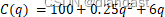目录
一、SwinTransformer
1、原理
2、代码
二、STViT-R
1、中心思想
2、代码与原文
本次不做具体的训练。只是看代码。所以只需搭建它的网络,执行一次前向传播即可。
一、SwinTransformer
1、原理
主要思想,将token按区域划分成窗口,只需每个窗口内的token单独进行 self-attention。

但是不同之间的窗口没有进行交互,为了解决这个问题。提出了

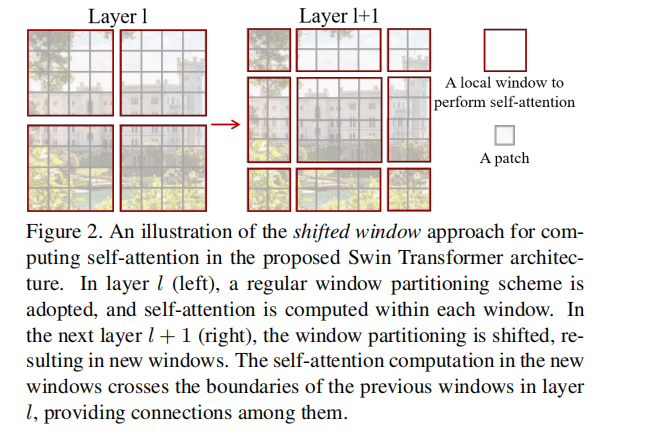
2、代码
1、均匀的划分窗口
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C window_size 7 # 划分窗口 (64,7,7,96)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C (64,49,96)二、STViT-R
1、中心思想

在浅层的 transformer保持不变,去提取低层 特征, 保证image token 中包含丰富的空间信息。在深层时,本文提出了 STGM 去生成 语义token, 通过聚类,整个图像由一些具有高级语义信息的标记来表示。。 在第一个STGM过程中,语义token 由 intra and inter-window spatial pooling初始化。 由于这种空间初始化,语义token主要包含局部语义信息,并在空间中实现离散和均匀分布。 在接下来的注意层中,除了进一步的聚类外,语义标记还配备了全局聚类中心,网络可以自适应地选择部分语义标记,以聚焦于全局语义信息。
2、代码与原文
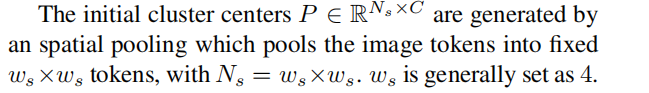
对应
xx = x.reshape(B, H // self.window_size, self.window_size, W // self.window_size, self.window_size, C) # (1,2,7,2,7,384)
windows = xx.permute(0, 1, 3, 2, 4, 5).contiguous().reshape(-1, self.window_size, self.window_size, C).permute(0, 3, 1, 2) # (4,384,7,7)
shortcut = self.multi_scale(windows) # B*nW, W*W, C multi_scale.py --13 (4,9,384)
if self.use_conv_pos: # Falseshortcut = self.conv_pos(shortcut)
pool_x = self.norm1(shortcut.reshape(B, -1, C)).reshape(-1, self.multi_scale.num_samples, C) # (4,9,384)#
class multi_scale_semantic_token1(nn.Module):def __init__(self, sample_window_size):super().__init__()self.sample_window_size = sample_window_size # 3self.num_samples = sample_window_size * sample_window_sizedef forward(self, x): # (4,384,7,7)B, C, _, _ = x.size()pool_x = F.adaptive_max_pool2d(x, (self.sample_window_size, self.sample_window_size)).view(B, C, self.num_samples).transpose(2, 1) # (4,9,384)return pool_x
注意,这个是按照每个窗口内进行 pooling的。代码中,窗口size为7,分成了4个窗口,故pooling前的 x(4,384,7,7),pooling后,按窗口池化,每个窗口池化后的 size为3,故池化后的输出 (4,9,384)。 至于参数的设置,由于采用的是local,所以文中所述

而且

所以 有了如下的操作,将原来窗口的size扩大了,
k_windows = F.unfold(x.permute(0, 3, 1, 2), kernel_size=10, stride=4).view(B, C, 10, 10, -1).permute(0, 4, 2, 3, 1) # (1,4,10,10,384)
k_windows = k_windows.reshape(-1, 100, C) # (4,100,384)
k_windows = torch.cat([shortcut, k_windows], dim=1) # (4,109,384)
k_windows = self.norm1(k_windows.reshape(B, -1, C)).reshape(-1, 100+self.multi_scale.num_samples, C) # (4,109,384)公式1
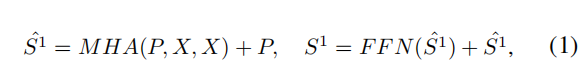
前边的对应
# P
shortcut = self.multi_scale(windows) # MHA(P, X, X)pool_x = self.norm1(shortcut.reshape(B, -1, C)).reshape(-1, self.multi_scale.num_samples, C)if self.shortcut:x = shortcut + self.drop_path(self.layer_scale_1 * self.attn(pool_x, k_windows))
中间省略了Norm层,所以括号里的 P是 有Norm的,外面的P是 shortcut
后边的对应
x = x + self.drop_path(self.layer_scale_2 * self.mlp(self.norm2(x))) # (1,36,384)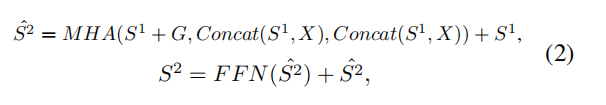
对应
elif i == 2:if self.use_global:semantic_token = blk(semantic_token+self.semantic_token2, torch.cat([semantic_token, x], dim=1))else: # Truesemantic_token = blk(semantic_token, torch.cat([semantic_token, x], dim=1))文中的

