目录
编辑
一、Hive权限简介
1.1 hive中的用户与组
1.1.1 用户
1.1.2 组
1.1.3 角色
1.2 使用场景
1.2.1 hive cli
1.2.2 hiveserver2
1.2.3 hcatalog api
1.3 权限模型
1.3.1 Storage Based Authorization in the Metastore Server
1.3.2 SQL Standards Based Authorization in HiveServer2
1.3.3 Default Hive Authorization (Legacy Mode)
1.4 hive的超级用户
二、授权管理
2.1 管理命令
2.1.1 角色
2.1.1.1 创建角色
2.1.1.2 删除角色
2.1.1.3 设置角色
2.1.1.4 查看当前具有的角色
2.1.1.5 查看所有存在的角色
2.1.2 用户
2.1.2.1 用户进入admin角色权限
2.1.2.2 查看某用户的所有角色
2.1.2.3 给角色添加用户
2.1.3 用户授权
2.1.3.1 基于数据库
2.1.3.2 基于某张表
2.1.4 组授权
2.1.4.1 基于数据库
2.1.4.2 基于某张表
2.1.5 角色授权
2.1.5.1 基于数据库
2.1.5.2 基于某个表
2.1.6 用户移出权限
2.1.6.1 基于数据库
2.1.6.2 基于某个表
2.1.7 查看用户权限
2.1.7.1 查看某用户在某数据库的权限
2.1.7.2 查看某用户在某表的权限
2.2 权限表
2.2.1 HIVE支持的权限
2.2.2 权限和操作对应关系
2.3 权限分配图
2.4 hive开启权限管理
2.4.1 设置开启hiveserver2权限管理
2.4.2 开启hive权限管理
2.4.3 验证权限
一、Hive权限简介
1.1 hive中的用户与组
hive权限中有用户、组、角色的概念。
1.1.1 用户
即操作系统中的用户,或者在hiveserver2中定义的用户。
1.1.2 组
即操作系统中的组。(组是相对默认授权方式来说的)
1.1.3 角色
是一组权限的集合,参考关系型数据库。
