从“手工时代”到“自动化工厂”
想象一下,你正在经营一家工厂。在传统模式下,每个工人(服务器)需要手动组装产品(应用),效率低下且容易出错。而Kubernetes(k8s)就像一个全自动的智能工厂:它管理着成千上万的机器人(容器),自动分配任务、修复故障,甚至根据订单量动态调整生产线规模。
这就是云原生时代的核心——Kubernetes。本文将带你理解它的本质、架构,以及它如何成为现代应用的基础设施层。
一、为什么需要Kubernetes?
1.1 容器化 vs 虚拟化
在Kubernetes出现之前,虚拟化技术(如VMware)通过虚拟机(VM)实现了资源隔离,但存在致命缺陷:
- 资源浪费:每个VM需携带完整操作系统,占用大量磁盘和内存。
- 启动缓慢:启动一个VM可能需要分钟级时间。
容器化技术(如Docker)解决了这些问题:
- 轻量高效:容器共享主机内核,资源占用仅为MB级。
- 快速部署:秒级启动,适合微服务架构的动态伸缩需求。
# 示例:Docker与虚拟机资源占用对比
docker run -d nginx # 容器:约5MB内存,秒级启动
VM启动一个Nginx服务 # 虚拟机:约500MB内存,分钟级启动
1.2 容器编排的挑战
单个容器容易管理,但在生产环境中,你可能面临:
- 大规模部署:如何同时启动100个容器并监控状态?
- 故障自愈:某个容器崩溃后如何自动重启?
- 流量调度:如何将用户请求分发给健康的容器?
Kubernetes的使命:自动化解决上述问题,成为分布式系统的“操作系统”。
二、Kubernetes的核心架构
2.1 核心组件:Master与Node
Kubernetes集群由两类节点组成:
-
Master节点相当于整个集群的大脑和心脏:
- API Server:集群的“前台”,接收所有操作请求(如
kubectl命令)。 - Scheduler:决定Pod应该运行在哪个Node上。
- Controller Manager:确保集群状态符合预期(如副本数)。
- etcd:分布式键值数据库,存储集群所有配置数据。
- API Server:集群的“前台”,接收所有操作请求(如
-
Worker节点 相当于集群的手和脚用于具体工作的执行:
- kubelet:节点上的“监工”,管理Pod生命周期。
- kube-proxy:处理网络规则(如Service流量转发)。
- 容器运行时:Docker、containerd等,负责运行容器。

