文章目录
- 背景
- 入口起点分离
- 基本使用
- 防重复
- SplitChunksPlugin插件分离
- 背景
- 基本使用
- splitChunks.chunks
- splitChunks.minChunks
- splitChunks.minSize
- splitChunks.maxSize
- splitChunks.name
- splitChunks.cacheGroups
- splitChunks.cacheGroups.{cacheGroup}.priority
- splitChunks.cacheGroups.{cacheGroup}.reuseExistingChunk
- splitChunks.cacheGroups.{cacheGroup}.test
- splitChunks.cacheGroups.{cacheGroup}.filename
- optimization.runtimeChunk
- 举例
- 例一
- 例二
- 例三
背景
代码分离可以说是 webpack 最牛逼的功能了,使用代码分离可以将 chunks 分离到不同的 bundle 中,比如把不经常更新的库打包到一起放在一个 bundle 中缓存起来,这样可以减少加载时间等等。
什么是 chunks?
英文原意:块,可以被 import、require等引用的模块就是 chunk
什么是 bundle?
英文原意:束,捆,包,把一个或者多个模块打包成的一个整体就叫 bundle,比如我们项目中打包后 dist 中的内容
常用的代码分离方法有两种:
- 入口起点分离:使用 entry 配置手动地分离代码
- SplitChunksPlugin插件分离
可能会遇到的问题:
- 重复问题
代码分离的技巧:
- 动态导入:通过模块的内联函数调用分离代码。
https://webpack.docschina.org/guides/code-splitting/
入口起点分离
基本使用
我们配置两个入口
const path = require('path');module.exports = {mode: 'development',entry: {index: './src/index.js',another: './src/another-module.js',},output: {filename: '[name].bundle.js',path: path.resolve(__dirname, 'dist'),},
};
其中 index.js 引入了 another-module.js,another-module.js引入了 lodash。
但是打包后我们发现两个文件:
index.bundle.js 553 KiB
another.bundle.js 553 KiB
也就是说如果入口 chunk 之间包含一些重复的模块,那么这些重复模块都会被引入到各个 bundle 中。当然这个也是可以解决的,只需要配置 dependOn 选项就可以防止重复。
防重复
const path = require('path');module.exports = {mode: 'development',entry: {index: {import: './src/index.js',// adddependOn: 'shared',},another: {import: './src/another-module.js',// adddependOn: 'shared',},// addshared: 'lodash',},output: {filename: '[name].bundle.js',path: path.resolve(__dirname, 'dist'),},
};
如果想要在一个 HTML 页面上使用多个入口,还需设置 optimization.runtimeChunk: ‘single’
const path = require('path');module.exports = {mode: 'development',entry: {index: {import: './src/index.js',dependOn: 'shared',},another: {import: './src/another-module.js',dependOn: 'shared',},shared: 'lodash',},output: {filename: '[name].bundle.js',path: path.resolve(__dirname, 'dist'),},// addoptimization: {runtimeChunk: 'single',},
};
shared.bundle.js 549 KiB
runtime.bundle.js 7.79 KiB
index.bundle.js 1.77 KiB
another.bundle.js 1.65 KiB
官方并不推荐多入口,既是是多入口,也推荐 entry: { page: ['./analytics', './app'] } 这种写法
SplitChunksPlugin插件分离
背景
最初,chunks(以及内部导入的模块)是通过内部 webpack 图谱中的父子关系关联的。CommonsChunkPlugin 曾被用来避免他们之间的重复依赖,但是不可能再做进一步的优化。
从 webpack v4 开始,移除了 CommonsChunkPlugin,取而代之的是 optimization.splitChunks。所以这个插件是 webpack内置的,不需要单独导入。
基本使用
如果你没有配置 optimization.splitChunks,那么 webpack 会使用这份默认配置。这里配置的目的都是表示什么样的模块可以进行分割打包,比如下面的 minSize 表示大于等于2k的模块才会被分割
module.exports = {//...optimization: {splitChunks: {chunks: 'async',minSize: 20000,minRemainingSize: 0,minChunks: 1,maxAsyncRequests: 30,maxInitialRequests: 30,enforceSizeThreshold: 50000,cacheGroups: {defaultVendors: {test: /[\\/]node_modules[\\/]/,priority: -10,reuseExistingChunk: true,},default: {minChunks: 2,priority: -20,reuseExistingChunk: true,},},},},
};
我们分析一下这些字段代表的含义:
- 默认只对按需引入的模块进行代码分割;
- 来自 node_modules 的模块,或被引用两次及以上的模块,才会做代码分割;
- 被分割的模块必须大于30kb(代码压缩前);
- 按需加载时,并行的请求数必须小于或等于5;
- 初始页加载时,并行的请求数必须小于或等于3;
