文章目录
- 正则化(Regularization):
- 验证(Validation):

正则化和验证是机器学习中重要的概念,它们帮助提高模型的性能和泛化能力。让我详细介绍一下这两个概念:
正则化(Regularization):
正则化是一种用于防止机器学习模型过拟合(Overfitting)的技术。过拟合是指模型在训练数据上表现得非常好,但在未见过的数据上表现糟糕的情况。正则化的目标是限制模型的复杂性,使其更好地泛化到新数据。
常见的正则化技术包括:
-
L1 正则化:也称为 Lasso 正则化,它通过在损失函数中添加模型权重的绝对值之和来惩罚特征的绝对值。这可以促使模型选择对目标变量具有最大影响的关键特征,同时减小不相关特征的权重。
-
L2 正则化:也称为 Ridge 正则化,它通过在损失函数中添加模型权重的平方和来惩罚特征的平方值。这有助于防止模型权重过大,减少特征之间的共线性。
-
弹性网络正则化:弹性网络是 L1 正则化和 L2 正则化的组合,它允许同时控制特征选择和权重缩放。
正则化的目标是在损失函数中加入一个惩罚项,通过调整正则化参数(如λ)来控制正则化的强度。通过适当选择正则化参数,可以找到适合的平衡点,既能拟合训练数据又能防止过拟合。
验证(Validation):
验证是用于评估机器学习模型性能的关键步骤。通常,将数据分为三个部分:训练集(Training Set)、验证集(Validation Set)和测试集(Test Set)。
-
训练集:用于训练模型的数据集。
-
验证集:用于调整模型超参数、选择模型和监测模型性能的数据集。在训练过程中,模型根据验证集的性能进行调整。这有助于防止在训练过程中过度拟合训练数据。
-
测试集:用于最终评估模型性能的数据集。测试集是模型未见过的数据,用于估计模型在实际应用中的泛化性能。
常见的验证技术包括:
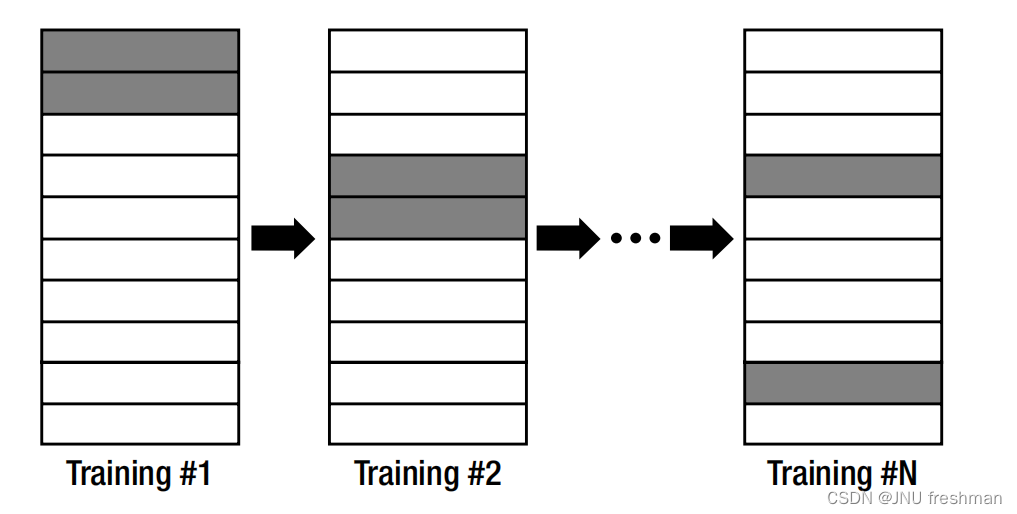
- 交叉验证(Cross-Validation):这是一种有效的验证方法,将数据划分为多个子集,然后多次训练和验证模型,每次使用不同的子集作为验证集。最常见的交叉验证是 k 折交叉验证,其中数据被分成 k 个子集,每个子集轮流充当验证集,其余作为训练集。
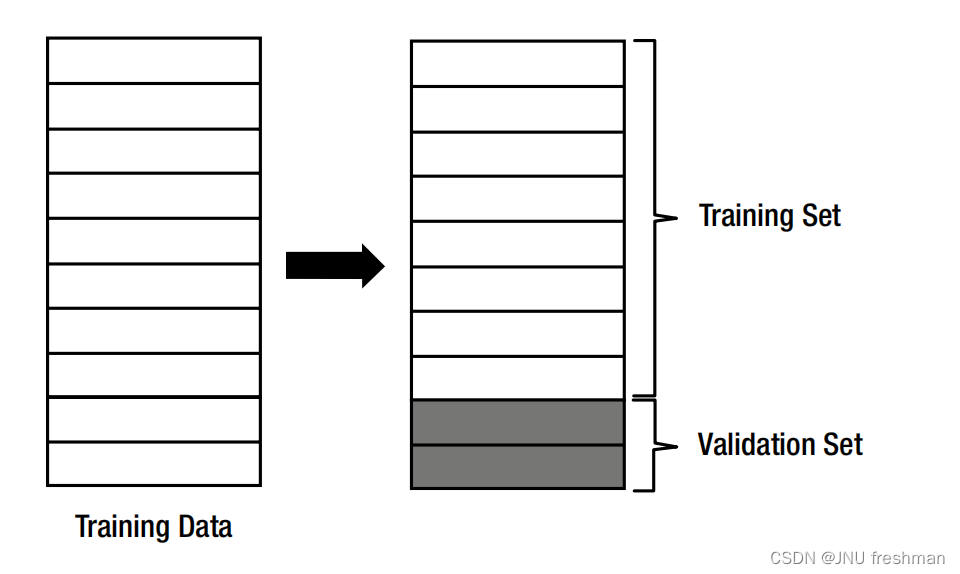
- 留出验证(Holdout Validation):将数据分成训练集和验证集两部分,通常以 70-80% 的数据作为训练集,其余作为验证集。这是最简单的验证方法,但数据量较小时可能会导致验证结果不稳定。
- 网格搜索(Grid Search)和随机搜索(Random Search):用于自动搜索模型的最佳超参数组合。这些方法在验证过程中尝试多个超参数组合,以找到最佳性能的模型。
验证的目标是评估模型的性能,包括准确性、精确度、召回率、F1 分数等指标。通过验证,可以选择最佳模型和超参数,以确保模型在实际应用中的良好性能。最终,测试集用于验证模型是否能够在未见数据上进行良好的泛化。