文章目录
- 前言
- PageHelper 应用
- 实现原理剖析
- 应用场景分析
前言
分页插件PageHelper是我们使用Mybatis到的比较多的插件应用,适用于任何复杂的单表、多表分页查询操作。本文介绍PageHelper的使用及原理。
PageHelper 应用
添加依赖
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>4.1.6</version>
</dependency>
在全局配置文件中注册
<!-- com.github.pagehelper为PageHelper类所在包名 -->
<plugin interceptor="com.github.pagehelper.PageHelper"><property name="dialect" value="mysql" /><!-- 该参数默认为false --><!-- 设置为true时,会将RowBounds第一个参数offset当成pageNum页码使用 --><!-- 和startPage中的pageNum效果一样 --><property name="offsetAsPageNum" value="true" /><!-- 该参数默认为false --><!-- 设置为true时,使用RowBounds分页会进行count查询 --><property name="rowBoundsWithCount" value="true" /><!-- 设置为true时,如果pageSize=0或者RowBounds.limit = 0就会查询出全部的结果 --><!-- (相当于没有执行分页查询,但是返回结果仍然是Page类型) --><property name="pageSizeZero" value="true" /><!-- 3.3.0版本可用 - 分页参数合理化,默认false禁用 --><!-- 启用合理化时,如果pageNum<1会查询第一页,如果pageNum>pages会查询最后一页 --><!-- 禁用合理化时,如果pageNum<1或pageNum>pages会返回空数据 --><property name="reasonable" value="false" /><!-- 3.5.0版本可用 - 为了支持startPage(Object params)方法 --><!-- 增加了一个`params`参数来配置参数映射,用于从Map或ServletRequest中取值 --><!