🌏博客主页: 主页
🔖系列专栏: C++
❤️感谢大家点赞👍收藏⭐评论✍️
😍期待与大家一起进步!
文章目录
- 前言
- 一、求下标仿函数的建议
- 二、布隆过滤器代码
- 面试题
- 1.近似算法:
- 2.精确算法
前言
`
布隆过滤器特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。布隆过滤器一般用来操作的对象类型为string,因为string在位图中不好被标记
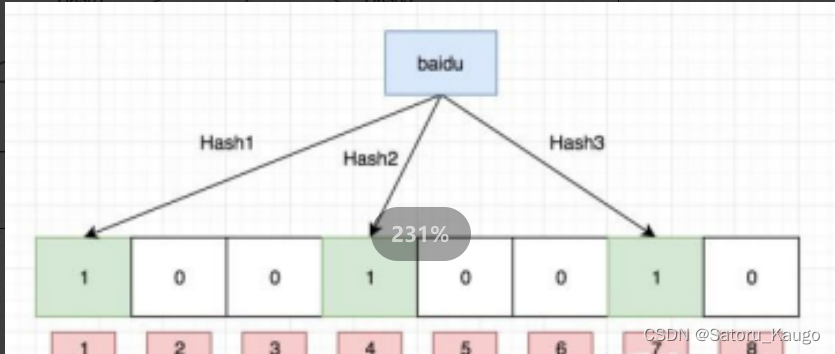
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的
为了减小失误,我们可以用多种方法计算对应字符串的下标所对应位置
一、求下标仿函数的建议
struct BKDRHash
{size_t operator()(const string& str){size_t hash = 0;for (auto ch : str){hash = hash * 131 + ch;}//cout <<"BKDRHash:" << hash << endl;return hash;}
};struct APHash
{size_t operator()(const string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); i++){size_t ch = str[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}//cout << "APHash:" << hash << endl;return hash;}
};struct DJBHash
{size_t operator()(const string& str){size_t hash = 5381;for (auto ch : str){hash += (hash << 5) + ch;}//cout << "DJBHash:" << hash << endl;return hash;}
};
二、布隆过滤器代码
template<size_t N,class K=string, class Hash1 = BKDRHash,class Hash2 = APHash,class Hash3 = DJBHash>
class BloomFilter {
