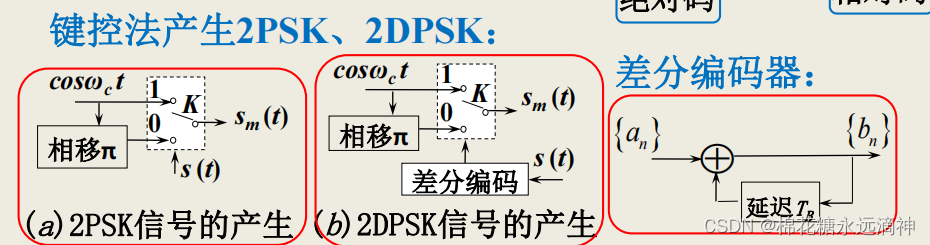
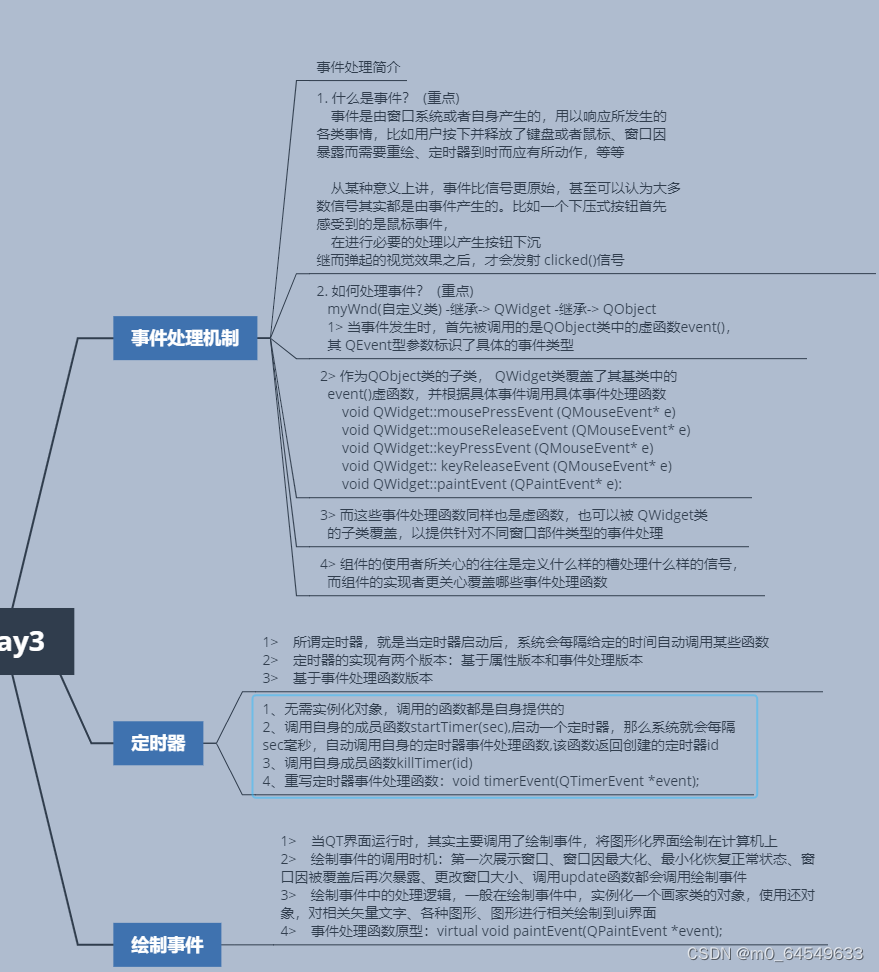
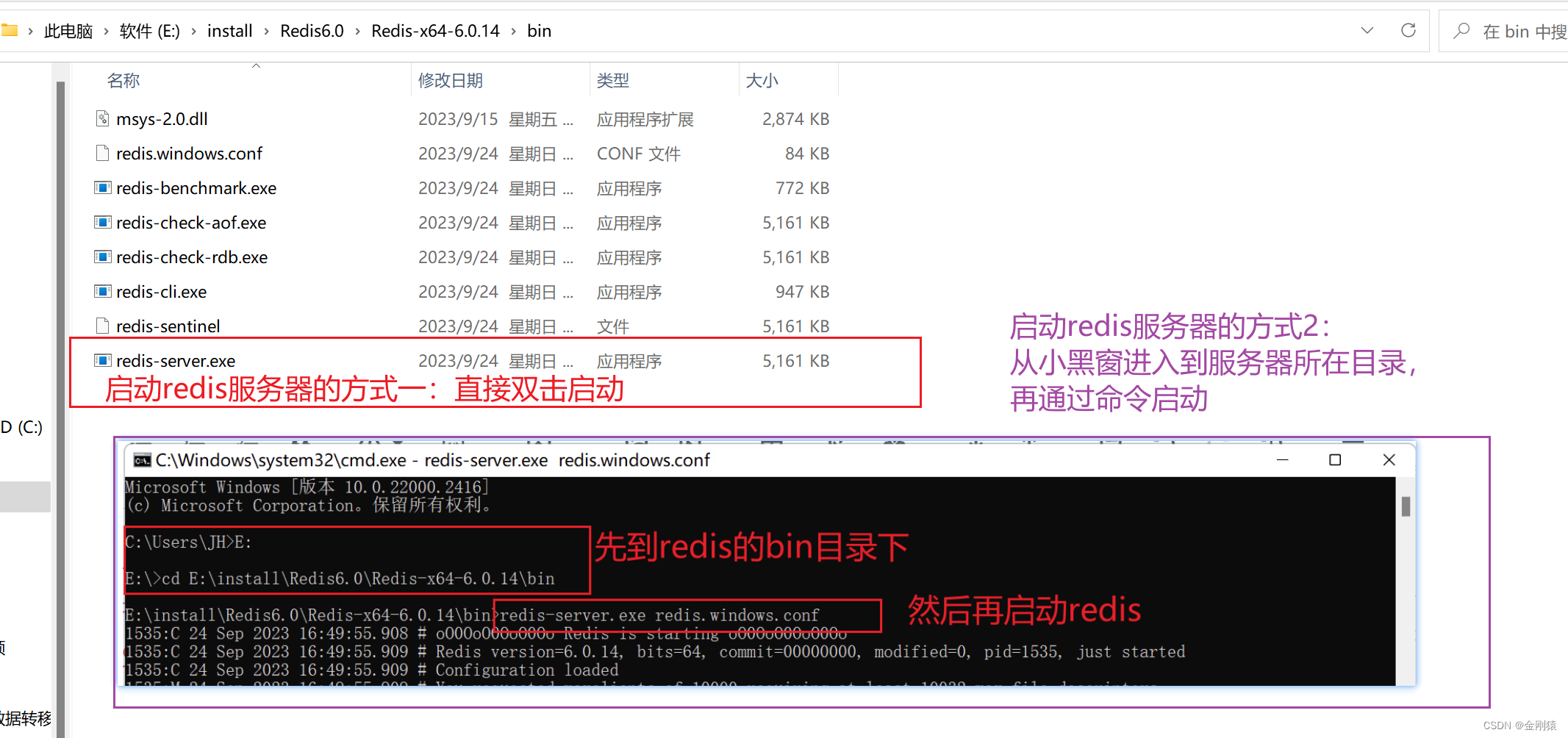
1、均值方差标准化(Z-Score标准化)
计算过程:
对每个属性/每列分别进行一下操作,将数据按属性/按列减去其均值,并除以其方差,最终使每个属性/每列的所有数据都聚集在均值为0,方差为1附近。
公式:(x-mean(x))/std(x)
使用sklearn.processing()方法
from sklearn import preprocessing
scaled = preprocessing.scale(data)# 还可以自定义公式
def std_ch(data):data=(data-data.mean())/data.std()return data使用sklearn.preprocessing.StandardScaler类。
from sklearn.preprocessing import StandardScaler
scaler = StandradScaler().fit(train_data)
# 查看数据的均值
scaler.mean_
# 查看数据的方差
scaler.std_
# 直接对测试集进行转换
scaler.transform(test_data)2、0-1标准化(离差标准化,最大最小标准化)
对原始数据进行线性变换,使其结果落在[0,1]区间内,转换函数如下: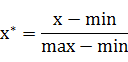
其中max为样本数据的最大值,min为样本数据的最小值。
可以通过sklearn.preprocessing.MinMaxScaler类实现。
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
train_scaled = min_max_scaler.fit_transform(train_data)
# 同样的缩放应用到测试集数据中
test_scaled = min_max_scaler.transform(test_data)
# 查看缩放因子
min_max_scaler.scale_# 自定义公式
def deal(data):data=(data-data.min())/(data.max()-data.min())return data3、正态化分布
计算的主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后的样本的p-范数等于1。在文本分类和聚类分析中经常作为向量空间模型(SVM)的基础。
使用sklearn.preprocessing.normalize()来实现。
from sklearn.preprocessing import normalize
data_normalized = normalize(data,norm = 'l2')
# data_normalized = normalize(data,norm = 'l1')