-- 可以配置pageNum,pageSize,count,pageSizeZero,reasonable,不配置映射的用默认值 --><!-- 不理解该含义的前提下,不要随便复制该配置 --><property name="params" value="pageNum=start;pageSize=limit;" /><!-- always总是返回PageInfo类型,check检查返回类型是否为PageInfo,none返回Page --><property name="returnPageInfo" value="check" />
</plugin>
在执行查询操作之前设置了一句PageHelper.startPage(1,5); 即可实现分页效果。
实现原理剖析
PageHelper也必然要实现 Interceptor ,通过源码我们可以发现是PageHelper方法头部添加的注解,声明了该拦截器拦截的是Executor的query方法。
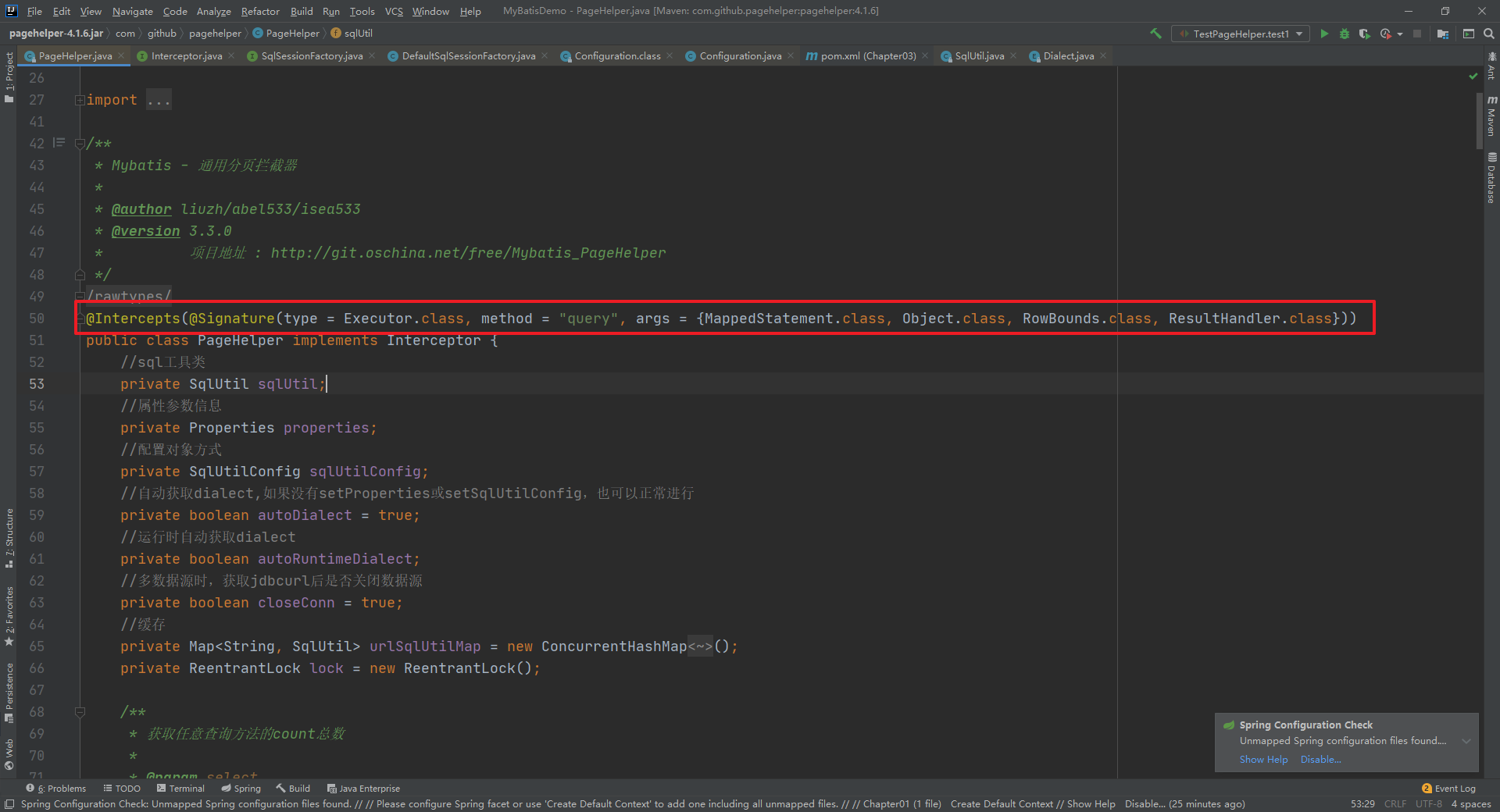
执行查询操作的时候, Executor.query() 方法的执行本质上是执行 Executor的代理对象的方法。先来看下Plugin中的invoke方法
/*** 代理对象方法被调用时执行的代码* @param proxy* @param method* @param args* @return* @throws Throwable*/@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {// 获取当前方法所在类或接口中,可被当前Interceptor拦截的方法Set<Method> methods = signatureMap.get(method.getDeclaringClass());if (methods != null && methods.contains(method)) {// 当前调用的方法需要被拦截 执行拦截操作return interceptor.intercept(new Invocation(target, method, args));}// 不需要拦截 则调用 目标对象中的方法return method.invoke(target, args);} catch (Exception e) {throw ExceptionUtil.unwrapThrowable(e);}}