接下来这里只说一些重要的字段含义:
splitChunks.chunks
可选值: function (chunk) | initial | async | all
initial表示入口文件中非动态引入的模块all表示所有模块async表示异步引入的模块
动态/异步导入
第一种,符合 ECMAScript 提案 的 import() 语法
第二种,是 webpack 的遗留功能,使用 webpack 特定的 require.ensure
splitChunks.minChunks
拆分前必须共享模块的最小 chunks 数,也就是说如果这个模块被依赖几次才会被分割,默认为1
splitChunks.minSize
生成 chunk 的最小体积,单位为子节,1K=1024bytes
splitChunks.maxSize
同上相反
splitChunks.name
用户指定分割模块的名字,设置为true表示根据chunks和cacheGroup key自动生成
可选值: boolean: true | function (module, chunks, cacheGroupKey) | string
名称可以通过三种方式获取
module.rawRequest
module.resourceResolveData.descriptionFileData.name
chunks.name
使用 chunks.name 获取的时候需要使用 webpack 的魔法注释
import(/*webpackChunkName:"a"*/ './a.js')
举例:
name(module, chunks, cacheGroupKey) {// 打包到不同文件中了return `${cacheGroupKey}-${module.resourceResolveData.descriptionFileData.name}`;// 如果是写死一个字符串,那么多个chunk会被打包到同一个文件中,这样可能会导致首次加载变慢// return 'maincommon';// 指定打包后的文件所在的目录// return 'test/commons';
}
splitChunks.cacheGroups
缓存组可以继承和/或覆盖来自 splitChunks.* 的任何选项。但是 test、priority 和 reuseExistingChunk 只能在缓存组级别上进行配置。将它们设置为 false以禁用任何默认缓存组。
module.exports = {//...optimization: {splitChunks: {cacheGroups: {// 默认为 true,表示继承 splitChunks.* 的字段default: false,},},},
};
splitChunks.cacheGroups.{cacheGroup}.priority
一个模块可以属于多个缓存组,所以需要优先级。default 组的优先级为负数,我们自定义组的优先级默认为 0
splitChunks.cacheGroups.{cacheGroup}.reuseExistingChunk
如果这个缓存组中的chunk已经在入口模块(main module)中存在了,就不会引入
splitChunks.cacheGroups.{cacheGroup}.test
module.exports = {//...optimization: {splitChunks: {cacheGroups: {svgGroup: {test(module) {// `module.resource` contains the absolute path of the file on disk.// Note the usage of `path.sep` instead of / or \, for cross-platform compatibility.const path = require('path');return (module.resource &&module.resource.endsWith('.svg') &&module.resource.includes(`${path.sep}cacheable_svgs${path.sep}`));},},byModuleTypeGroup: {test(module) {return module.type === 'javascript/auto';},},testGroup: {// `[\\/]` 是作为跨平台兼容性的路径分隔符,也就是/test: /[\\/]node_modules[\\/]/,}},},},
};
splitChunks.cacheGroups.{cacheGroup}.filename
module.exports = {//...optimization: {splitChunks: {cacheGroups: {defaultVendors: {filename: '[name].bundle.js',filename: (pathData) => {// Use pathData object for generating filename string based on your requirementsreturn `${pathData.chunk.name}-bundle.js`;},},},},},
};
optimization.runtimeChunk
optimization: {runtimeChunk: 'single',
}
// 等同于
optimization: {runtimeChunk: {name: 'runtime'}
}
优化持久化缓存的, runtime 指的是 webpack 的运行环境(具体作用就是模块解析, 加载) 和 模块信息清单, 模块信息清单在每次有模块变更(hash 变更)时都会变更, 所以我们想把这部分代码单独打包出来, 配合后端缓存策略, 这样就不会因为某个模块的变更导致包含模块信息的模块(通常会被包含在最后一个 bundle 中)缓存失效. optimization.runtimeChunk 就是告诉 webpack 是否要把这部分单独打包出来.
假设一个使用动态导入的情况(使用import()),在app.js动态导入component.js
const app = () =>import('./component').then();
build之后,产生3个包。
0.01e47fe5.js
main.xxx.js
runtime.xxx.js
其中runtime,用于管理被分出来的包。下面就是一个runtimeChunk的截图,可以看到chunkId这些东西。
...
function jsonpScriptSrc(chunkId) {
/******/ return __webpack_require__.p + "" + ({}[chunkId]||chunkId) + "." + {"0":"01e47fe5"}[chunkId] + ".bundle.js"
/******/ }
...