定义为(当只有 use_global时才使用)
if self.use_global:self.semantic_token2 = nn.Parameter(torch.zeros(1, self.num_samples, embed_dim))trunc_normal_(self.semantic_token2, std=.02)最终的对应
x = shortcut + self.drop_path(self.layer_scale_1 * attn)
x = x + self.drop_path(self.layer_scale_2 * self.mlp(self.norm2(x)))注意,在 i=1 到 i=5之间的层是 STGM,当i=5时,开始了哑铃的另一侧

对应代码
elif i == 5:x = blk(x, semantic_token) # to layers.py--132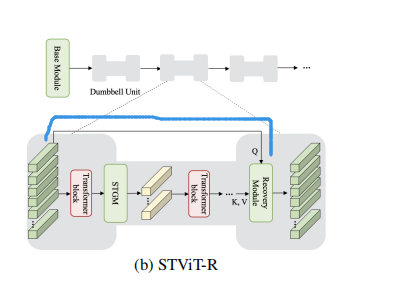
如图中的蓝线,原始的 image token作为Q,然后STGM的语义令牌作为KV,
上述过程循环往复,就组成了多个的哑铃结构
if i == 0:x = blk(x) # (1,196,384) to swin_transformer -- 242elif i == 1:semantic_token = blk(x) # to layers.py --179elif i == 2:if self.use_global: # Truesemantic_token = blk(semantic_token+self.semantic_token2, torch.cat([semantic_token, x], dim=1)) # to layers.py--132else: # Truesemantic_token = blk(semantic_token, torch.cat([semantic_token, x], dim=1)) # to layers.py--132elif i > 2 and i < 5:semantic_token = blk(semantic_token) # to layers.py--132elif i == 5:x = blk(x, semantic_token) # to layers.py--132elif i == 6:x = blk(x)elif i == 7:semantic_token = blk(x)elif i == 8:semantic_token = blk(semantic_token, torch.cat([semantic_token, x], dim=1))elif i > 8 and i < 11:semantic_token = blk(semantic_token)elif i == 11:x = blk(x, semantic_token)elif i == 12:x = blk(x)elif i == 13:semantic_token = blk(x)elif i == 14:semantic_token = blk(semantic_token, torch.cat([semantic_token, x], dim=1))elif i > 14 and i < 17:semantic_token = blk(semantic_token)else:x = blk(x, semantic_token)tiny
SwinTransformer((patch_embed): PatchEmbed((proj): Sequential((0): Conv2d_BN((c): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): Hardswish()(2): Conv2d_BN((c): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(3): Hardswish()))(pos_drop): Dropout(p=0.0, inplace=False)(layers): ModuleList((0): BasicLayer(dim=96, input_resolution=(56, 56), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=96, window_size=(7, 7), num_heads=3(qkv): Linear(in_features=96, out_features=288, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=96, out_features=96, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): Identity()(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(act): GELU()(fc2): Linear(in_features=384, out_features=96, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=3, mlp_ratio=4.0(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=96, window_size=(7, 7), num_heads=3(qkv): Linear(in_features=96, out_features=288, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=96, out_features=96, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.018)(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(act): GELU()(fc2): Linear(in_features=384, out_features=96, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(56, 56), dim=96(reduction): Linear(in_features=384, out_features=192, bias=False)(norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)))(1): BasicLayer(dim=192, input_resolution=(28, 28), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=192, window_size=(7, 7), num_heads=6(qkv): Linear(in_features=192, out_features=576, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=192, out_features=192, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.036)(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(act): GELU()(fc2): Linear(in_features=768, out_features=192, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=3, mlp_ratio=4.0(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=192, window_size=(7, 7), num_heads=6(qkv): Linear(in_features=192, out_features=576, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=192, out_features=192, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.055)(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(act): GELU()(fc2): Linear(in_features=768, out_features=192, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(28, 28), dim=192(reduction): Linear(in_features=768, out_features=384, bias=False)(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)))(2): Deit((blocks): ModuleList((0): SwinTransformerBlock(dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=384, window_size=(7, 7), num_heads=12(qkv): Linear(in_features=384, out_features=1152, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.073)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SemanticAttentionBlock((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(multi_scale): multi_scale_semantic_token1()(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.091)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(2): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.109)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(3): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.127)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(4): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.145)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(5): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.164)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(14, 14), dim=384(reduction): Linear(in_features=1536, out_features=768, bias=False)(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)))(3): BasicLayer(dim=768, input_resolution=(7, 7), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=768, window_size=(7, 7), num_heads=24(qkv): Linear(in_features=768, out_features=2304, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=768, out_features=768, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.182)(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(act): GELU()(fc2): Linear(in_features=3072, out_features=768, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=768, window_size=(7, 7), num_heads=24(qkv): Linear(in_features=768, out_features=2304, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=768, out_features=768, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.200)(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(act): GELU()(fc2): Linear(in_features=3072, out_features=768, bias=True)(drop): Dropout(p=0.0, inplace=False))))))(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(avgpool): AdaptiveAvgPool1d(output_size=1)(head): Linear(in_features=768, out_features=100, bias=True)
)网络结构
