回流. 多个了一个boolean标记
DataStream<Tuple2<Boolean, Row>> resultStream = tableEnv.toRetractStream(resultTable, Row.class);
resultStream.print();
六、通过Connector声明写出数据
6.1 File Sink
package com.atguigu.flink.java.chapter_11;import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Schema;import static org.apache.flink.table.api.Expressions.$;/*** @Author lizhenchao@atguigu.cn* @Date 2021/1/11 21:43*/
public class Flink02_TableApi_ToFileSystem {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> waterSensorStream =env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60));// 1. 创建表的执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);Table sensorTable = tableEnv.fromDataStream(waterSensorStream);Table resultTable = sensorTable.where($("id").isEqual("sensor_1") ).select($("id"), $("ts"), $("vc"));// 创建输出表Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());tableEnv.connect(new FileSystem().path("output/sensor_id.txt")).withFormat(new Csv().fieldDelimiter('|')).withSchema(schema).createTemporaryTable("sensor");// 把数据写入到输出表中resultTable.executeInsert("sensor");}
}
6.2 Kafka Sink
package com.atguigu.flink.java.chapter_11;import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Json;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;import static org.apache.flink.table.api.Expressions.$;/*** @Author lizhenchao@atguigu.cn* @Date 2021/1/11 21:43*/
public class Flink03_TableApi_ToKafka {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> waterSensorStream =env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60));// 1. 创建表的执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);Table sensorTable = tableEnv.fromDataStream(waterSensorStream);Table resultTable = sensorTable.where($("id").isEqual("sensor_1") ).select($("id"), $("ts"), $("vc"));// 创建输出表Schema schema = new Schema().field("id", DataTypes.STRING()).field("ts", DataTypes.BIGINT()).field("vc", DataTypes.INT());tableEnv.connect(new Kafka().version("universal").topic("sink_sensor").sinkPartitionerRoundRobin().property("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092")).withFormat(new Json()).withSchema(schema).createTemporaryTable("sensor");// 把数据写入到输出表中resultTable.executeInsert("sensor");}
}
七、基本使用
7.1 查询未注册的表
package com.lyh.flink12;import org.apache.flink.types.Row;
import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class Connect_File_source {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> dataStreamSource =env.fromElements(new WaterSensor("sensor_1", 1000L, 20),new WaterSensor("sensor_1", 2000L, 30),new WaterSensor("sensor_1", 3000L, 40),new WaterSensor("sensor_1", 4000L, 50),new WaterSensor("sensor_1", 5000L, 60));// 创建动态表环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 使用SQL查询未注册的表// 从流中得到一个表Table inputTable = tableEnv.fromDataStream(dataStreamSource);Table resultTable = tableEnv.sqlQuery("select * from " + inputTable + " where id = 'sensor_1'");tableEnv.toAppendStream(resultTable, Row.class).print();env.execute();}
}
7.2 查询已注册的表
package com.lyh.flink12;
import com.atguigu.flink.java.chapter_5.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;public class Flink05_SQL_BaseUse_2 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> waterSensorStream =env.fromElements(new WaterSensor("sensor_1", 1000L, 10),new WaterSensor("sensor_1", 2000L, 20),new WaterSensor("sensor_2", 3000L, 30),new WaterSensor("sensor_1", 4000L, 40),new WaterSensor("sensor_1", 5000L, 50),new WaterSensor("sensor_2", 6000L, 60));StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 使用sql查询一个已注册的表// 1. 从流得到一个表Table inputTable = tableEnv.fromDataStream(waterSensorStream);// 2. 把注册为一个临时视图tableEnv.createTemporaryView("sensor", inputTable);// 3. 在临时视图查询数据, 并得到一个新表Table resultTable = tableEnv.sqlQuery("select * from sensor where id='sensor_1'");// 4. 显示resultTable的数据tableEnv.toAppendStream(resultTable, Row.class).print();env.execute();}
}
7.3 Kafka到Kafka
使用sql从Kafka读数据, 并写入到Kafka中
package com.lyh.flink12;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class Sql_kafka_kafka {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);tableEnv.executeSql("create table source_sensor (id string, ts bigint, vc int) with("+ "'connector' = 'kafka',"+ "'topic' = 'topic_source_sensor',"+ "'properties.bootstrap.servers' = 'hadoop100:9029',"+ "'properties.group.id' = 'atguigu',"+ "'scan.startup.mode' = 'latest-offset',"+ "'format' = 'json'"+ ")");// 2. 注册SinkTable: sink_sensortableEnv.executeSql("create table sink_sensor(id string, ts bigint, vc int) with("+ "'connector' = 'kafka',"+ "'topic' = 'topic_sink_sensor',"+ "'properties.bootstrap.servers' = 'hadoop100:9029',"+ "'format' = 'json'"+ ")");// 3. 从SourceTable 查询数据, 并写入到 SinkTabletableEnv.executeSql("insert into sink_sensor select * from source_sensor where id='sensor_1'");}
}