public:void Set(const K& key) {//字符串插入size_t hash1 = Hash1()(key) % N;_bs.set(hash1);size_t hash2 = Hash2()(key) % N;_bs.set(hash2);size_t hash3 = Hash3()(key) % N;_bs.set(hash3);}bool Test(const K& key)//检测字符串是否存在{//你每个哈希下标都为1,不能说明这个字符串一定存在,//但若你有一个下标检测为0,那么一定不存在size_t hash1 = Hash1()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash2 = Hash2()(key) % N;if (_bs.test(hash2) == false)return false;size_t hash3 = Hash3()(key) % N;if (_bs.test(hash3) == false)return false;return true; }private:bitset<N> _bs;
};
面试题
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
1.近似算法:
这里直接就是布隆过滤器,因为其可能存在冲突,所以为近似算法,因为结果有小概率是错误的
2.精确算法
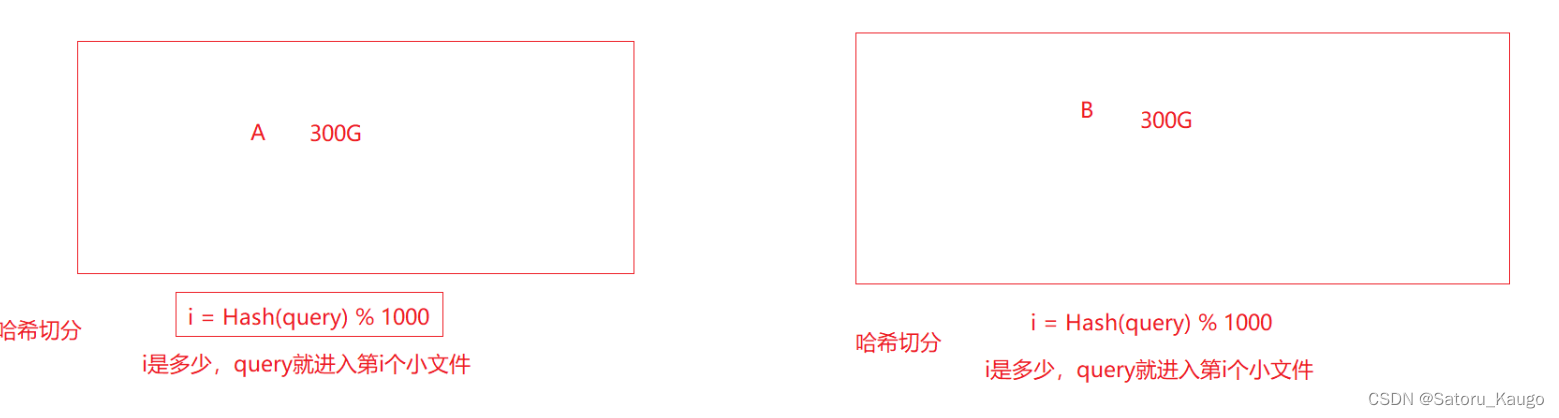
先将大文件进行分割,取出一部分进行找交集
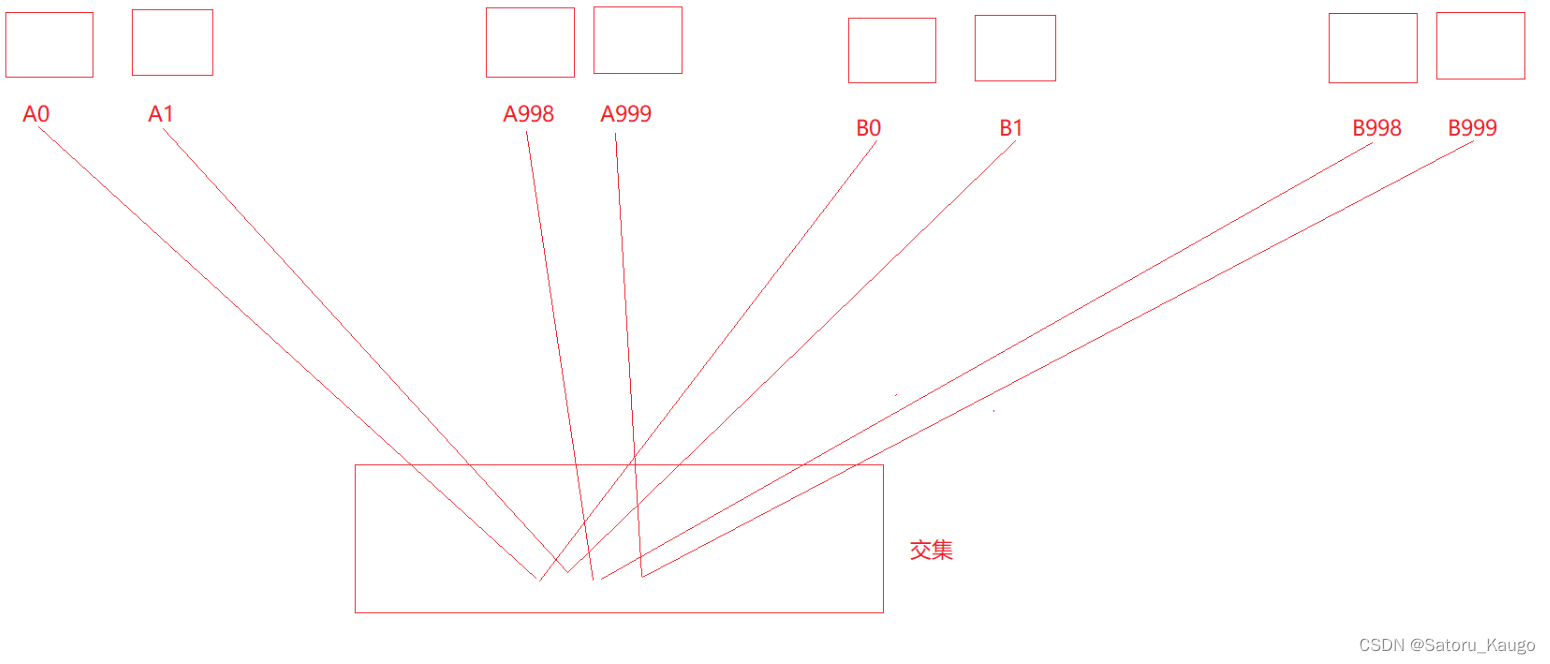
利用哈希切分:A与B中相同的query一定会分别进入Ai与Bi相同编号的小文件
找交集,Ai读出来放进一个set,再依次读取B的query,在就是交集并且删掉,就可以找到Ai与Bi的交集。
可能存在的情况:
两个场景:Ai有5G
1.4G都是相同的query,1G冲突
2.大多数都是冲突的,这里冲突指的是两个不同的字符串算哈希下标的时候,所有哈希下标均相同。
解决方案:
1.先把Ai的query读到一个set中,再依次读取Bi的query,如果set的insert报错抛异常(因为超出的最大容量),那么大多数的都是冲突的,因为如果我是相同的话,哪怕我有4G给相同数据,最后只插入一个,因为set有去重的功能
如果能全部insert到里面说明Ai大部分都是相同的
2.如果抛异常,说明有大量冲突,哈希下标全都重了,这个时候我们需要新换一个哈希函数,继续进行切分