如果采用这种分包策略
当更改app的时候runtime与(被分出的动态加载的代码)0.01e47fe5.js的名称(hash)不会改变,main的名称(hash)会改变。
当更改component.js,main的名称(hash)不会改变,runtime与 (动态加载的代码) 0.01e47fe5.js的名称(hash)会改变。
举例
把默认配置放在这里做对照方便查阅
module.exports = {//...optimization: {splitChunks: {chunks: 'async',minSize: 20000,minRemainingSize: 0,minChunks: 1,maxAsyncRequests: 30,maxInitialRequests: 30,enforceSizeThreshold: 50000,cacheGroups: {defaultVendors: {test: /[\\/]node_modules[\\/]/,priority: -10,reuseExistingChunk: true,},default: {minChunks: 2,priority: -20,reuseExistingChunk: true,},},},},
};
例一
// 静态引入
import lodash from 'lodash'
import(/*webpackChunkName:"jquery"*/'jquery')
import('./echarts.js')
console.log('hello world')
module.exports = {//...optimization: {splitChunks: {chunks: 'async',name(module, chunks, cacheGroupKey) {// 打包到不同文件中了return `${cacheGroupKey}-${module.resourceResolveData.descriptionFileData.name}`;},},},
};
lodash 是静态引入的,jquery 和 echarts 是动态引入的,而我们这里配置了 async,所以打包会分割出出动态引入的包:
// 可以看到这里的 cacheGroupKey 就是 defaultVendors,也就是默认的分组名称。
defaultVendors-jquery.js
// 主包中包含了lodash和console.log('你好')
main.js
// echarts 也是动态引入的,但是由于走的相对路径,所以name函数无法对其自定义,因为name函数是在外面,只对默认的 defaultVendors 组负责,而这个组中没有对 name 的自定义,所以就生成了默认的。
510.js
例二
那么接下来我们对 echarts 进行分组
module.exports = {//...optimization: {splitChunks: {chunks: 'async',name(module, chunks, cacheGroupKey) {// 打包到不同文件中了return `${cacheGroupKey}-${module.resourceResolveData.descriptionFileData.name}`;},cacheGroups: {echartsVendor: {test: /[\\/]echarts/,name: 'echarts-bundle',chunks: 'async',},},},},
};
// 可以看到这里的 cacheGroupKey 就是 defaultVendors,也就是默认的分组名称。
defaultVendors-jquery.js
// 主包中包含了lodash和console.log('你好')
main.js
// 由 echartsVendor 组生成的bundle
echarts-bundle.js
例三
打包小程序的时候,如果主包依赖分包的js,会把分包的代码打包进主包的 bundle 里,这里做一下调整也用到了 splitChunks
原本是这样的,可以看到所有的包都打进了 common 里面
module.exports = {//...optimization: {splitChunks: {chunks: 'all',name: 'common'},},
};
修改后
module.exports = {//...optimization: {splitChunks: {chunks: 'all',name: 'common',cacheGroups: {echartsVendor: {test: /[\\/]subpackage-echarts[\\/]/,name: 'subpackage-echarts/echartsVendor',chunks: 'all'},compontentsVendor: {test: /[\\/]subpackage-components[\\/]/,name: 'subpackage-components/componentsVendor',chunks: 'all',minSize: 0}}},},
};
可以看到,如果是分包 subpackage-echarts 和 subpackage-components,我会把打包后的 bundle 放到对应的分包文件夹里。但是我觉得这样有点硬编码了,如果后面再增加一个分包还是会有此问题,于是再修改一下
const { resolve } = require('path')
const fs = require('fs')
/*** @function 获取分包名称* @returns {Array} ['subpackage-a', 'subpackage-a']*/
const getSubpackageNameList = () => {const configFile = resolve(__dirname, 'src/app.json')const content = fs.readFileSync(configFile, 'utf8')let config = ''try {config = JSON.parse(content)} catch (error) {console.log(configFile)}const { subpackages } = configreturn subpackages.map(item => item.root)
}module.exports = {//...optimization: {splitChunks: {chunks: 'all',name: 'common',cacheGroups: {subVendor: {test: (module) => {const list = getSubpackageNameList()const isSubpackage = list.some(item => module.resource.indexOf(`/${item}/`) !== -1)return isSubpackage},name(module, chunks, cacheGroupKey) {const list = getSubpackageNameList()const subpackageName = list.find(item => module.resource.indexOf(`/${item}/`) !== -1)return `${subpackageName}/vendor`},chunks: 'all',minSize: 0},}},},
};
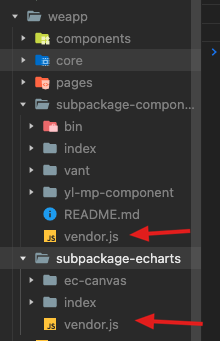
可以看到打包后依赖分包的文件都放到了分包里,这样,不管后面怎么增加分包,都不用修改代码了。