SwinTransformer((patch_embed): PatchEmbed((proj): Sequential((0): Conv2d_BN((c): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): Hardswish()(2): Conv2d_BN((c): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(3): Hardswish()))(pos_drop): Dropout(p=0.0, inplace=False)(layers): ModuleList((0): BasicLayer(dim=96, input_resolution=(56, 56), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=96, window_size=(7, 7), num_heads=3(qkv): Linear(in_features=96, out_features=288, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=96, out_features=96, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): Identity()(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(act): GELU()(fc2): Linear(in_features=384, out_features=96, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=3, mlp_ratio=4.0(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=96, window_size=(7, 7), num_heads=3(qkv): Linear(in_features=96, out_features=288, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=96, out_features=96, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.013)(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=96, out_features=384, bias=True)(act): GELU()(fc2): Linear(in_features=384, out_features=96, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(56, 56), dim=96(reduction): Linear(in_features=384, out_features=192, bias=False)(norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)))(1): BasicLayer(dim=192, input_resolution=(28, 28), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=192, window_size=(7, 7), num_heads=6(qkv): Linear(in_features=192, out_features=576, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=192, out_features=192, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.026)(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(act): GELU()(fc2): Linear(in_features=768, out_features=192, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=3, mlp_ratio=4.0(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=192, window_size=(7, 7), num_heads=6(qkv): Linear(in_features=192, out_features=576, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=192, out_features=192, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.039)(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=192, out_features=768, bias=True)(act): GELU()(fc2): Linear(in_features=768, out_features=192, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(28, 28), dim=192(reduction): Linear(in_features=768, out_features=384, bias=False)(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)))(2): Deit((blocks): ModuleList((0): SwinTransformerBlock(dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=384, window_size=(7, 7), num_heads=12(qkv): Linear(in_features=384, out_features=1152, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.052)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SemanticAttentionBlock((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(multi_scale): multi_scale_semantic_token1()(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.065)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(2): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.078)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(3): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.091)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(4): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.104)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(5): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.117)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(6): SwinTransformerBlock(dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=384, window_size=(7, 7), num_heads=12(qkv): Linear(in_features=384, out_features=1152, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.130)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop): Dropout(p=0.0, inplace=False)))(7): SemanticAttentionBlock((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(multi_scale): multi_scale_semantic_token1()(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.143)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(8): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.157)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(9): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.170)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(10): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.183)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(11): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.196)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(12): SwinTransformerBlock(dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=384, window_size=(7, 7), num_heads=12(qkv): Linear(in_features=384, out_features=1152, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.209)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop): Dropout(p=0.0, inplace=False)))(13): SemanticAttentionBlock((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(multi_scale): multi_scale_semantic_token1()(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.222)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(14): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.235)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(15): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.248)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(16): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.261)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False)))(17): Block((norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(attn): Attention((q): Linear(in_features=384, out_features=384, bias=True)(kv): Linear(in_features=384, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=384, out_features=384, bias=True)(proj_drop): Dropout(p=0.0, inplace=False))(drop_path): DropPath(drop_prob=0.274)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=384, out_features=1536, bias=True)(act): GELU()(drop1): Dropout(p=0.0, inplace=False)(fc2): Linear(in_features=1536, out_features=384, bias=True)(drop2): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging(input_resolution=(14, 14), dim=384(reduction): Linear(in_features=1536, out_features=768, bias=False)(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)))(3): BasicLayer(dim=768, input_resolution=(7, 7), depth=2(blocks): ModuleList((0): SwinTransformerBlock(dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=768, window_size=(7, 7), num_heads=24(qkv): Linear(in_features=768, out_features=2304, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=768, out_features=768, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.287)(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(act): GELU()(fc2): Linear(in_features=3072, out_features=768, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock(dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention(dim=768, window_size=(7, 7), num_heads=24(qkv): Linear(in_features=768, out_features=2304, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=768, out_features=768, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.300)(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=768, out_features=3072, bias=True)(act): GELU()(fc2): Linear(in_features=3072, out_features=768, bias=True)(drop): Dropout(p=0.0, inplace=False))))))(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(avgpool): AdaptiveAvgPool1d(output_size=1)(head): Linear(in_features=768, out_features=100, bias=True)
)