9.24 day1 Q
1.
this 指针是用来干什么的?
2.基类和派生类分别是指什么?
3.为什么方法中不能写静态变量
4.
解释一下ASCII码和ANSI码和两者的区别
5.简述j ava.io java.sql java.awt java.rmi 分别是什么类型的包
6.
看下面一段代码:
public class Test{private static int i = 1;public int getNext(){return i++;}public static void main(String[] args){Test test = new Test();Test testObject = new Test();test.getNext();testObject.getNext();Sout(testObject.getNext());}
}
最后打印的值
7.
以下的代码结果是:
public class foo {public static void main(String sgf[]) {StringBuffer a=new StringBuffer("A");StringBuffer b=new StringBuffer("B");operate(a,b);System.out.println(a+"."+b);}static void operate(StringBuffer x,StringBuffer y) {x.append(y);y=x;}
}
8.
分析此构造结果:
class Base{public Base(String s){System.out.print("B");}
}
public class Derived extends Base{public Derived (String s) {System.out.print("D");}public static void main(String[] args){new Derived("C");}
}
10.
说一说HashMap 和 Hashtable 两者的区别?
1.线程安全性:
2.null键和null值
3.继承关系
4.效能
5.初始容量和负载因子
6.迭代顺序
12.
那些类实现或继承了COllection接口和Map接口?
13.
看一下的代码,其中能正常执行的有
public static void main(String args[]) {
byte a = 3;
byte b = 2;
b = a + b;
System.out.println(b);
}
// A
public static void main(String args[]) {
byte a = 127;
byte b = 126;
b = a + b;
System.out.println(b);
}
// B
public static void main(String args[]) {
byte a = 3;
byte b = 2;
a+=b;
System.out.println(b);
}
//C
public static void main(String args[]) {
byte a = 127;
byte b = 127;
a+=b;
System.out.println(b);
}
//D
14.说一说实例变量、局部变量、类变量和final变量之间的异同点
实例变量
是在类中声明的变量,可以具有访问修饰符(public,private,protected等)可以通过对象引用以及在类中的方法进行访问和修改
只有对象被销毁后才会被销毁
局部变量
局部变量不具有默认值,必须初始化
在代码块执行结束之后被销毁
类变量
用static修饰的变量
会一直存在于内存中,直到程序退出或类被卸载
final 变量
final变量是一个常量,一旦被赋值后就不能再更改它的值
final变量可以是实例变量,局部变量或类变量
final变量必须在声明时或构造函数中进行初始化,且不能再被修改
final变量在java编译器中有重要作用,提供了不可变性和线程安全性
public class VariableExample {// 实例变量private int instanceVariable;// 类变量private static String classVariable = "Hello";
public void exampleMethod() {// 局部变量int localVar = 10;
// 使用实例变量和类变量instanceVariable = 20;System.out.println("Instance Variable: " + instanceVariable);System.out.println("Class Variable: " + classVariable);
// 使用局部变量System.out.println("Local Variable: " + localVar);// 使用final变量final int finalVar = 30;System.out.println("Final Variable: " + finalVar);// 错误示例:finalVar = 40; // 无法修改final变量的值}public static void main(String[] args) {VariableExample obj = new VariableExample();obj.exampleMethod();}
}
15.
Q: 以下代码将打印出
public static void main (String[] args) { String classFile = "com.jd.". replaceAll(".", "/") + "MyClass.class";System.out.println(classFile);
}
9.24 java 1 A
1.
this指针是隐藏的,可以使用该指针来访问调用对象中的数据。
保证每个对象拥有自己的成员,但共享处理这些数据的代码
2.
基类是继承关系中位于最高i级别的类,也就是父类
派生类是从基类继承属性和方法的类
3.
因为被static修饰的变量称为静态变量,静态变量属于整个类,而局部变量属于方法,只在该方法内有效,两者矛盾
public class Test {static String x = "1";static int y = 1;public static void main(String args[]){static int z = 2;//error}
}
4.
相同点:都是用于表示字符的编码方案
ASCII码无法包括所有国际字符
ANSI码使用更加广泛,因为它包含的更多
标准ASCII只使用7 个bit
ANSI就是GB2312
ASCII码是ANSI码的子集
都不能打印,因为包含一些特殊空字符
5.
java,io提供了全面的IO接口。包括:文件读写、标准设备输出
java.sql:提供使用编程语言访问并处理在数据源中的数据的API。此API包括一个框架,凭借此框架可以动态地安装不同驱动程序来访问不同数据源
java.awt:是一个软件包,包含用于创建用户界面和绘制图形图像的所有分类。功能:包含用于创建用户界面和绘制图形图像的所有类
java.rmi:提供RMI包。RMI指的是远程方法调用。它是一种机制。能够让某个java虚拟机上的对象调用另一个java虚拟机中的对象上的方法
6.
答案是:3
return i++,先返回i,然后i+1
7.
简单来说就是有a,b,x,y四个指针
往方法中传参,传的仅仅知识地址,而不是实际内存,所以y = x ,并不是b=a的执行,这里只是y指向了a指向的地址
8.