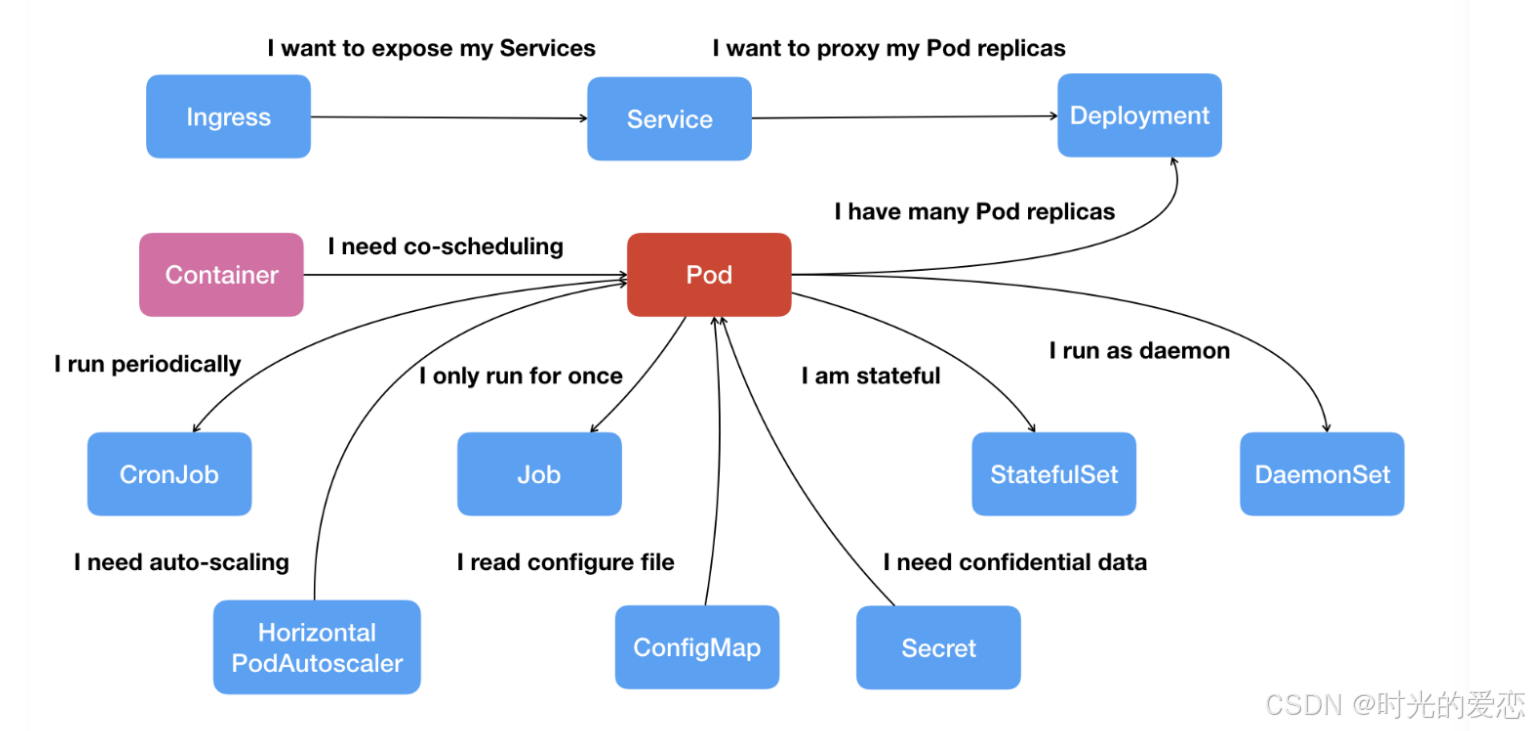
2.2 核心概念:Pod、Deployment与Service
-
Pod:最小的调度单元,像一个“胶囊”,用于封装1个或多个容器,其他的对象如Deployment,configMap 都是基于pod 扩展出来的。
# pod-example.yaml apiVersion: v1 kind: Pod metadata:name: nginx-pod spec:containers:- name: nginximage: nginx:latestports:- containerPort: 80 -
Deployment:定义Pod的“理想状态”,实现滚动更新与回滚。
kubectl create deployment nginx --image=nginx:1.25 --replicas=3 -
Service:为一组Pod提供稳定的访问入口(如负载均衡)。
# service-example.yaml apiVersion: v1 kind: Service metadata:name: nginx-service spec:selector:app: nginxports:- protocol: TCPport: 80targetPort: 80type: LoadBalancer
三、为什么说Kubernetes是云原生的基石?
3.1 云原生的四大特征
根据CNCF(云原生计算基金会)定义,云原生技术需具备:
- 容器化:应用以容器为载体,与环境解耦。
- 动态管理:通过Kubernetes实现自动化编排。
- 微服务架构:应用拆分为松耦合的小型服务。
- 声明式API:描述“期望状态”,而非命令式需要具体步骤。
Kubernetes是这一切的粘合剂:它提供统一的平台,整合存储、网络、计算资源,让开发者聚焦业务逻辑。
四、总结
Kubernetes重新定义了应用交付的方式,成为云原生时代的“操作系统”。它的核心价值在于:
- 标准化基础设施层:让开发者无需关心底层资源细节。
- 加速创新:通过自动化释放运维压力,让团队专注业务迭代。

![[论文阅读] Knowledge Fusion of Large Language Models](https://i-blog.csdnimg.cn/direct/ede44fe0565046a6af7c700d1e645fcd.png#pic_center)