hive内置public角色。public,所有用户都拥有的角色。
1.2 使用场景
目前主要通过以下三种方式使用hive:
hive cli、hiveserver2、hcatalog api
1.2.1 hive cli
hive cli中的用户是操作系统中存在的用户。使用hive cli,只会验证用户的hdfs目录权限。
1.2.2 hiveserver2
hiveserver2中的用户即可以是操作系统中的用户,也可以是hiveserver2中定义的用户。
hiveserver2默认开启用户代理,即用启动hiveserver2的用户来模拟实际用户来提交任务,这时的权限是实际提交的用户的。如果关闭代理,则以启动hiveserver2的用户的权限来执行。
1.2.3 hcatalog api
通过hcatalog api访问hive的用户只会检查用户hdfs上的目录权限。
1.3 权限模型
1.3.1 Storage Based Authorization in the Metastore Server
基于存储权限验证metastore服务:默认情况下hive像dbms一样管理权限,但是有时候为用户授权后用户却没有hdfs权限。因此,当前hive元数据授权的方式是结合dbms权限管理和底层的存储权限管理。当用hive给用户授权时,会先检查用户是hdfs的对应目录是否有相应权限,如果有再执行授权,如果没有则反错。可以对Metastore中的元数据进行保护,但是该种权限模式没有提供更加细粒度的访问控制(例如:列级别、行级别)。
比如给用户授权查询test.t1表时,如果用户在hdfs上没有访问hdfs://user/hive/warehouse/test/t1目录权限则会直接报错。默认是不开启的。
1.3.2 SQL Standards Based Authorization in HiveServer2
基于sql的hiveserver2的权限验证。基于存储的权限验证方式只能验证用户是否有访问目录或文件的权限,但无法执行如列访问之类更精细的控制,因此要用基于sql的权限控制方式。hiveserver2提供了一套完全类似sql的权限验证,可以设置role、用户,可以执行表级、行级、列级授权。