interceptor.intercept(new Invocation(target, method, args));方法的执行会进入到 PageHelper的intercept方法中
/*** Mybatis拦截器方法** @param invocation 拦截器入参* @return 返回执行结果* @throws Throwable 抛出异常*/public Object intercept(Invocation invocation) throws Throwable {if (autoRuntimeDialect) {SqlUtil sqlUtil = getSqlUtil(invocation);return sqlUtil.processPage(invocation);} else {if (autoDialect) {initSqlUtil(invocation);}return sqlUtil.processPage(invocation);}}
intercept方法
/*** Mybatis拦截器方法** @param invocation 拦截器入参* @return 返回执行结果* @throws Throwable 抛出异常*/public Object intercept(Invocation invocation) throws Throwable {if (autoRuntimeDialect) { // 多数据源SqlUtil sqlUtil = getSqlUtil(invocation);return sqlUtil.processPage(invocation);} else { // 单数据源if (autoDialect) {initSqlUtil(invocation);}return sqlUtil.processPage(invocation);}}
在interceptor方法中首先会获取一个SqlUtils对象
SqlUtil:数据库类型专用sql工具类,一个数据库url对应一个SqlUtil实例,SqlUtil内有一个Parser对象,如果是mysql,它是MysqlParser,如果是oracle,它是OracleParser,这个Parser对象是SqlUtil不同实例的主要存在价值。执行count查询、设置Parser对象、执行分页查询、保存Page分页对象等功能,均由SqlUtil来完成。
initSqlUtil 方法创建的解析器