子类构造方法在调用时必须先调用父类的,由于父类没有无参构造,所以只能在子类中显性调用,在子类构造方法的第一行
public Derived extends Base{
public Derived(String s){super("s");
System.out.print("D")
}
}
9.
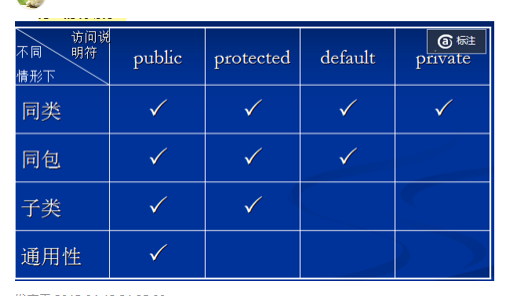
这个表记住
10.
Hashtable and HashMap 的区别:
1.线程安全性:Hashtable是线程安全的,而HashMap不是。Hashtable中的方法是同步的,多个线程可以安全的同时访问和修改Hashtable 的内容
2.null键和null值:
HashMap允许使用null作为键和值,而Hashtable不允许。在HashMap中,可以将null作为键和值都可以
3.继承关系:
都是基于哈希表实现的,Hashtable是基于哈希表和同步机制的组合实现的
4.效能:HashMap 通常比 Hashtable具有更好的性能。由于Hashtbale 中的方法是同步的,这会在多线程环境下引入一定的性能开销。而HashMap不具备同步机制,可以在单线程环境或自行进行线程同步时提供更高的性能
5.初始容量和负载因子:HashMap允许设置初始容量和负载因子。初始容量是指哈希表初始的大小,负载因子表示哈希表在容量自动扩充之前可以达到多满的程度。而Hashtable有一个默认的初始容量,且在内部逻辑中使用了默认的负载因子
6.迭代顺序:HashMap的迭代顺序不保证是特定,他可能会随着时间和容量的变化而变化。而Hashtable的迭代顺序是按照插入顺序保持不变的
在这里帮大家总结一下hashMap和hashtable方面的知识点吧:
-
关于HashMap的一些说法: a) HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。HashMap的底层结构是一个数组,数组中的每一项是一条链表。
-
b) HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子。 c) HashMap实现不同步,线程不安全。 HashTable线程安全
-
d) HashMap中的key-value都是存储在Entry中的。
-
e) HashMap可以存null键和null值,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性
-
f) 解决冲突主要有三种方法:定址法,拉链法,再散列法。HashMap是采用拉链法解决哈希冲突的。
-
注: 链表法是将相同hash值的对象组成一个链表放在hash值对应的槽位;
-
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。 沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。
-
拉链法解决冲突的做法是: 将所有关键字为同义词的结点链接在同一个单链表中 。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。拉链法适合未规定元素的大小。
-
Hashtable和HashMap的区别: a) 继承不同。
public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map
-
b) Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
-
c) Hashtable 中, key 和 value 都不允许出现 null 值。 在 HashMap 中, null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null 。当 get() 方法返回 null 值时,即可以表示 HashMap 中没有该键,也可以表示该键所对应的值为 null 。因此,在 HashMap 中不能由 get() 方法来判断 HashMap 中是否存在某个键, 而应该用 containsKey() 方法来判断。
-
d) 两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 e) 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
-
f) Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。 注: HashSet子类依靠hashCode()和equal()方法来区分重复元素。 HashSet内部使用Map保存数据,即将HashSet的数据作为Map的key值保存,这也是HashSet中元素不能重复的原因。而Map中保存key值的,会去判断当前Map中是否含有该Key对象,内部是先通过key的hashCode,确定有相同的hashCode之后,再通过equals方法判断是否相同
11.
[a,b):包括a,但不包括b
12.

13.
byte类型的值在进行运算的时候,会强行转化为int
A and B 都是左边是byte,右边是int,转换不了
而C,D语句中用的是 a+=b 的语句,此语句会将被赋值的变量自动强制转化为相对应的类型
14.
float占4个字节为什么比long占8个字节大呢,因为底层的实现方式不同。
浮点数的32位并不是简单直接表示大小,而是按照一定标准分配的。
第1位,符号位,即S
接下来8位,指数域,即E。
剩下23位,小数域,即M,取值范围为[1 ,2 ) 或[0 , 1)
然后按照公式: V=(-1)^s * M * 2^E
也就是说浮点数在内存中的32位不是简单地转换为十进制,而是通过公式来计算而来,通过这个公式虽然,只有4个字节,但浮点数最大值要比长整型的范围要大。
不行
15.
replaceAll()函数的第一个参数是一个正则表达式,而“."在正则表达式中代表的了全部字符
R:
1.接口与抽象类是不同的概念,抽象类是捕捉子类的通用特性,接口是抽象方法的集合
2.实现接口必须实现接口的所有方法
3.接口可以继承一个或多个接口,抽象类只能继承一个类或多个接口
4.一个类只能继承一个类,但是可以实现多个接口
一个接口可以实现多个接口的原因是多重继承的替代方案,多态化实现,接口的解耦和复用,使用不同的业务需求。如果没有实现所有接口的方法,那么该类必须声明为抽象类