注意:hive cli是不支持sql验证方式的。因为用户可以在cli中改变验证规则甚至禁用该规则。
特点
1)dfs add delete compile reset会被禁止
2)set 命令被限制,只能用来设置少量安全的参数。hive.security.authorization.sqlstd.confwhitelist 参数可设置set可以设置哪些参数。
3)add/drop function以及宏只能被admin角色使用的
4)只能有admin角色来创建永久性函数,其它用户都可以使用
5)admin角色必须使用set role=admin来启动角色
用户和角色
非常类似关系型数据库,用户可以被授予角色。角色是一组权限的集合。
内置了public和admin两个角色,每个用户都有public角色,可以执行基本操作。admin为管理角色。用户登录hiveserver2时执行 show current roles;来查看当前角色。使用set role切换角色。
admin角色用户可以创建其它角色。做admin角色前,做set role切换到admin角色。
role name不分大小写,但是用户名分大小写。
1.3.3 Default Hive Authorization (Legacy Mode)
类似于dbms的授权方式,但是人人都可以执行Grant,当然也可以实现超级用户类来管理hive.开启权限验证后,不配置上面的两个默认就是用这个。
设计目的仅仅只是为了防止用户产生误操作,而不是防止恶意用户访问未经授权的数据。
1.4 hive的超级用户
默认hive是不启用权限验证的,只要使用hive的用户在hdfs上权限即可。默认存在超级用户,用户可以通过自定义类来实现超级用户。使用超级启用必须开始权限验证。
二、授权管理
2.1 管理命令
2.1.1 角色
2.1.1.1 创建角色
CREATE ROLE role_name;2.1.1.2 删除角色
DROP ROLE role_name;2.1.1.3 设置角色
SET ROLE (role_name|ALL|NONE);2.1.1.4 查看当前具有的角色