public static Parser newParser(Dialect dialect) {Parser parser = null;switch (dialect) {case mysql:case mariadb:case sqlite:parser = new MysqlParser();break;case oracle:parser = new OracleParser();break;case hsqldb:parser = new HsqldbParser();break;case sqlserver:parser = new SqlServerParser();break;case sqlserver2012:parser = new SqlServer2012Dialect();break;case db2:parser = new Db2Parser();break;case postgresql:parser = new PostgreSQLParser();break;case informix:parser = new InformixParser();break;case h2:parser = new H2Parser();break;default:throw new RuntimeException("分页插件" + dialect + "方言错误!");}return parser;}
不同的数据库方言,创建了对应的解析器。
sqlUtil.processPage(invocation);方法中会完成分页SQL的绑定
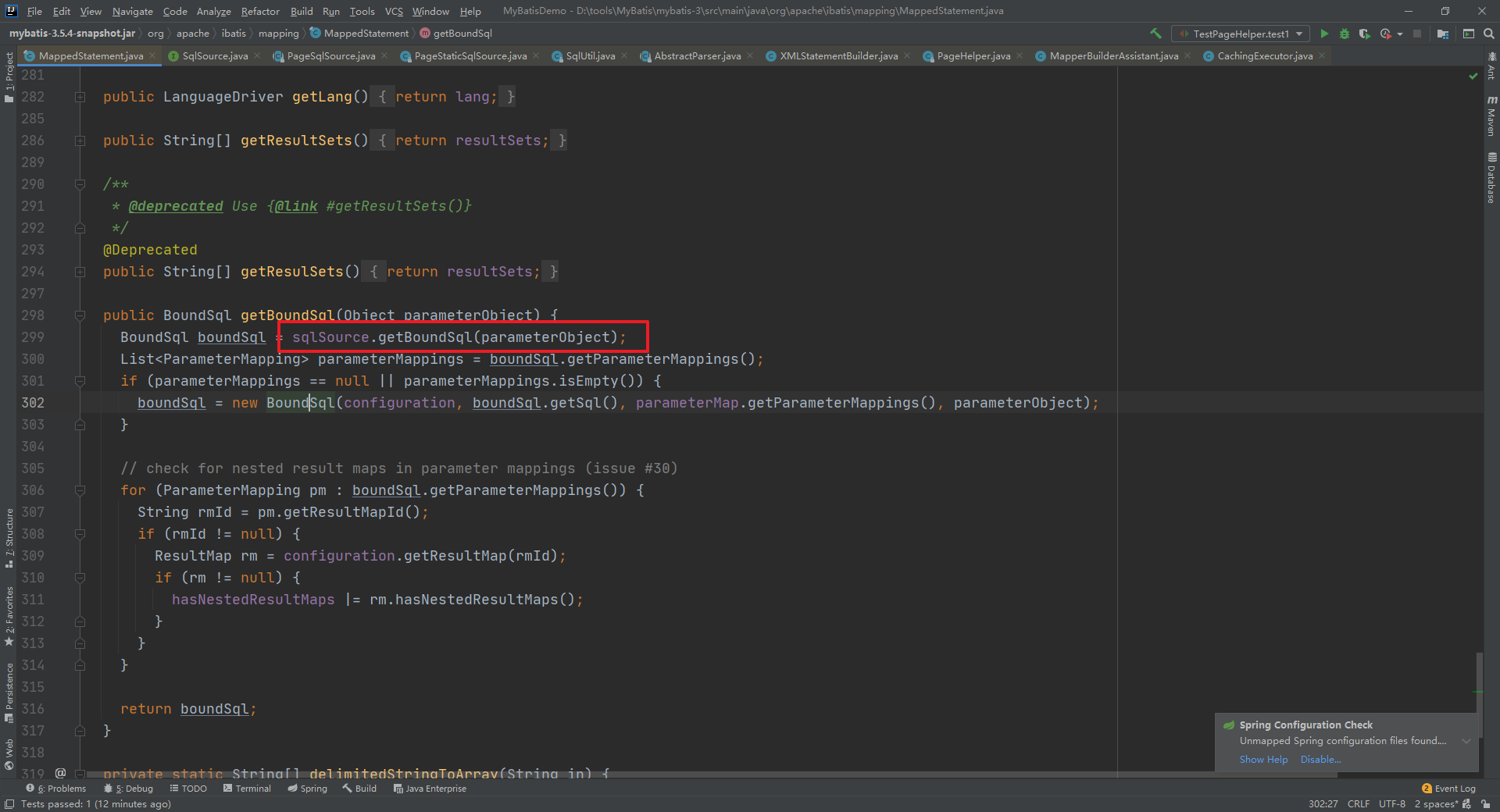
进入 PageSqlSource 的getBoundSql方法中

/*** 获取BoundSql** @param parameterObject* @return*/@Overridepublic BoundSql getBoundSql(Object parameterObject) {Boolean count = getCount();if (count == null) {return getDefaultBoundSql(parameterObject);} else if (count) {return getCountBoundSql(parameterObject);} else {return getPageBoundSql(parameterObject);}}
getPageBoundSql获取分页的SQL语句,在这个方法中可以发现查询总的记录数的SQL生成
