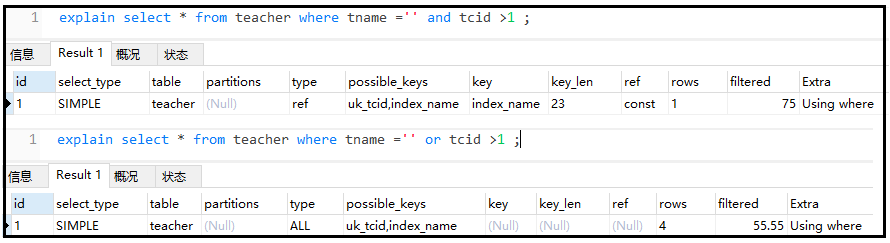
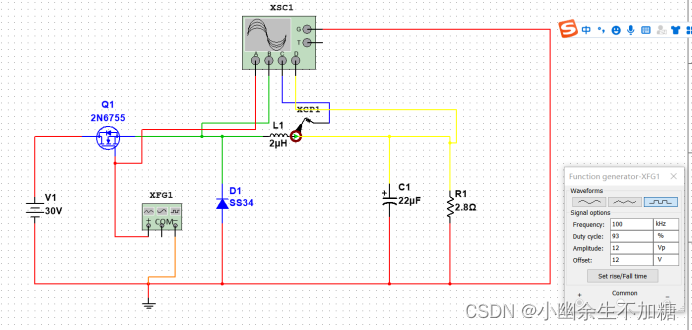
MySQL内部组件结构

Server层
主要包括连接器、词法分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
引擎层
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引 擎。
Innodb底层原理与Mysql日志机制

undo log和redo log属于innodb,bin log属于server层。
redo log 写入磁盘过程分析
redo log 从头开始写,写完一个文件继续写另一个文件,写到最后一个文件末尾就又回到第一个文件开头循环写,如下面这个图所示。

write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件里。
write pos 和 checkpoint 之间的部分就是空着的可写部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示redo log写满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下,把数据刷入磁盘文件ibd。
innodb_flush_log_at_trx_commit:这个参数控制 redo log 的写入策略,它有三种可能取值:
设置为0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,数据库宕机可能会丢失数据。
设置为1(默认值):表示每次事务提交时都将 redo log 直接持久化到磁盘,数据最安全,不会因为数据库宕机丢失数据,但是效率稍微差一点,线上系统推荐这个设置。
设置为2:表示每次事务提交时都只是把 redo log 写到操作系统的缓存page cache里,这种情况如果数据库宕机是不会丢失数据的,但是操作系统如果宕机了,page cache里的数据还没来得及写入磁盘文件的话就 会丢失数据。
对于设置2,InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用操作系统函数 write 写到文件系统的page cache,然后调用操作系统函数 fsync 持久化到磁盘文件。
redo log写入策略参看下图:

binlog二进制归档日志
bin log二进制日志记录保存了所有执行过的修改操作语句,不保存查询操作。如果 MySQL 服务意外停止,可通过二进制日志文件排查,用户操作或表结构操作,从而来恢复数据库数据。一般来说redo log用于重启mysql时恢复数据,bin log用于数据库的数据恢复和主从复制。
MySQL5.7 版本中,bin log默认是关闭的,8.0版本默认是打开的
redo log和bin log区别:
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。redo log 是循环写的,空间固定会用完;
- binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
binlog 的日志格式
用参数 binlog_format 可以设置binlog日志的记录格式,mysql支持三种格式类型:
- STATEMENT:基于SQL语句的复制,每一条会修改数据的sql都会记录到master机器的bin-log中,这种方式日志量小,节约IO开销,提高性能,但是对于一些执行过程中才能确定结果的函数,比如UUID()、 SYSDATE()等函数如果随sql同步到slave机器去执行,则结果跟master机器执行的不一样。
- ROW:基于行的复制,日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改记录下每一行数据修改的细节,可以解决函数、存储过程等在slave机器的复制问题,但这种方式日志量较 大,性能不如Statement。举个例子,假设update语句更新10行数据,Statement方式就记录这条update语句,Row方式会记录被修改的10行数据。
- MIXED:混合模式复制,实际就是前两种模式的结合,在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种,如果sql里有函数或一些在执行时才知道结果的情况,会选择Row,其它情况选择Statement,推荐使用这一种。
binlog写入磁盘机制
binlog写入磁盘机制主要通过 sync_binlog 参数控制,默认值是 0。(可以类比下redo log,相似但是少一个log buffer)
- 为0的时候,表示每次提交事务都只 write 到page cache,由系统自行判断什么时候执行 fsync 写入磁盘。虽然性能得到提升,但是机器宕机,page cache里面的 binlog 会丢失。
- 也可以设置为1,表示每次提交事务都会执行 fsync 写入磁盘,这种方式最安全。
- 还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write 到page cache,但累积N个事务后才 fsync 写入磁盘,这种如果机器宕机会丢失N个事务的binlog。
查看 binlog 日志文件
可以用mysql自带的命令工具 mysqlbinlog 查看binlog日志内容(文件为二进制,无法直接查看)
# 查看bin‐log二进制文件(命令行方式,不用登录mysql) mysqlbinlog ‐‐no‐defaults ‐v ‐‐base64‐output=decode‐rows D:/dev/mysql‐5.7.25‐winx64/data/mysql‐binlog.000007 # 查看bin‐log二进制文件(带查询条件) mysqlbinlog ‐‐no‐defaults ‐v ‐‐base64‐output=decode‐rows D:/dev/mysql‐5.7.25‐winx64/data/mysql‐binlog.000007 start‐datetime="2023‐01‐21 00:00:00" stop‐datetime="2023‐02‐01 00:00:00" start‐position="5000" stop‐position="20000
binlog日志文件恢复数据
首先bin log如果开启,默认是不删除bin log,文件将会越来越多,不推荐。但是为了防止删库跑路,需要结合数据库备份来设置bin log保留天数,一般推荐每日备份一次数据库,bin log保留大于一天。那么恢复数据库可以用最近的一次全量备份再加上备份时间点之后的binlog来恢复数据。
备份数据库:
mysqldump ‐u root 数据库名>备份文件名; #备份整个数据库 mysqldump ‐u root 数据库名 表名字>备份文件名; #备份整个表 mysql ‐u root test < 备份文件名 #恢复整个数据库,test为数据库名称,需要自己先建一个数据库test
查看bin log日志:
# at 291SET TIMESTAMP=1674833560/*!*/;
注意到上述的两行,一个代表位置标识一个代表时间戳,可以根据上面两个变量来恢复某一段的数据:
# 根据位置标识恢复
mysqlbinlog ‐‐no‐defaults ‐‐start‐position=219 ‐‐stop‐position=701 ‐‐database=test D:/dev/mysql‐5.7.25‐winx64/data/mysql‐binlog.000009 | mysql ‐uroot ‐p123456 ‐v test # 补充一个根据时间来恢复数据的命令,我们找到第一条sql BEGIN前面的时间戳标记
SET TIMESTAMP=1674833544, 再找到第二条sql COMMIT后面的时间戳标记
SET TIMESTAMP=1674833663,转成datetime格式 mysqlbinlog ‐‐no‐defaults ‐‐start‐datetime="2023‐1‐27 23:32:24" ‐‐stop‐datetime="2023‐1‐27 23:34:23" ‐‐database=test D:/dev/mysql‐5.7.25‐winx64/data/mysql‐binlog.000009 | mysql ‐uroot ‐p123456 ‐v test