SHOW CURRENT ROLES;2.1.1.5 查看所有存在的角色
SHOW ROLES;2.1.2 用户
2.1.2.1 用户进入admin角色权限
set hive.users.in.admin.role;
set role admin;2.1.2.2 查看某用户的所有角色
show role grant user user_name2.1.2.3 给角色添加用户
grant role role_name to user user_name;2.1.3 用户授权
2.1.3.1 基于数据库
grant select on database default to useradmin;2.1.3.2 基于某张表
grant select on table test_table to user admin;2.1.4 组授权
2.1.4.1 基于数据库
grant select on database default to group admin;2.1.4.2 基于某张表
grant select on table ppdata to group admin;2.1.5 角色授权
2.1.5.1 基于数据库
grant select on database default to role admin;2.1.5.2 基于某个表
grant select on table ppdata to role admin;2.1.6 用户移出权限
2.1.6.1 基于数据库
revoke select on database default from useruserB;2.1.6.2 基于某个表
revoke select on table ppdata from useruserB;2.1.7 查看用户权限
2.1.7.1 查看某用户在某数据库的权限
show grant role role_name on database database_name;2.1.7.2 查看某用户在某表的权限
show grant role role_name on [table] table_name;2.2 权限表
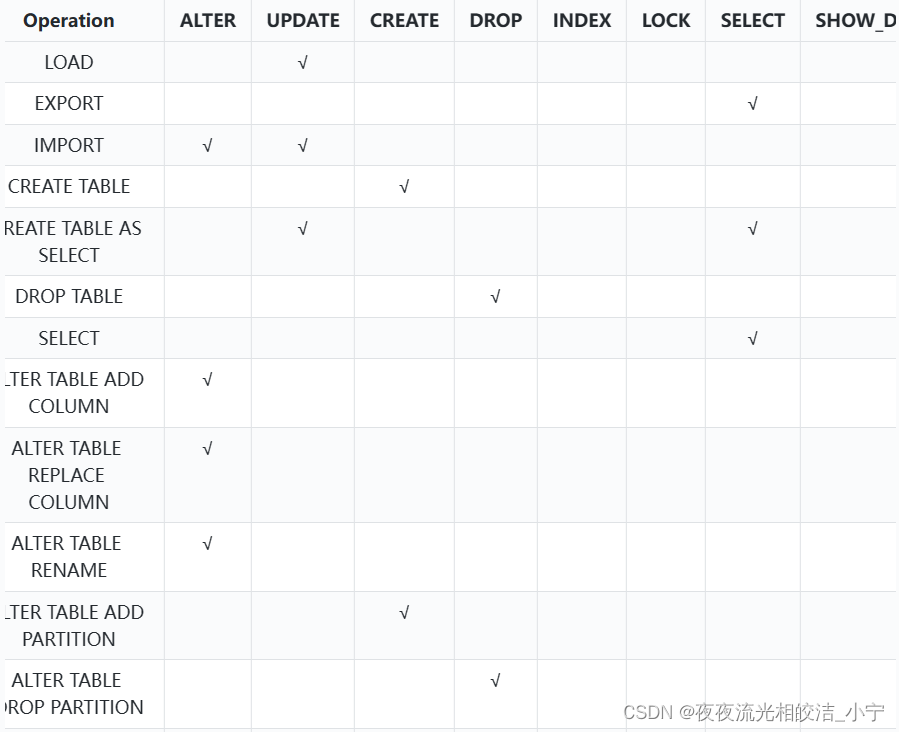