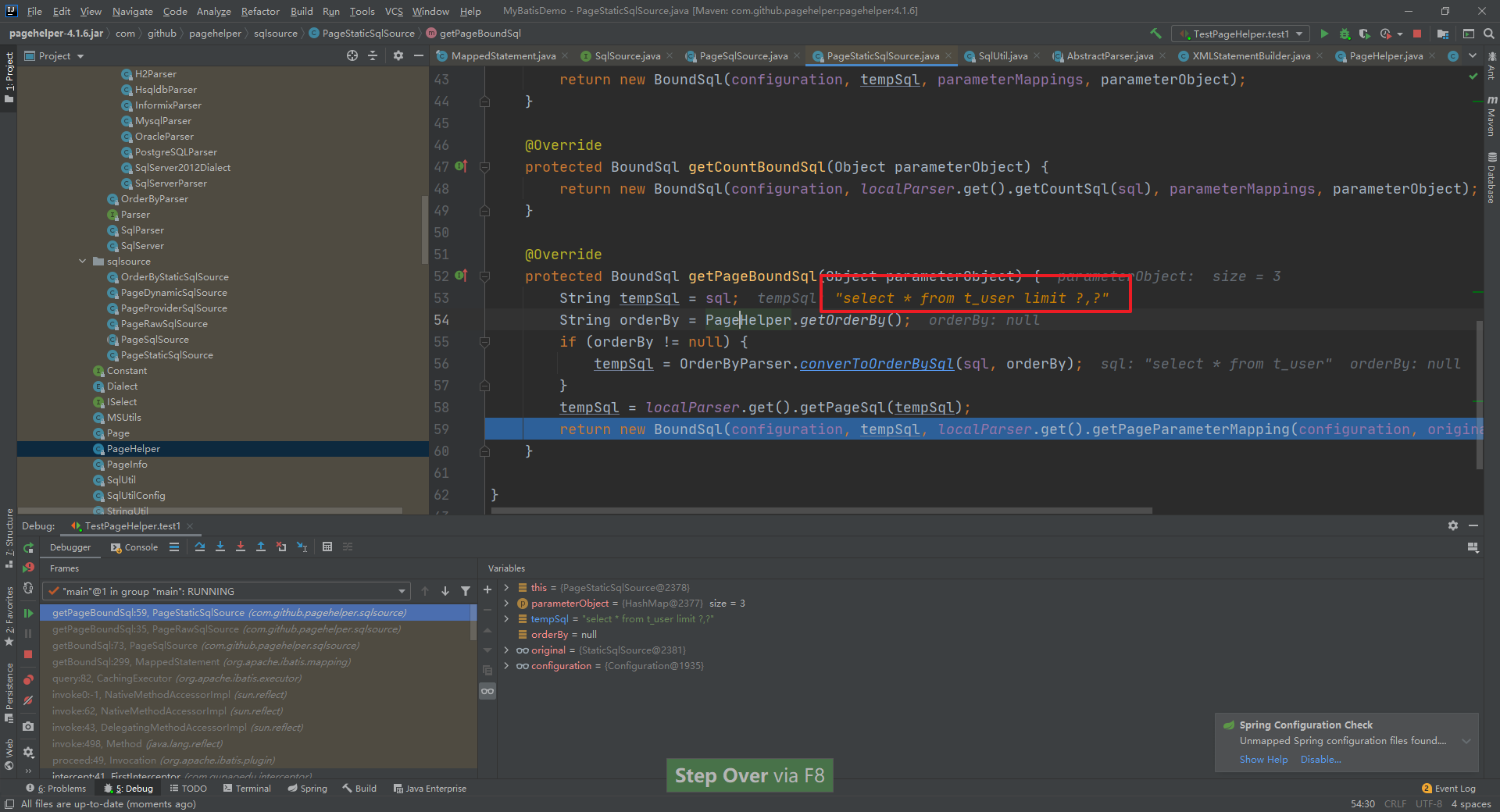
@Overrideprotected BoundSql getPageBoundSql(Object parameterObject) {String tempSql = sql;String orderBy = PageHelper.getOrderBy();if (orderBy != null) {tempSql = OrderByParser.converToOrderBySql(sql, orderBy);}tempSql = localParser.get().getPageSql(tempSql);return new BoundSql(configuration, tempSql, localParser.get().getPageParameterMapping(configuration, original.getBoundSql(parameterObject)), parameterObject);}
最终在这个方法中生成了对应数据库的分页语句
应用场景分析
| 作用 | 描述 | 实现方式 |
|---|---|---|
| 水平分表 | 一张费用表按月度拆分为12张表。fee_202001-202012。当查询条件出现月度(tran_month)时,把select语句中的逻辑表名修改为对应的月份表。 | 对query update方法进行拦截在接口上添加注解,通过反射获取接口注解,根据注解上配置的参数进行分表,修改原SQL,例如id取模,按月分表 |
| 数据脱敏 | 手机号和身份证在数据库完整存储。但是返回给用户,屏蔽手机号的中间四位。屏蔽身份证号中的出生日期。 | query——对结果集脱敏 |
| 菜单权限控制 | 不同的用户登录,查询菜单权限表时获得不同的结果,在前端展示不同的菜单 | 对query方法进行拦截在方法上添加注解,根据权限配置,以及用户登录信息,在SQL上加上权限过滤条件 |
| 黑白名单 | 有些SQL语句在生产环境中是不允许执行的,比如like %% | 对Executor的update和query方法进行拦截,将拦截的SQL语句和黑白名单进行比较,控制SQL语句的执行 |
| 全局唯一ID | 在高并发的环境下传统的生成ID的方式不太适用,这时我们就需要考虑其他方式了 | 创建插件拦截Executor的insert方法,通过UUID或者雪花算法来生成ID,并修改SQL中的插入信息 |