2.2.1 HIVE支持的权限
| 权限名称 | 含义 |
| ALL | 所有权限 |
| ALTER | 允许修改元数据(modify metadata data of object)---表信息数据 |
| UPDATE | 允许修改物理数据(modify physical data of object)---实际数据 |
| CREATE | 允许进行Create操作 |
| DROP | 允许进行DROP操作 |
| INDEX | 允许建索引(目前还没有实现) |
| LOCK | 当出现并发的使用允许用户进行LOCK和UNLOCK操作 |
| SELECT | 允许用户进行SELECT操作 |
| SHOW_DATABASE | 允许用户查看可用的数据库 |
2.2.2 权限和操作对应关系
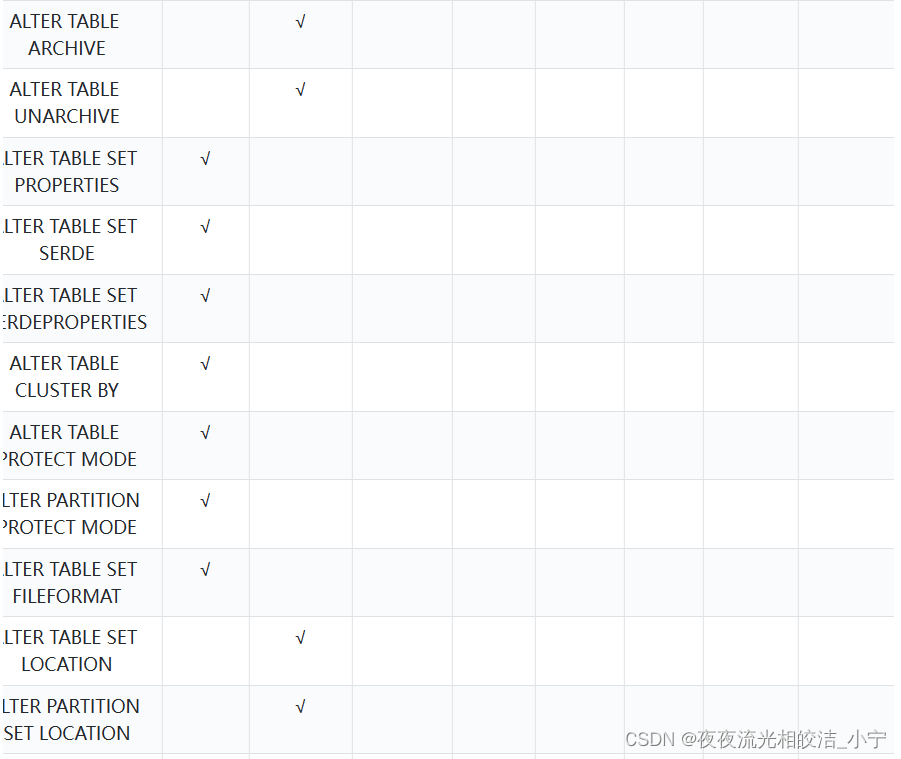
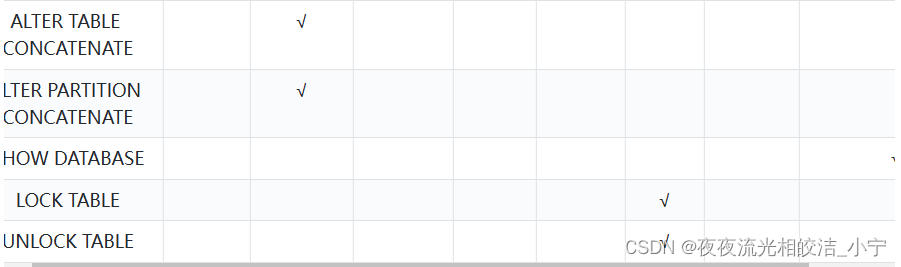
2.3 权限分配图
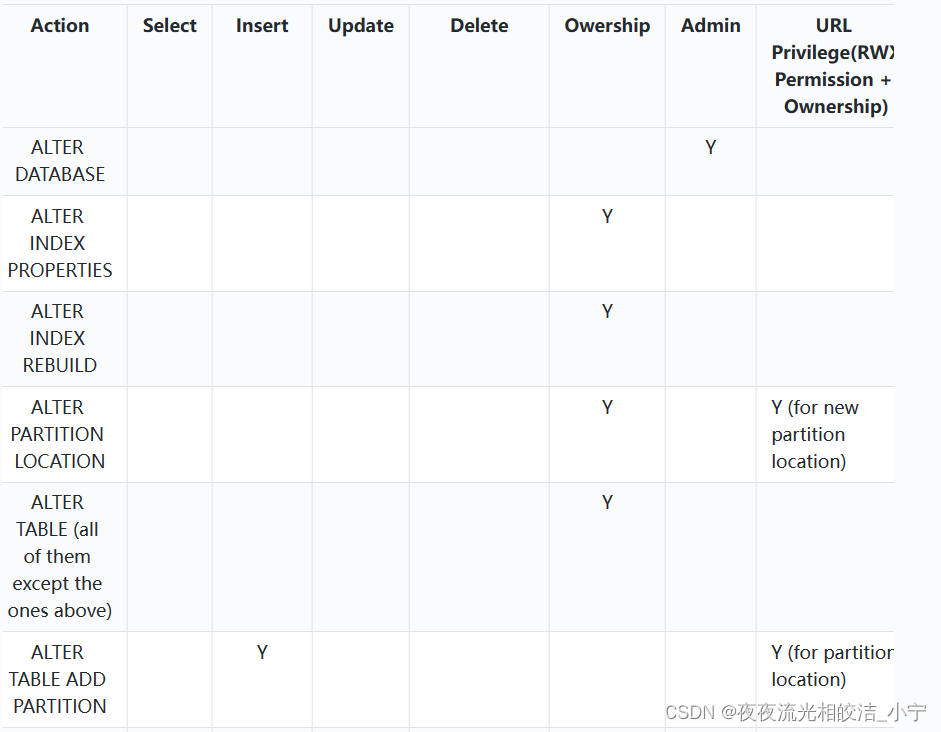
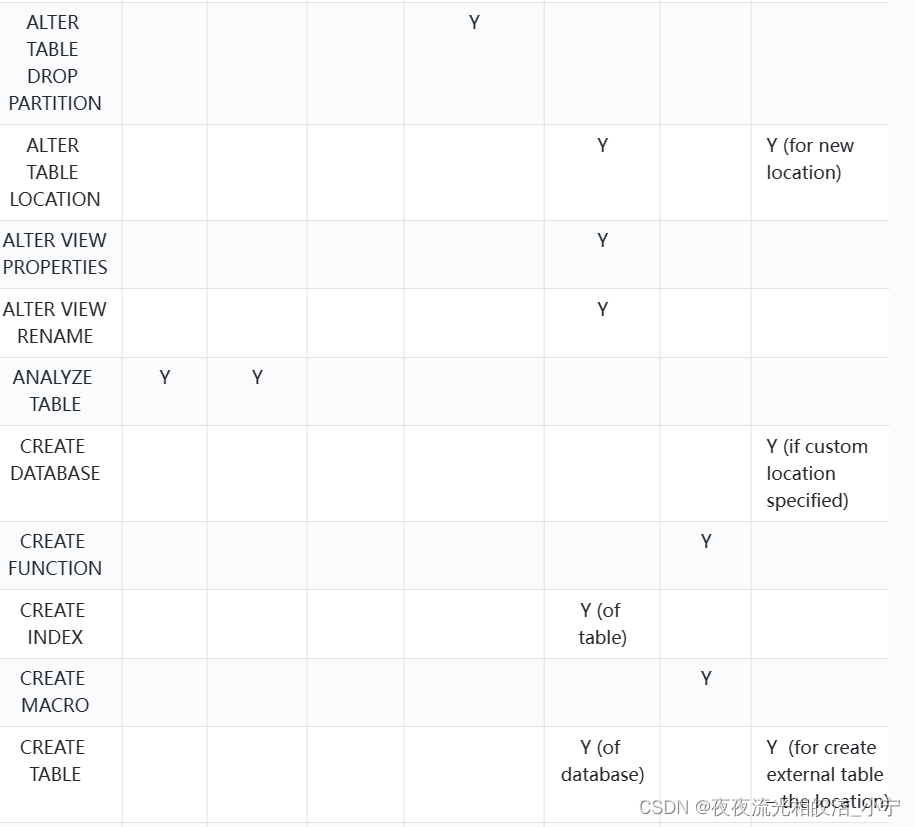
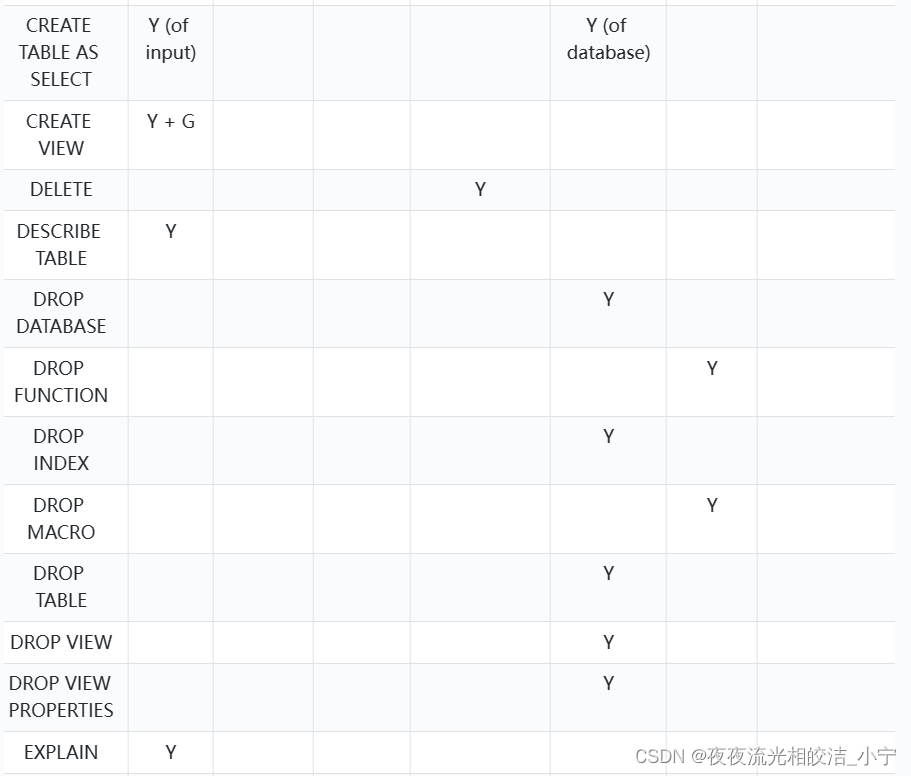
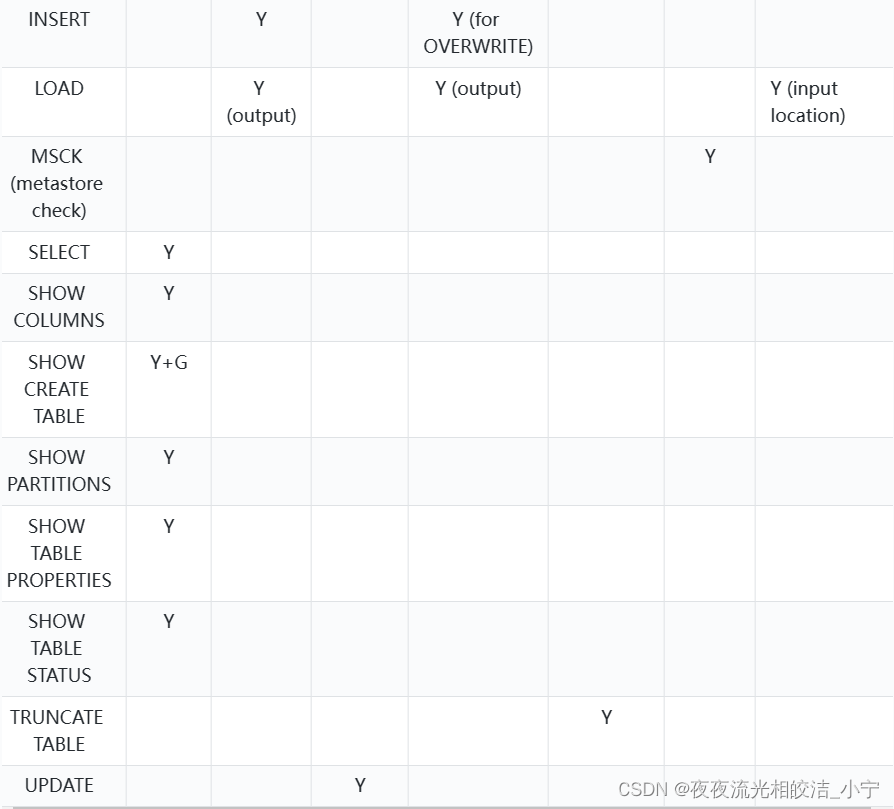
2.4 hive开启权限管理
2.4.1 设置开启hiveserver2权限管理
#在hiveserver2-site.xml中加入如下配置
<property><name>hive.security.authorization.enabled</name><value>true</value>
</property>
<property><name>hive.server2.enable.doAs</name><value>false</value>
</property>
<property><name>hive.users.in.admin.role</name><value>root</value>
</property>
<property><name>hive.security.authorization.manager</name> <value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property><name>hive.security.authenticator.manager</name><value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>2.4.2 开启hive权限管理
#在hive-site.xml中加入如下配置
<property><name>hive.security.authorization.enabled</name><value>true</value>
</property>
<property><name>hive.server2.enable.doAs</name><value>false</value>
</property>
<property><name>hive.users.in.admin.role</name><value>root</value>
</property>
<property><name>hive.security.authorization.manager</name> <value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property><name>hive.security.authenticator.manager</name><value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>2.4.3 验证权限
我们不使用账号密码登录hiveserver2,或者使用普通角色用户登录hiveserver2,我们查看下psn4表的数据
执行:select * from psn4;
执行结果:

我们发现,权限管理生效的,不是自己创建的表,没有权限查看。
好了,今天Hive权限管理的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!